お久しぶりですね。
今回はサンプルのCross Validation for Binary Classification - Adult Income Predictionを使ってpythonから実行してみたいと思います。
また、汎用的に利用したいので、一部項目をパラメータにして試してみたいと思います。
ワークスペースやクラスターの作成、実行方法等は最初の記事を参考にしてください。
サンプルを開く
それではいつものようにサンプルを見ていきましょう。
データの内容は依然やったものと同じだったので割愛します。

シンプルですね。
今までと違う点はCrossValidateModelでしょうか。
どのようなブロックなのか確認していきましょう。
サンプルの内容
CrossValidateModelは交差検証を行うブロックです。
交差検証とは、
データセットの変動性と、そのデータを通じてトレーニングされたモデルの信頼性の両方を評価するために、機械学習でよく使用される手法
らしいです。
学習データとテストデータの分割を数回行い、一つのデータで何回かの学習を行い、その結果を比較することでモデルを評価するという者みたいですね。
ブロックには前処理後のデータとアルゴリズムを繋いでるようですね。
結果としてはどのようなものが得られるのでしょうか。

一つ目は予測結果ですね。
予測結果はScoredProbabilitiesの値が一番良かった施行のデータが入っているようです。
FoldNumberには何回目の施行のデータなのかが入っているようです。

二つ目は評価指標のリストですね。
各施行ごとの評価を比較できるので、作成したモデルがだいたいどれくらいの精度を持つのかを確認することができますね。
サンプルをいじってみる
今回はここからが本番です。
今まではAzureMLStudio上で作業していましたが、このブロック作成後の実行をpythonコード上から実行してみたいと思います。
また、パラメータを利用して、学習させるデータや結果の出力先を自由に決められるようにしたいと思います。
AzureCLIでAzureにログインする
pythonでAzureMLを操作するためにAzureCLIでログインする必要があります。
AzureCLIのインストールはこちらを参考に行います。
といってもこちらにあるインストーラーを実行するだけですので簡単ですね。
その後PCを再起動してazコマンドが実行できることを確認します。
az --version
こちらが実行できたらインストールは成功ですね。
あとはログインして、利用しているサブスクリプションを選択します。
az login
az account set --subscription "サブスクリプションID"
az loginを実行するとwebページが開くのでloginします。
自分の場合は既定のサブスクリプションが利用中のものと異なっていたので下のコマンドを利用して変更する必要がありました。
これで準備完了です。
ブロックの修正
まずは先ほどのブロックに修正をしていきます。

ブロックの変更は
- データの入力をImportDataに変更
- ScoreModelの後ろにExportDataを追加
- CrossValidateModelの後ろにExportDataを追加
になります。
また、TrainModelやCrossValidateModelでは学習対象のカラムを指定する部分があります。
もともとはカラム名を指定しているのですが、いろんなデータを使いたいとなると名前指定はよくありません。
そこで、必ず最初のデータを学習対象にするように変更します。
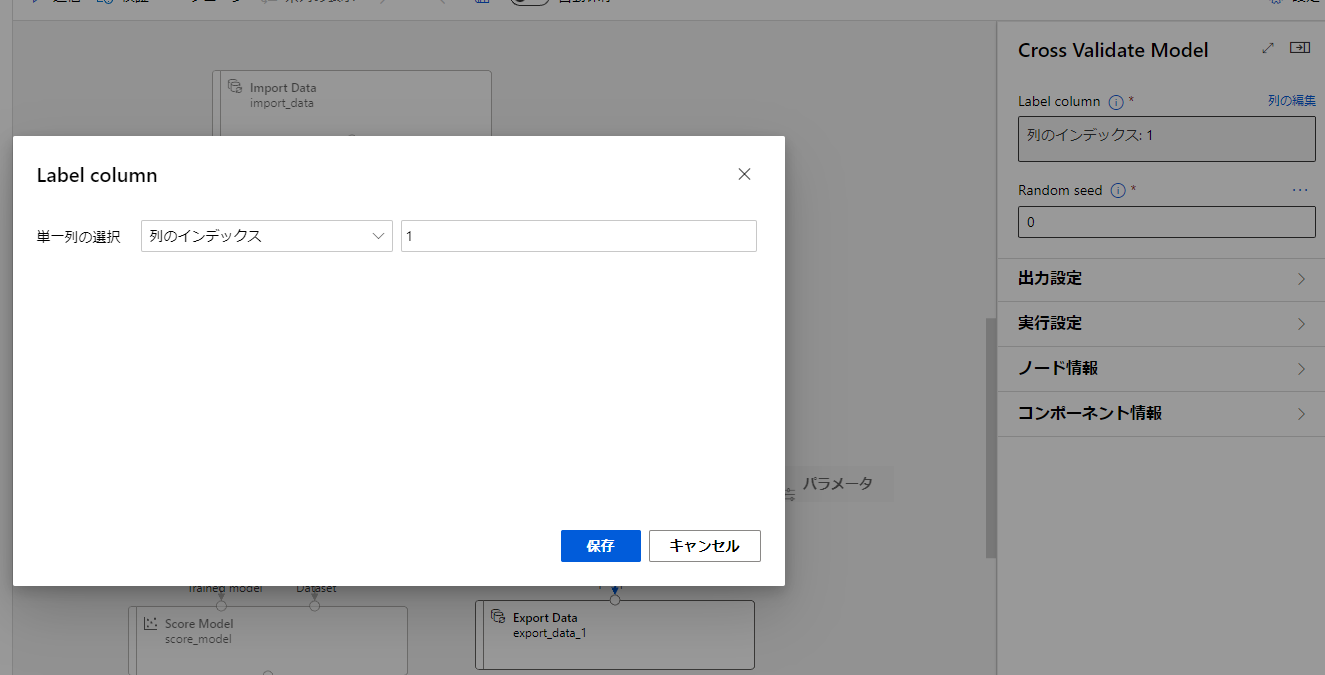
このようにすることで、学習時にデータを成型することで任意のデータを学習させることができるはずです。
この変更をTrainModelとCrossValidateModelに行います。
入力データと出力ファイル名は実行ごとに自由に決めたいです。
そこでパイプラインパラメータを利用したいと思います。
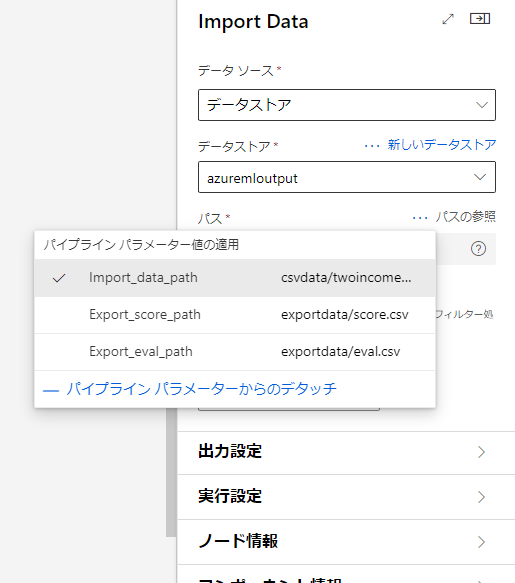
パイプラインパラメータを利用することで、実行時に変数として値を渡すことができるようになります。
この変更をImportDataとExportDataに行います。

変更はこのようにパラメータ名と値の組み合わせで設定するので、それぞれパラメータ名は一意のものを、値には初期値としてふさわしいものを入れておきます。
例えばImportDataの初期値に存在しないファイル名を入れてしまうと、値を設定しなかった場合にエラーが出てしまうので注意しましょう。
パイプラインの公開
それではPythonから実行できるようにパイプラインを公開したいと思います。
まずはこれを実行し、動作することを確認します。

その後パイプラインエンドポイントを作成するのですが、自分の環境だとAzureMLStuido上からだとうまく動作しなかったのでPythonコードから作成していきたいと思います。
from azureml.core import Workspace
from azureml.core.experiment import Experiment
from azureml.pipeline.core import PipelineRun
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='<実験の名前>')
pipeline_endpoint = PipelineRun(experiment, "<実行のID>").publish_pipeline(
name="<表示名>",
description="<説明>",
version="<バージョン>",
continue_on_step_failure=None #失敗ステップを続行するかどうか
)
こちらを実行しましょう。
実験の名前は送信時に選択した実験名を入れます。
実行IDはジョブの概要から確認できます。
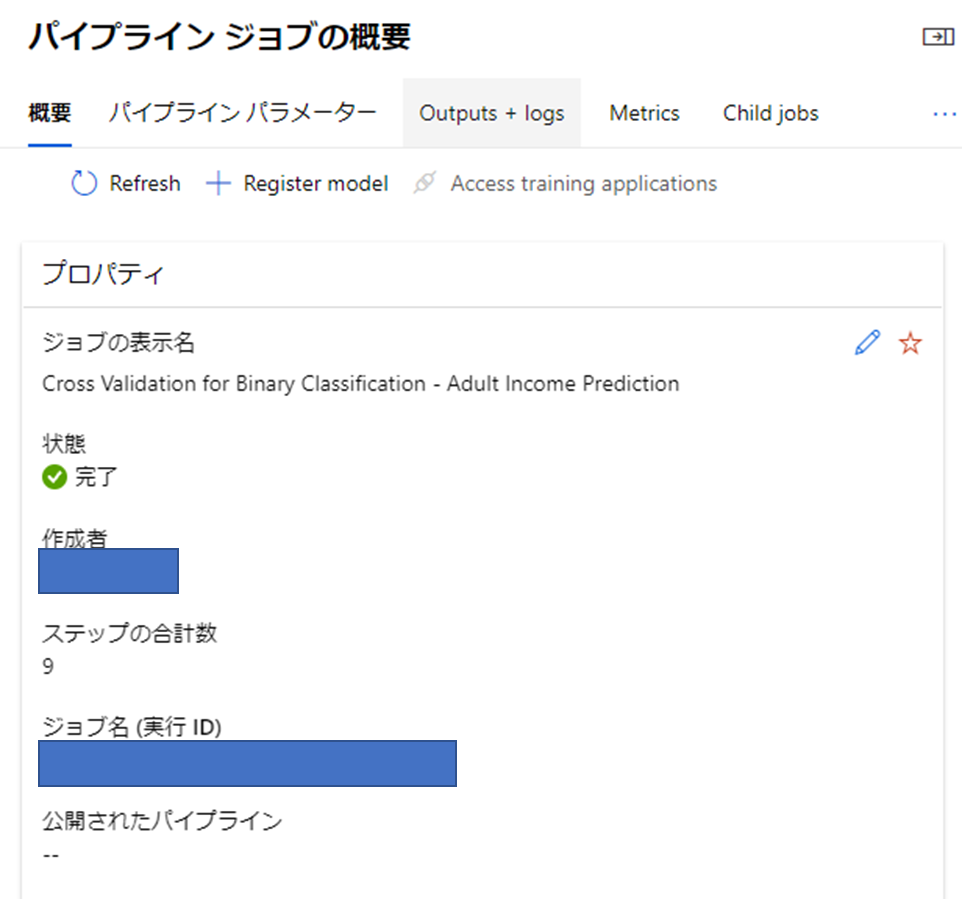
上記コードを実行すると、パイプラインタブのパイプラインエンドポイントに項目が作成されていると思います。

こちらを開いてみましょう。
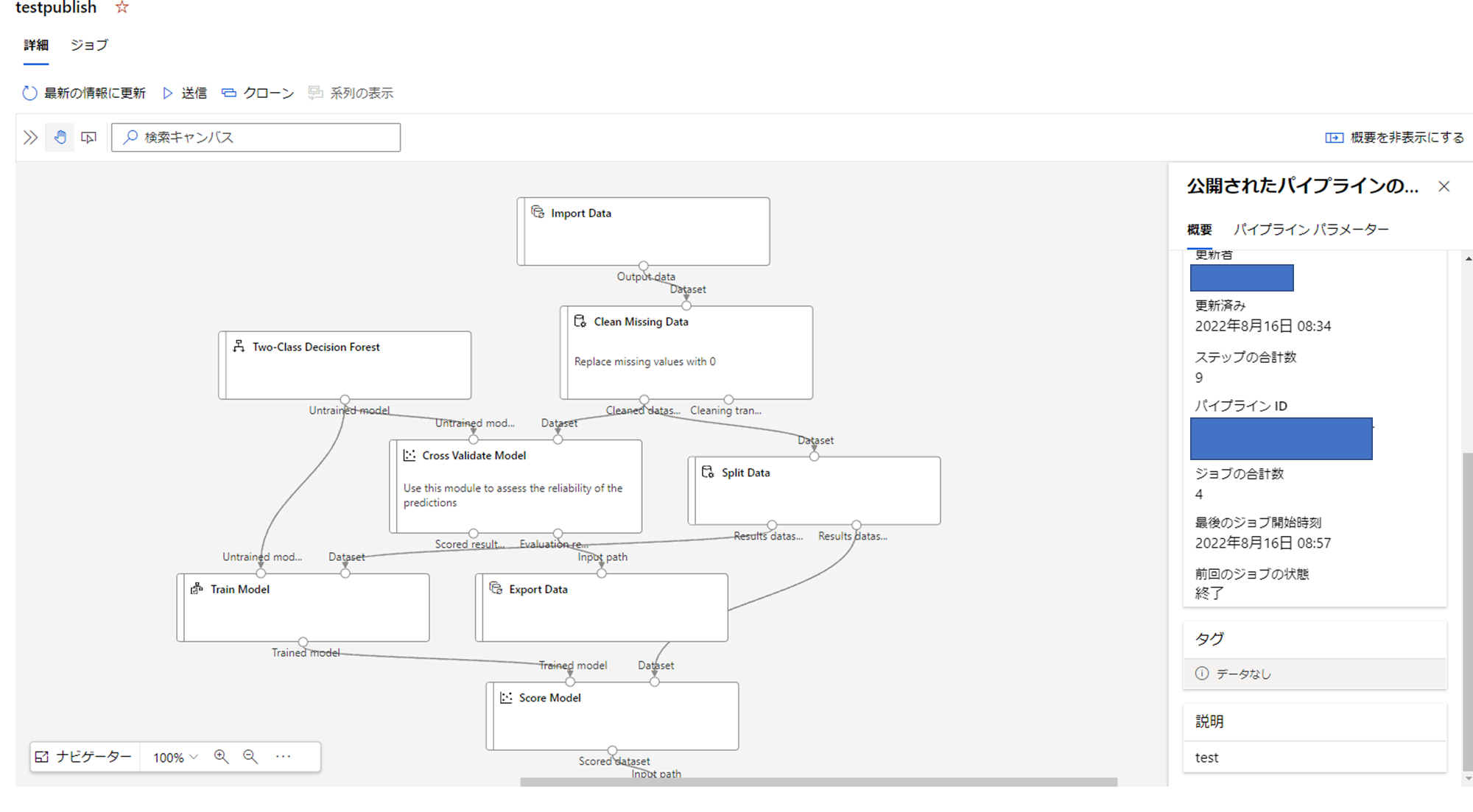
このように表示されると思います。
この右にあるパイプラインIDを利用してこちらを実行させていきます。
それでは実行するためのコードを見ていきましょう。
from azureml.core import Workspace
from azureml.core.experiment import Experiment
from azureml.pipeline.core import PublishedPipeline
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='<実験の名前>')
published_pipeline = PublishedPipeline.get(workspace=ws, id="<パイプラインID>")
pipeline_run = experiment.submit(
published_pipeline,
pipeline_parameters={
"Import_data_path": "csvdata/titanic.csv",
"Export_score_path": "exportdata/scorepub2.csv",
"Export_eval_path": "exportdata/evalpub2.csv"
}
)
ワークスペースを取得して、先ほど作成したパイプラインエンドポイントを取得します。
その後、設定したパラメータに任意の値を入れて実行するといった流れになります。
こちらを実行して動作を確認してみます。
今回は入力データをタイタニックの生存予測のデータに変更してみました。
ちゃんと結果は出るでしょうか…
実行結果の確認
実行を行うと
Submitted PipelineRun -----
Link to Azure Machine Learning Portal: https://ml.azure.com/----
というような結果が返ってきます。
一つ目のほうは実行IDになります。
二つ目のほうは実験へのURLになります。こちらを開くことで実行の確認ができますね。
今回は正しく出力されているかが気になるのでBLOBを直接見てみたいと思います。

どうやらファイルの生成はできているようです。
スコアデータがちゃんとできているかを見てみましょう。
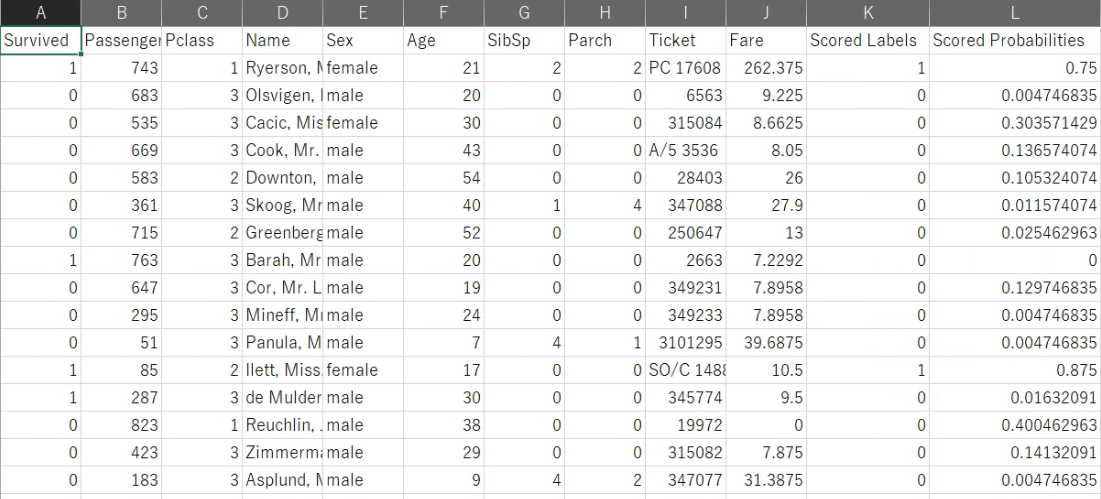
ちゃんとタイタニックのデータが出力できています!
評価のほうも見てみましょう。

評価もちゃんと出力できてますね。
まとめ
今回はデザイナーで作成したパイプラインをpythonから実行させてみました。
これによって、学習の流れをブロックで作成して、利用はコード上からできることがわかりました。
デザイナーで作成したパイプラインをサービスに組み込んだりして利用できそうですね。