MLでSageMaker使ってみたいと思ったので、サンプルを一通りやってみたいと思います。
なお、SageMakerもPyTorchもほぼ触ったことなし。
ノートブックで実行していきます。
ノートブックインスタンスの作成
AmazonSageMakerを開くと右上にノートブックインスタンスの作成というボタンがあるのでそこから作成を開始。
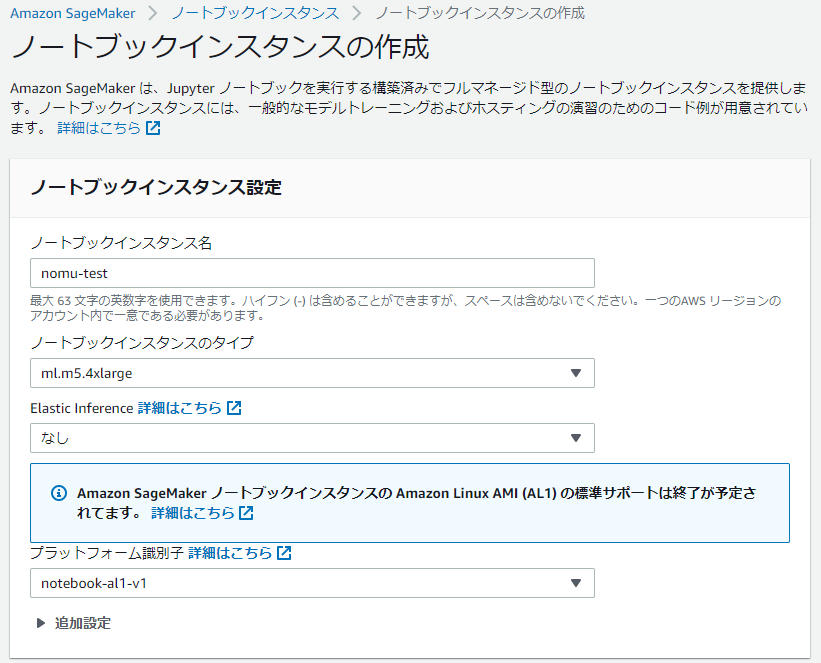
名前とml.m5.4xlargeを指定しました。これは無料枠らしいので選択してみてます。参考
こちらでインスタンスを作成しました。
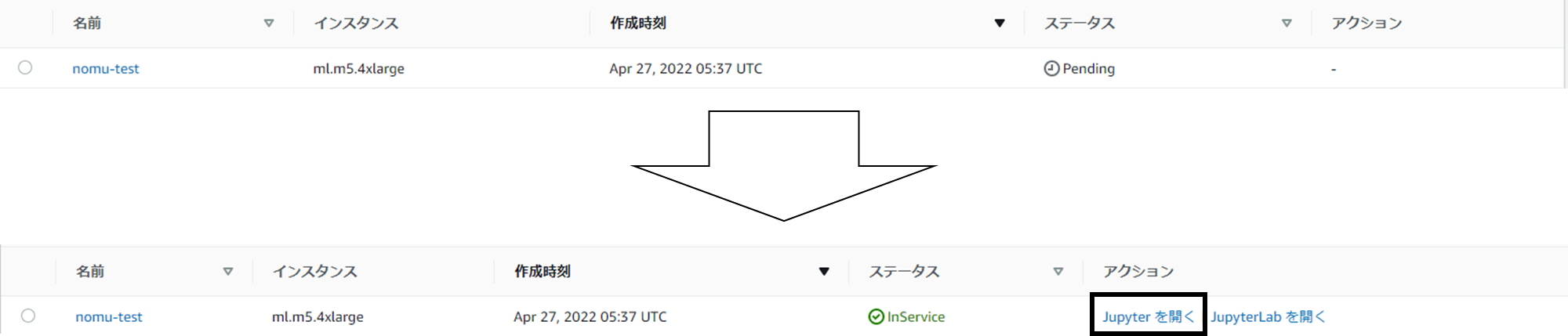
作成が終わったらJupyterを開きましょう。
開くとまっさらなので、スクリプト保存用のsrcフォルダとPyTorch用のノートブックを起動させます。
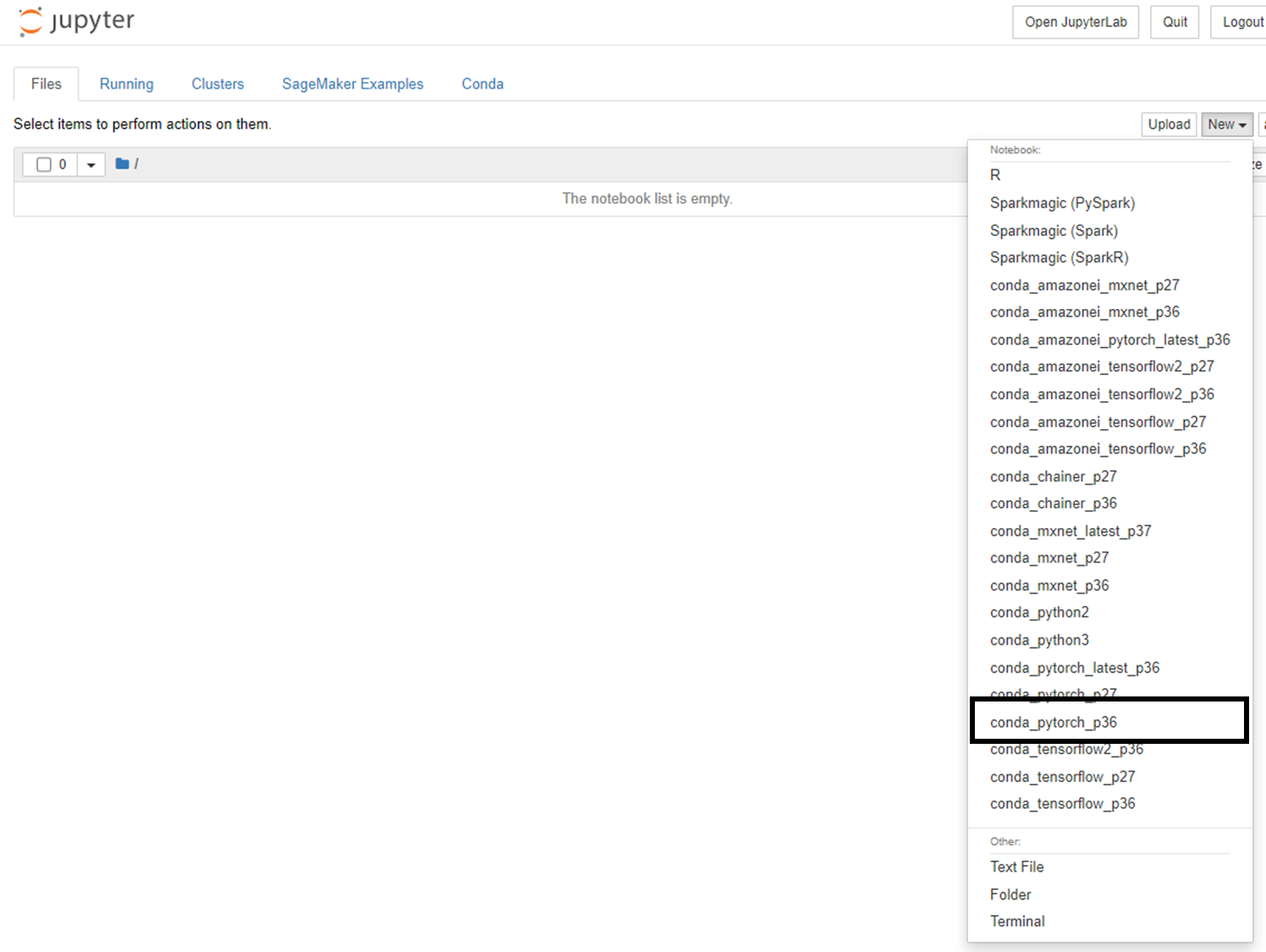
起動するとセルが出てきますので、ここでコードを書いていきます。
テストデータの準備
いろいろ作業する前に今回利用するテストデータをs3にあげておきましょう。
import torchvision
import numpy as np
import torch
import sagemaker
import os
train_dir = './train'
valid_dir = './valid'
!mkdir -p {train_dir}
!mkdir -p {valid_dir}
train_data = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()]))
train_data_loader = torch.utils.data.DataLoader(train_data, batch_size=len(train_data))
valid_data = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()]))
valid_data_loader = torch.utils.data.DataLoader(valid_data, batch_size=len(valid_data))
train_data_loaded = next(iter(train_data_loader))
torch.save(train_data_loaded, os.path.join(train_dir, 'train.pt'))
valid_data_loaded = next(iter(valid_data_loader))
torch.save(valid_data_loaded, os.path.join(valid_dir, 'valid.pt'))
train_s3_uri = sagemaker.session.Session().upload_data(path=train_dir, bucket=sagemaker.session.Session().default_bucket(), key_prefix='{your prefix}')
valid_s3_uri = sagemaker.session.Session().upload_data(path=valid_dir, bucket=sagemaker.session.Session().default_bucket(), key_prefix='{your prefix}')
print(train_s3_uri)
print(valid_s3_uri)
こちらで、データをlocalにダウンロードしたのちs3にアップロードを行います。
アップロード先のパスは後々利用するので持っておきましょう。
入力値の受け取り
PyTorchでは実行するソースコードを指定するようです(entry_point)
なので、実行するコードを書き出してあげる必要があります。
コードの書き出しは%%writefile ...でそれ以降の文章を指定パスに書き出してくれます。
今回は./src/testcode.pyに書き出してみましょう。
%%writefile ./src/testcode.py
これに続けてコードを書いていきます。
まずは、受け取る値たちを取得していきましょう。
今回受け取りたい値はhyperparametersとデータのパスです。
最初はデータのパスを受け取りましょう。
実行時に辞書型で入れてあげることでデータを渡せます。
estimator.fit({
'train':train_s3_path,
'test':test_s3_path,
})
これらで入力したデータは、環境変数のSM_CHANNEL_{大文字key名}で参照できます。
たとえばtrainのデータが欲しい時はSM_CHANNEL_TRAINを参照するといいですね。
続いてhyperparametersを受け取ります。
こちらはPyTorchの引数に入れるデータです。
estimator = PyTorch(
entry_point='./src/testcode.py',
py_version='py38',
framework_version='1.10.0',
instance_count=1,
instance_type='local',
role=sagemaker.get_execution_role(),
hyperparameters={
'filters':8,
'epochs':1,
'batch-size':'16',
'learning_rate' : 0.001
}
)
このように入力されます。
この値はSM_HPSという環境変数にjson文字列で格納されます。
なので受け取り後は辞書として扱えばいいですね。
それでは値の受け取りを追記しましょう。
train_dir = os.environ.get('SM_CHANNEL_TRAIN')
valid_dir = os.environ.get('SM_CHANNEL_TEST')
hps = json.loads(os.environ.get('SM_HPS'))
filters = hps['filters']
epochs = hps['epochs']
batch_size = hps['batch_size']
learning_rate = hps['learning_rate']
これでそれぞれの入力データを受け取れました。
次にデータを取得して読み込んでいきましょう。
データの読み込み
train_data = torch.utils.data.TensorDataset(*torch.load(os.path.join(train_dir, 'train.pt')))
valid_data = torch.utils.data.TensorDataset(*torch.load(os.path.join(valid_dir, 'valid.pt')))
train_data_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=2)
valid_data_loader = torch.utils.data.DataLoader(valid_data, batch_size=batch_size, shuffle=True, num_workers=2)
こちらになりますね。
上二つでs3上にある特定のファイルを取得、下二つでそれぞれ読み込むといった感じです。
次にモデルの定義と学習の定義、実行と保存です。
モデルの定義と実行、保存
#モデル定義
model = torch.nn.Sequential(
torch.nn.Conv2d(3, batch_size, kernel_size=(3,3), stride=1, padding=(1,1)),
torch.nn.ReLU(),
torch.nn.Flatten(),
torch.nn.Linear(batch_size*32*32,10),
torch.nn.Softmax(dim=1)
)
# 学習
def exec_epoch(loader, model, train_flg, optimizer, criterion):
total_loss = 0.0
correct = 0
count = 0
for i, data in enumerate(loader, 0):
inputs, labels = data
if train_flg:
inputs, labels = torch.autograd.Variable(inputs), torch.autograd.Variable(labels)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
if train_flg:
loss.backward()
optimizer.step()
total_loss += loss.item()
pred_y = outputs.argmax(axis=1)
correct += sum(labels==pred_y)
count += len(labels)
total_loss /= (i+1)
total_acc = 100 * correct / count
if train_flg:
print(f'train_loss: {total_loss:.3f} train_acc: {total_acc:.3f}%',end=' ')
else:
print(f'valid_loss: {total_loss:.3f} valid_acc: {total_acc:.3f}%')
return model
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=learning_rate)
for epoch in range(epochs):
print(f'epoch: {epoch+1}',end=' ')
model = exec_epoch(train_data_loader, model, True, optimizer, criterion)
exec_epoch(valid_data_loader, model, False, optimizer, criterion)
# モデル保存
model_dir = os.environ.get('SM_MODEL_DIR')
torch.save(model.state_dict(),os.path.join(model_dir,'1.pth'))
残念ながらここはあまり理解できてないですね…
次回以降はPyTorchについても理解したいところです、、、
モデルの実行
それでは実際に実行していきましょう。
まずは先ほどまでに作ったスクリプトを実行します。
%%writefile ./src/testcode.py
import torch
import torchvision
import os
import json
train_dir = os.environ.get('SM_CHANNEL_TRAIN')
valid_dir = os.environ.get('SM_CHANNEL_TEST')
hps = json.loads(os.environ.get('SM_HPS'))
filters = hps['filters']
epochs = hps['epochs']
batch_size = hps['batch_size']
learning_rate = hps['learning_rate']
train_data = torch.utils.data.TensorDataset(*torch.load(os.path.join(train_dir, 'train.pt')))
valid_data = torch.utils.data.TensorDataset(*torch.load(os.path.join(valid_dir, 'valid.pt')))
train_data_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=2)
valid_data_loader = torch.utils.data.DataLoader(valid_data, batch_size=batch_size, shuffle=True, num_workers=2)
#モデル定義
model = torch.nn.Sequential(
torch.nn.Conv2d(3, batch_size, kernel_size=(3,3), stride=1, padding=(1,1)),
torch.nn.ReLU(),
torch.nn.Flatten(),
torch.nn.Linear(batch_size*32*32,10),
torch.nn.Softmax(dim=1)
)
# 学習
def exec_epoch(loader, model, train_flg, optimizer, criterion):
total_loss = 0.0
correct = 0
count = 0
for i, data in enumerate(loader, 0):
inputs, labels = data
if train_flg:
inputs, labels = torch.autograd.Variable(inputs), torch.autograd.Variable(labels)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
if train_flg:
loss.backward()
optimizer.step()
total_loss += loss.item()
pred_y = outputs.argmax(axis=1)
correct += sum(labels==pred_y)
count += len(labels)
total_loss /= (i+1)
total_acc = 100 * correct / count
if train_flg:
print(f'train_loss: {total_loss:.3f} train_acc: {total_acc:.3f}%',end=' ')
else:
print(f'valid_loss: {total_loss:.3f} valid_acc: {total_acc:.3f}%')
return model
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=learning_rate)
for epoch in range(epochs):
print(f'epoch: {epoch+1}',end=' ')
model = exec_epoch(train_data_loader, model, True, optimizer, criterion)
exec_epoch(valid_data_loader, model, False, optimizer, criterion)
# モデル保存
model_dir = os.environ.get('SM_MODEL_DIR')
torch.save(model.state_dict(),os.path.join(model_dir,'1.pth'))
それではトレーニングを実行します。
import sagemaker
from sagemaker.pytorch import PyTorch
estimator = PyTorch(
entry_point='./src/testcode.py',
py_version='py38',
framework_version='1.10.0',
instance_count=1,
instance_type='local',
role=sagemaker.get_execution_role(),
hyperparameters={
'filters':8,
'epochs':1,
'batch_size':16,
'learning_rate' : 0.001
}
)
estimator.fit({
'train':{your s3 data path},
'test':{your s3 data path},
})
こちらを実行することでトレーニングが開始されます。
entry_pointには先ほど出力したスクリプトのパスを入れます。
また、今回instance_typeにlocalを入れていますので、今実行しているノートブック上で実行されることになります。
ここに好きなインスタンスタイプを入れてあげることで希望のスペックでトレーニングを行うことができます。
estimator.fitの中身を自身のs3パスに書き換える必要があることに注意してください。
では実行してみましょう。
----------- | train_loss: 2.045 train_acc: 41.568%
----------- | valid_loss: 1.970 valid_acc: 49.260%
----------- | 2022-04-27 07:54:43,793 sagemaker-training-toolkit INFO Reporting training SUCCESS
----------- exited with code 0
Aborting on container exit...
===== Job Complete =====
実行結果の精度が出てますね!実行できたみたいです。
以上でSageMakerの使い方の解説を終わります!
PyTorchの使い方、覚えないとなぁ、、、
これで終わりではないんですよね
さて、作成したリソースはちゃんと削除しておきましょう。
まずはノートブックのインスタンス。
作成したときの画面でインスタンスを選択肢アクションから停止を選びます。
停止後、そのインスタンスを利用する予定がないなら削除しておきましょう。
また、S3のバケットも作っているので削除しておきましょう。
バケットは先のコードで取得してると思うので、探して消しちゃいます。
以上でほんとに終わりです!
でわでわ