shebang(シバン) ではない。Python に限ったものではないので、それはわかる。知りたいのは Python の教科書などで「ソースの文頭に書け」と言われる、冒頭に記述する
utf-8とかの文字コードのアレ。
# -*- coding: <encoding name> -*-
#使用例: # -*- coding: utf_8 -*-
# coding: <encoding name>
#使用例: # coding: utf_8
#
「python 文頭に記載する アレ」とか「python 文頭 記述 文字コード アレ」の Qiita 記事をググっても出てこなかったので、自分のググラビリティ(備忘録)として。
TL; DR (今北産業)
- アレは英語で
Magic commentと言います。 - Python 3 の場合、ソースが UTF-8 の時は記載は不要(むしろ非推奨)です。
- Python 3 で使えるコーデック一覧はこちらになります。
- Standard Encodings | Codecs | Library | v3 @ docs.python.org
TS; DR Python3 ソースコードの文字コード指定を完全に理解するコマケーこと
取りまとめ
-
英語で
Magic commentと言いますMagic comment の日本語表記について
英語の文献(PEP-263)には「
magic comment」という記載がありました。To define a source code encoding, a magic comment must be placed into the source files either as first or second line in the file
(「PEP 263 Defining Python Source Code Encodings」 @ PEP より、赤字は筆者)
【筆者訳】
ソースコードのエンコーディングを定義するには、ソースファイルの 1 行目もしくは 2 行目にマジックコメントを設置する必要があります
Ruby などの「マジックコメント1」と同様なようです。しかし、Python の公式文献(日本語版)には、具体的な和名は見つかりませんでした。
- ソースコードの文字コード指定の特別なコメント
- ソースコードのエンコーディング
- 文字セットエンコーディングの宣言
(「ソースコードの文字コード」| インタプリタとその環境 @ Python3 公式マニュアル より)
(「PEP 263: ソースコードのエンコーディング」| What’s New in Python 2.3 @ Python2 公式マニュアル より)「特別なコメント」が「
magic comment」の訳だと思いますが、magicの訳し方が難しかったのだと思います。「ソースコードに魔法のコメントで文字コードを指定します」だと微妙、みたいな。「おいしくなぁれ」のような謎の仕様に思われるからでしょうか。
普通に「文字コード指定」「エンコーディング指定」「エンコーディング宣言」「文字セットエンコーディングの宣言」などで通じそうです。深く考えすぎてしまいました。
コンピューターの世界では「何を言っているのかわからないも、唱えると動いちゃうし、むしろそれがないと正常に動かない」系のものを「マジックなんとか」と呼ぶ習慣があります。マジックナンバーなどは有名です。しかし、ドキュメントにそこまで説明的に書くのはナンセンスですし「初心者に優しい言語」と、うたっている Python ゆえの葛藤だったのかもしれません。知らんけど。
-
Python 3 の場合、ソースが UTF-8 の時は記載は不要
(PEP-8 ではむしろ記載は非推奨 😱)- Python 2 の場合、ソースが UTF-8 の時は逆に記載が必須
-
文字コード宣言を記載する場合:
- 1 行目 or 2 行目に記載すること
- 以下のいずれの記述方法でも構わない(その理由は後述)。
# coding: [encoding]# coding:[encoding]# coding=[encoding]# coding= [encoding]-
# -*- coding: [encoding] -*-(Emacs 併用) -
# -*- coding:[encoding] -*-(Emacs 併用) -
# vim:fileencoding=[encoding](Vim 併用)
-
[encoding]部分の仕様- 正規表現
([-\w.]+)にマッチすること-
-a-zA-Z0-9_.の連続文字列 -
_は\wの正規表現に含まれています。(詳しくはコメント参照)
-
- 大文字・小文字は問わない
- 正規表現
-
[encoding]部分で指定可能な UTF-8 の一覧(エイリアス含む)-
utf8,utf-8,utf_8,u8,utf,cp65001
-
-
Python3 ソースコードのエンコーディング指定で利用可能な文字コード名一覧
- Standard Encodings | Codecs | Library @ Python3 公式ドキュメント(英語版)
PEPとは
PEP の基本概要
PEPとは何か?
公式のガイドラインには以下のような説明があります。
PEP は Python 拡張提案(
Python Enhancement Proposal)を表しています。PEP は Python のコミュニティに対して情報を提供したり、Python の新機能やプロセス、環境などを説明するための設計書です。PEP は、技術的な仕様と、その機能が必要な論理的な理由を提供しなければなりません。我々は、PEP を、新機能を提案したり、課題に関するコミュニティの意見を集約したり、Python に取り込まれることになる、設計上の決定をドキュメント化するための、主要なメカニズムであると位置づけています。PEP の作者は、コミュニティの中でコンセンサスを取ったり、反対意見の記録を取る責任を持ちます。
PEP はテキストファイルの形式でバージョン管理されたリポジトリの中に保管されます。そのリポジトリの変更履歴は、機能提案の経緯の記録となります。
(PEP-0001「PEPの目的とガイドライン(日本語訳)」@ Sphinx の日本ユーザ会 より)
なかなか、何を、言っているか、わからない、感じの、説明です。
一言で言うと「PEP は Python のスタンダード(標準)をまとめたもの」です。
つまり、ISO・IEEE・W3C のような、Python における各種スタンダード(標準化された規格)が制定されたものが取りまとめられた、いわば Python のプロトコル CODE です。
例えば「Python のコーディング規約は PEP-8 で制定されている」といった具合です。そのため、何かの仕様や新しい機能が追加・変更される(拡張される)場合に PEP を通して制定されます。
PHP の PSR のようなものですが、外部団体でなく Python 自体が制定しているので「Python はコードが読みやすい」理由にもなっているのかもしれません。最初から整頓されていて、さすが Python パイセン。PHP より年上とは思えない几帳面さ。
- 参考文献
- PEP-0008「Python コードのスタイルガイド(日本語訳)」@ ReadTheDocs
ミッフィーちゃんみたいなやつ
(・×・) のような顔文字っぽいのは薄っすらと覚えているのです。
さすがに (・×・) ではないとわかるも、それが -*- だったか _*_ だったか (⊃*⊂) だったか思い出せないのです。
文字コードの指定方法も /*-utf-8-*/ だったか lang=ja_JP.utf-8 だったか encode=utf-8 だったかすらも思い出せないのです。
そこで、パーツを2つにわけて覚えようとしました。「前後の記号」部分(A)と「エンコード指定」部分(B)です。
[A] [ B ] [A]
-*- coding=[encoding] -*-
まずは「前後の記号」(A の -*- の部分)です。
「迫るパイソンに、冷静に口を開いて威嚇するミッフィー」
-x-(威嚇前)→-*-(威嚇中)
せっかく覚えたのですが、「エンコード指定部」の文言( B のcoding: utf-8 の部分)を調べていくうちに Emacs ユーザーでない場合はミッフィーちゃんは不要であることがわかりました。
どうやら、-*- coding: ... -*- と書くのは Emacs 互換のための記述のようです。
しかも、GNU Emacs も v23 からデフォルトエンコーディングが UTF-8 になりました。
- 参考文献
- 「ファイル中に明示的に文字コード指定を埋め込む (
-*- coding: utf-8; -*-)」| emacs @ MediaHub - PEP 3120 -- Using UTF-8 as the default source encoding | PEP @ Python.org
- Ruby 「衝撃の事実!?
# -*- encoding: utf-8 -*-じゃなくてもいいんです!」@ Qiita - Choosing File Modes | Modes | Manual @ GNU Emacs
- Emacs 23.1 released | Archive | Lists @ GNU Emacs
- 「ファイル中に明示的に文字コード指定を埋め込む (
文字コード宣言の仕様
残念ながら「ミッフィーちゃんは必須ではない」らしい情報は得たものの、続けて「エンコード指定」の部分を調べていると、同じ UTF-8 でも人によって書き方にバラツキがあることに気付きました。
coding=utf8coding=utf-8coding:utf-8coding:utf8coding: utf8coding=utf_8coding:utf_8encoding:utf-8encoding:UTF8- etc...
どうやら、これも覚えられなかった一因のようです。むしろ「ウォーリーを探せ」くらいの微妙な違いです。(実は、このことが検証時にさらなる悲劇を生むことになります。こうご期待)
そこで、仕様的に正しくはどう書くのか調べたので報告いたします。
If a comment in the first or second line of the Python script matches the regular expression
coding[=:]\s*([-\w.]+), this comment is processed as an encoding declaration;(Encoding declarations | Lexical analysis @ 英語版公式 Python3 言語リファレンスより)
【筆者訳】
Python スクリプトの 1 行目または 2 行目のコメントが正規表現coding[=:]\s*([-\w.]+)にマッチした場合、このコメントはエンコーディングの宣言文として扱われます。
上記仕様によると、Python では以下の2つの条件にマッチすると「文字コード指定行」と判断されます。
-
1行目もしくは2行目のコメント行であること
-
「
coding[=:]\s*([-\w.]+)」の正規表現にマッチすること正規表現の説明
コメント行は Bash で言う
head -2 | grep -e "^#"と同等で、最初の 2 行のうち#から始まるものをコメント行として扱います。そしてコメント行を正規表現でチェックします。「
coding[=:]\s*([-\w.]+)」の正規表現の意味は以下の通りです。-
coding[=:]-
coding=もしくはcoding:を含む -
Coding:など大文字で始まるとマッチしないので注意
-
-
\s*- 0個以上のスペースが続く
-
[-\w.]+-
-[a-zA-Z][0-9]_.の任意の1つ以上の連続文字。これがエンコード名。 -
_は\wの正規表現に含まれています。詳しくはコメント参照。
-
-
つまり、仕様上は -*- は必要ないのです。
これがミッフィーちゃんが不要な理由です。逆に言えば以下の指定でも動いてしまうということです。
# 💩💩💩💩 uncoding=utf-8 💩💩💩💩
- 本当に動いちゃう例をオンラインで見る @ paiza.IO
同様に、これが Vim 併用の記述としても使える理由です。
# vim:fileencoding=utf-8
また検証の結果、文字コードの UTF-8 utf-8 の大文字・小文字は区別しませんでした。調べたところ、内部で小文字に変換しているそうです。(後述)
となると不思議な点が出てきます。
coding[=:]\s*([-\w.]+) の仕様はわかったのですが、utf_8 のように _(アンダースコア、アンダーバー)を使った記述はどうなっているのでしょうか。
Python3 のソースコードのエンコーディングで利用可能な文字コード名
UTF-8 と UTF_8 の違い
先に結論から言うと「UTF-8」も「UTF_8」も違いはありません。内部で変換されてから正規表現を通して utf_8 と認識されるためです。
しかし、「正しくは(仕様的には)どちらで書いた方が好ましいのか」気になったので続けて調べてみました。
日本語の Python リファレンスには以下のように書かれています。
エンコーディングが宣言される場合、そのエンコーディング名は Python によって認識できなければなりません。宣言されたエンコーディングは、例えば文字列リテラル、コメント、識別子などの、全ての字句解析に使われます。
(「エンコード宣言(encoding declaration)| 字句解析」@ 公式 Python3 言語リファレンス より)
「エンコーディング名は Python によって認識できなければなりません」とあるのですが、どのようなものが認識されるのか明記されていませんでした。(2020/10/27 現在)
しかし、英語の方の公式 Python3 のドキュメントには、より具体的な記述がありました。
To declare an encoding other than the default one, a special comment line should be added as the first line of the file. The syntax is as follows:
# -*- coding: encoding -*-where encoding is one of the valid codecs supported by Python.
(Source Code Encoding | The Interpreter and Its Environment | 英語版公式 Python3 チュートリアル より)
【筆者訳】
デフォルト以外のエンコーディングを宣言するには、ファイルの1行目に特別なコメント行を追加する必要があります。構文は以下の通りです。# -*- coding: [encoding] -*-ここでの "encoding" は、Python でサポートされている有効なコーデックを指定します。
とリンク付きであります。
さらに英語版の方では、ありがたいことに「ソースコードの文字コードが Windows-1252 の場合、encoding 部分は cp1252 であるべき」というサンプルも記載されていました。
For example, to declare that Windows-1252 encoding is to be used, the first line of your source code file should be:
# -*- coding: cp1252 -*-(Source Code Encoding | The Interpreter and Its Environment | 英語版公式 Python3 チュートリアル より)
【筆者訳】
例えば、Windows-1252 エンコーディングを使用することを宣言するには、ソースコードファイルの 1 行目を以下のように記述します。# -*- coding: cp1252 -*-
つまり、この codecs の対応表を探せば「Python3 のソースコードのエンコーディングで利用可能な文字コード名」とやらがわかりそうです。
ちゃんとライブラリのドキュメントの codecs 欄に対応表の一覧がありました。
そこから URL をいじって日本語版を開いてみます。
- Python3 のソースコードのエンコーディングで利用可能な文字コード名
- Standard Encodings | Codecs | Library @ Python3 公式ドキュメント(英語版)
- 標準エンコーディング | Codecs | Library @ Python3 公式ドキュメント(日本語版)
🐒 Python のドキュメントは整頓されているものの、意外に探しづらい気がするのは筆者だけでしょうか。情報の並びが東急ハンズに見えるのに、ドンキーで探し物をしているような印象を受けます。
| Codec | Aliases | Languages |
|---|---|---|
| ... | ... | ... |
| utf_8 | U8, UTF, utf8, cp65001 | all languages |
| ... | ... | ... |
なんと、ここで UTF-8 の内部コーデック名が utf_8 と _(アンダースコア)で指定されています。また、エイリアスとして別名でも指定できることがわかりました。
つまり U8 や utf8 や cp65001 と指定しても、内部で utf_8 に変換されるということです。
しかし、エイリアスの一覧に utf-8 の -(ハイフン)の記述がありません。
謎は深まるばかりです。
すると、一覧の上にサラっと以下の一文が記載されていました。
Notice that spelling alternatives that only differ in case or use a hyphen instead of an underscore are also valid aliases; therefore, e.g.
'utf-8'is a valid alias for the'utf_8'codec.【筆者訳】
注意点として、エイリアス以外でつづりの違いが有効なのは、「大文字と小文字の違い」と「アンダースコア(_)の代わりにハイフン(-)を使用する場合」のみです。したがって、たとえば'utf-8'は'utf_8'コーデックの有効なエイリアスとなります。
つまり、-(ハイフン)は _(アンダースコア、アンダーバー)に変換されるということです。
以上を踏まえると、utf-8 と utf_8 なら、utf_8 と記載した方が良いことになります。置換処理を必要としないストレートな処理ができるためです(ゆうて大した速度の違いはないのですが)。
大いなる誤解
実は、以前の記事の版では「_ は使わずに - を使え。Python2 で coding:utf_8 で動くのはたまたま」と言っていました。しかも、律儀に検証実証まで添えて。
というのも、coding[=:]\s*([-\w.]+) の正規表現には _ が含まれないと勘違いしていたのです。\w の正規表現はword の w だから [a-z][A-Z][0-9] だけだと重いコンダラ状態だったです。
ところが、コメントを読んでビックリしました。
... そう ... 実は小生、_ の挙動を色々と検証している中で、ずーっと coding を codeing と typo していたのでごザルよ!!そりゃ動かないわな!
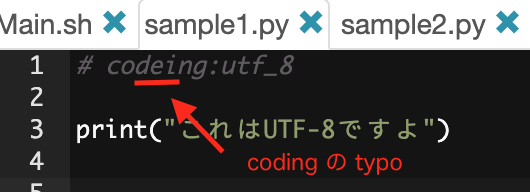 |
|---|
| ザルな検証のしすぎで、検証猿でごザルの例 |
そこで、確認のために公式ドキュメントを読むと、なんと!Python の正規表現の \w には _(アンダースコア、アンダーバー)も含まれていると明記されているじゃぁないですか!!
\w
Unicode (str) パターンでは:
Unicode 単語文字にマッチします。これはあらゆる言語で単語の一部になりうるほとんどの文字、数字、およびアンダースコアを含みます。ASCII フラグが使われているなら、 [a-zA-Z0-9_] のみにマッチします。
(正規表現のシンタックス | re --- 正規表現操作 | v3 | JA @ docs.python.org より)
ここでもドキュメント嫁にしかられてしまいました ... ... よくよく考えてみれば PHP の word character も同じ letter, number, underscore でした。とほほ。
このように、coding:utf_8 でも動いてしまう理由は「たまたま」ではなく、\w の正規表現に _ が含まれていることと、- が _ に置換されるからでした! > @JsM さん、ありがとう!
まとめ
まとめると、渡されたエンコーディング名は前処理として以下を行い、codec と完全一致した場合に有効なエンコード指定と判断されるということです。
- コメント行の 1 〜 2 行目を取得する
- 正規表現でフィルターをかける
- 小文字に変換する
-
-は_に変換される -
Aliases一覧にマッチした場合は、対応するCodecに置換する - 変換/置換後の結果が
Codec一覧のいずれかにマッチした場合は有効なエンコード指定とする
今度は、ちゃんとした実証実験として、# coding:utf_8 と宣言した Python ファイルを Python2 で実行すると、ちゃんと動きました!
$ python3 sample.py
これはUTF-8ですよ
$ python2 sample.py
これはUTF-8ですよ
- オンラインで動作をみる @ paiza.IO
- typo 版をオンラインでみる @ paiza.IO
文字コードを記載しない人たちの理由 (PEP-8に準拠している人たち)
さて、文字コードについて完全に理解したつもりでいたところ、「そもそも文字コードを指定していないソースコード」も見かけました。
「(おいおい。そんな装備で大丈夫かぁ)」とニヤニヤしながら調べたところ、そもそも Python3 では UTF-8 の場合は文字コードは指定しないことが推奨されていることがわかりました。
PEP8を読んでいたらこんな記述に気づいた。
ASCII (Python 2) や UTF-8 (Python 3) を使用しているファイルにはエンコーディング宣言を入れるべきではありません。
はじめに — pep8-ja 1.0 ドキュメントえぇぇぇぇ!? と思ったんだけど、何回読み直しても「デフォルトエンコーディング使うならエンコーディング宣言は書くなよ!」と書いてあるようにしか読めない。
(「# coding: utf-8はもうやめる」 @ 静かなる名辞 より)
マスオさんどころか、私もビックリです。
確かに、リンク先のドキュメントや PEP-8 の英語の原文を読んでも、「Python2 の場合 ASCII、Python3 の場合 UTF-8 で書かれたソースコードでは文字コードの宣言文はいれない」という規約があるようです。(コメントも 120% の確信がなければ日本語も不可って随分と厳しいルールですね。まぁ、レベルが should 以下なので絶対というわけではないですけど)
Python3 の公式マニュアルでは、「デフォルトでは、Python のソースコードは UTF-8 でエンコードされているものとして扱われます。」とあります。
そのため、UTF-8 の場合は基本的に不要というのはわかりました。そして、Python2 の場合は、デフォルト・エンコードが ASCII であるため、逆に UTF-8 の場合は必須ということです。
おそらく、名著とされる本でも文字コードを書くように勧めるのは、Python2 から Python3 への過渡期であるいま、両バージョンを網羅しないといけないからなのかもしれません。また、SJIS-win から UTF-16 への移行過渡期にある Windows ユーザーのことも考えてポカヨケとして記載させているのかもしれません。
PHP4 時代、メール送信の実装でガラケー対応など、混沌とした文字コードを吸った揉んだしようとしたホロ苦い経験から、内部では UTF-8 で処理を統一して、出力時に文字コードを変換するというプラクティスがありました。そのため、むしろ Python3 の UTF-8 がデフォルトというのはシックリと来ます。
さて、ここまで調べた結果の結論を言うと、Python3 で行くと決めたし、UTF-8 で統一しているから「冒頭に記載するアレ」は不要という、ナンタルチアな答えに。とほほ。
- 参考文献
- PEP-0263 | PEPs | dev @ python.org
- PEP-0008 | PEPs | dev @ python.org
- Python のコーディング規約 PEP8 に準拠する @ Qiita
- # coding: utf-8はもうやめる @ 静かなる名辞
- ソースコードの文字コード | Python インタプリタを使う @ 公式 Python3 チュートリアル
- Pythonのcoding: ナントカのことがよく分からないから調べてみた @ Qiita
あわせて読みたい
- Python 3の各種エンコーディングについて @ Qiita
その他参考文献
-
magic_comment | 多言語化 @ Ruby 公式ドキュメント ↩