今回はサンプルデータの顧客関係の予測を利用してみたいと思います。
ワークスペースやクラスターの作成、実行方法等は最初の記事を参考にしてください。
サンプルを開く
それではサンプルを開いてみていきましょう。

今回は割とすっきりしていて見やすいですね。
利用するデータについても見ていきます。今回は二つあるようですね。

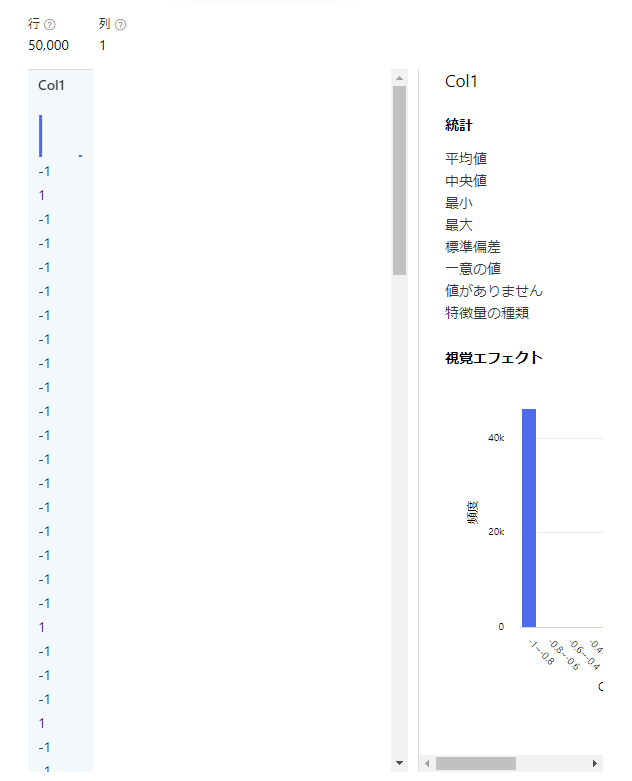
一つには様々なデータが入っており、もう一方には1と-1のデータが入っていますね。
サンプルの内容
モデルを2つ作っているのと、前処理しているところに目が行きますね。
気になる点をピックアップしてみていきましょう。
AddColumns
データの結合をしていますね。
前回の記事でも結合は出てきてましたが、そちらはAddRowsとなっており、行を追加するものでした。
今回のAddColumnsは列の追加になります。
なので新しく別データを追加していることになりますね。
片方の行が少ない場合は小さいソースのカラムに欠損値が埋め込まれるようです。
また、このブロックでは追加するデータを選択することはできず、全データを追加することになるようです。
データの取捨選択は別のブロックを用いて行う必要があるようですね。
SMOTE
さて、続いてSMOTEブロックを見ていきましょう。
SMOTEとは前処理の一種で、二値のデータのカラムをもとに、少ないデータをかさましすることでバランスを調整する手法になります。
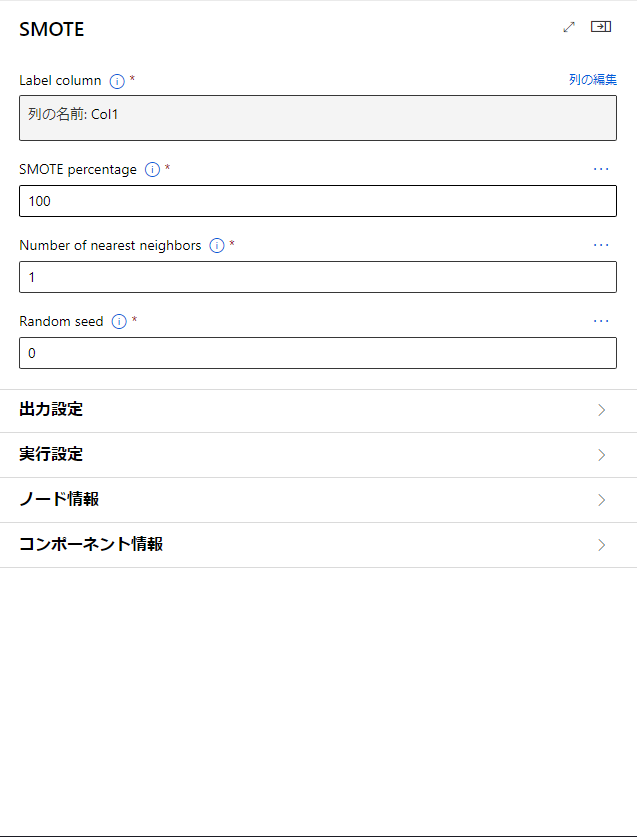
LabelColumnでは基にするカラムを選択します。
SmotePercentageでは増加させる量を指定します。ここでは少ないデータの数の何パーセントを増加させるかを選ぶことができます。
| 多いデータ | 少ないデータ | SmotePrecentage | 処理後の少ないデータ |
|---|---|---|---|
| 570 | 178 | 100 | 356 |
| 570 | 178 | 200 | 534 |
| 570 | 178 | 300 | 712 |
また、このパラメータには100の倍数しか指定できない点に注意しましょう。
Number of nearest neighborsについてですが...あまり理解できませんでした。
ここに指定する数が多いほど特徴を取得できる、とのことなので関係の強そうなデータを生成できるということだと思います。
指定する数が少ないほど元のサンプルに近い特徴を使用する、とのことなので元のデータに似たデータを生成できるということだと思います。
Random seedでは乱数のシード値を設定できます。これにより同じデータが流れてきた際には同様のデータを生成することができ、場合によって結果が変わってしまうことを防ぎます。
それでは実行結果を見てみましょう。
まずは予測結果を見てみたいと思います。

なぜかスコアデータが入ってないように見えます。
よくよく見てみると列が223列とありますがデータ内では99列目までしか映ってないみたいです。
サンプルをいじってみる
予測結果を確認する
確認するためにデータをエクスポートしてみたいと思います。
エクスポートについては昨日やっているのでそちらをご確認ください。
ブロックはこんな感じです。

また、ScoreModelのパラメータに、Append score columns to outputという項目があり、
これは出力結果にスコアと予測結果と実際の値以外のデータを含むかどうかを決めるものらしいので、これをTrueからFalseにして確認してみたいと思います。
まずエクスポートしたcsvを見てみましょう。

ちゃんとデータが入っていました。
あまりにも列が多いとAzureML上だと確認できなくなるようですね。表示最大は100列のようです。
続いてFalseにした結果を見てみましょう。
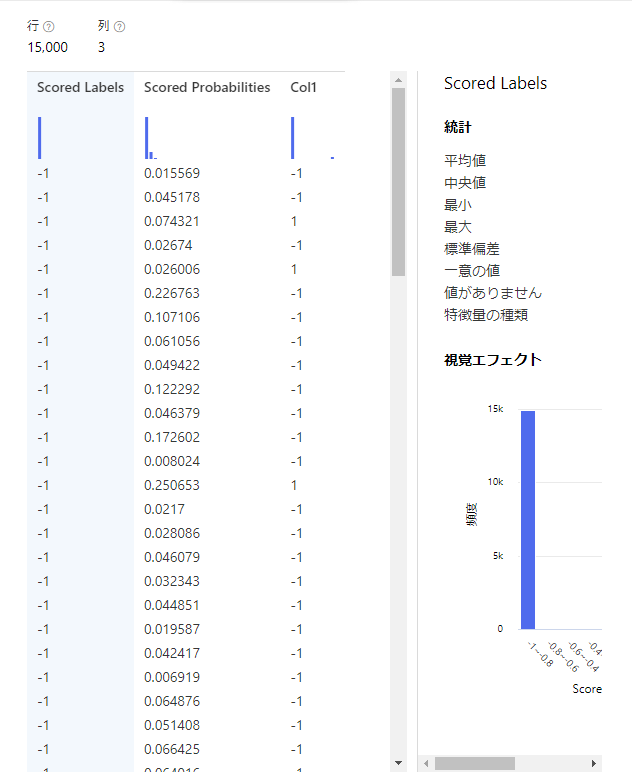
ちゃんと予測値とスコアと実際の値の3列だけになっていますね。
このブロックにつなげた出力も見ておきましょう。

ちゃんと3つだけのデータが出力されていました。
blobからのデータ読み込み
今回利用したデータには2種類あったので、片方をblobから読み込んで実行できるかを試してみたいと思います。
異なるデータソースが結合できたら便利そうですね。
修正箇所は一番上のデータをImportDataに変えた点のみです。

データソースはデータストア、データストアの場所を選択後データのパスを指定します。
ブロックに「!」が表示されていますが、ExportDataのブロックでも表示されたままになっていたので問題はないかなと思います。
それでは実行してみましょう。

こちらが実行結果になります。
前回同様の値が出ています。どうやら問題なくデータを読み込むことができたようです!
まとめ
今回は顧客関係の予測を利用しました。
また、サンプルデータをblobから読み込んで利用してみました。これによってblobに集めたデータで簡単に前処理からモデル作成を行えることがわかりました。
データソースにはHTTP経由のURLも選択できたので、URLでデータのやり取りもできるようです。
こちらも今度試してみたいと思います。