はじめに
UiPath Document Understanding Processのテンプレートに、生成AIによる抽出もサポートできる様にカスタマイズする方法を記載します。現在(2023年12月時点)公開中のUiPath Document Understanding Processテンプレート(英語版) v2022.10では、対応されていないため、いち早く、本ブログの日本向けテンプレートでは越えていきたいと思います。
前提
- 本ブログではUiPath Document Understanding Process日本向けテンプレートの作り方(#1 初期設定)で作成したテンプレートを使ってカスタマイズしています。ただし、公式の英語版UiPath Document Understanding Processでも変更箇所は同じです。
- UiPath Studio v203.10.2を利用しています。
生成AIによる分類と抽出の対応箇所
テンプレートに入れるサンプル帳票の準備とタクソノミーを定義します。その後に、30_Classify(分類)と50_Extract(抽出)に生成AIを利用するための処理を追加します。Document Understanding Processの全体構成から見た本ブログでの対応場所は下記の赤枠の部分です。
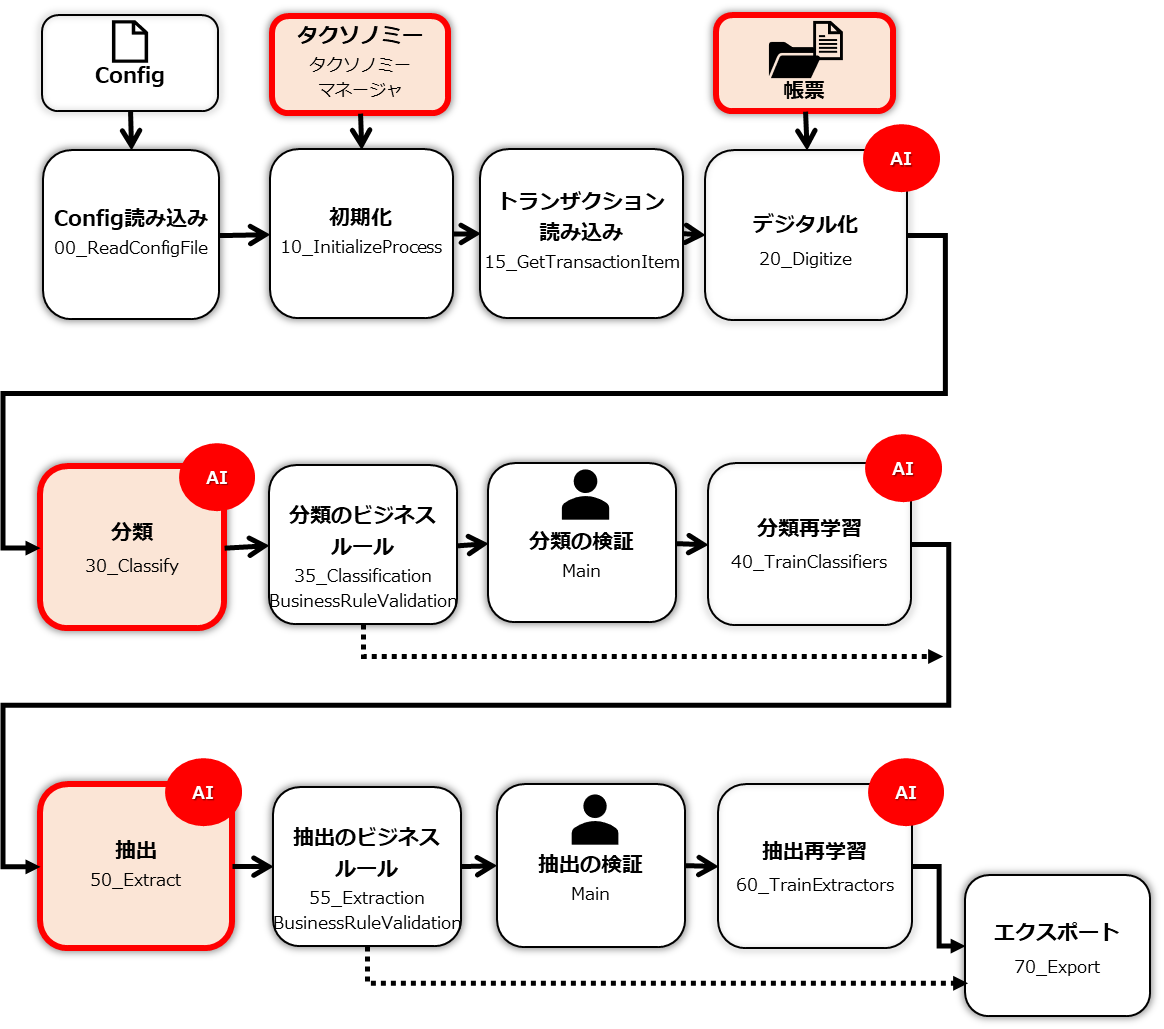
手順
1. アクティビティのバージョンを変更する
はじめに、生成AIによる分類と抽出がサポートされているアクティビティのパッケージバージョンに変更する必要があります。「パッケージを管理」から、下記のパッケージバージョンに変更してください。
❶ UiPath.DocumentUnderstanding.ML.Activities v1.24.0以上
❷ UiPath.IntelligentOCR.Activities v6.14.1以上
2. サンプル帳票の準備
生成AIを利用するサンプル帳票は、基本何でも良いですが、ここでは自由書式の職務経歴書を準備します。後程、UiPath Document Understanding Process日本向けテンプレートの作り方(#1 初期設定)のフォーム抽出で準備した厚生労働省様式の履歴書サンプルでも同様の結果が得られるか確認しようと思います。
職務経歴書山田太郎.pdf
Wordのテンプレートで提供されている履歴書を少しアレンジしてpdf化したものです。

3.タクソノミーマネージャの設定
グループは「Semi-StructuredDocuments」(半構造化されたドキュメント)>カテゴリは「プロフィール」>ドキュメントの種類は「職務経歴フリー書式」に定義します。グループは「Documents」でも良いですが、項目が決まっており、フォーマットが自由書式と仮定して、ここでは「Semi-StructuredDocuments」としています。
< 定義する場所 >

< 各フィールドの詳細 >
読み取りたいフィールドを下記の様に設定します。
ちなみに、生成AI利用時に、フィールドの種類を区別しても抽出の有効な情報には使われないため、全てTextにしてます。
| フィールド名 | 種類 |
|---|---|
| 名前 | Text |
| 現住所 | Text |
| 連絡先電話番号 | Text |
| 連絡先メールアドレス | Text |
| 年齢 | Text |
| 学歴1学校名 | Text |
| 学歴1在籍期間 | Text |
| 学歴2学校名 | Text |
| 学歴2在籍期間 | Text |
| 学歴3学校名 | Text |
| 学歴3在籍期間 | Text |
| 職歴1会社名 | Text |
| 職歴1在籍期間 | Text |
| 職歴2会社名 | Text |
| 職歴2在籍期間 | Text |
| 職歴3会社名 | Text |
| 職歴3在籍期間 | Text |
| スキル | Text |
| 日付 | Text |
生成AI抽出器ではフィールドの種類のTableはサポートされてません。
- フィールドの種類でTableを選び、フィールドを設定しても、生成AIの抽出器の設定項目には表示されません。そのため、テーブル形式のデータ抽出については、固定数になりますが、読み取るフィールドを個々で用意して置く必要があります。
- このサンプルでは、Tableと同等の抽出を行うために、この様に個々のフィールドを設けてますが、フィールド数が固定できない場合やフィールド作成が面倒な場合、後ほど解説するプロンプトの指示で、まとめて1フィールドに読み取ってくることも可能です。
4.「30_Classify」(分類)の生成AIの分類器を追加設定
(1)「30_Classify」の「ドキュメント分類スコープ」アクティビティの中に生成AIの分類器である「Generative Classifier」アクティビティを追加します。「Generative Classifier」アクティビティに表示されている「Manage Prompt」をクリックします。
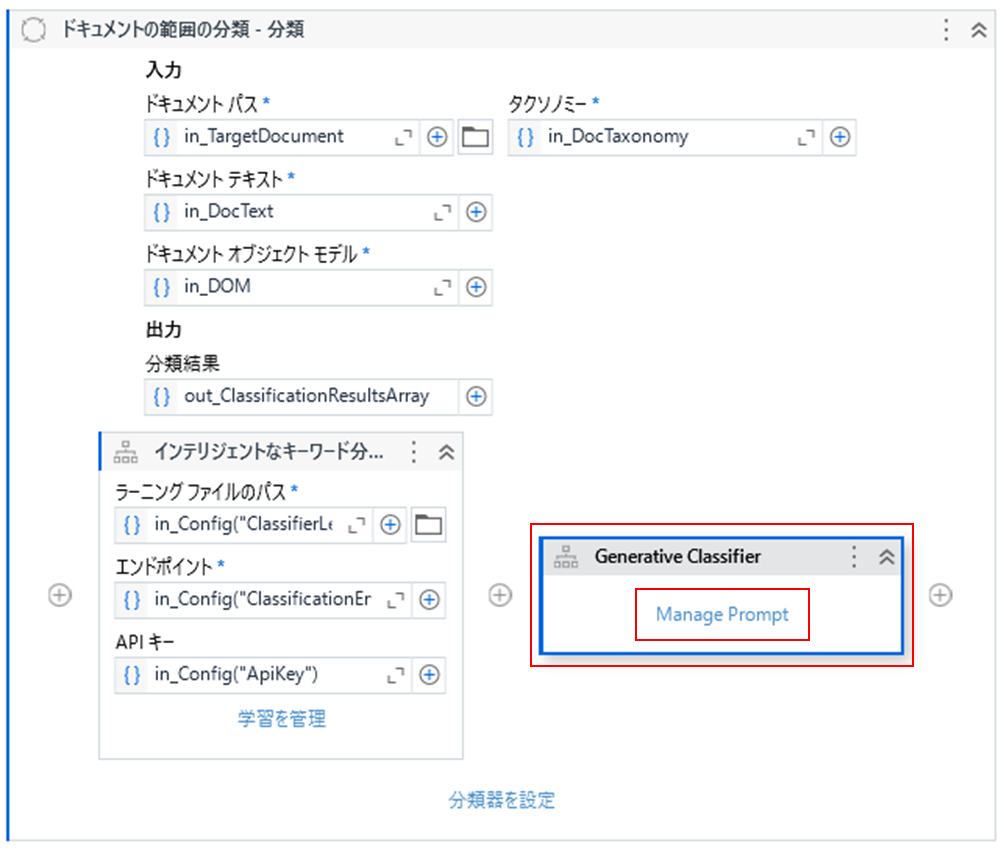
(2)分類を指示できるプロンプト入力画面が表示されるので、下記の様に入力して保存します。

(3)「分類器を設定」をクリックします。

(4)最小信頼度(インテリジェントなキーワード分類器-分類)を80%に設定します。
職務経歴フリー書式(Generative Classifier)にチェックをして保存します。
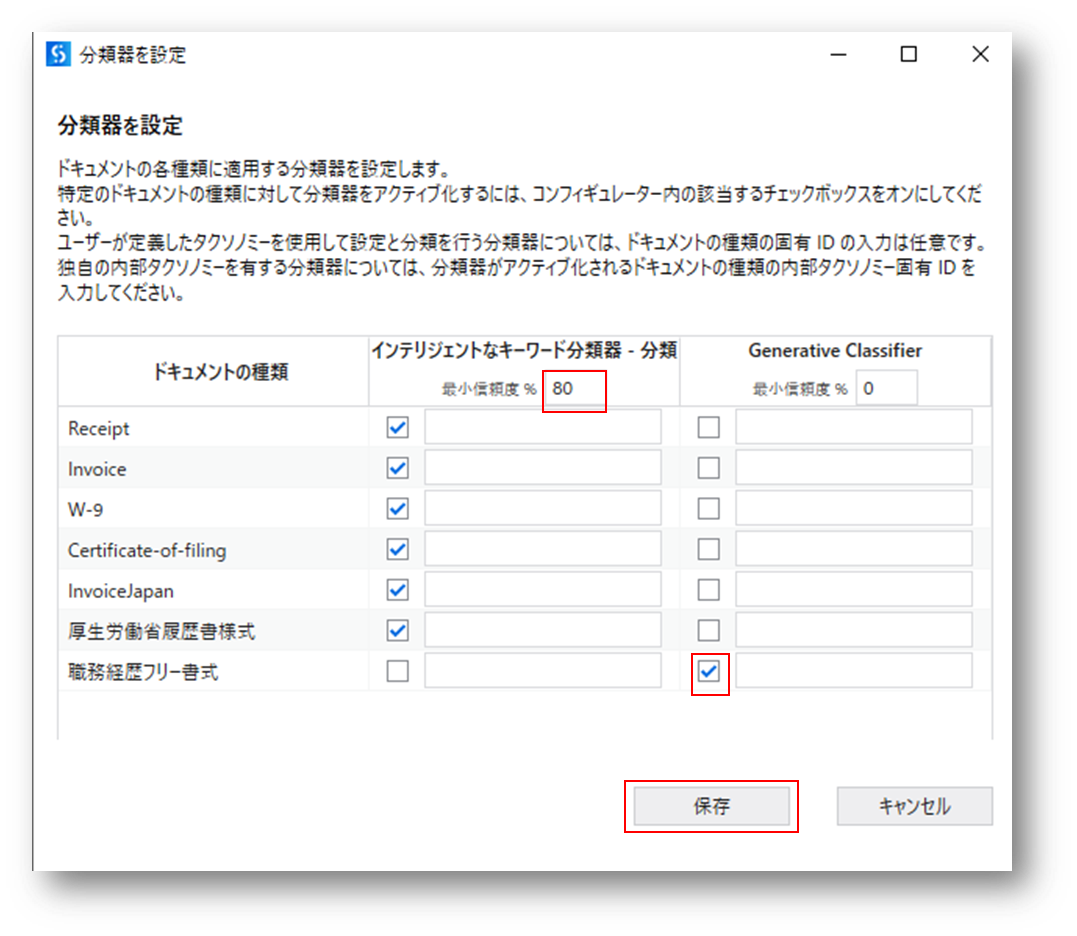
分類器は左から右へと順に評価されますが、インテリジェントなキーワード分類器の最小信頼度が0に設定されていると、この分類器でチェックされているドキュメントの種類で最も信頼度の高いものに必ず分類されるため、右にあるGenerative Classifierは評価しに行かない様です。つまり、この場合はインテリジェントなキーワード分類器で既にチェックされている「厚生労働省履歴書様式」に分類されてしまいます。そこで、最小信頼度を80%に設定し、Generative Classifierに評価を渡す様にしています。
尚、今回、Generative Classifierのプロンプトに”厚生労働省履歴書様式以外”と指定していますが、このままでは意味のない指定になってます。インテリジェントなキーワード分類器の「厚生労働省履歴書様式」のチェックを外し、代わりにGenerative Classifierの「厚生労働省履歴書様式」のプロンプトに"厚生労働省履歴書様式"と入力すると、厚生労働省履歴書様式の履歴書は80%の信頼度で分類され、職務経歴書サンプルは、職務経歴フリー書式に90%の信頼度で分類されてきたので、今後、どちらのパターンでも利用できる様に、この文言のまま残しています。
5.「50_Extract」で生成AIの抽出器を追加
(1)「50_Extract」の「データ抽出スコープ」アクティビティの中に生成AIの抽出器である「Generative Extractor」アクティビティを追加します。「Generative Extractor」アクティビティに表示されている「Manage Prompt」をクリックします。
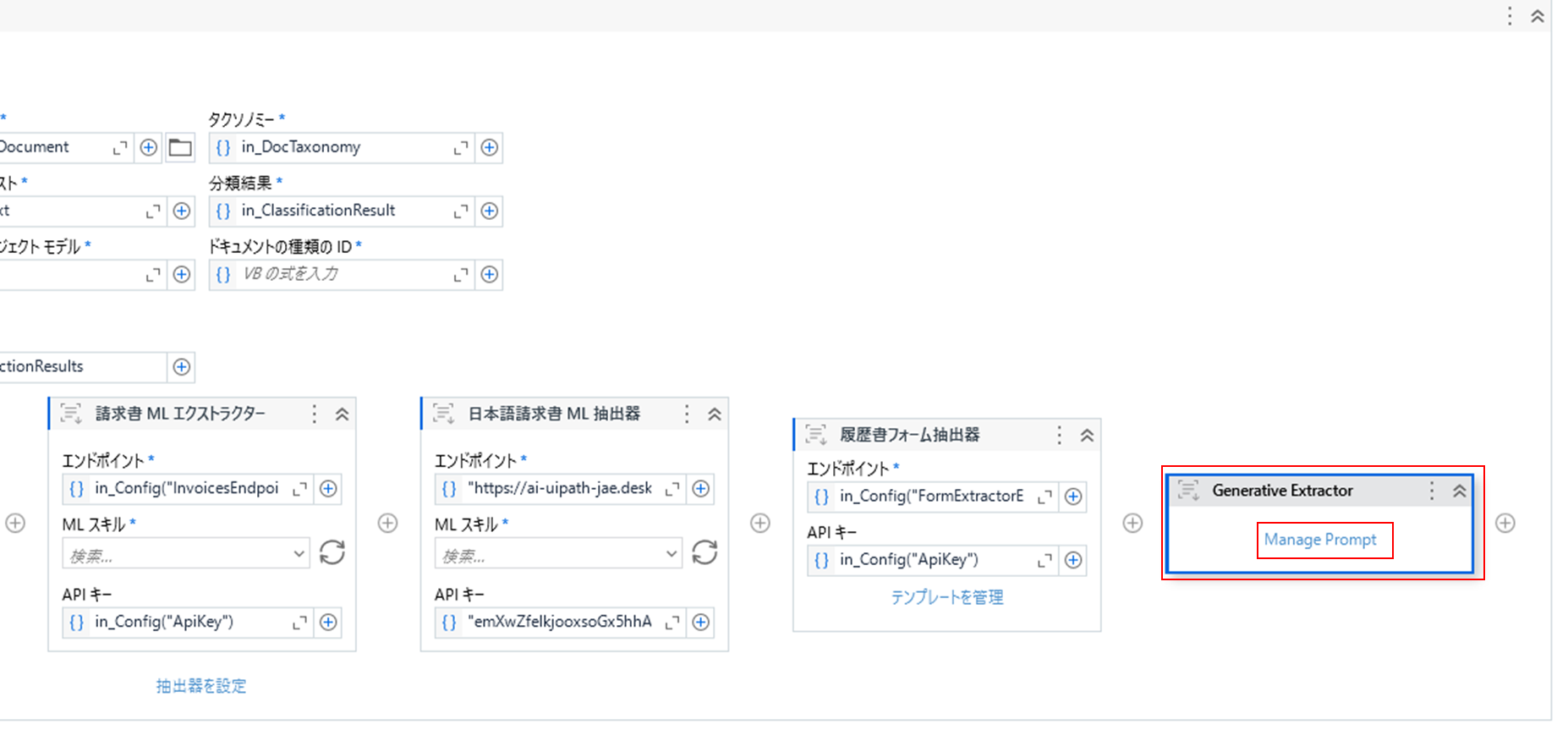
(2)抽出を指示できるプロンプト入力画面が表示されるので、下記の様に入力して保存します。尚、スキルには、生成AIならではで、プロフィールや保有技術を要約を指定してみました。

| フィールド名 | プロンプト |
|---|---|
| 名前 | 氏名を教えてください。 |
| 現住所 | 現住所を教えてください。 |
| 連絡先電話番号 | 連絡先の電話番号を教えてください。 |
| 連絡先メールアドレス | 連絡先のメールアドレスを教えてください。 |
| 年齢 | 年齢を教えてください。 |
| 学歴1学校名 | 学歴の1つ目の学校名や学部や学科および、その学校を卒業したのか中退したのかを教えてください。 |
| 学歴1在籍期間 | 学歴の1つ目の在籍期間(開始年月日-終了年月日)を教えてください。 |
| 学歴2学校名 | 学歴の2つ目の学校名や学部や学科および、その学校を卒業したのか中退したのかを教えてください。 |
| 学歴2在籍期間 | 学歴の2つ目の在籍期間(開始年月日-終了年月日)を教えてください。 |
| 学歴3学校名 | 学歴の3つ目の学校名や学部や学科および、その学校を卒業したのか中退したのかを教えてください。 |
| 学歴3在籍期間 | 学歴の3つ目の在籍期間(開始年月日-終了年月日)を教えてください。 |
| 職歴1会社名 | 職歴の1つ目の会社名や所属を教えてください。 |
| 職歴1在籍期間 | 職歴の1つ目の会社の在籍期間(開始年月日-終了年月日)を教えてください。 |
| 職歴2会社名 | 職歴の2つ目の会社名や所属を教えてください。 |
| 職歴2在籍期間 | 職歴の2つ目の会社の在籍期間(開始年月日-終了年月日)を教えてください。 |
| 職歴3会社名 | 職歴の3つ目の会社名や所属を教えてください。 |
| 職歴3在籍期間 | 職歴の3つ目の会社の在籍期間(開始年月日-終了年月日)を教えてください。 |
| スキル | プロフィールや保有技術を要約して教えてください。 |
| 日付 | 帳票の日付を教えてください。 |
(3)「抽出器を設定」をクリックします。

(4)「職務経歴フリー書式」の「Generative Extractor」をチェックし、保存します。

6.実行する
職務経歴書山田太郎.pdfを選択
(1)分類ステーションでは90%の信頼度で「職務経歴フリー書式」で分類されてきました。

(2)抽出ステーションで確認すると、ちゃんとデータが抽出されている様です。

スキルのフィールドで「プロフィールや保有技術を要約して教えてください。」と指定した結果、"プログラマを担当していました。趣味はC言語、C++言語、C#、Java、UiPathです。"と格納されていました。山田さんはC言語、C++言語、C#、Java、UiPathも趣味かも知れません。(笑)
プロンプトを見直せば、もう少し期待通りの要約してくれますが、あえて、このまま掲載しておきます。

(3)Excelへの出力結果です。

履歴書富士花子.pdfを選択
試しに厚生労働省履歴書様式で作成した履歴書を、生成AIで抽出する「職務経歴フリー書式」で通して見ました。
(1)分類ステーションでは、当然、「厚生労働省履歴書様式」に分類されてくるので、ここで「職務経歴フリー書式」に変更することで、生成AI抽出器が使われます。

(2)抽出ステーションで確認すると、ちゃんとデータが抽出されている様です。
※スキルに関連する情報は、履歴書に書いてないので抽出はされません。
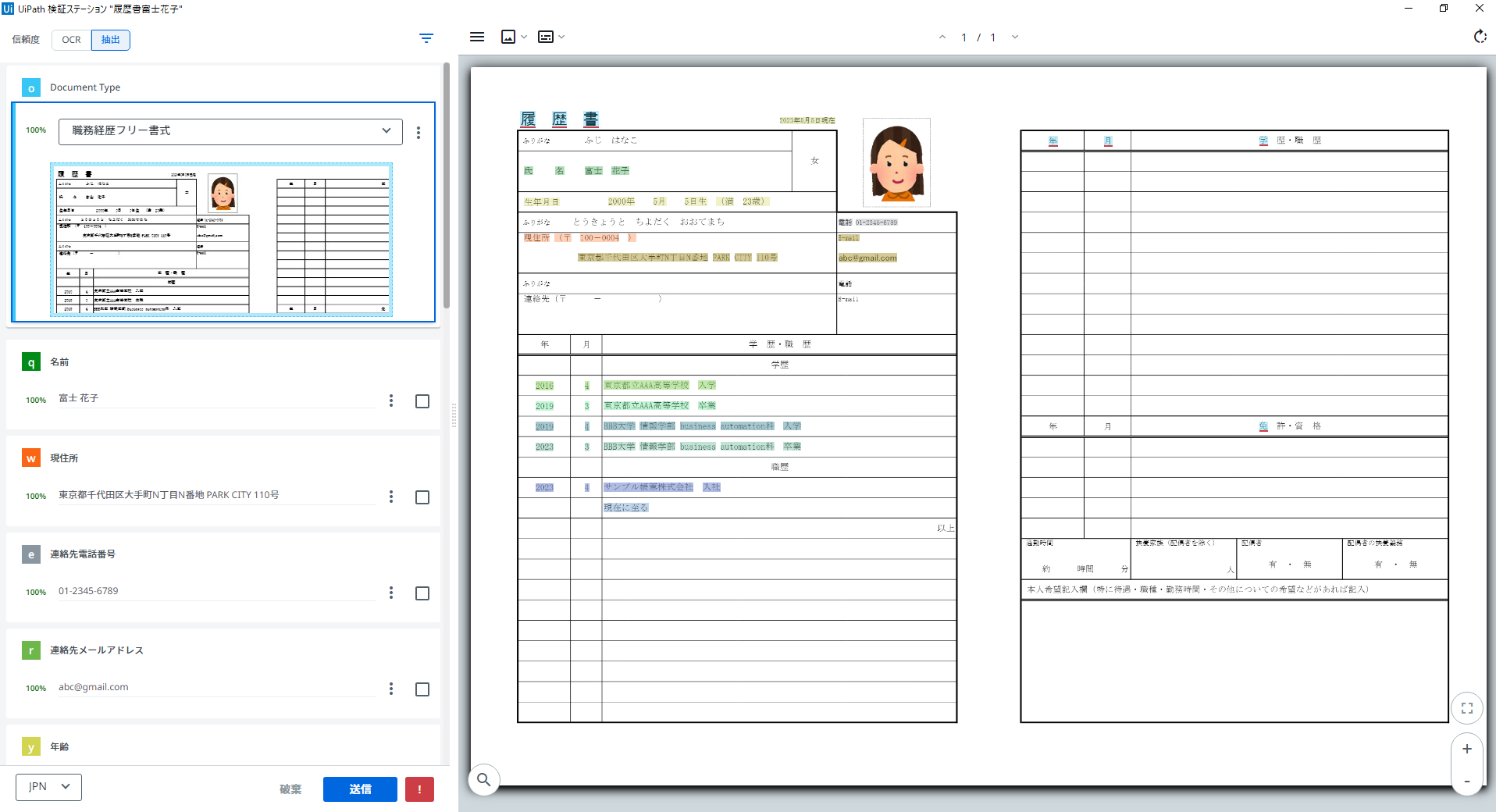
(3)Excelへの出力結果です。

おわりに
ML抽出の様な学習のための多くのデータ集めや面倒なラベリング作業の労力を必要とせず、プロンプトに指示や質問を入力するだけで、そこそこの精度で抽出できる様になってます。検証ステーションやAction Centerによる確認に頼る前提に割り切ってしまえば、正直、こっちをお勧めしたくなる感じです。本ブログを執筆し、全部とは言えませんが、生成AIの登場で、使いどころによっては、従来使われていたAIを、従来のAI専門知識や労力なしに軽く超えてくる、そんな時代の到来を感じました。