はじめに
今回はデータベース設計について学び直したので内容をまとめていきます。
自分は2021年に新卒でWeb系の開発会社にフロントエンジニアとして入社し2022年で2年目になります。
実務ではNext.js×TypeScriptを利用したフロントの開発をメインで行っています。
直近の開発案件でRailsを使ったサーバーサイドの開発を担当することになり、DB設計を触ったのですが体系的な理解をしていなかったので苦戦をしました。
実装はできたものの、データベース設計を「なんとなくの理解」で終わらせないように、体系的に学び直しました。
データベース設計の学習に関しては下記の書籍を参考に進めました。
対象者
- データベース設計について基礎から学びたい人
- 何となくデータベースの設計をしている人
- 正規化について学びたい人
データベースとDBMS
データベースとはデータを整合的に保持しいつでも簡単に利用可能な状態にしておくためのシステムです。
またデータベースを管理するためのシステムをDBMS(data base management system)と呼びます。
リレーショナルデータベース(RDB)
RDBはデータベースの中で最も普及されているデータベースです。
RDBは二次元表の形式で管理されており、データの取り扱いを直感的に行うことができます。
| id | name | address |
|---|---|---|
| 1 | 山田 | 東京都 |
| 2 | 鈴木 | 大阪 |
| 3 | 長谷川 | 名古屋 |
システム開発について
そもそもデータベース設計と呼ばれる工程がシステム開発全体においてどの位置にあるのかを確認します。
システム開発の工程は
- 要件定義 (システムが満たす機能やサービスの要件を決める)
- 設計 (定義された要件を満たすための設計)
- 開発 (設計書に沿って実際に開発)
- テスト (実装後に本当に実用できるかをテスト)
- 保守・運用(開発したものを運用する)
といったステップで進められます。
データベース設計は上記の2の工程に含まれています。
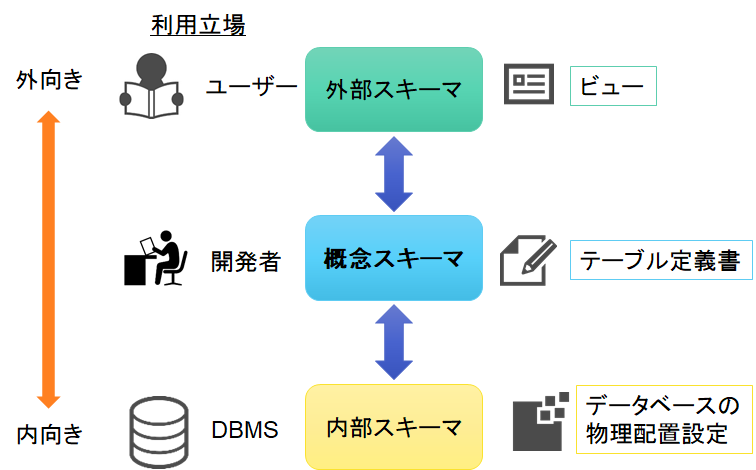
3層スキーマ
データベース設計をする上で重要な概念であるスキーマについて解説します。
そもそもスキーマとはデータ構造やデータベースを操作する際のルールや表現法を定義したもので、データベースの設計図です。
またスキーマは三層スキーマアーキテクチャーという三つのレベルに分けられています。
三層スキーマは
- 外部スキーマ
- 概念スキーマ
- 内部スキーマ
に分類されています。
引用: https://itmanabi.com/db-schema/
外部スキーマ
外部スキーマとはユーザーやアプリ側からみたデータベースの構造を定義するスキーマです。
データのビューや出力などを意味し、ビューを変更してもデータ構造は変わりません。
| id | name | age | address |
|---|---|---|---|
| 1 | 高橋 | 24 | 東京都 |
| 2 | 中島 | 18 | 千葉県 |
| 3 | 伊藤 | 39 | 埼玉県 |
| 4 | 大橋 | 12 | 茨城県 |
| 5 | 中島 | 25 | 千葉県 |
概念スキーマ
概念スキーマは開発者から見たデータベースです。概念スキーマを定義する設計を論理設計とも呼びます。
具体的にはデータの要素やデータ同士の関係を定義します。データベースにテーブルを作成するための設計図です。
内部スキーマ
概念スキーマで定義されたデータを具体的にどのようにDBMS内部に格納するかを定義します。ハードウェア的な変更もここで吸収されます。
3層に分ける理由
そもそもなぜ3層に分けるのかを疑問に思った方もいるかもしれません。
3層に分ける理由は、各スキーマにおいて変更があったとして他の2つには影響が起きないからです。
仕様変更が起きた際に都度データベース全体に影響があると時間が大幅にかかってしまいます。
3層スキーマでデータベースの設計をすることでビューやハードウェアを変更せずにデータベースの保守・運用をすることができます。
論理設計と物理設計
論理設計のステップ
論理設計とは先ほど紹介した概念スキーマを定義する設計です。論理設計は物理層(CPUやストレージ等)の制約にとらわれない特徴があります。
論理設計を進めていく中で物理層の制約は一旦脇に置いておきます。
これらの前提のもとで論理設計を下記のステップで進めていきます。
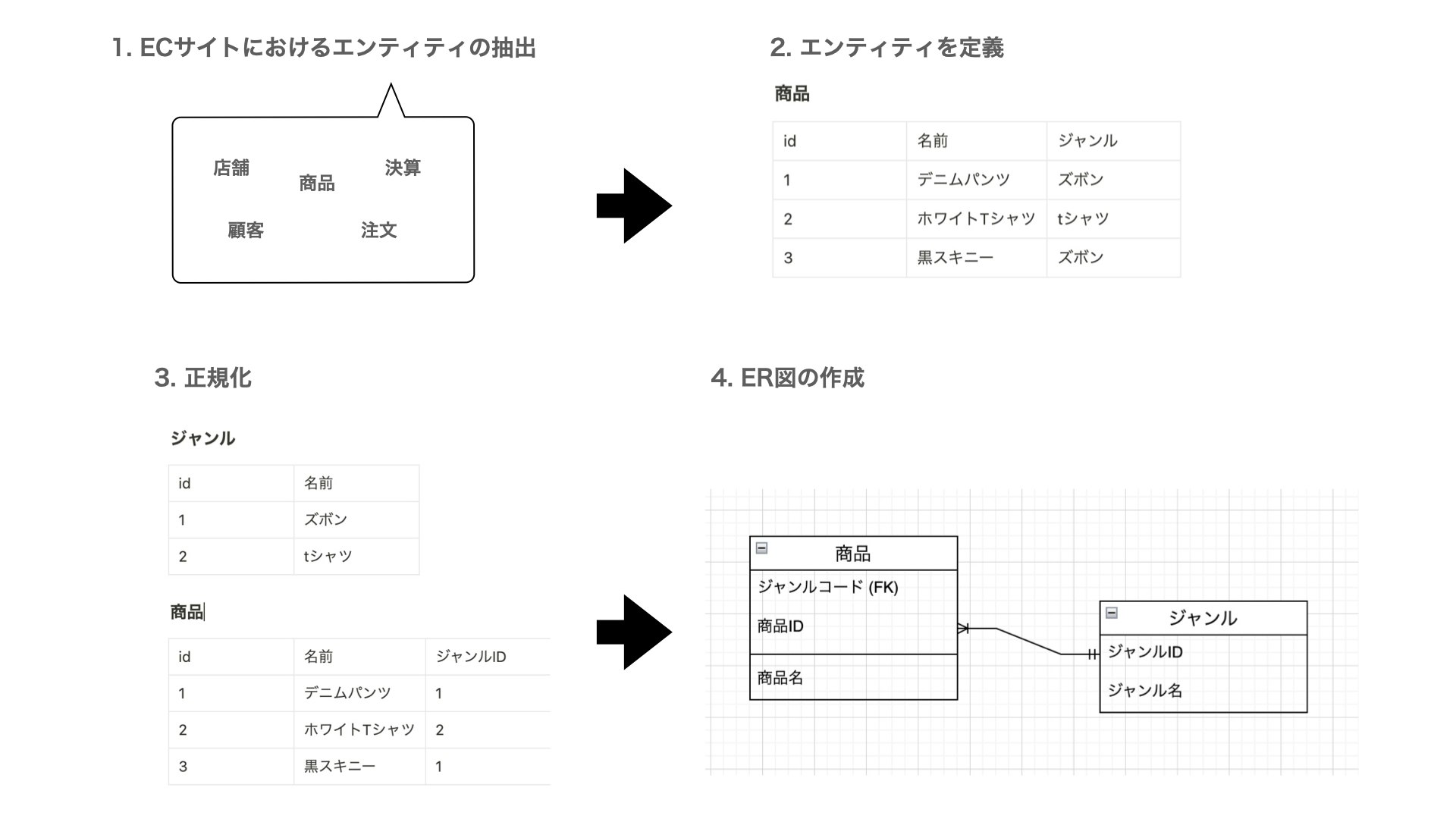
- エンティティの抽出
- エンティティの定義
- 正規化
- ER図の作成
エンティティの抽出
エンティティとは実体を表します。
具体的にECサイトにおけるエンティティは「店舗」「商品」「顧客」「注文」「決済」などがあります。
実際に開発するシステムにおいて必要なエンティティを抽出するのがエンティティの抽出のステップになります。
エンティティの定義
次に抽出エンティティがどのようなデータを保持するかを決定していきます。
エンティティが持つデータを属性(attribute)と呼びます。
テーブルでいう列の部分が属性に当たります。
店舗というエンティティはid,name,feeという属性(attribute)を持っているので列を下記のように定義します。
【店舗】
| id | name | fee |
|---|---|---|
| 1 | ユニクロ | 300 |
| 2 | しまむら | 200 |
| 3 | ZARA | 500 |
商品というエンティティはid,name,priceという属性(attribute)を持っているので下記のように列を定義します。
【商品】
| id | name | price |
|---|---|---|
| 1 | Tシャツ | 1000 |
| 2 | スキニー | 200 |
| 3 | コーチジャケット | 500 |
顧客というエンティティはid,name,address, emailという属性(attribute)を持っているので下記のように列を定義します。
【顧客】
| id | name | address | |
|---|---|---|---|
| 1 | 内藤 | 東京都 | naito@com |
| 2 | 鈴木 | 千葉 | suzuki@com |
| 3 | 五十嵐 | 埼玉 | igarashi@com |
ここまででエンティティの抽出及びエンティティの定義が完了しました。
正規化
次に正規化をおこないます。正規化はエンティティ(テーブル)がデータを扱いやすようにするための設計です。
正規化をすることでデータの冗長性や不整合が発生する機会を減らすことができます。
正規化についてはこの後の章で詳しく解説をします。
ER図の作成
ER図はエンティティ同士の関係を表現するための図です。
論理設計まとめ
概念スキーマを定義する論理設計は下記の手順で進めていきます。
- エンティティの抽出
- エンティティの定義
- 正規化
- ER図の作成
論理設計のステップをECサイトをサンプルとた図でイメージすると下記のようになります。
物理設計のステップ
次に論理設計で決まったデータを格納するための物理的な領域の格納方法を決める物理設計について解説をしていきます。
- テーブル定義
- インデックス定義
- ハードウェアのサイジング
- ストレージの冗長構成
- ファイルの物理的配置
テーブルの定義
テーブル定義では論理設計で定義された概念スキーマを元に、それらを格納するためのテーブルの単位に変換していきます。
このフェーズで作成されるモデルを物理モデルと呼びます。
インデックス定義
インデックス(索引)を付与することで非機能部分であるパフォーマンスを向上させることができます。
インデックスを参照することで目的のデータが格納されている位置に直接アクセスすることができ、検索を高速化することができます。
ハードウェアのサイジング
システムに対するデータを見積りストレージを選定します。
キャパシティーとパフォーマンスの観点から選定をしていきます。
そもそもデータベースは整合性を高くしようとするとパフォーマンスが犠牲になり、パフォーマンスを追及すると整合性を犠牲にする必要があるトレードオフの関係を持っています。
ハードウェアのサイジングをするにあたっては下記の入力情報が必要です。
- システムで利用するデータ量
- サービス終了時のデータの増加率
しかし実際はサービス終了時のデータ量を正確に見積もるのは難しい場合もあります。
データ量が増加することを想定し、スケーラビリティー(拡張性)が高い構成にする。
ストレージの冗長構成
ストレージの冗長構成は、ストレージが障害で利用できなくなった場合を想定し、迅速に復旧させるべく予備を配置しストレージを多重構成にしておくことを意味しています。
具体的にはRAID(レイド)を利用してデータを冗長化させます。
RAIDについての詳しい解説はここでは省くので気になった方はこちらを参考にしてみてください。
ファイルの物理配置
冗長構成が決まったら最後にデータベースファイルをどのディスクに配置するかを決定します。
データベースに格納されるファイルは以下の5種類に分類できる
- データファイル: ユーザーがデータベースに格納するデータを保持するファイル
- インデックスファイル: テーブルに作成されたインデックスが格納される
- システムファイル: DBMSの内部管理に使われるデータを管理する
- 一時ファイル: 一時的なデータの格納。GROUP BY等を利用した時のソートデータ
- ログファイル: テーブルに対するデータ変更の一時格納ファイル
このうち開発者はデータファイルとインデックスファイルを意識する必要があります。
バックアップ設計
障害等によってデータが失われた時に、復旧できるような設計をバックアップ設計によって行います。
主要バックアップは下記の3種類になります。
- フルバックアップ
- 差分バックアップ
- 増分バックアップ
フルバックアップ
名前の通り、バックアップを取る地点で保持されているデータを全てバックアップする方式です。
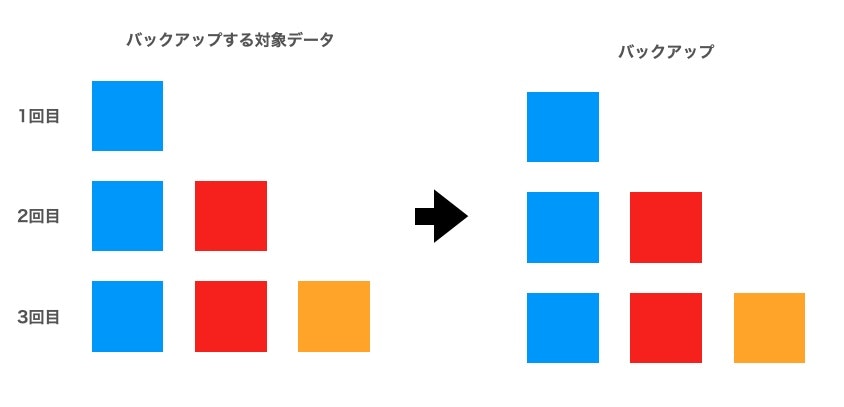
フルバックは非常にシンプルである一方で欠点もあります。
- バックアップ時間が長い
- ハードウェアリソースへの負荷が高い
- サービスの停止が必要
差分バックアップ
1回目のデータのみフルバックアップし、そこからは差分だけをバックアップしていく。
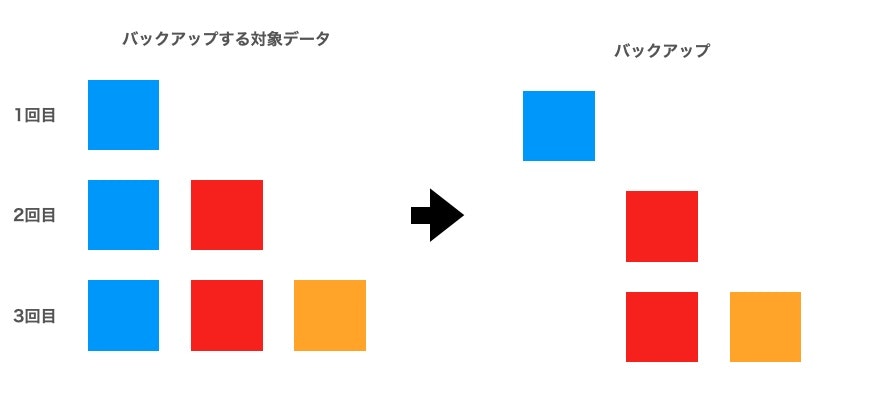
もし3回目の翌日に障害が発生しデータが失われた場合は、1回目と3回目のファイルがあれば復旧させることができます。
増分バックアップ
差分バックアップの冗長性を省いたものが増分バックアップになっています。
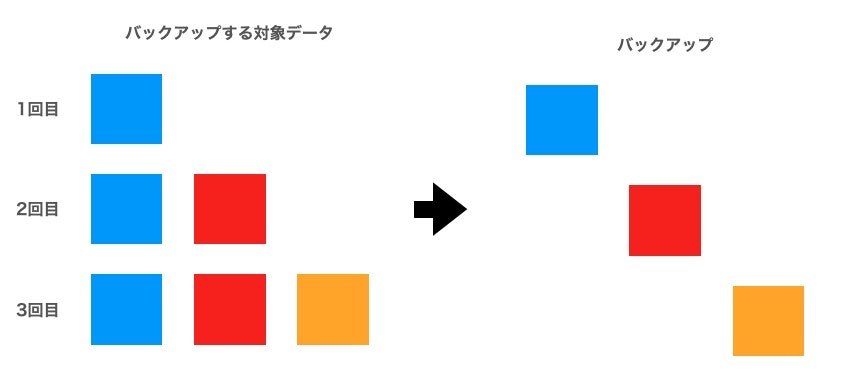
増分バックアップは3つの方式のうちで一番データ量が最小になる一方で、リカバリ手順が最も複雑になるという欠点もあります。
以上より紹介した3つのバックアップ方式においてはどれもトレードオフの関係になっているのがわかります。
フルバックアップはバックアップのデータ量のコストは高くなる一方で障害時の復旧は容易に行うことができます。一方で増分バックアップはバックアップのデータ量のコストは小さくなる一方で、障害時の復旧は複雑になります。
どのバックアップを採用すべきか
結論としてはそれぞれの利点と欠点を比較検討し、システムの特性に応じて選択する。
抑えるべきポイントとしては
- 復旧の必要はそもそもあるのか
- バックアップにかけることができる時間
- 復旧にかけることができる時間
- 何世代までのデータを残す必要があるのか
という点をサービスに応じて考慮し適切なバックアップ方式を選択します。
達人DBでは採用が多い方式として下記の2パターンが挙げられています。
- フルバックアップ+差分バックアップ
- フルバックアップ+増分バックアップ
ここまでで論理設計と物理設計の大まかな流れの解説が終わりました。次の章では論理設計における正規化について詳しく解説をしていきます。
論理設計と正規化
テーブルの構成要素
そもそもテーブルの構成は行にレコード、列に属性を持っています。
| id | name | age |
|---|---|---|
| 1 | 高橋 | 24 |
| 2 | 鈴木 | 21 |
| 3 | 伊藤 | 39 |
キーについて
データベースにおけるキーは下記の2つがあります。
- 主キー
- 外部キー
主キーはプライマリキーと呼ばれテーブルに必ず1つは必要な存在であり、主キーを指定することで必ず1行のレコードを特定できます。
先程のテーブルにおいてはidが主キーになっていることがわかります。
| id | name | age |
|---|---|---|
| 1 | 高橋 | 24 |
| 2 | 鈴木 | 21 |
| 3 | 伊藤 | 39 |
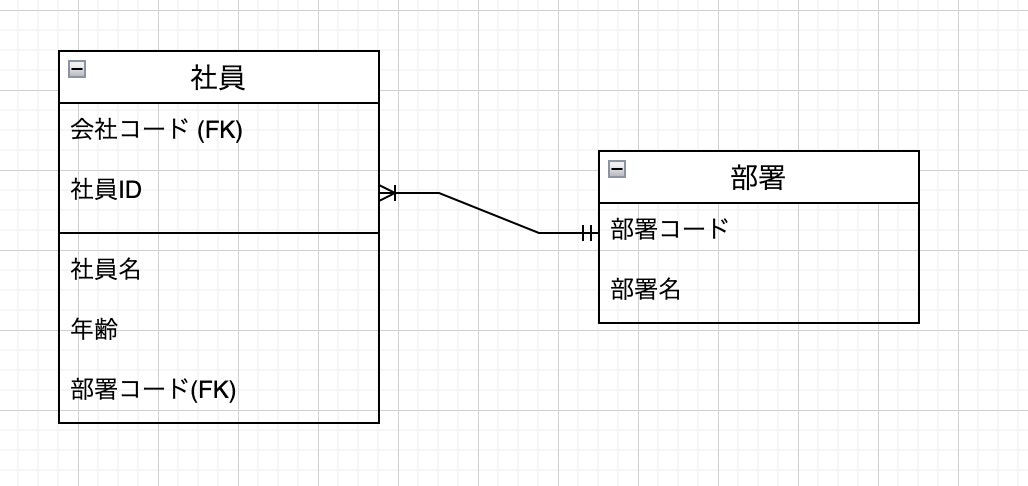
主キーの次に重要なキーとして外部キーがあります。
外部キーは2つのテーブル間の列同士で設定するものなっています。
例えば下記の場合は社員テーブルにあるdepartment_idが外部キーになっています。
部署テーブル
| id | department |
|---|---|
| 1 | 営業 |
| 2 | 人事 |
| 3 | 広報 |
社員テーブル
| id | name | age | department_id |
|---|---|---|---|
| 1 | 高橋 | 20 | 1 |
| 2 | 鈴木 | 24 | 3 |
| 3 | 伊藤 | 18 | 2 |
| 4 | 鈴木 | 30 | 2 |
| 5 | 中島 | 35 | 3 |
外部キーを設定することで社員テーブルに対して参照制約をつけることができます。
参照制約をつけることで存在しない部署IDを登録することを防げます。
制約について
先ほど紹介した参照制約以外のテーブルに付与できる制約を紹介します。
- NOT NULL制約
- 一意制約
- CHECK制約
NOT NULL制約
NOT NULL制約を付与することで下記のように列において空欄が発生することを防ぎます。NOT NULL制約は列単位で指定することができます。
SQLを扱う上でNULLは厄介者になる可能性があるのでテーブル定義の際は可能な限りNOT NULL制約をつけることが好ましいとされています。
| id | name | age |
|---|---|---|
| 1 | 高橋 | 24 |
| 2 | 21 | |
| 3 | 伊藤 | 39 |
| 4 | 32 | |
| 5 | 中島 | 25 |
一意制約
ある列について一意性を求める制約になっています。
例えば会員登録サイトにおけるメールアドレスの重複などを防ぐ時に利用します。
下記の場合がid2の鈴木さんとid4の鈴木さんのメールアドレスが重複しています。
| id | name | |
|---|---|---|
| 1 | 高橋 | takashi@com |
| 2 | 鈴木 | suzuki@com |
| 3 | 伊藤 | itou@com |
| 4 | 鈴木 | suzuki@com |
| 5 | 中島 | nakazima |
CHECK制約
ある列のとりうる値の範囲を指定する制約です。
例えば年齢制限が20歳以上の場合などを付けたい場合にこの制約を使います。
下記のように20歳未満の人がデータに入ってきてしまうことを防ぐことができます。
| id | name | age |
|---|---|---|
| 1 | 高橋 | 24 |
| 2 | 中島 | 18 |
| 3 | 伊藤 | 39 |
| 4 | 大橋 | 5 |
| 5 | 中島 | 25 |
正規化について
正規化とはデータベースで保持するデータの冗長性を排除し、一貫性と効率性を保持するためのデータ形式と定義されています。
正規化によって、一つの情報が複数のテーブルに存在して無駄な領域や更新処理を発生させることを防ぐことができます。(冗長性)
最初は第一正規化から第三正規化まで理解すれば大丈夫です。
第一正規化
第一正規化では下記のように1つのレコードに複数の値が入ってしまっているもの排除し、1つのセルには1つの値だけが含まれるようにします。
第一正規化前
| name | age | department |
|---|---|---|
| 高橋 | 20 | 営業 |
| 鈴木 | 24 | 人事 広報 |
| 伊藤 | 18 | 開発 広報 |
| 鈴木 | 30 | 事務 |
| 中島 | 35 | 営業 |
第一正規化後
| name | age | department |
|---|---|---|
| 高橋 | 20 | 営業 |
| 鈴木 | 24 | 人事 |
| 鈴木 | 24 | 広報 |
| 伊藤 | 18 | 開発 |
| 伊藤 | 18 | 広報 |
| 鈴木 | 30 | 事務 |
| 中島 | 35 | 営業 |
第二正規化
第二正規化をするために関数従属と部分関数従属という言葉を理解する必要があります。
関数従属とはその名の通りY=f(X)と同じでXを決めれば出力Yが決まるものを指します。
テーブルにおいて言い換えると、ある列Xの値が決まれば列Yの値も決まることを意味しています。
例えば下記のテーブルにおいて、社員IDが決まれば社員名が決まります。
| 社員ID | 社員名 | 部署 |
|---|---|---|
| 1 | 高橋 | 開発 |
| 2 | 鈴木 | 営業 |
| 3 | 鈴木 | 人事 |
| 4 | 伊藤 | 広報 |
この時、社員IDと社員名には関数従属関係が成立しています。
下記のテーブルにおいて第二正規化を進めていきます。
第二正規化前
| 会社コード | 会社名 | 社員ID | 社員名 | 年齢 | 部署コード | 部署名 |
|---|---|---|---|---|---|---|
| C0001 | A銀行 | 000A | 中島 | 40 | D01 | 開発 |
| C0001 | A銀行 | 000B | 鈴木 | 32 | D02 | 人事 |
| C0001 | A銀行 | 000F | 高橋 | 45 | D03 | 営業 |
| C0002 | B商事 | 000A | 小泉 | 50 | D03 | 営業 |
| C0002 | B商事 | 009F | 加藤 | 23 | D01 | 開発 |
| C0002 | B商事 | 010A | 増田 | 31 | D04 | 総務 |
こちらのテーブルでは第一正規化は満たされています。
このテーブルにおける主キーは{会社コード, 社員ID}になっており、この2つのキーがわかれば値を特定することができます。
(例) 会社コードC0001で社員IDが000Fは「高橋さん、42歳、営業部署」とわかる。
また会社名に関しては、社員IDがわからなくても会社コードがわかれば特定することができます。
このように主キー(今回でいう{会社コード, 社員ID})の一部の列に対して従属する列がある場合に、この関係を部分関数従属と呼びます。
つまり主キー(今回でいう{会社コード, 社員ID})の一部({会社コード})がわかれば会社名が特定できる{会社コード}→{会社名}が成り立つので、これらは部分関数従属の関係にあることがわかります。
第二正規化では、テーブル内の部分関数従属を解消し、完全関数従属のみのテーブルを作ることをしていきます。
第二正規化後
【社員テーブル】
| 会社コード | 社員ID | 社員名 | 年齢 | 部署コード | 部署名 |
|---|---|---|---|---|---|
| C0001 | 000A | 中島 | 40 | D01 | 開発 |
| C0001 | 000B | 鈴木 | 32 | D02 | 人事 |
| C0001 | 000F | 高橋 | 45 | D03 | 営業 |
| C0002 | 000A | 小泉 | 50 | D03 | 営業 |
| C0002 | 009F | 加藤 | 23 | D01 | 開発 |
| C0002 | 010A | 増田 | 31 | D04 | 総務 |
【会社テーブル】
| 会社コード | 会社名 |
|---|---|
| C0001 | A銀行 |
| C0002 | B商事 |
第二正規化によって、社員テーブルは主キーである{会社コード, 社員ID}がわかれば、値が特定できる完全関数従属にすることができました。
また第二正規化をしなかった場合、下記のように同じ会社コードに対して異なる会社名が入ってきてしまう可能性がありますが、第二正規化をすることでこのようなミスを防ぐことができます。
| 会社コード | 会社名 | 社員ID | 社員名 | 年齢 | 部署コード | 部署名 |
|---|---|---|---|---|---|---|
| C0001 | A銀行 | 000A | 中島 | 40 | D01 | 開発 |
| C0001 | A商事 | 000B | 鈴木 | 32 | D02 | 人事 |
第三正規化
第三正規化をする上で推移的関数従属という言葉を知る必要があります。
推移的関数従属とはAが決まるとBが決まる。Bが決まるとCが決まる。ゆえにAが決まるとCも決まるといった推移的な関係を持つものです。
先程、第二正規化した下記のテーブルで確認してみます。
【社員テーブル】
| 会社コード | 社員ID | 社員名 | 年齢 | 部署コード | 部署名 |
|---|---|---|---|---|---|
| C0001 | 000A | 中島 | 40 | D01 | 開発 |
| C0001 | 000B | 鈴木 | 32 | D02 | 人事 |
| C0001 | 000F | 高橋 | 45 | D03 | 営業 |
| C0002 | 000A | 小泉 | 50 | D03 | 営業 |
| C002 | 009F | 加藤 | 23 | D01 | 開発 |
| C002 | 010A | 増田 | 31 | D04 | 総務 |
【会社テーブル】
| 会社コード | 会社名 |
|---|---|
| C0001 | A銀行 |
| C0002 | B商事 |
社員テーブルにおいて{部署コード}→{部署名}とういう関数従属が成り立っていることがわかります。
また主キーである{会社コード, 社員ID}は、{会社コード, 社員ID}→{部署コード}という関数従属が存在しています。
以上より
{会社コード, 社員ID} → {部署コード} → {部署名}という推移的関数従属が成り立っていることがわかります。
第三正規化後
【部署テーブル】
| 部署コード | 部署名 |
|---|---|
| D01 | 開発 |
| D02 | 人事 |
| D03 | 営業 |
| D04 | 総務 |
【会社テーブル】
| 会社コード | 会社名 |
|---|---|
| C0001 | A銀行 |
| C0002 | B商事 |
【社員テーブル】
| 会社コード | 社員ID | 社員名 | 年齢 | 部署コード |
|---|---|---|---|---|
| C0001 | 000A | 中島 | 40 | D01 |
| C0001 | 000B | 鈴木 | 32 | D02 |
| C0001 | 000F | 高橋 | 45 | D03 |
| C0002 | 000A | 小泉 | 50 | D03 |
| C002 | 009F | 加藤 | 23 | D01 |
| C002 | 010A | 増田 | 31 | D04 |
これによって第三正規化まで完了することができました。
ER図
テーブル(エンティティー)の数が増えていくとテーブル同士の関係の理解が難しくなります。
ER図を使うことでテーブル同士の関係を表現することができ、この問題を解決することができます。
リレーショナルデータベースは「1対1」「1対多」「多対多」に基本的に分解されます。
テーブルの関係性を洗い出す
まず先ほど作成した社員テーブル、会社テーブル、部署テーブルの関係をER図で表現していきます。
【部署テーブル】
| 部署コード | 部署名 |
|---|---|
| D01 | 開発 |
| D02 | 人事 |
| D03 | 営業 |
| D04 | 総務 |
【会社テーブル】
| 会社コード | 会社名 |
|---|---|
| C0001 | A銀行 |
| C0002 | B商事 |
| C0003 | C建設 |
【社員テーブル】
| 会社コード | 社員ID | 社員名 | 年齢 | 部署コード |
|---|---|---|---|---|
| C0001 | 000A | 中島 | 40 | D01 |
| C0001 | 000B | 鈴木 | 32 | D02 |
| C0001 | 000F | 高橋 | 45 | D03 |
| C0002 | 000A | 小泉 | 50 | D03 |
| C002 | 009F | 加藤 | 23 | D01 |
| C002 | 010A | 増田 | 31 | D04 |
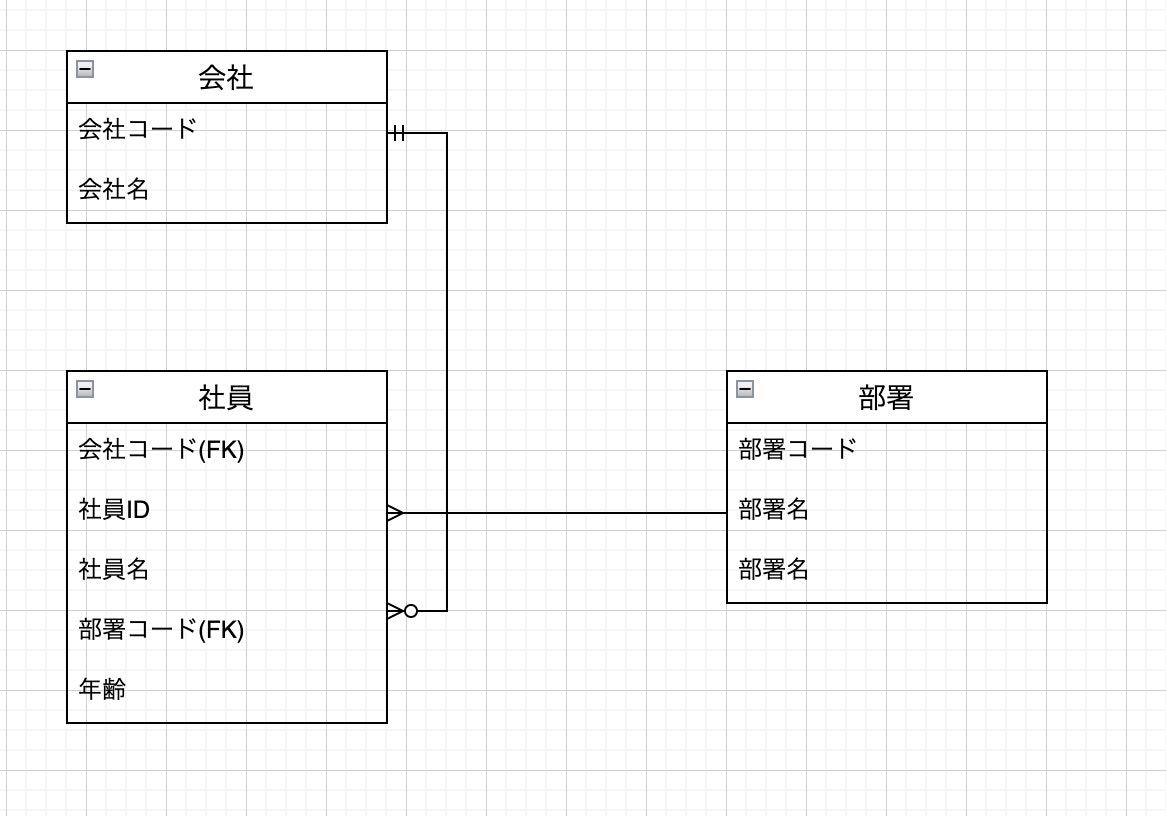
まず社員テーブルと会社テーブルにおいては下記の関係が成り立ちます。
- 会社は社員を複数人持っている(会社を主語)
- 社員は1つの会社に属している(社員を主語)
以上の関係から会社と社員は「1対多」の関係があることがわかります。
また会社テーブルのC建設に属している社員は社員テーブルを見るといないことがわかります。
より厳密にこれを表現すると「会社は0~n人の社員が属している」と言えます。(後でER図で表現)
もう一つの部署テーブルについてみていきます。
- 部署は複数の社員を持っている(部署が主語)
- 社員は一つの部署に属している(社員が主語)
以上の関係から部署と社員は「1対多」の関係があることがわかります。
実際にER図で表すと下記のようになります。
またER図を書く際自分はdraw.ioを使っています。
正規化によるパフォーマンスについて
正規化をすることでSQL文の中で結合(JOIN)が必要になり処理コストが高くなる。結果として正規化はSQLの速度が悪化するという欠点を持っている。
正規化はデータの整合性を高める一方で、検索パフォーマンスを低下させるというトレードオフの関係を持っています。
冗長性とパフォーマンスのトレードオフ
- 非正規化は検索パフォーマンスを向上させるが更新パフォーマンスを低下させる
- データのリアルタイム性を低下させる
- 設計変更をすると出戻りが多い
論理設計のアンチパターン
最後に論理設計においてやってはいけない(アンチパターン)の設計を解説していきます。
配列型
1999年のSQLの世界共通標準規格にて盛り込まれた「配列型」は利用せず、第一正規化を守るようにする。(それほど普及はされずに終わった)
配列型を利用することで下記のように複数のデータが入ることを可能にしてしまい整合性が取れなくなる。
| 社員ID | 社員名 | 部署 |
|---|---|---|
| 001 | 鈴木 | 開発 人事 |
| 002 | 加藤 | マーケティング |
| 003 | 磯野 | 広報 |
| 004 | 中島 | 営業 広報 |
単一参照テーブル
先ほど第三正規化で作成した下記のテーブルにおいて会社と部署のテーブル構成が同じなので2つのテーブルを1つにまとめることが可能です。
【部署テーブル】
| 部署コード | 部署名 |
|---|---|
| D01 | 開発 |
| D02 | 人事 |
| D03 | 営業 |
| D04 | 総務 |
【会社テーブル】
| 会社コード | 会社名 |
|---|---|
| C0001 | A銀行 |
| C0002 | B商事 |
| C0003 | C建設 |
【単一参照テーブル(2つをまとめる)】
| コードタイプ | コード値 | コード内容 |
|---|---|---|
| company | C0001 | A銀行 |
| company | C0002 | B商事 |
| company | C0003 | C建設 |
| department | D01 | 開発 |
| department | D02 | 人事 |
| department | D03 | 営業 |
| department | D04 | 総務 |
単一参照テーブルの利点
- テーブル数が減るのでER図がシンプルになる
- コード検索のSQLを共通化できる
単一参照テーブルの欠点
- 全ての列において可変長文字列型で宣言する必要がある
- レコード数が多くなり検索パフォーマンスが悪化する
- ER図はすっきりする一方で可読性が落ちる
以上のように複数テーブルを1つにまとめる単一参照テーブルは作らない方が得策。
テーブル分割
テーブルのレコード数は数百万近くになる場合がある。そのような場合にテーブルのレコード数を減らすためにテーブル分割という方法がある。
【商品テーブル】
| 商品ID | 商品名 | 価格 |
|---|---|---|
| 001 | Tシャツ | 800 |
| 002 | スキニー | 2000 |
| 003 | ジャケット | 5000 |
| 004 | ダウン | 10000 |
これを水平分割する。
【商品テーブル001~002】
| 商品ID | 商品名 | 価格 |
|---|---|---|
| 001 | Tシャツ | 800 |
| 002 | スキニー | 2000 |
【商品テーブル003~004】
| 商品ID | 商品名 | 価格 |
|---|---|---|
| 003 | ジャケット | 5000 |
| 004 | ダウン | 10000 |
今回はサンプルのため4件のデータを分割する例で紹介しているが、本来なら数百万件のデータがある。
水平分割することでアクセスするデータ量を減らすことができパフォーマンスの改善をすることができます。
その一方で水平分割をすることで下記のような欠点があります
- 分割する意味的な理由がない(パフォーマンス面の改善の要請がない限りは実施は不要)
- 拡張性が乏しくなる
- 水平分割以外にもパフォーマンス問題を解決する手段はある
集約
テーブル分割の代案として利用されることが多く下記の2点の手法がある
- 列の絞り込み
- サマリテーブル
列の絞り込み
下記の社員テーブルにおいて、会社コードと社員IDと年齢の列だけに絞り込んでテーブルを新規に分割させる。
【社員テーブル】
| 会社コード | 社員ID | 社員名 | 年齢 | 部署コード |
|---|---|---|---|---|
| C0001 | 000A | 中島 | 40 | D01 |
| C0001 | 000B | 鈴木 | 32 | D02 |
| C0001 | 000F | 高橋 | 45 | D03 |
| C0002 | 000A | 小泉 | 50 | D03 |
| C002 | 009F | 加藤 | 23 | D01 |
| C002 | 010A | 増田 | 31 | D04 |
【社員テーブル(年齢を抽出)】
| 会社コード | 社員ID | 年齢 |
|---|---|---|
| C0001 | 000A | 40 |
| C0001 | 000B | 32 |
| C0001 | 000F | 45 |
| C0002 | 000A | 50 |
| C002 | 009F | 23 |
| C002 | 010A | 31 |
社員テーブルから年齢の列を抽出した新しい小規模テーブル(データマート)を作成しました。
これによって大量データを扱う際のパフォーマンスの向上を期待できます。その一方で社員テーブル本体との定期的な同期をする必要があります。
社員テーブルの年齢が更新されたタイミングで年齢のみのデータマートも更新する必要があります。
そのことからパフォーマンスを向上させることができる一方で下記のような欠点があります
- オリジナルテーブルとのデータ同期が必要
- 更新処理によって負荷が上がる
- オリジナルテーブルとの不整合性の期間が長くなる可能性がある
サマリテーブル
サマリテーブルは集約関数によってレコードを集約した状態で保持するテーブル。
集約関数とは1つの列グループに対して施すことができる関数でSUM(), AVG(), MAX(), MIN(), COUNT()がある。
例えば会社ごとに社員の平均年齢を集約したテーブルを新規に作成するとする。
【社員の平均年齢】
| 会社コード | 平均年齢 |
|---|---|
| C0001 | 35 |
| C0002 | 32 |
このサマリテーブルによってI/Oコストを大きく削減することができる。
一方で絞り込みと同じくデータの同期問題が発生してしまう可能性があります。
最後に
いかがだったでしょうか。今回はデータベース設計についての解説をしました。
自分自身もまだまだ学習中なので今回の学びを元にデータベース設計についてより理解を深めていけたらなと思っています。
普段はフロント向けの記事を書いているので併せて読んでいただけると嬉しいです。
参考文献
なおこの記事は以下の情報を参考にして執筆しました。