今回はサンプルデータのカスタム Python スクリプトを使用した二項分類 - 信用リスクの予測を利用してみたいと思います。
ワークスペースやクラスターの作成、実行方法等は最初の記事を参考にしてください。
サンプルを開く
それではいつものようにサンプルを開いていきましょう。
今回は上記のサンプルを開いていきます。

開くとこのようになっています。
今までのに比べてとても複雑そうですが、上部から読み解いていきましょう。
サンプルの内容
最初にデータを持ってきています。
ここは変わらないですね。
データの内容も見ておきましょう。

カラム名がわからないですね…このデータをどのように処理していくのでしょうか。
Edit Metadata
次にEdit Metadataというブロックがありますね。
これは接続されたデータを編集してくれるブロックのようです。

Columnでは操作する列を指定してます。
今回はすべての列に対して捜査しているようです。
Data typeではデータの型を指定できるようです。
指定しない場合は何もしないらしいので、今回は何もしないということですね。
利用できるデータの型はString,int,double,bool,DateTimeのようですね。
続いてCategoricalについてです。こちらは選択した列をカテゴリとしてあつかうようにするオプションらしいです。
はい、いいえ、その他のようなデータを0,1,2といったカテゴリ変数に変換してくれるものですね。
こちらも今回はしないみたいですね。
次にFieldsです。こちらは列の種類を選べるオプションみたいです。特徴を使用すると、これらにのみ処理をするフラグを立てられるようになるみたいです。
ラベルを選択すると、ターゲット変数(予測対象)にすることができるようです。
最後にNew column namesですね。これは選択した列に対して新しい列名を設定するためのものです。
今回はすべて選択しているのですべての列名を更新していることになります。この時入力する列名は選択した列の数と同じにする必要があり、入力している順番通りに命名する必要があるようです。
ここまでで前処理をしているということみたいですね。
次はデータの分割をしていますね。
pythonスクリプト
さて、ここからが複雑になっています。
左のブロックから追いかけてみましょう。
一つ目はpythonスクリプトの実行です。

内容は20個目のカラムが1のデータのみ抽出、2のデータのみ抽出して、1のほうのデータ量を5倍に増量してます。
Normalize Data
その後Normalize Dataによって正規化を行います。
この時Credit riskという列は含まないようにしてますね。

以降はいつも通り学習して評価する流れをとっています。
次に真ん中のブロック群ですね。
こちらは左のブロックからpythonスクリプトの実行以外は同じことをしているようです。
学習モデルのテスト後、先のモデルと組み合わせて評価をしているので、前処理によってどうへんかするのかを検証したいのだと思います。
テストデータの流れ
右のほうのブロックを見ていきましょう。
先ほどと同じpythonスクリプトがありますが、こちらはテストデータのほうを処理しているようです。
そのデータの流れを追うと、正規化を経由して先ほどの2つのモデルのテストに、正規化を経由しないで別のモデルのテストに2つ伸びています。
これら二つのブロックを見てみると、片方はpythonスクリプト実行直後のデータ、もう一方は2分割した直後のデータで学習をしています。ともに正規化前のデータなのでテストデータも正規化前のものを利用しているんだと思います。

(ここに正規化ブロックが一つ浮かんでいますが、これは間違いだと思うので削除してから実行してみます。)
学習後の流れ
それぞれテストまで終わったら、正規化したモデルを組み合わせて評価、正規化しなかったモデルを組み合わせて評価を行っています。
さらにそれぞれをAddRowsで組み合わせています。
なるほどこれで結合できたんですね…前回pythonでやってみましたがこれを使えばよかったですね。

その後pythonスクリプトを実行しています。これは合体させたデータに新たにカラム名を設定しているのだと思います。
またわかりやすいように組み合わせを各行に追記してるのでしょう。
最後にSelectColumunsを使ってアルゴリズム、学習内容、精度を表示して比較しやすいようにしているみたいですね。
EditMetadataの実行結果
それでは実際に実行してみます。
実行結果で気になる点を見ていきましょう。
まずはEditMetadataの結果を見ましょう。
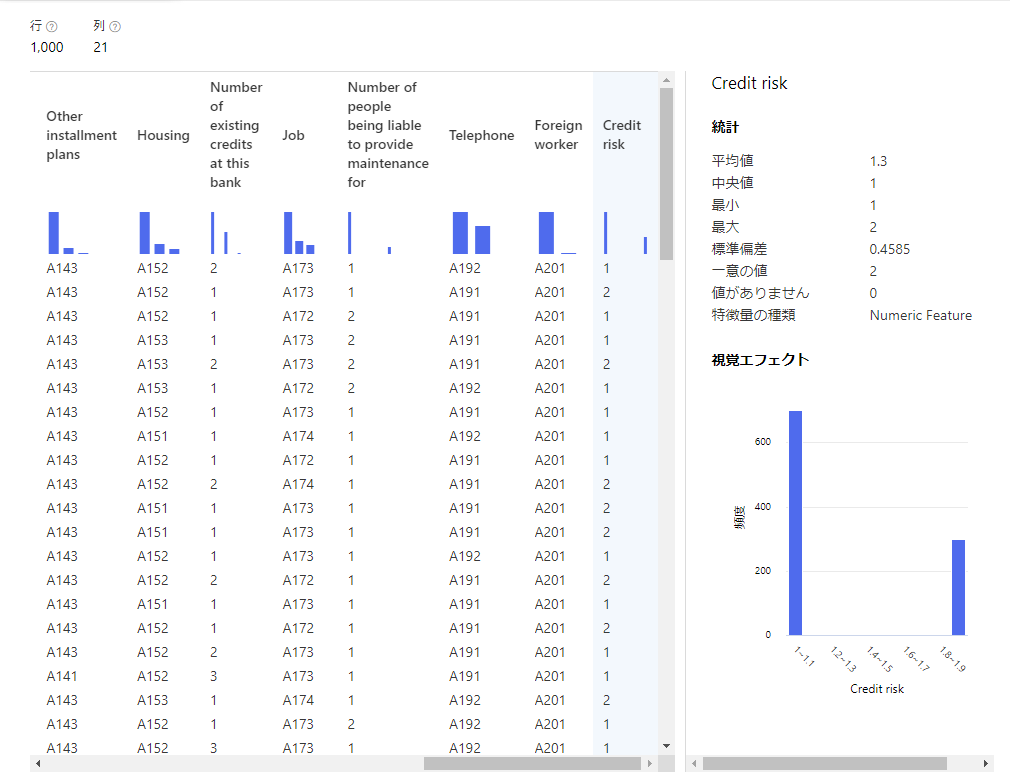
このようにカラムの名前がちゃんとついてることがわかりますね。
これでデータを扱いやすくなりました。
pythonスクリプトの実行結果
次にpythonスクリプトの実行結果を見てみましょう。

CreditRiskの1のデータが増えていますね。
NormalizeDataの結果
NormalizeDataの結果も見てみましょう。

CreditRiskのデータは含めていないので変わっていないですが、NumberOfExisting...のデータは値が変化していますね。
正規化することでほかのデータとの値の変動を一様に判断できるようになるのが正規化の利点ですね。
AddRowsの結果
少し飛ばしてAddRowsの結果を確認してみましょう。
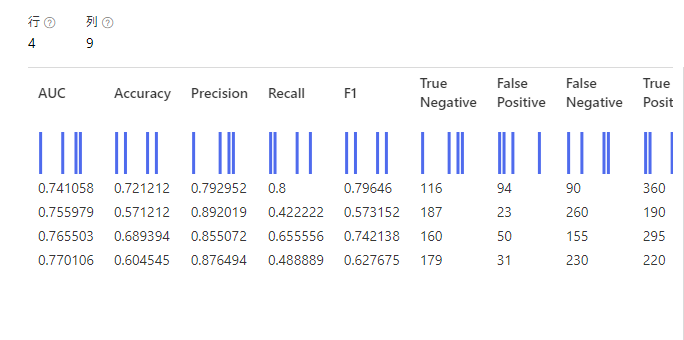
ちゃんと全部のデータを合わせてみることができています。
これなら比較もしやすいですね。
最終実行結果
最後のブロックも確認してみましょう。

このようになっています。
これにより、どのアルゴリズムで何の処理をしたモデルの精度かがわかりやすくなっていますね。
サンプルをいじってみる
それでは、前回やってみたいと言っていた、データのアウトプットをしていきたいと思います。
今回は最後に出てきたデータをcsvとしてblobに出力してみたいと思います。
データの出力にはExportDataというブロックを使います。
利用しているワークスペース以外のストレージも選択できるので少し確認してみましょう。
データストアの追加
新しいデータストアの追加からストレージを追加しましょう。

今回はAzureBlobStorageを追加します。サブスクリプションには利用したいサブスクリプションのIDを持ってきて追加しましょう。
ストレージアカウントには、アクセス可能なものが出てくるので、その中から選択しましょう。
Blobコンテナーは既存のものを選択する必要があるようなので先に作成しておきましょう。
アカウントキーはストレージのページでストレージキーとして確認できるので、確認後こちらに追記しましょう。

ExportData
それではExportDataブロックの設定をしていきましょう。
パスにはコンテナー以降のパスを記述します。
今回データストアではazuremloutputというコンテナーを選択しているため、画像の設定だと
azuremloutput/azuremloutput/evalute.csvというパスにデータが出てくるはずです。
最後にファイル形式を設定します。今回はCSVですね。
それでは実行して確認してみます。
blobを確認してみましょう。
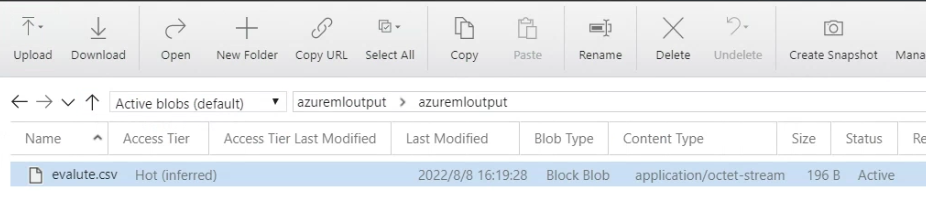
このようにデータが出力されてるのがわかりました。
データの中身も確認してみます。

このように先ほど確認したデータがcsvとして出力されていることがわかりました。
これによりデータをblobで管理できるようになりましたね!
まとめ
今回はカスタム Python スクリプトを使用した二項分類 - 信用リスクの予測を確認してみました。
また、実行結果をblobに出力して確認することもできました。
これによりblobに出したデータを他サービス等で利用したりすることができますね。
次回はblobからデータを読み込むことができるかも確認してみたいですね。