私について
はじめまして、私はRailsで開発しているWeb系の駆け出しエンジニアです。
サービス運用にあたり、膨大なアクセス数やイベント数の解析を効率的に行えるように分析基盤を作成することになりました。
そこで、GoogleAnalytics4(以下GA4)のデータをBigQuery(以下BQ)で扱うための分析基盤を作成しました。
もちろんデータ分析基盤の作成は初めてです。
作成するために、書籍やオンライン勉強会への参加で知識を集めました。
不十分な点や今後の改善点はありますが、入門者としてできる範囲で分析基盤の設計、作成、パイプライン構築についての記録となります。
記事概要
この記事に含まれるもの
- データ分析基盤の基本構造
- DataformからBigQueryのクエリ実行
- WorkflowsからDataformの実行
- WorkflowsからSlackへ通知
- CloudSchedulerによるスケジュールの実行
この記事に含まれないもの
- SQLやBQのクエリに関すること
- IAMやサービスアカウントの設定など権限に関すること
- GithubやSlackなど別サービスの設定に関すること
- GA4に関する内容と設定について
- タグマネージャー(GTM)の利用/設定について
- データ品質/コストなどについて
対象 / 想定 の読者
- これから社内にBQを利用したデータ分析基盤の設計をされる方
- データ分析基盤に興味がある方
- 他の人がどのようにデータ分析基盤を作っているか気になる人
データ分析基盤設計を考える
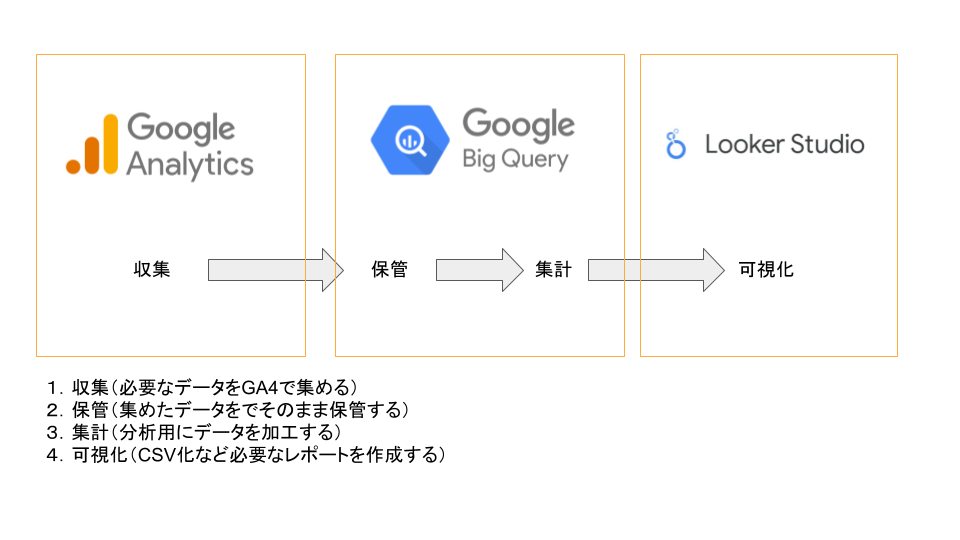
まずGA4とBQの利用用途、目的の違いを知りました。
以下の図のように、4つのステップがあります。
今回、扱うのは 2保管/3集計 の箇所になります。
次に「じゃあBQの保管/集計ってどうやってるの?」という疑問が生まれました。
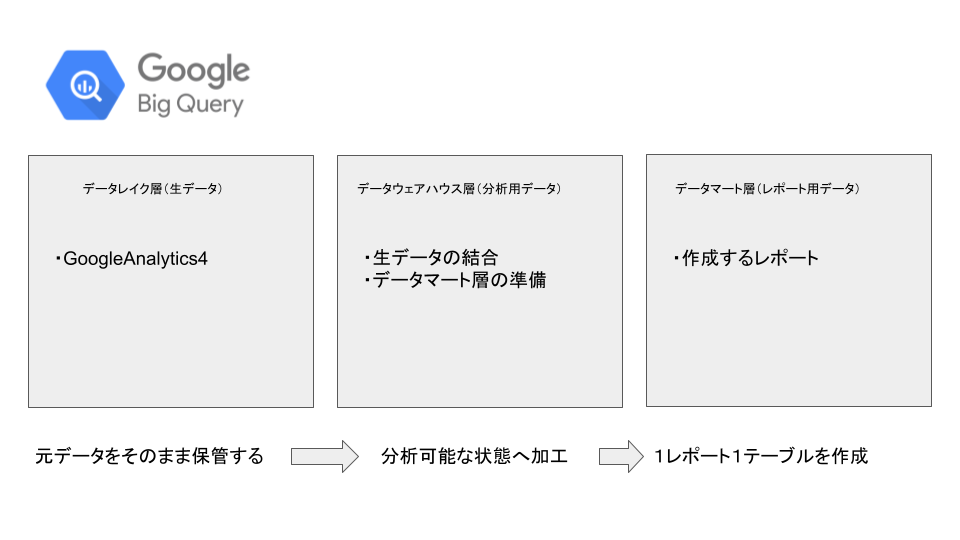
書籍や勉強会で登壇される方の発表を聞く中で、「データレイク」「データウェアハウス」「データマート」の3層構造を構築するという考えを知りました。
BQ内をさらに3つに分けてGA4の生データを少しずつレポート用に適切な状態へ変換するという方法です。
ここで重要なのは、データレイクに 元データをそのまま保管する ということです。
とにかく元データを生の状態で保持しておくことで、分析/レポート用データを何度でも違う形式に作り直すことが可能です。
今回扱うのはGA4のデータだけですが、生データにはCSVやDBの情報、ログなど様々なデータを集めておくことで、組み合わせた分析が可能になります。
また、データウェアハウスでは、分析用に生データを整形しておくことで、分析者が幅広い内容からの分析を行うことができます。
この時点でデータ品質のテストなどを行うことで、以降のデータマート層の品質を担保するのが良いのだと思います。
データマートの価値は、レポートごとに適切な形式で出力できることにあると思います。
定型的なものはをシステムによって出力することで、誰でも閲覧可能な状態にしておくことができます。
個々で計算を行うことで発生する数値の違いもなくなり、全ての人が同じ数字を参照することができます。
私は3層を用意して、段階的に加工することでそれぞれの目的に合わせた構造を作成できるという利点があると思います。
BigQueryにウェアハウス層とマート層を作る
では早速BQにウェアハウス層とマート層を作りたいと思います。
(※前提としてGA4のデータがBQにエクスポートされていることを前提としています)
まず、ウェアハウス用とマート用に新しいデータセットを作成しました。
| レイヤー | データセット名 |
|---|---|
| ウェアハウス層 | staging_{プロジェク名} |
| マート層 | mart_{プロジェクト名} |
| レイク層 | source_{プロジェクト名} |
レイク層は、ひとまずGA4からエクスポートされるデータセットを利用します。
(※注意点として、元データを毎回フルスキャンするため、データ量&集計期間の増加とコスト増加が比例します)
一例としてGA4page_viewイベントのウェアハウスをBQのクエリから作成したいと思います。
パーティション分割については割愛しますが、以下のドキュメントなどを参照ください。
-- {PROJECT_ID}はGoogleCloudのプロジェクトIDです
CREATE OR REPLACE TABLE `{PROJECT_ID}.staging_{プロジェクト名}.page_view`
PARTITION BY event_date AS
(SELECT
event_name,
CAST(event_date AS DATE FORMAT 'YYYYMMDD') AS event_date,
event_timestamp,
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location') AS page_location,
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_referrer') AS page_referrer,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id,
user_pseudo_id,
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'source') AS source,
device.category AS device_category,
device.mobile_model_name AS device_mobile_model_name,
device.operating_system_version AS device_operating_system_version,
device.web_info.browser AS device_web_info_browser
FROM `{PROJECT_ID}.analytics_000000000.*`
WHERE event_name = 'page_view')
カスタムパラメータも event_paramsに格納されているので、必要なものを取り出すと良いと思います。
テーブル作成は CREATE OR REPLACE として、毎回新しいテーブルを作りなおすようにしています。
(冪等性が大事という話を聞いたので、元データが変わっていない限り同じ結果となることを意識しました。)
私は、現時点では、page_view click などイベントごとにテーブルを作成しています。
マート層では、これらのウェアハウス層のテーブルを参照し、必要なものを組み合わせたり、絞り込んで作成しています。
それぞれ、BQでクエリを作成し保存することで、ウェアハウス層 → マート層の順に手動でテーブルの作成/更新を行えるようになります。
ファーストステップとしては十分かもしれませんが、やはり更新の度に複数のクエリを順に実行していくのは手間です。
そこで、もう少し簡単にボタン1つでウェアハウス層からマート層の構築を順に実行したいと考えました。
DataformでBigQueryのテーブルを更新する
調べていると色々と方法があるようでしたが、私の要件としては以下を検討しました。
- BQのクエリ実行が行えること
- テーブル間の依存関係(ウェアハウス→マート)を考慮した順に実行されること
- できればコストを最小限に抑えたい
これらの要件を満たすものとして、Dataform を利用することにしました。
利用料は無料です。(クエリ実行はBQへ加算されます)
設定については、以下のドキュメントを参考にしました。
(私の作成時点ではリージョンに東京がなかったため、asia-east1 を設定しました)
まずBQのデータセットへのアクセスを行うために、dataform.json のデフォルトロケーションをBQのデータセットのロケーションに合わせ変更しておきます。
(sqlxごとにロケーションの設定も可能ですが、おおよそ複数ロケーションを利用しているケースは少ないと想像します)
{
...
- "defaultLocation": "asia-east1"
+ "defaultLocation": {BQデータセットのロケーション}
}
私は、/definitions 配下に /staging と /mart というディレクトリを作成し、それぞれに必要な .sqlxファイルを作成しました。
ファーストステップは先程の page_view テーブル作成を例にします。
.sqlx ファイルは上部に config を記載し、下部にSQL を記載するようになっています。
私はとりあえず動いてほしかったので、configを type: "operations" としてカスタムSQLを利用して動作の検証を行いました。
先程BQに作成したクエリをコピーして、貼り付けると動くと思います。
config { type: "operations" }
-- 以下にBQのクエリをそのままコピー
動作が確認できたら、Dataformに従って書き換えます。
SELECT文の出力をconfigに設定したテーブルへ流しているイメージです。
(詳しくはコンパイルされたSQLを見ると良いと思います)
同様にウェアハウス層のクエリを作成していきます。
config {
type: "table",
schema: "staging_{プロジェクト名}",
name: "page_view",
bigquery: {
partitionBy: "event_date",
}
}
-- 以下は、BQクエリにあるSELECT文をそのままコピーします
次に、マート層のクエリを作成します。
ポイントは1つで、依存先(作成元となるテーブル)を ${ref("page_view")} のように設定します。
これでパイプラインとして依存するテーブルの処理が完了してから実行されるようになります。
COMPILED GRAPH を確認すると、元のテーブルから作成するテーブルへ線が繋がっていると思います。
config {
-- 省略します。おおよそ同じです。
}
SELECT
event_date,
device_category,
FROM ${ref("page_view")}
WHERE
...;
DataformをGithubで管理する
DataformはGithub(Gitlab)と接続して作成したパイプラインのバージョン管理を行うことができます。
ブランチを切って開発を行い、PullRequestの作成、レビュー、mainへのマージというフローを行えます。
(mainブランチでなく、開発用ブランチでもパイプラインの実行は行なえます)
まず事前対応としてGithubにDataformを管理するためのリポジトリとpersonal access tokenを作成しておきます。
上記のドキュメントを参考に、IAMのロール設定を行い、作成しておいたpersonal access tokenをGoogleCloudのSecret Managerに追加します。
IAMの権限が適切に設定されていれば、GithubへのPushが行えると思います。
(※作成した開発ワークスペース名がgitのブランチ名になります)
ボタン1つで、BQのテーブル情報が更新されるようになりました。
次に、私が取り組みたいと思ったのは、Slackへの通知です。
処理結果をSlackへ通知することで、正常に処理が完了したか、何らかの異常が発生し対応が必要であるかSlackから把握したいと思いました。
WorkflowsからDataformを実行する
DataformにはSlackへの通知機能がない(と思われる)ので、別のサービスを組み合わせて実現することにしました。
私が選択したのは、Workflows というサービスです。
採用理由は、現時点の見積もりは無料枠内で利用できそうな点と最後に取り上げますがスケジュール実行を行える点から利用を決めました。
Workflowsを利用するにあたっては、サービスアカウントの作成とロールを追加する必要があります(省略します)
上記ドキュメントの例をコピーして貼り付けます。
PROJECT_ID REPOSITORY_LOCATION REPOSITORY_ID GIT_COMMITISH を自身の環境に置き換えます。
これでWorkflowsからDataformが実行できるようになりました。
main:
steps:
- init:
assign:
- repository: projects/PROJECT_ID/locations/REPOSITORY_LOCATION/repositories/REPOSITORY_ID
- createCompilationResult:
call: http.post
args:
url: ${"https://dataform.googleapis.com/v1beta1/" + repository + "/compilationResults"}
auth:
type: OAuth2
body:
gitCommitish: GIT_COMMITISH
result: compilationResult
- createWorkflowInvocation:
call: http.post
args:
url: ${"https://dataform.googleapis.com/v1beta1/" + repository + "/workflowInvocations"}
auth:
type: OAuth2
body:
compilationResult: ${compilationResult.body.name}
result: workflowInvocation
- complete:
return: ${workflowInvocation.body.name}
WorkflowsにSlackへの通知を追加する
追加してみたものの、完了通知としては不十分
Slackへの通知はSlackの Incoming Webhookを利用しました。
事前にSlack APIの作成を行い、Incoming Webhookを有効にしてURLを取得します。
下記ドキュメントにありますが、秘密にしなさいとのことなので、GoogleCloudのSecret Managerに追加しておきます。
Keep it secret, keep it safe. Your webhook URL contains a secret. Don't share it online, including via public version control repositories. Slack actively searches out and revokes leaked secrets.
createWorkflowInvocation と complete のステップの間にSlackへの通知(とシークレットからURLの取得)を追加します。
workflowInvocationにはPOSTリクエストのレスポンスとして以下のドキュメントの戻りがあります。
workflowInvocation.body.state とすることで実行の状態を確認することができます。
以下、上手く行きません。理由は後述します。
# 上手く行かないので、参考程度にしてください。
- createWorkflowInvocation:
call: http.post
args:
url: ${"https://dataform.googleapis.com/v1beta1/" + repository + "/workflowInvocations"}
auth:
type: OAuth2
body:
compilationResult: ${compilationResult.body.name}
result: workflowInvocation
# SecretからURLを取得し、slack_info_urlという変数へ格納
- accessSecretInfoUrl:
call: googleapis.secretmanager.v1.projects.secrets.versions.accessString
args:
secret_id: bq-pord-slack-webhook-url-info
project_id: ga-byoinnavi-bq-prod
result: slack_info_url
# POSTリクエストでSlackへメッセージを送信します。
- startSlackNoticeInfo:
call: http.post
args:
url: ${slack_info_url}
headers:
Content-type: application/json
body:
"blocks": [
{
"type": "header",
"text": {
"type": "plain_text",
"text": '${"State: " + workflowInvocation.body.state}'
}
},
]
- complete
Slackへ通知されるテキストの '${"State: " + workflowInvocation.body.state}' ですが、
通知された内容は State: RUNNING でした。。。
Enumとなっており、いくつかの状態があるのですが、私が欲しかったのは SUCCEEDED FAILED でした。
完了状態を通知したいので、根気強く待ってみた
Stateが RUNNING となっていましたが、それはそうで、Requestした時点で実行が開始されるため、その時点のResponseは実行中です。
では、実行完了をどのように把握しようかというのが問題です。
(以下、自身で考えて解決しましたが、良い方法があれば教えて頂けると幸いです。)
参考にした考えは、「ポーリングを使用して待機する」というものです。
(※無限ループには、十分に注意してください)
実行を開始したら、とりあえず待ってみて、Dataform のGETリクエストを利用して、実行状態を再度、取得します。
このとき、POSTのレスポンスからbody.name とすることで GETリクエスト先を取得できます。
- createWorkflowInvocation:
call: http.post
args:
url: ${"https://dataform.googleapis.com/v1beta1/" + repository + "/workflowInvocations"}
auth:
type: OAuth2
body:
compilationResult: ${compilationResult.body.name}
result: runWorkflowInvocation
# 実行を開始したら、とりあえず待ちます
- waitResponse:
call: sys.sleep
args:
seconds: 30
# 待ったら、実行状態を確認します
- getWorkflowInvocation:
call: http.get
args:
url: ${"https://dataform.googleapis.com/v1beta1/" + runWorkflowInvocation.body.name}
auth:
type: OAuth2
result: workflowInvocation
# 実行中であれば、上に戻って再び待ちます
- checkIfDone:
switch:
- condition: ${workflowInvocation.body.state == "RUNNING"}
next: waitResponse
# 実行中でなければ、以下でSlackへの通知を行います
これでDataformの実行結果を待ち、処理が正常に完了したか、異常が発生したかをSlackで把握することができます。
私は、上記 checkIfDone のステップの switch に条件を追加し、異常発生時にはError(異常系)のチャンネルにも通知するようにしています。
(Info/正常系のチャンネルには常に通知するようにしています)
CloudSchedulerでスケジュール実行を設定する
最後に、これまでに作成したパイプラインにスケジュールを設定して、定期的に自動実行するようにしたいと思います。
利用するのは、 Cloud Scheduler というサービスです。
無料枠もありますが、料金については以下のドキュメントを参照ください。
設定方法はシンプルで、Workflows の画面から、トリガー を選択します。
あとは、タイムゾーンと実行したいスケジュールを cron で設定します。
私は、現時点ではGA4データを週に1回更新するようにしており、毎週木曜日に更新するように設定しています。
なぜ、木曜日としているかは、以下のドキュメントからの私の理解ですが、72時間は更新される可能性があると考え、月~日のデータが完全に完了するのは72時間後の木曜日という理解で、木曜日に更新するようにしています。(あくまで私の認識です)
日次エクスポートのテーブル(events_YYYYMMDD)は、その日のイベントがすべて収集された後に作成されます。アナリティクスでは、テーブルの日付から最大 72 時間日次テーブルが更新されます。
まとめ / 今後やりたいこと
以上が、私が行った、基本的なデータ分析基盤の作成とパイプラインの構築となります。
これで、LookerStudioやコネクテッドシート(Googleスプレッドシート)を利用することで、SQLの利用が難しい分析者や非エンジニアの方がBQのデータを活用した分析を行えるようになると思います。
今後は、BQのテーブル作成におけるクエリコストの削減に取り組みたいと考えています。
また社内での対話を重ね、作成した分析基盤を活用したデータドリブンな文化を今以上に根付かせたいと思います。
長くなりましたが、最後まで読んで頂きありがとうございました。