はじめに
DANetとmusic2vecを組み合わせ、ノイズが混ざった音楽からノイズを除去し、さらにその音楽のジャンルを分類することを試みました。
DANetの実装や解説は、DANetのQiita記事とDANetのGithubリポジトリを参照してください。
music2vecの実装や解説は、music2vecのQiita記事とmusic2vecのGithubリポジトリを参照してください。
まず環境音をノイズとして音楽に混ぜてそれらを分離するようにDANetを学習させ、事前に音楽ジャンル分類を学習させていたmusic2vecにDANetの出力を入力して音楽ジャンルの分類を行いました。
DANetとmusic2vecをつなげた推論とその結果の評価を実行したものをGoogle Colaboratory上にまとめています。
DANetの学習
ノイズとして使用する環境音としてESC-50、ジャンル分類する音楽としてGTZANを用いました。
環境音1つを音楽に混ぜて分離させる学習と、環境音2つを音楽に混ぜて分離させる学習の2パターンを行いました。
環境音2つを混ぜる場合でも、出力は環境音と音楽の2つになるように学習させました。
DANetでは訓練時にideal mask、推論時にkmeansを利用することでAttractorを作成して音声の分離を行いますが、今回の学習では全20エポックの学習の内、最後の5エポックはideal maskではなくkmeansを用いてAttractorを作成しました。
music2vecの学習
music2vecのQiita記事やmusic2vecのリポジトリをまとめるときに作成・学習させた、事前学習済みSoundNetベースのモデルを利用しました。
処理の流れ
まず音楽データと環境音データをそれぞれ短時間フーリエ変換した後、DANetの入力サイズに合うようにそれぞれデータを分割してから混合してDANetに入力します。
出力された音楽スペクトログラムに逆短時間フーリエ変換を行い、SoundNetの入力に合うようにリサンプリングした後、複数の出力を結合して元の音楽データに戻し、music2vecに入力して音楽ジャンルを分類させます。
図で表すと下のようになります。

結果と評価
50個の音楽テストデータと100個の環境音テストデータを用いて(1個の音楽データは30秒、1個の環境音データは5秒)DANetに音楽と環境音の分離をさせた後、音楽ジャンルを分類させて混同行列を作成し、Accuracy・Precision・Recall・F1を求めました。
比較として、DANetの出力をmusic2vecに入力する場合以外にも、元の音楽データをmusic2vecに入力する場合、DANetに入力される環境音と音楽との混合音声をmusic2vecに入力する場合にも同様のことを行って評価しました。
環境音を1つ混ぜた場合と2つ混ぜた場合それぞれについて下に示します。

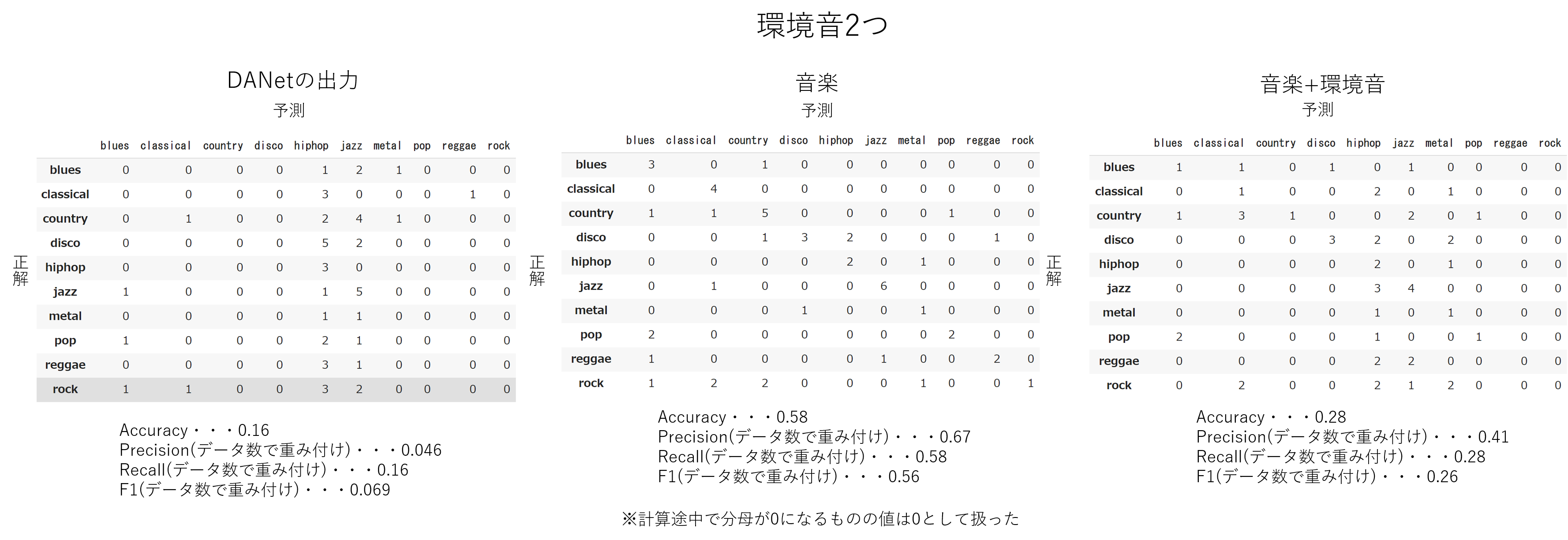
ここで、Precision・Recall・F1の値は各ラベルごとの値をデータ数に応じて重み付けをして平均したものです。例えば、下のような混同行列であれば下の計算式によりPrecisionはおよそ0.58になります。

\frac{10}{19}\times\frac{15}{50}+\frac{12}{18}\times\frac{25}{50}+\frac{6}{13}\times\frac{10}{50}\fallingdotseq0.58
環境音2つを混ぜたときは環境音1つを混ぜたときよりも結果が悪くなっています。
また、music2vecに環境音と音楽を混ぜたものを入力するよりもDANetの出力を入力したときの方が結果が悪くなっているので、DANetが思うように機能していないと言えます。
実際、環境音1つを混ぜたとき、DANet出力のGNSDRは-0.78、GSARは9.3、GSIRは6.0であり、環境音を2つ混ぜたときはGNSDRが0.76、GSARは9.4、GSIRは5.2でした。
これは、カエルの鳴き声と風の音を分離したときの値(GNSDR:5.3 GSAR:12 GSIR:10)と比べても全体的に低く、特にGNSDRやGSIRが低くなっています。
DANetから出力された音を聞いても分離されている感じはせず、大きな環境音が音楽に混ざったままであったり、逆に音楽が環境音とともに消されてしまったりしているような部分が多々あるように思えました。
分類精度を上げるにはまずノイズ除去がきちんと行われるように工夫する必要があります。
おわりに
DANetとmusic2vecを組み合わせ、ノイズが混ざった音楽からノイズを除去し、さらにその音楽のジャンルを分類することを試みました。
結果的にはうまくいかず、ノイズが混ざったまま分類させるよりも悪い分類精度になりました。
まずはノイズ除去がきちんと行われるように工夫する必要があることがわかりました。
不明な点、実装コードに関するアドバイス、ノイズ除去に関するアドバイスなどありましたらコメントお願いします。
(この記事は研究室インターンで取り組みました:https://kojima-r.github.io/kojima/)