はじめに
UiPath Document Understandingは、個々の機能をアクティビティで提供しており、UiPathのローコードプラットフォーム上でドキュメント処理をユーザーに適した仕様に細かくカスタマイズできる点も特徴の一つです。つまり、ブラックボックスで利用する前提ではないと言うことですが、アクティビティを使って、一から組み上げる前提だと、すぐに利用できません。そこで、一般的な機能を入れたDocument Understanding Processテンプレートを提供し、短時間で利用開始できる様になっています。
Document Understanding Processとは
Document Understanding Processは、ドキュメント処理フローチャートに基づいた非常に機能的な UiPath Studio プロジェクトテンプレートです。UiPath公式のドキュメントポータルでもテンプレートの使用を強く推奨しており、Document Understandingを使ったワークフローを作成する際のお手本と考えても良いでしょう。個人的にも、最初から完成度を高めるためにテンプレートの利用をお勧めします。
本記事の目的
Studioから選択できるDocument Understanding Processテンプレートは、2023年8月時点では日本向けのテンプレートが公開されていないため、日本帳票を扱う上で、元の英語版レベルで機能するための日本向けテンプレートを準備しておくことが有効だと著者は考えました。本ブログでは、その作り方を解説します。
作り方の全体構成
UiPath Document Understanding Process日本向けテンプレートの作り方の記事の全体構成です。いくつかの記事(下記、掲載場所)に分けて連載します。
| 内容 | 抽出方法 | 掲載場所 |
|---|---|---|
| Studioで選択できるテンプレートを日本語に変換 | - | 本記事 |
| ログメッセージの日本語化 | - | 本記事 |
| テンプレートが参照するアセットの作成 | - | 本記事 |
| 日本語OCR対応「20_Digitize」(デジタル化)の変更 | - | 本記事 |
| 日本向けフォーム抽出サンプル帳票の準備 | フォーム抽出 | 本記事 |
| タクソノミーマネージャの設定 | フォーム抽出 | 本記事 |
| 「30_Classify」(分類)の追加設定 | フォーム抽出 | 本記事 |
| 「40_TrainClassifiers」の設定 | フォーム抽出 | 本記事 |
| Configへ日本語用フォーム抽出器のエンドポイント追加 | フォーム抽出 | 本記事 |
| 「50_Extract」で履歴書フォーム抽出器を追加 | フォーム抽出 | 本記事 |
| フォーム抽出 CJK-OCR対策 | フォーム抽出 | #2 フォーム抽出 CJK-OCR対策 |
| ChatGPTを組み込んだ部分的な改良 | フォーム抽出 | #4 ChatGPTを組み込んだ部分的な改良 |
| InvoicesJapan(請求書-日本)-MLパッケージ利用のサンプル帳票の準備 | ML抽出 | 本記事 |
| タクソノミーマネージャの設定 | ML抽出 | 本記事 |
| 「30_Classify」(分類)の追加設定 | ML抽出 | 本記事 |
| 「40_TrainClassifiers」の設定 | ML抽出 | 本記事 |
| ConfigへInvoicesJapan (請求書 - 日本) - ML パッケージのエンドポイント追加 | ML抽出 | 本記事 |
| 「50_Extract」で日本語請求書 ML 抽出器を追加 | ML抽出 | 本記事 |
| InvoicesJapan対応ビジネスルール | ML抽出 | #3 InvoicesJapan対応ビジネスルール |
全体構成の中で本記事(#1 初期設定)の設定箇所
Document Understanding Processテンプレートの処理の流れと、個々ブロックのファイルを図に表現してみました。赤枠部分が、本記事(#1 初期設定)で設定する箇所です。
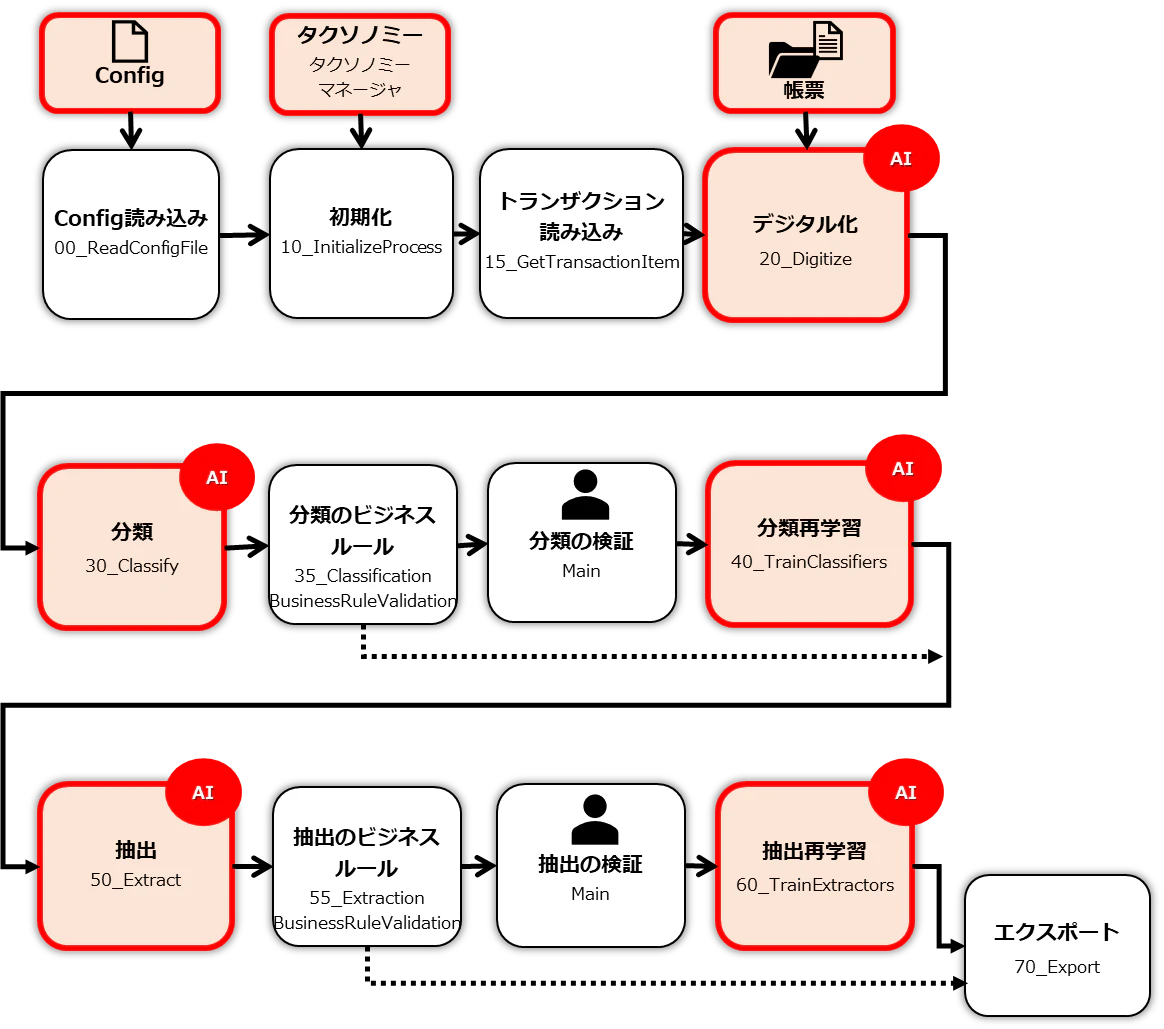
1. Studioで選択できるテンプレートを日本語に変換
Studioで選択できるDocument Understanding Processテンプレートは英語です。Robotic Enterprise Frameworkも未だに英語なので、ここでの日本語版公開は期待出来ません。とは言っても、Document Understanding Processはテストケースも含め60以上のワークフローが入ってますので、これを翻訳して、全て書き換えるのは大変な作業です。そこで、UiPath Marketplaceに公開(著者作)している「Workflow Translator」を使って英語のワークフローを翻訳して日本語版のワークフローを出力します。これはアクティビティの表示名、注釈、コメントアクティビティの説明が指定した国の言語に翻訳されます。一部手直しした結果ですが下記の様な日本語のワークフローを約30分程で作成することができます。
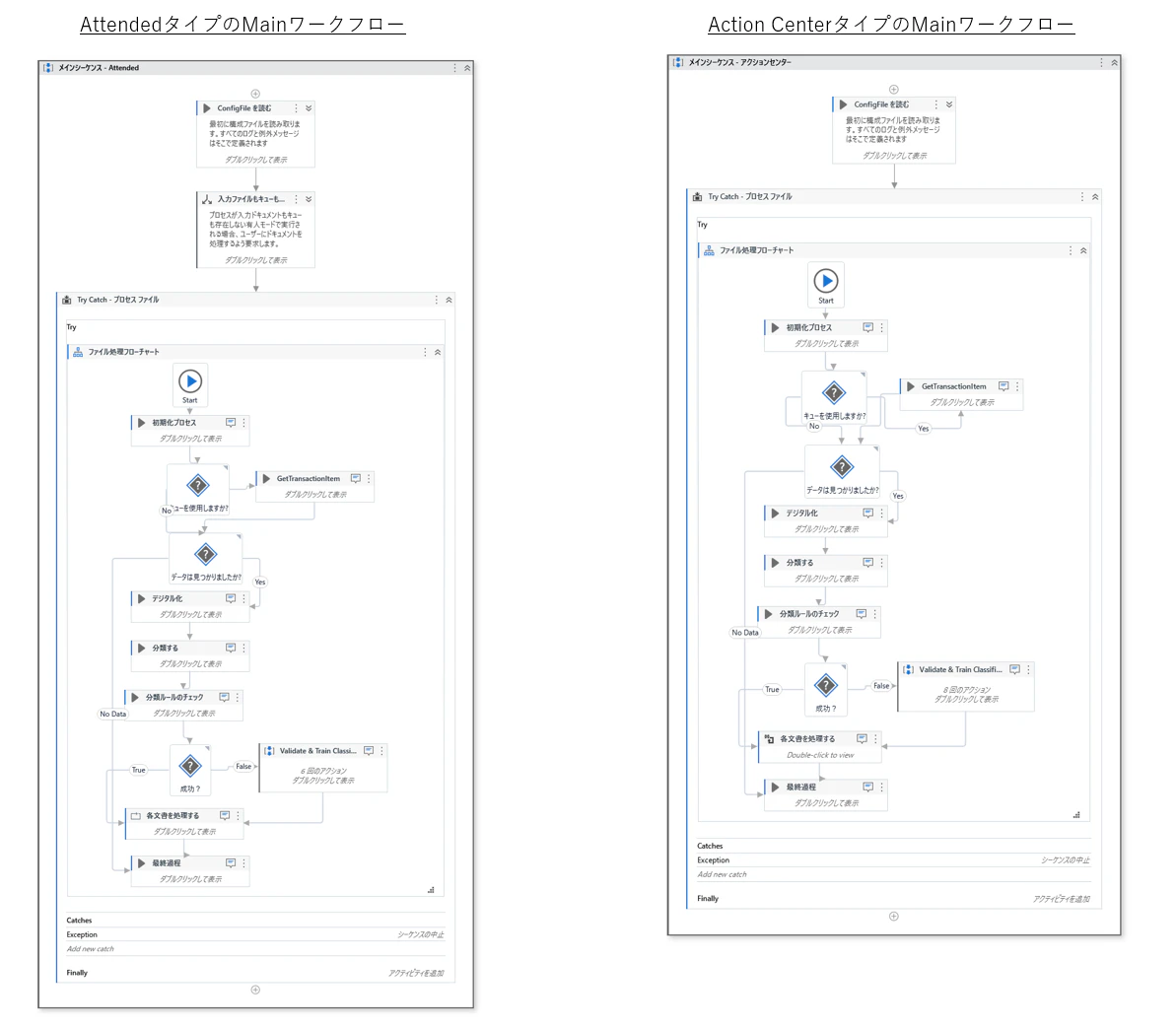
Workflow Translatorの補足
- Workflow TranslatorはWindowsプロジェクト(.net6)に対応していませんので、Windowsレガシーでの利用が必要です。Document Understanding Processのプロジェクト自体はWindowsプロジェクトですが、今のところ変換に問題ない様です。
- 文字列に”#”、”&”、 ”+”等が含まれていた場合は翻訳しない仕様にしており、一部翻訳されていない箇所があります。そして機械翻訳なので必要でに応じて手動で書き換えが必要です。
2. ログメッセージの日本語化
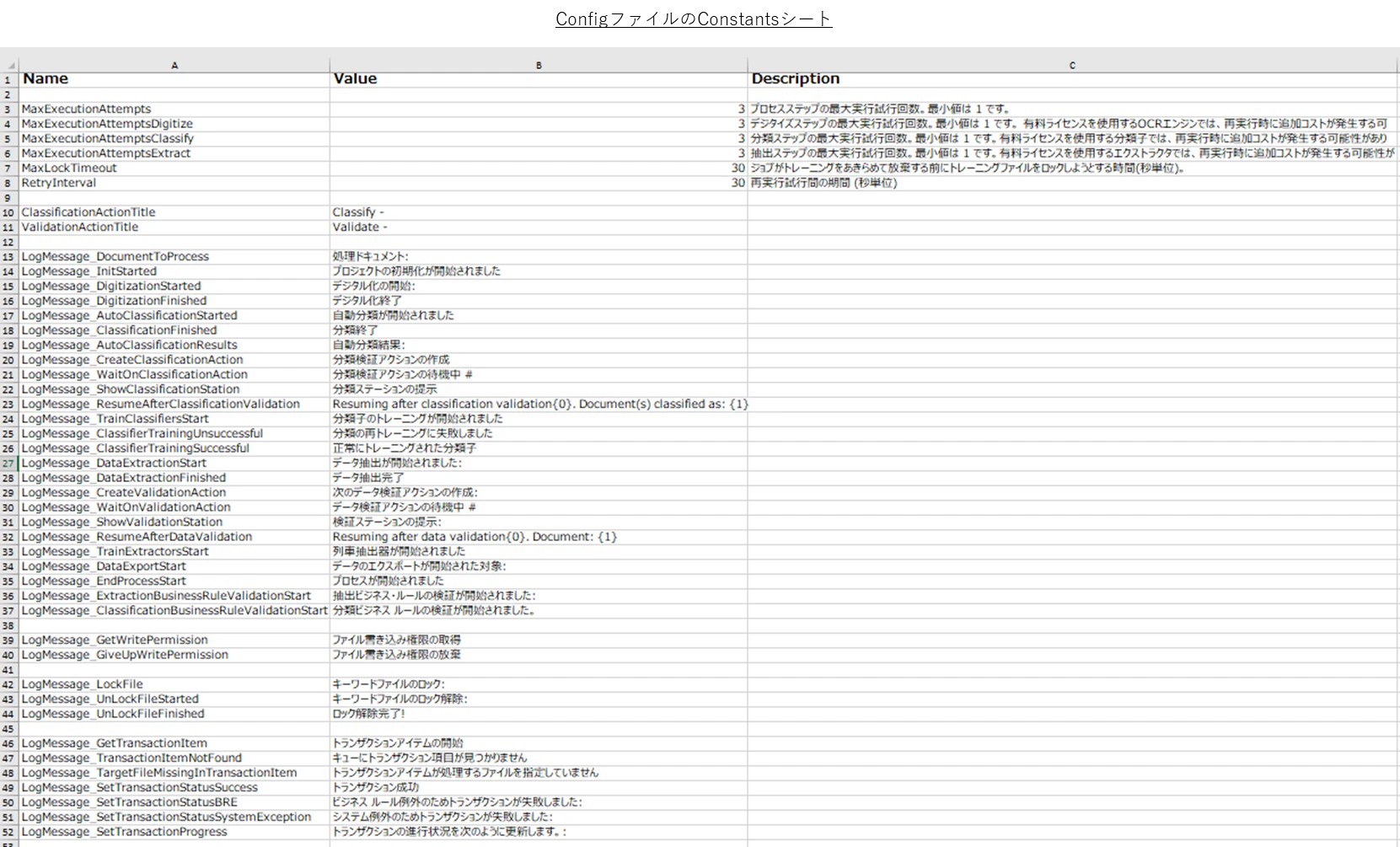
実行時に出力されるログメッセージは、Config.xlsxにメッセージが入っているので、このメッセージを日本語に変更します。Workflow TranslatorではConfig.xlsxの翻訳変換はサポートしていませんので、手動で書き換えします。量は多くありません。下記はConstantsシートを翻訳した例です。同様に、少なくともSettingsシート、Assetsの説明欄も翻訳して置くと良いでしょう。
< \Data\Config.xlsx >
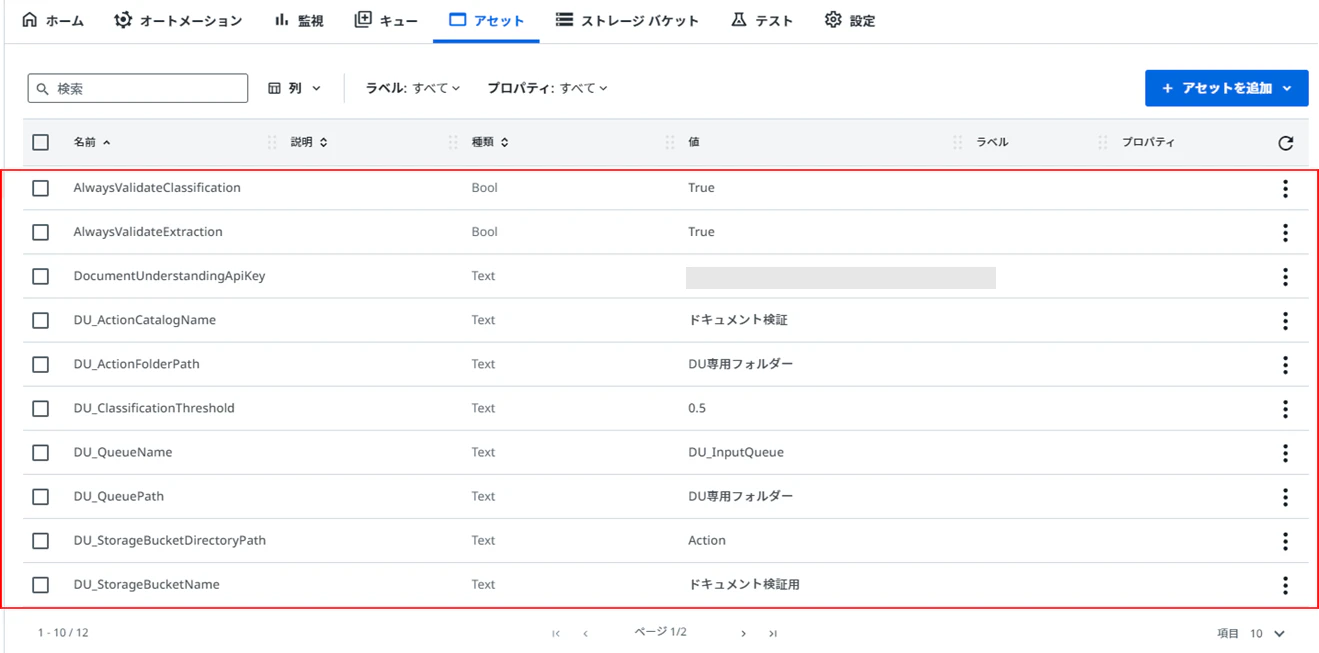
3. テンプレートが参照するアセットの作成
ConfigのAssetsシートにあるアセットをOrchestratorに設定します。Attendedで検証ステーションを使うのでAction Centerは使わない、Queueも使わない等で必ずしも全て登録して置く必要はありませんが、本稿はテンプレート目的なので、あらゆる利用方法で機能する前提で全て登録しています。
< ConfigのAssetsシート >

< Orchestratorのアセット >
アセットに格納するApiKeyの取得方法
ApiKeyはAutomation Cloudのライセンスページの「ロボットとサービス」タブから取得します。

4. 日本語OCR対応
日本語OCRはCJK-OCR(日中韓)を利用します。この章では、CJK-OCRに差し替える手順を説明します。
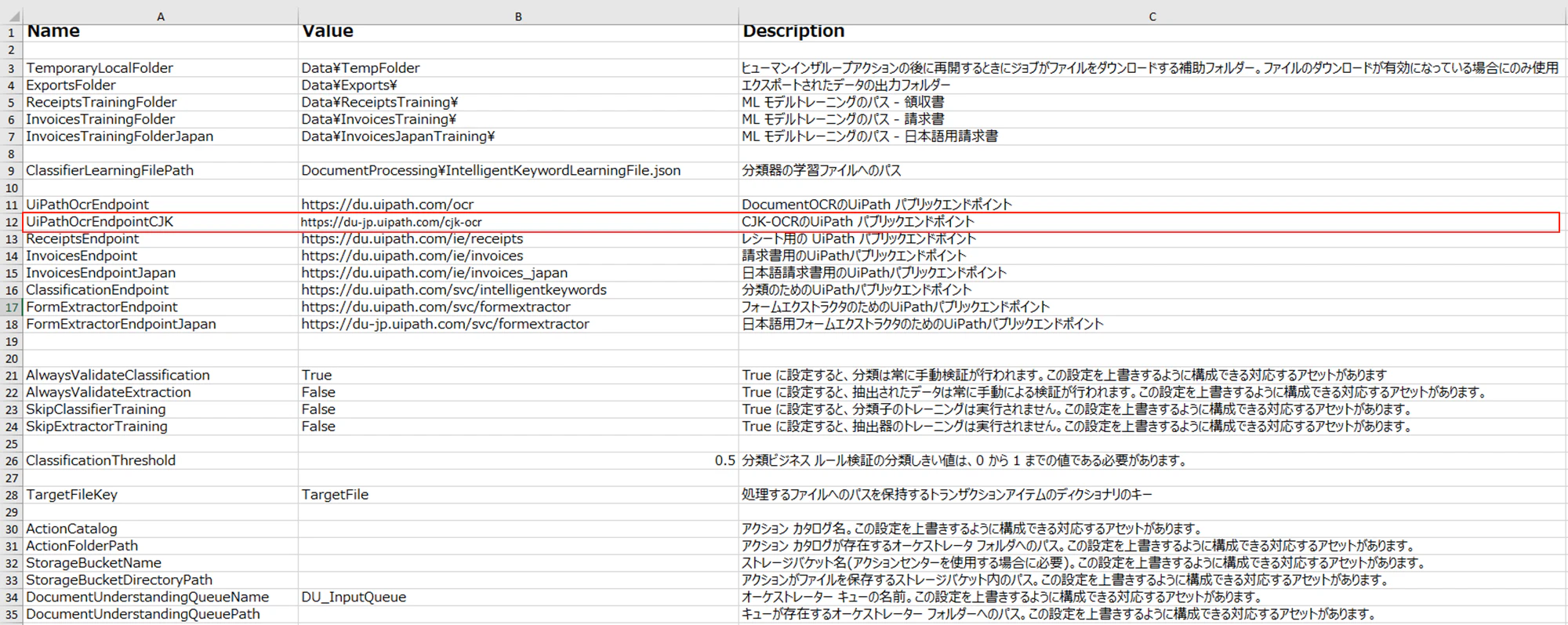
4.1 ConfigにCJK-OCRのエンドポイントを追加
Configの「Settings」シートにCJK-OCRのエンドポイントを追加します。
| Name | Value | Description |
|---|---|---|
| UiPathOcrEndpointCJK | https://du-jp.uipath.com/cjk-ocr | CJK-OCRのUiPath パブリックエンドポイント |
本記事に掲載している全て画像(これ以降も含む)は既に完成しているテンプレートでキャプタしたものです。つまり、手順の途中で、まだ設定されていない箇所も画像には含まれていますのでご注意ください。
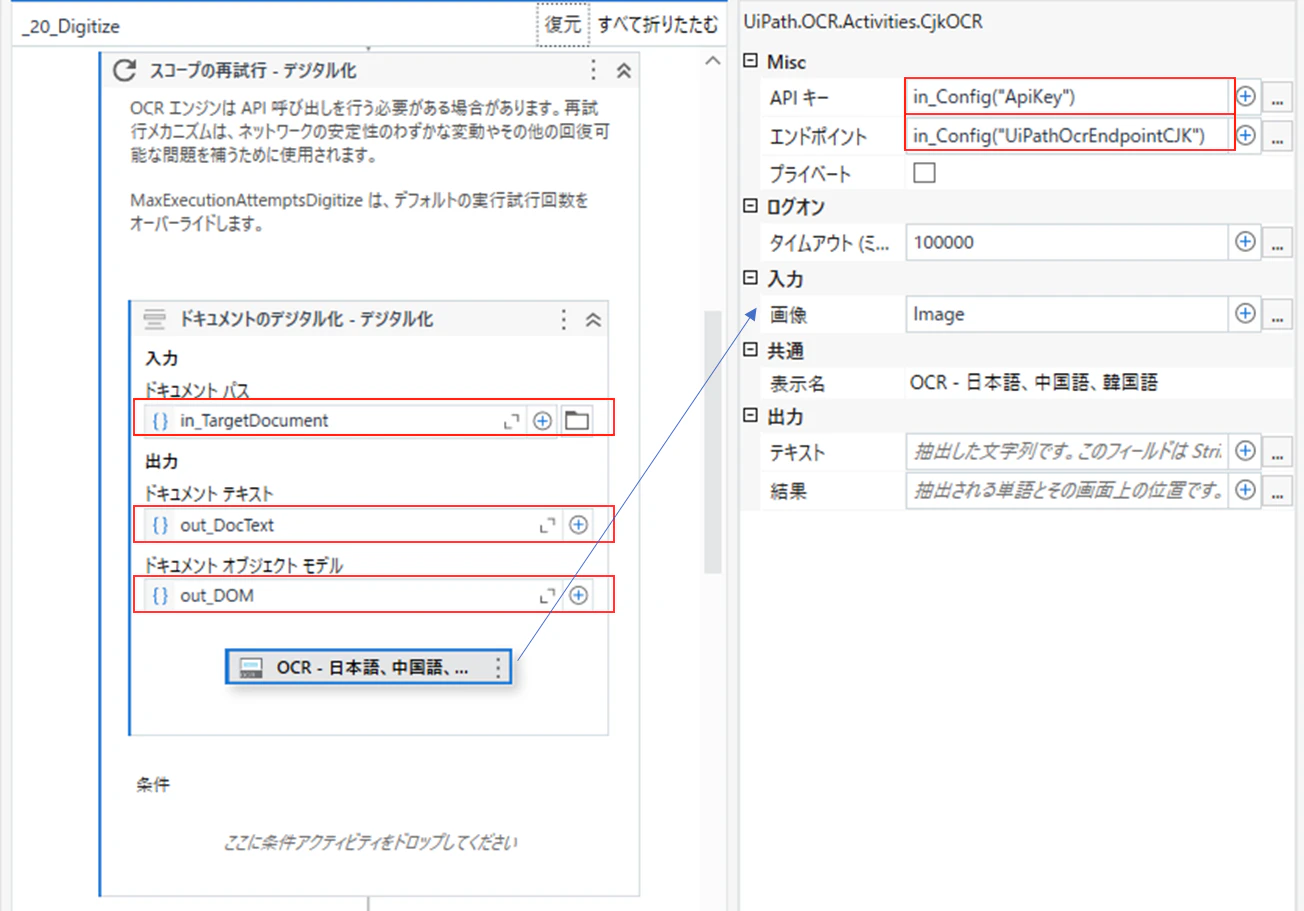
4.2 「20_Digitize」(デジタル化)の変更
「ドキュメントのデジタル化」アクティビティと、その中の「OCR - 日本語、中国語、韓国語」アクティビティを入れ替えて、各プロパティを下記の様に設定します。
5. 日本向けフォーム抽出サンプル
この章では、構造化(定型帳票)された帳票の読取りで利用する「フォーム抽出」のサンプル作成手順を説明します。英語のサンプル帳票W9に相当するものです。
5.1 サンプル帳票の準備
フォーム抽出のサンプル帳票は、基本何でも良いですが、ここでは入手し易い、履歴書の厚生労働省様式を利用しています。
①【書式】履歴書厚生労働省様式.pdf
分類のトレーニングでは、念のため、内容が記載されていない書式で、かつ写真貼り付け枠の文字も読み込む帳票には出てこないため、消したりと少し工夫しています。
文字取得できるPdfファイルです。

②履歴書富士太郎.png
「ドキュメントのデジタル化」アクティビティのプラパティ「PDFにOCRを適用」をAutoにすると、文字取得できるフィールドでは、OCRは機能しません。OCRを機能させるパターンも欲しかったため、画像ファイルのサンプル帳票を1つ用意しました。画像ファイルから変換したPdfファイルでもOKです。

③履歴書富士花子.pdf
文字取得できるPdfファイルのサンプル帳票を1つ用意しました。

5.2 タクソノミーマネージャの設定
グループは「Structured Documents」(構造化されたドキュメント)>カテゴリは「履歴書」>ドキュメントの種類は「厚生労働省履歴書様式」に定義します。
< 定義する場所 >
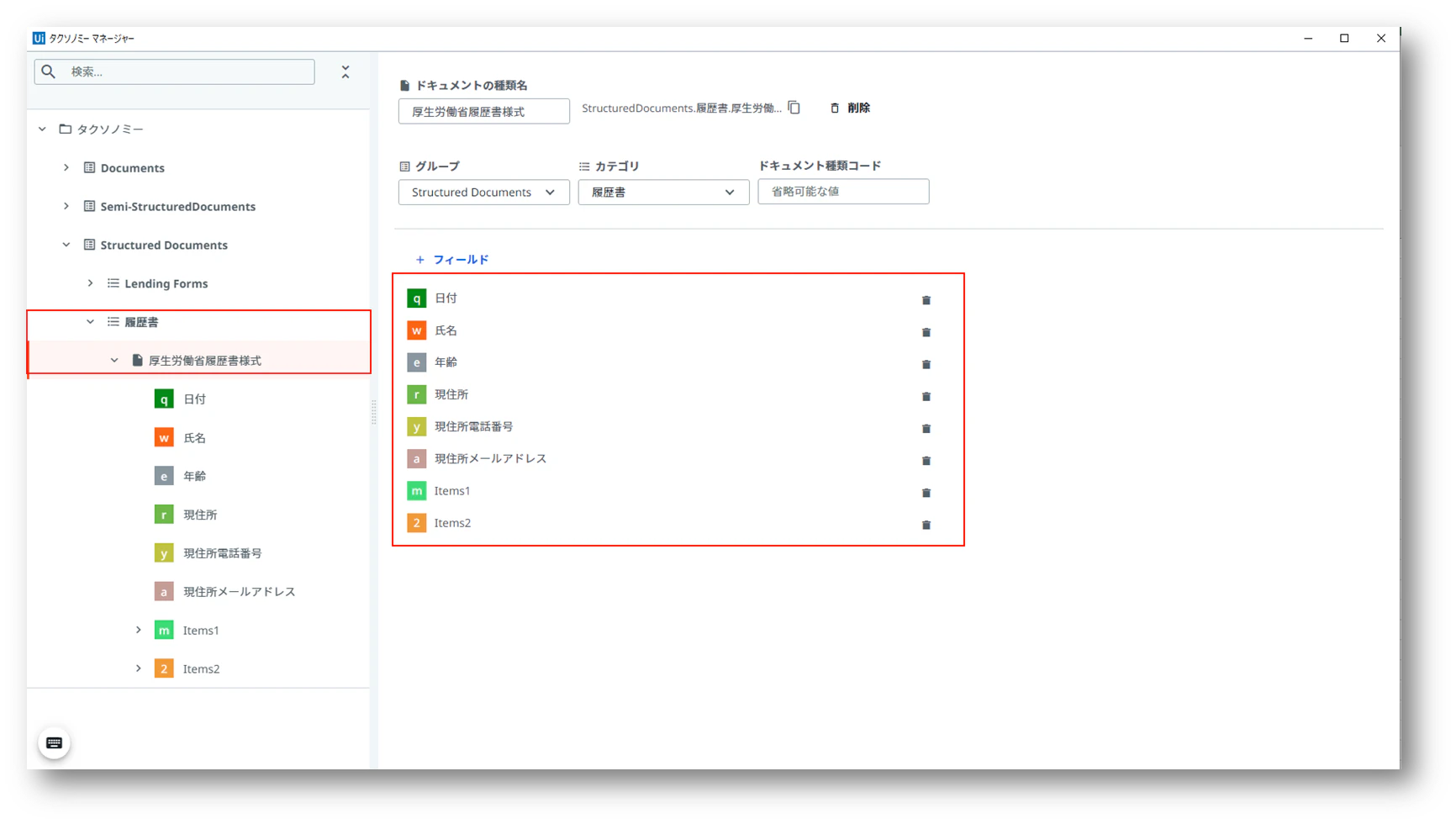
グループ>カテゴリ>ドキュメントの種類の場所
分類されたグループやカテゴリ、ドキュメントの種類によって、何かを処理することも考えられます。そう言ったカスタマイズも考慮し、適切な場所に定義することをお勧めします。
< 各フィールドの詳細 >
読み取りたいフィールドを下記の様に設定します。
| フィールド名 | 種類 | テーブル列フィールド名 | テーブル列種類 |
|---|---|---|---|
| 日付 | Date | ||
| 氏名 | Name | ||
| 年齢 | Text | ||
| 現住所 | Address | ||
| 現住所電話番号 | Text | ||
| 現住所メールアドレス | Text | ||
| Items1 | Table | ||
| 年 | Text | ||
| 月 | Text | ||
| 学歴職歴 | Text | ||
| Items2 | Table | ||
| 年 | Text | ||
| 月 | Text | ||
| 学歴職歴 | Text |
5.3 「30_Classify」(分類)の追加設定
追加する帳票を分類させるために、トレーニングを行います。
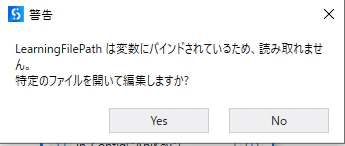
(1)「学習の管理」をクリックします。

ラーニングファイルのパス
「学習の管理」をクリックすると、LearningFilePathは変数にバインドされていると警告メッセージが表示されます。これは、プロパティ値に変数「in_Config("ClassifierLearningFilePath")」が入っているためです。ここでは、Configに設定している値「DocumentProcessing\IntelligentKeywordLearningFile.json」のファイルを直接指定する必要があります。
(2)「トレーニングを開始...」をクリックします。
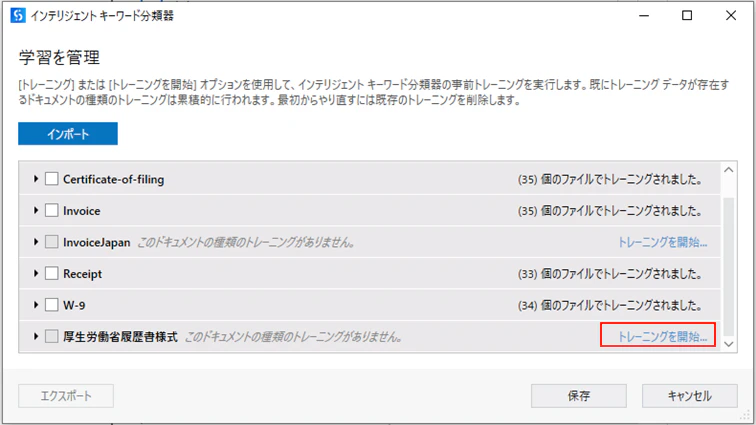
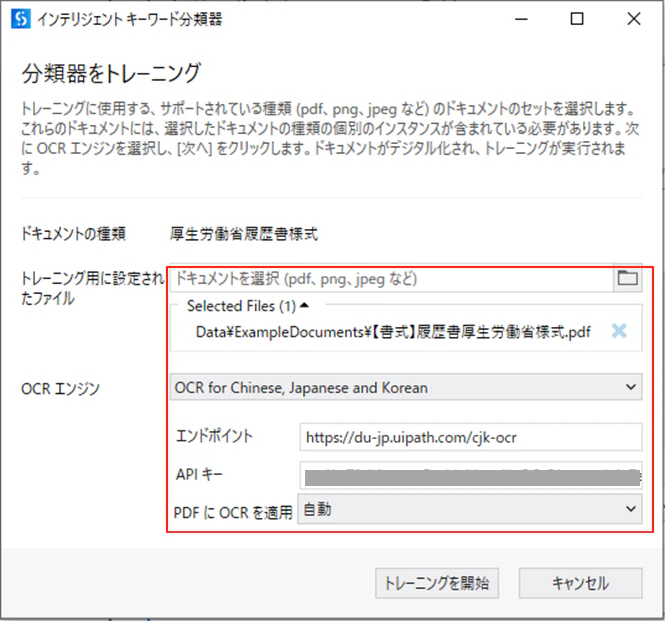
(3)分類器をトレーニングするためのパラメータを設定します。
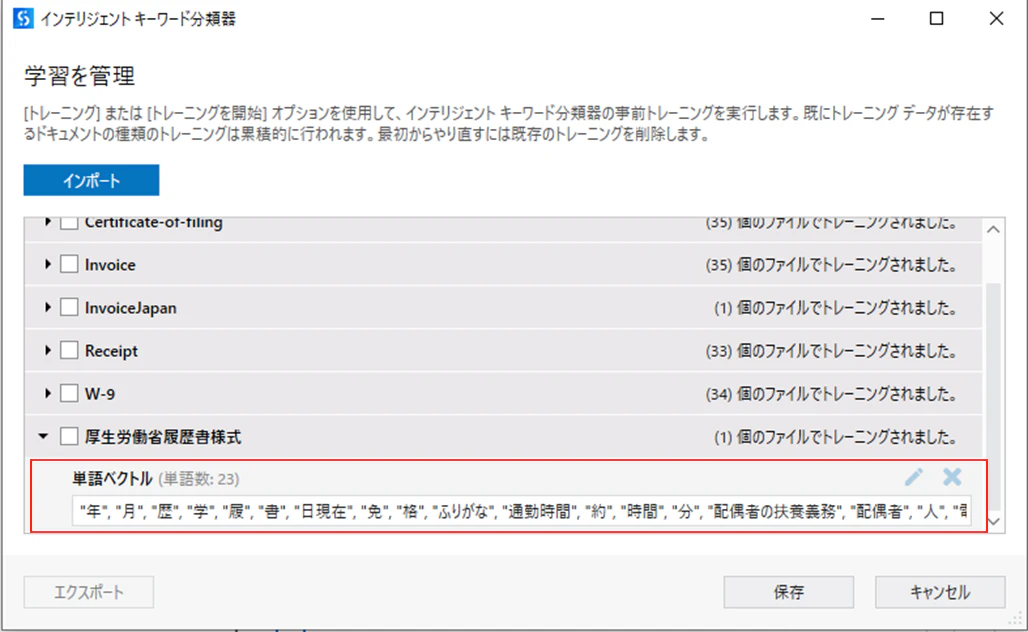
(4)分類のためのキーワード抽出結果は下記の通りです。
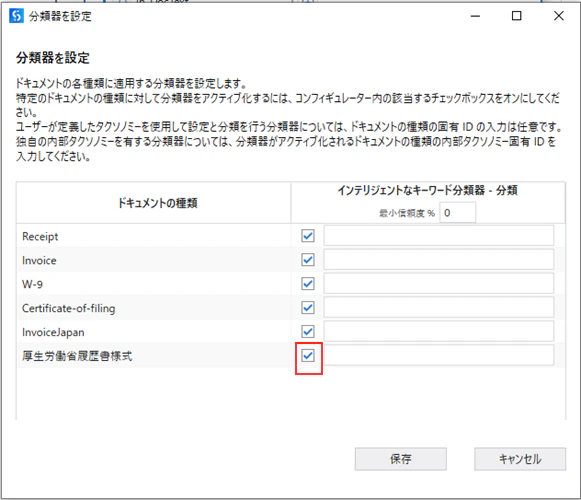
(5)「分類を設定」をクリックします。
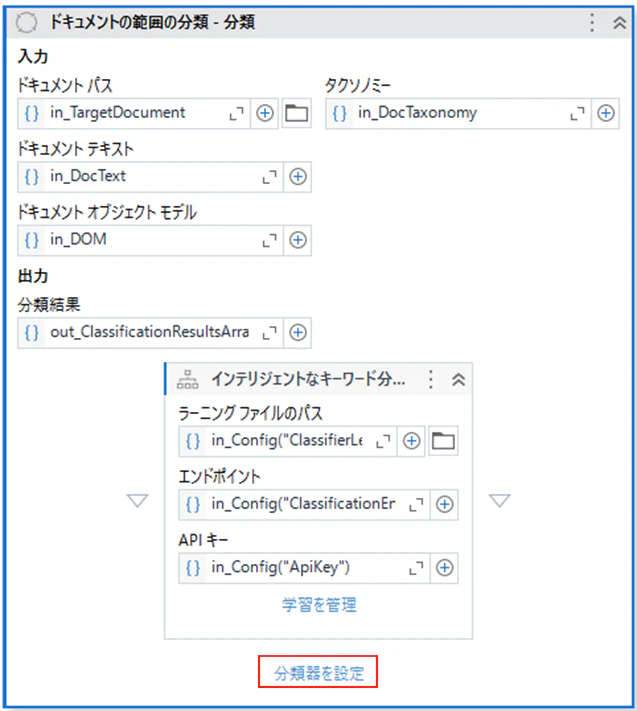
(6)チックボックスをクリックします。
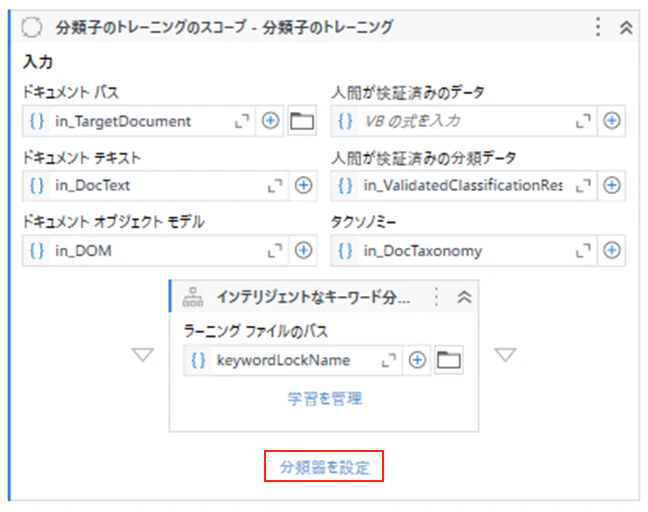
5.4 「40_TrainClassifiers」の設定
追加する帳票の分類を再トレーニングするための設定を行います。必須ではありませんが、既存の英語帳票のサンプルと合わせて設定しています。
(1)「分類器を設定」をクリックします。
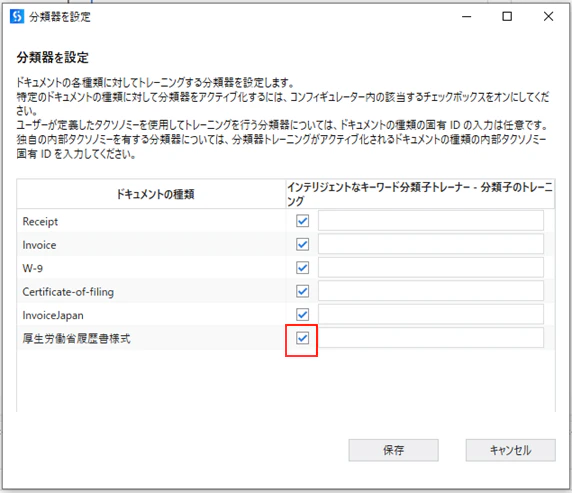
(2)チックボックスをクリックします。
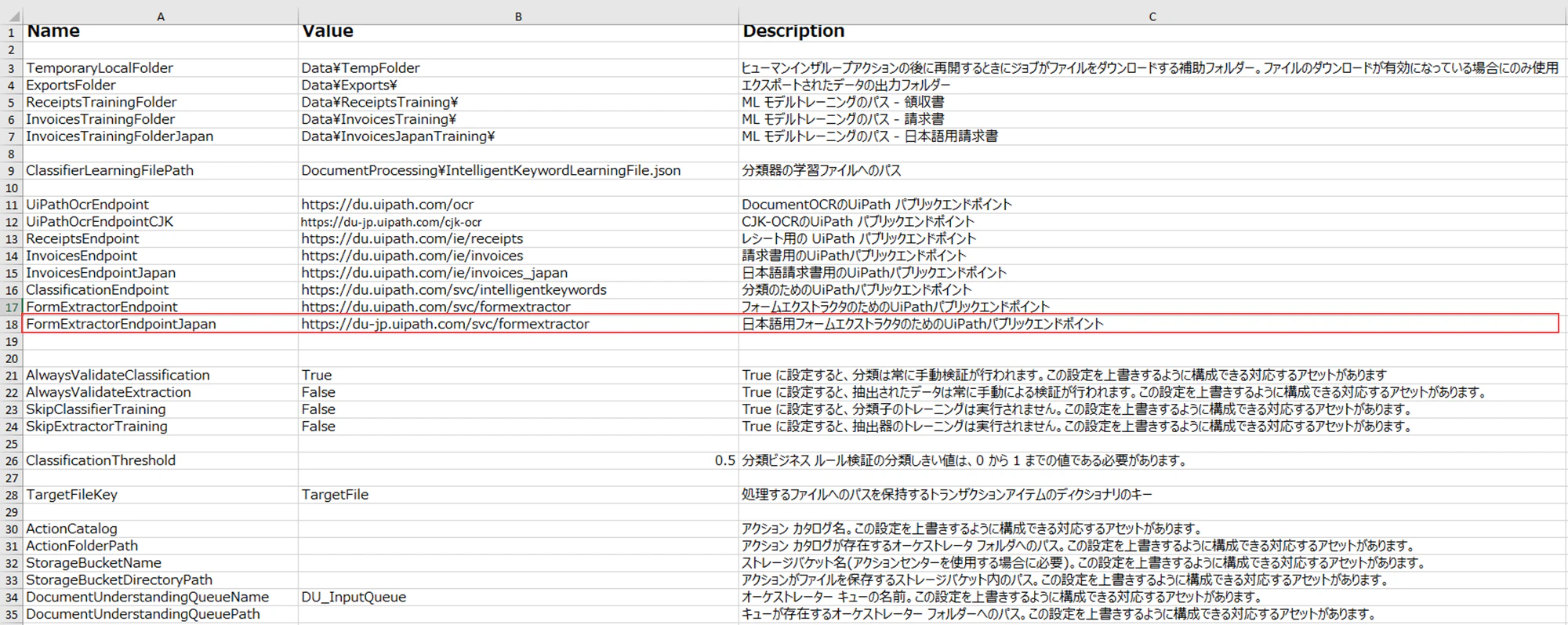
5.5 Configへ日本語用フォーム抽出器のエンドポイント追加
Configの「Settings」シートに日本語用フォーム抽出器のエンドポイントを追加します。
| Name | Value | Description |
|---|---|---|
| FormExtractorEndpointJapan | https://du-jp.uipath.com/svc/formextractor | 日本語用フォーム抽出器のためのUiPathパブリックエンドポイント |
5.6「50_Extract」で履歴書フォーム抽出器を追加
履歴書フォームのデータ抽出を追加します。
(1)「フォーム抽出器」アクティビティを他の抽出器と同様に横並びで追加します。
(2)プロパティを下記の様に設定した後、「テンプレートを管理」をクリックします。
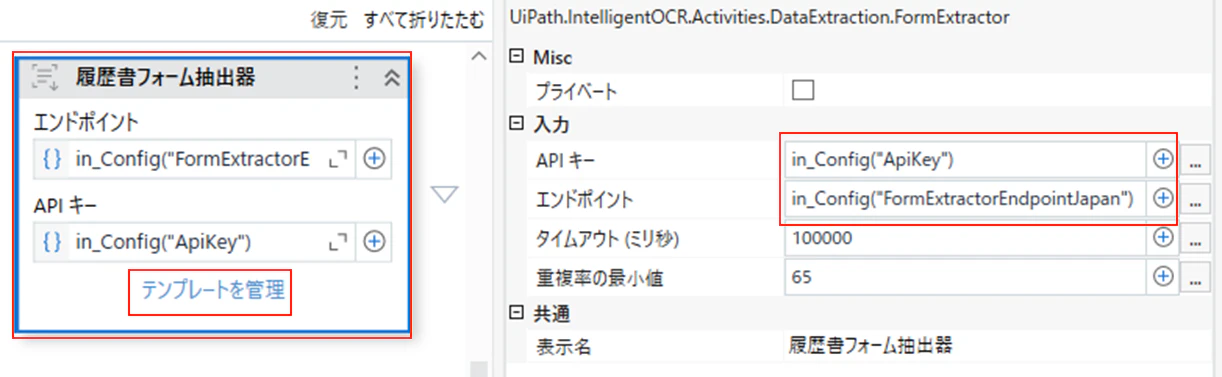
(3)「テンプレートを作成」をクリックします。
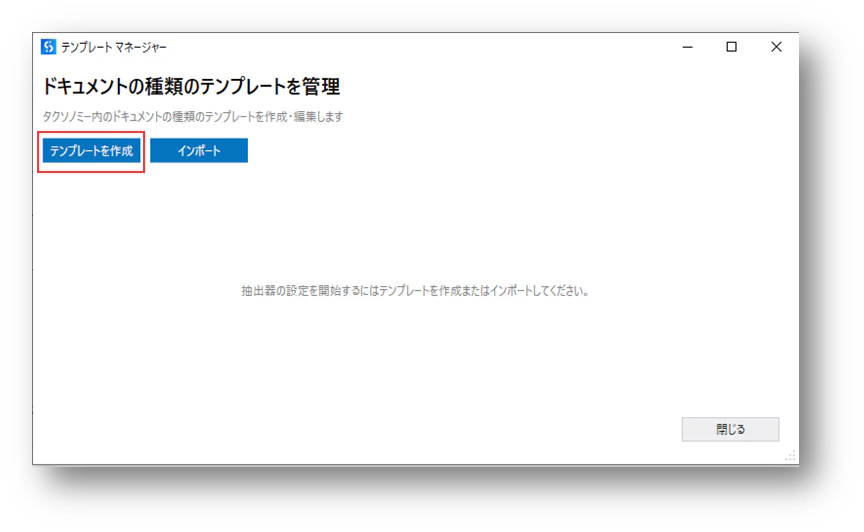
(4)新しいテンプレート作成するためのパラメータを設定します。
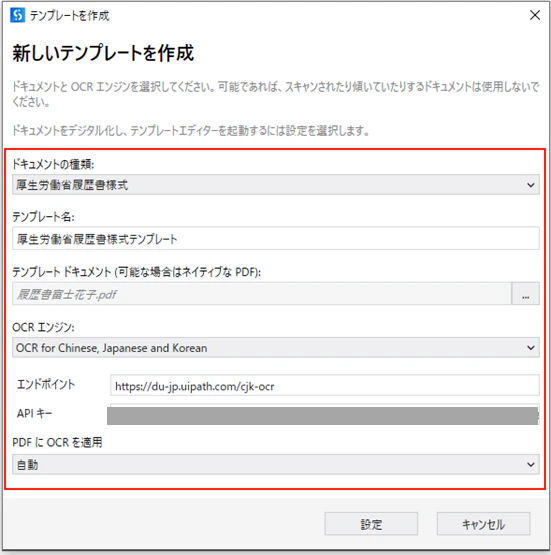
テンプレートドキュメントで選択する帳票
設定項目にある「テンプレートドキュメント」は、画像ファイルではなく、文字取得が可能なPDFファイルを指定することをお勧めします。画像ファイルの履歴書富士太郎.pngを使用すると、正しくデータ抽出されなくなります。
(5)テンプレートマネージャ(テンプレートエディターウィザード)で「ページの一致情報」と抽出する「フィールド」を設定します。
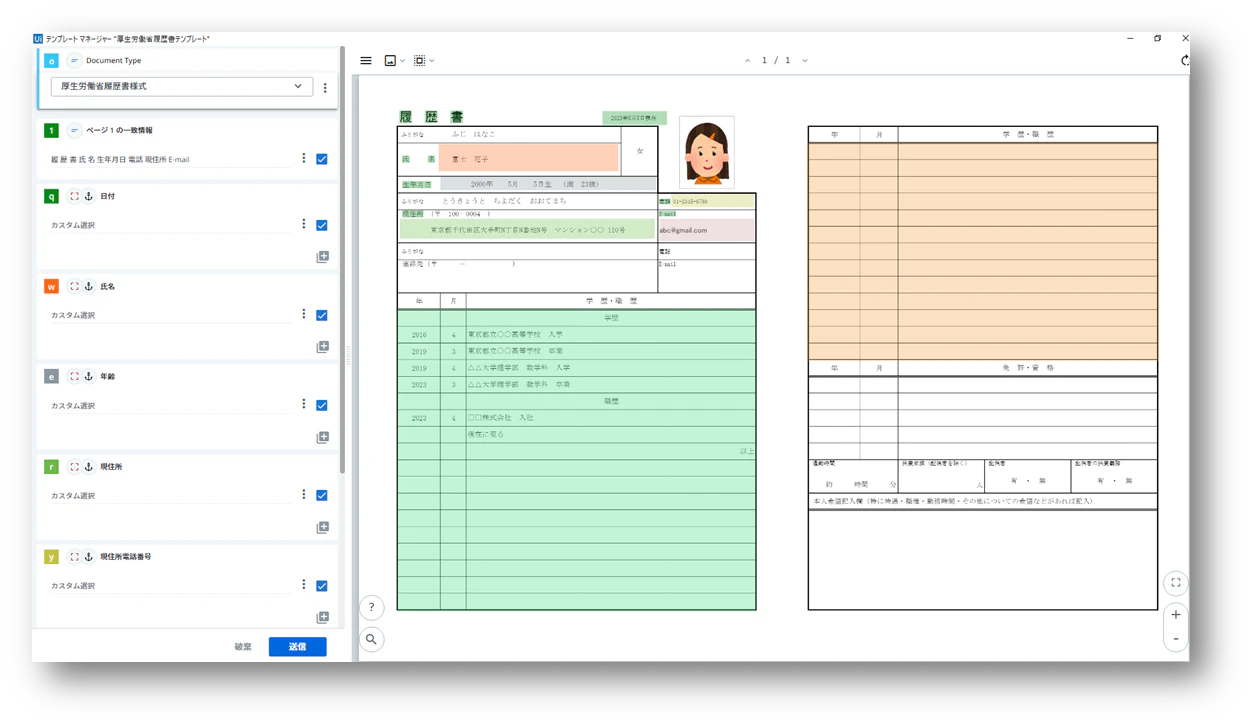
< 操作方法 >
操作方法は、UiPathドキュメントポータル「フォーム抽出器」ページの「テンプレート エディター ウィザード」を参照してください。
(6)「抽出器を設定」をクリックします。
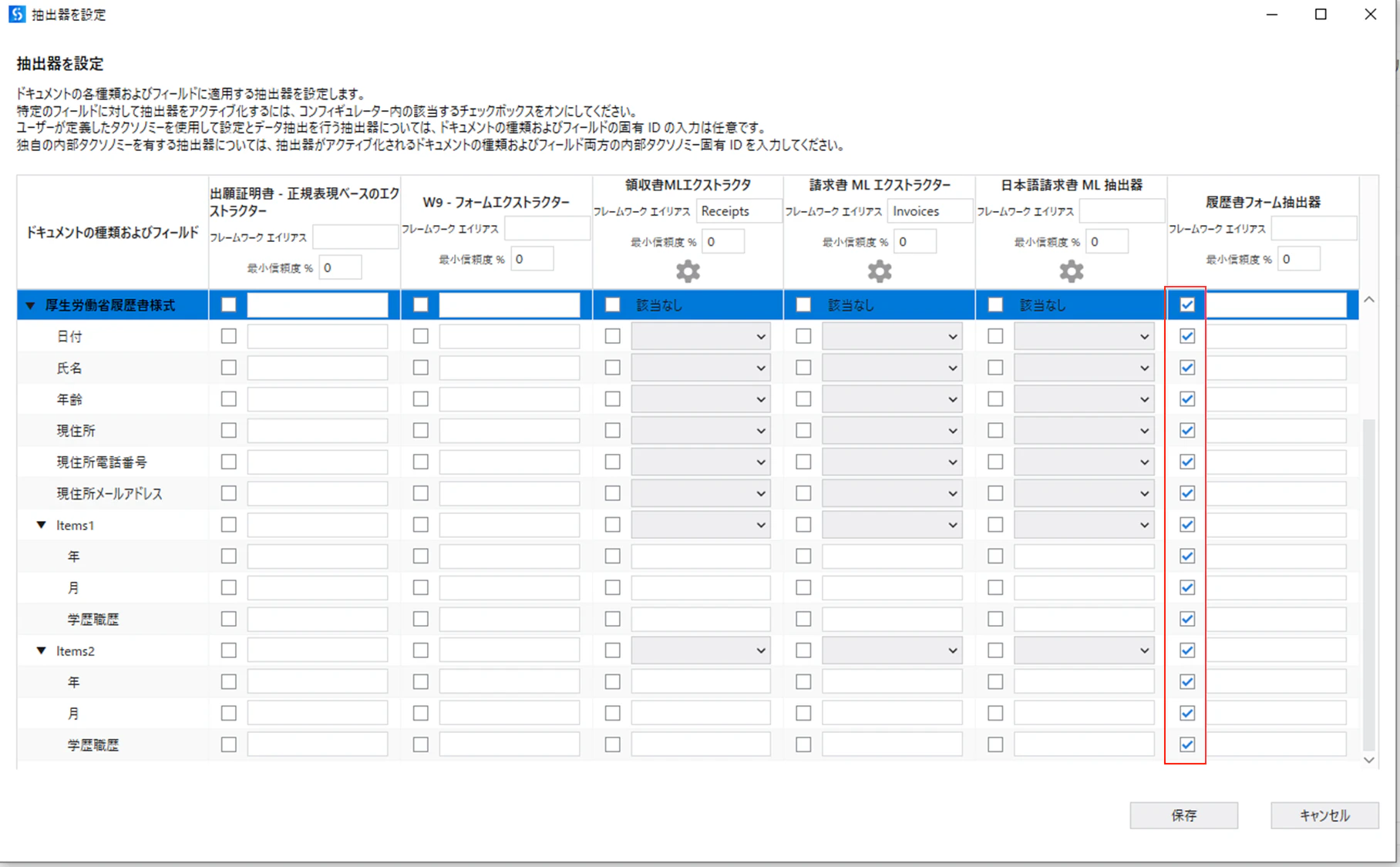
(7)フィールドに対して抽出器をアクティブ化するため、チェックボックスをチェックします。
5.7 フォーム抽出 CJK-OCR対策
ここまでが、「フォーム抽出」のサンプル作成手順です。ただし、日本語帳票が画像であった場合、フォーム抽出では現状、CJK OCRの仕様で、日本語の文字コードの前後に半角スペースが挿入された状態となり、検証時に修正の手間が発生します。この対策については、下記の記事で紹介しています。
6. InvoicesJapan(請求書-日本)-MLパッケージ利用のサンプル
この章では、半構造化(半定型帳票)された帳票の読取りで利用する「ML抽出」のサンプル作成手順を説明します。日本向けに提供されているのは現時点でInvoicesJapan(請求書-日本)-MLパッケージのみですので、これを利用します。英語のサンプル帳票「INVOICE」に相当するものです。
半定型帳票とはレイアウトやデザインは異なるが、同様の情報を含んだドキュメントです。AIが項目を自動抽出します。
6.1 サンプル帳票の準備
サンプル帳票は、何でも良いですが、Document Understanding Processにある英語の請求書サンプルを日本向けに少しアレンジしたものを利用しています。
①【書式】日本語請求書.pdf
分類のトレーニングでは、念のため、内容が記載されていない書式にしています。
文字取得できるPdfファイルです。
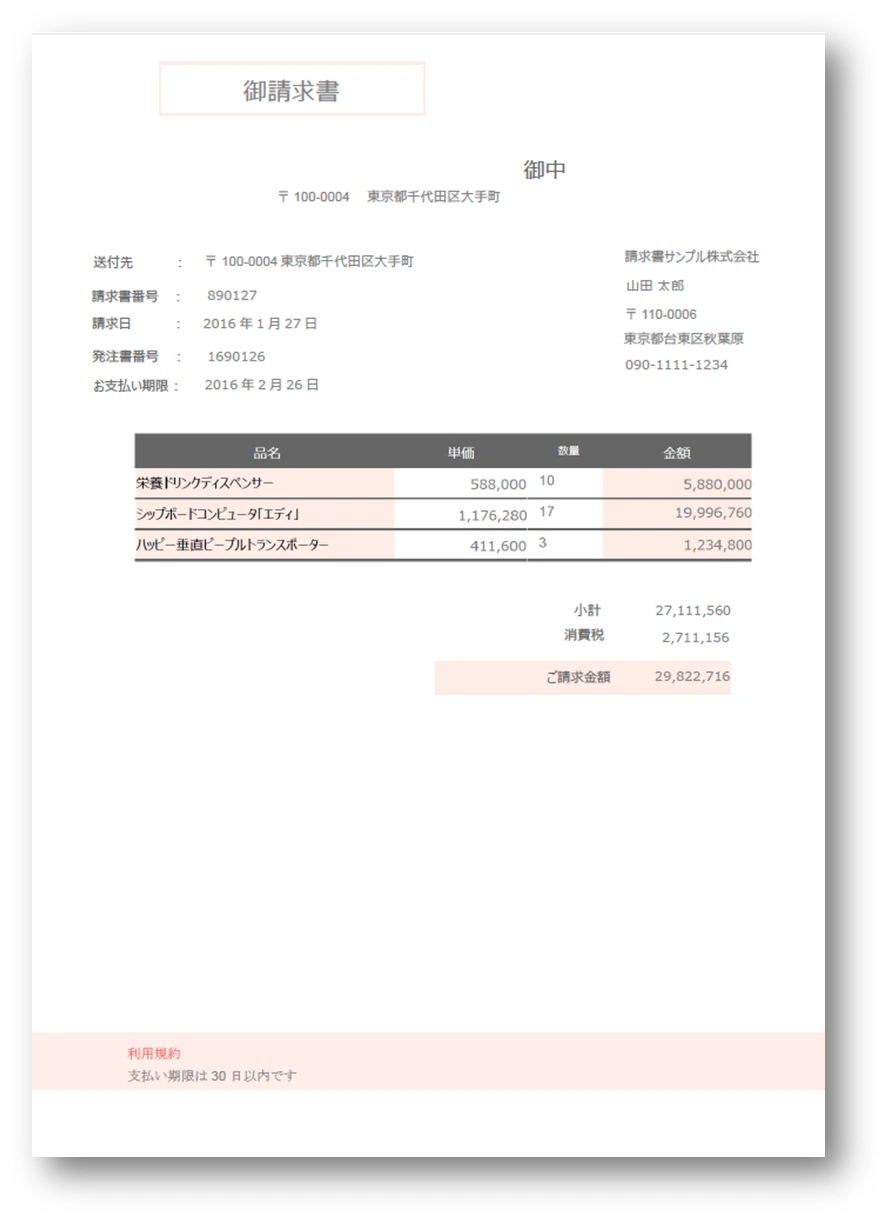
②日本語請求書.pdf
日本語請求書は、明細部分を画像にし、その他は文字取得できるテキストにして見ました。
画像の文字と文字取得できる部分が混在している帳票でも正しく読取りできる様にしたサンプルです。尚、フォーム抽出では帳票が画像であった場合、日本文字の前後に半角スペースが挿入されますが、MLパッケージでは、この現象が発生していないので、これがわかるサンプルも兼ねています。
6.2 タクソノミーマネージャの設定
グループは「Semi-StructuredDocuments」(半構造化されたドキュメント)>カテゴリは「Financial」>ドキュメントの種類は「InvoiceJapan」に定義します。
< 定義する場所 >
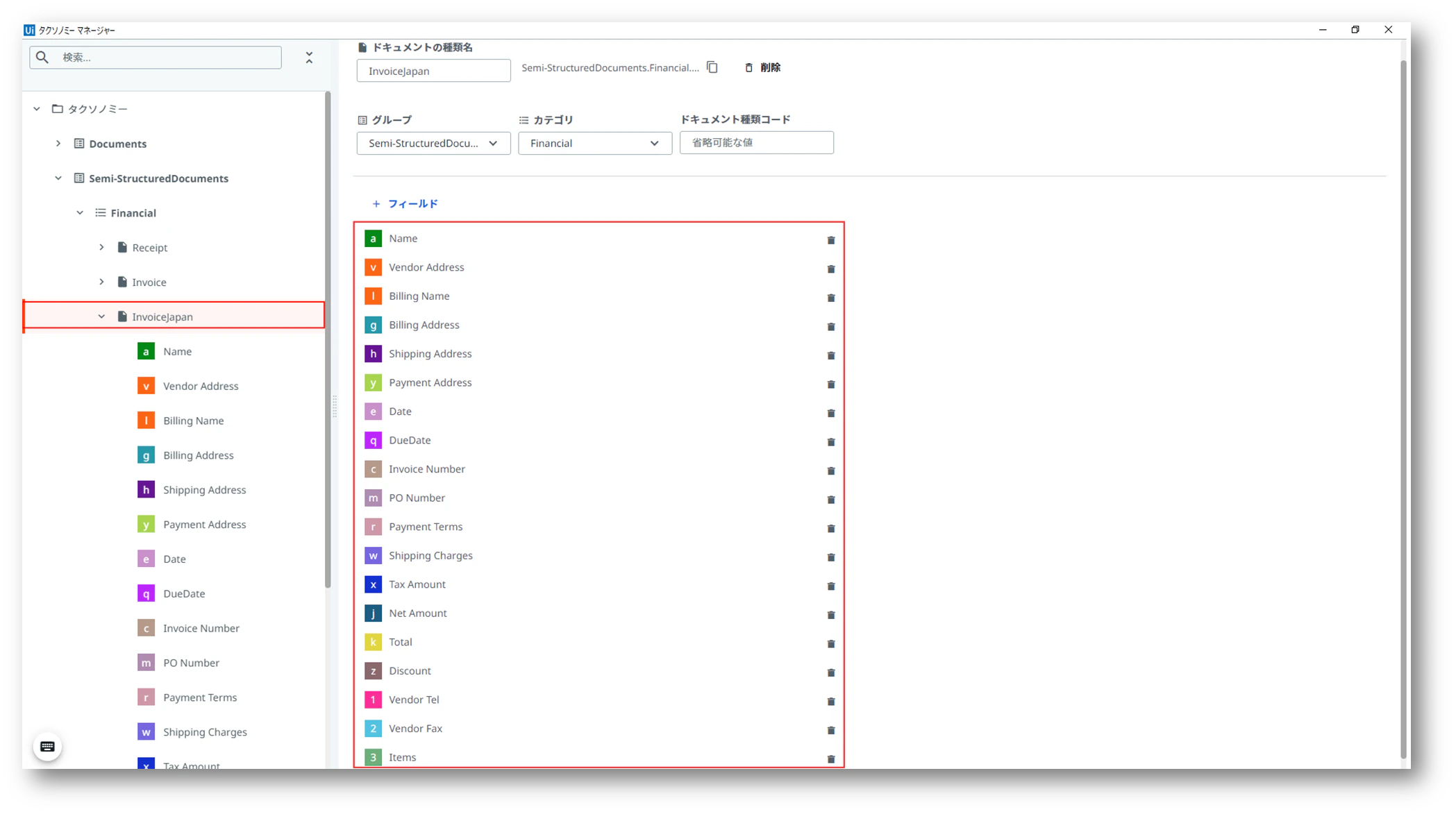
グループ>カテゴリ>ドキュメントの種類
分類されたグループやカテゴリ、ドキュメントの種類によって、何かを処理することも考えられます。そう言ったカスタマイズも考慮し、適切な場所に定義します。
< 各フィールドの詳細 >
読み取りたいフィールドを下記の様に設定します。
ここでは、抽出器を設定する際に指定できるフィールドを全て登録していますのでエクスポートされる際は、抽出されたフィールドには全て値が入ります。請求書によって項目の種類が異なったりするので、抽出できる項目は全て抽出して置こうと考えたためです。尚、英語のInvoices (請求書) - ML パッケージにあるBilling VAT Number、Vendor VAT Number、Currencyが選択できなかったため、それ以外を設定しています。
| フィールド名 | 種類 | テーブル列フィールド名 | テーブル列種類 | 説明 |
|---|---|---|---|---|
| Name | Text | 業者名 | ||
| Vendor Address | Address | 業者住所 | ||
| Billing Name | Text | 請求先宛名 | ||
| Billing Address | Address | 請求先住所 | ||
| Shipping Address | Address | 配送先住所 | ||
| Payment Address | Address | 支払い先住所 | ||
| Date | Date | 日付 | ||
| DueDate | Date | 期限日 | ||
| Invoice Number | Text | 請求書番号 | ||
| PO Number | Text | 発注書番号 | ||
| Payment Terms | Text | 支払条件 | ||
| Shipping Charges | Text | 配送料 | ||
| Tax Amount | Text | 税額 | ||
| Net Amount | Text | 正味金額 | ||
| Total | Text | 合計金額 | ||
| Discount | Text | 割引 | ||
| Vendor Tel | Text | 業者電話番号 | ||
| Vendor Fax | Text | 業者FAX番号 | ||
| Items | Table | |||
| Line Number | Text | 明細-番号 | ||
| Description | Text | 品名 | ||
| Item PO Number | Text | アイテム発注番号 | ||
| Quantity | Number | 数量 | ||
| Unit Price | Text | 単価 | ||
| Line Amount | Text | 明細-金額 | ||
| Part Number | Text | 部品番号 | ||
| Line Discount | Text | 明細-割引 | ||
| Line Tax Amount | Text | 明細-税額 | ||
| Line Net Amount | Text | 明細-正味金額 |
6.3 「30_Classify」(分類)の追加設定
追加する帳票を分類させるために、トレーニングを行います。
(1)「学習の管理」をクリックします。
ラーニングファイルのパス
「学習の管理」をクリックすると、LearningFilePathは変数にバインドされていると警告メッセージが表示されます。これは、プロパティ値に変数「in_Config("ClassifierLearningFilePath")」が入っているためです。ここでは、Configに設定している値「DocumentProcessing\IntelligentKeywordLearningFile.json」のファイルを直接指定する必要があります。
(2)「トレーニングを開始...」をクリックします。
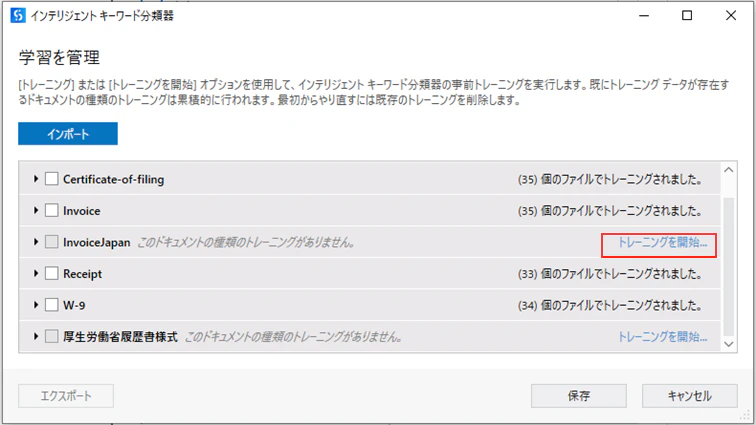
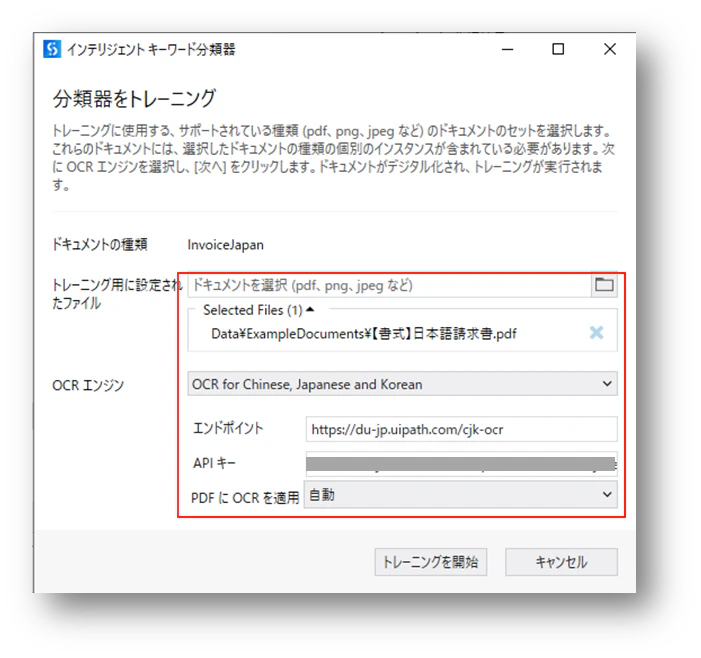
(3)分類器をトレーニングするためのパラメータを設定します。
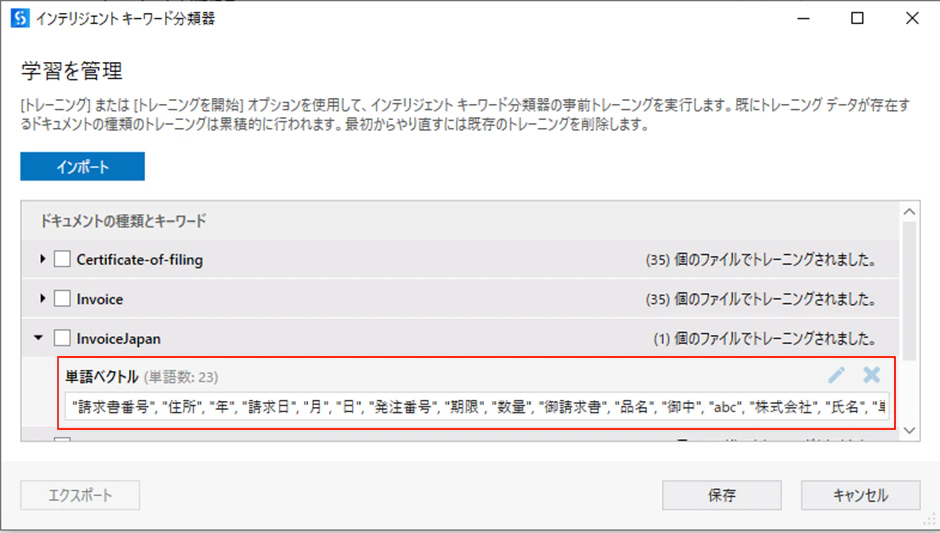
(4)分類のためのキーワード抽出結果は下記の通りです。
(5)「分類を設定」をクリックします。
(6)チックボックスをクリックします。
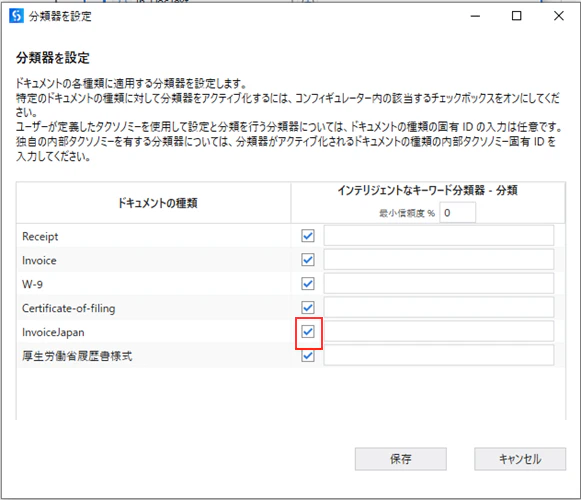
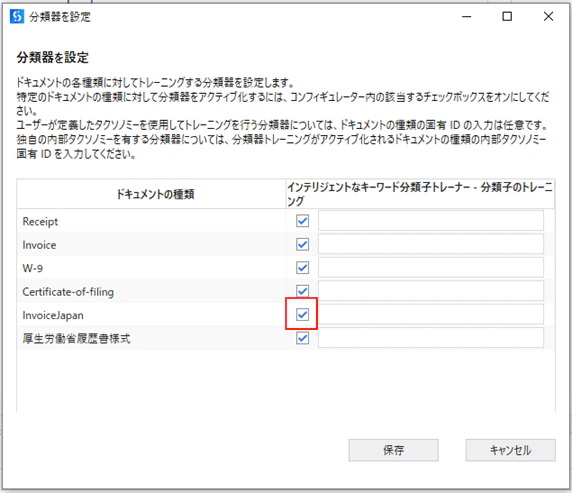
6.4 「40_TrainClassifiers」の設定
追加する帳票の分類を再トレーニングするための設定を行います。必須ではありませんが、既存の英語帳票のサンプルと合わせて設定しています。
(1)「分類器を設定」をクリックします。
(2)チックボックスをクリックします。
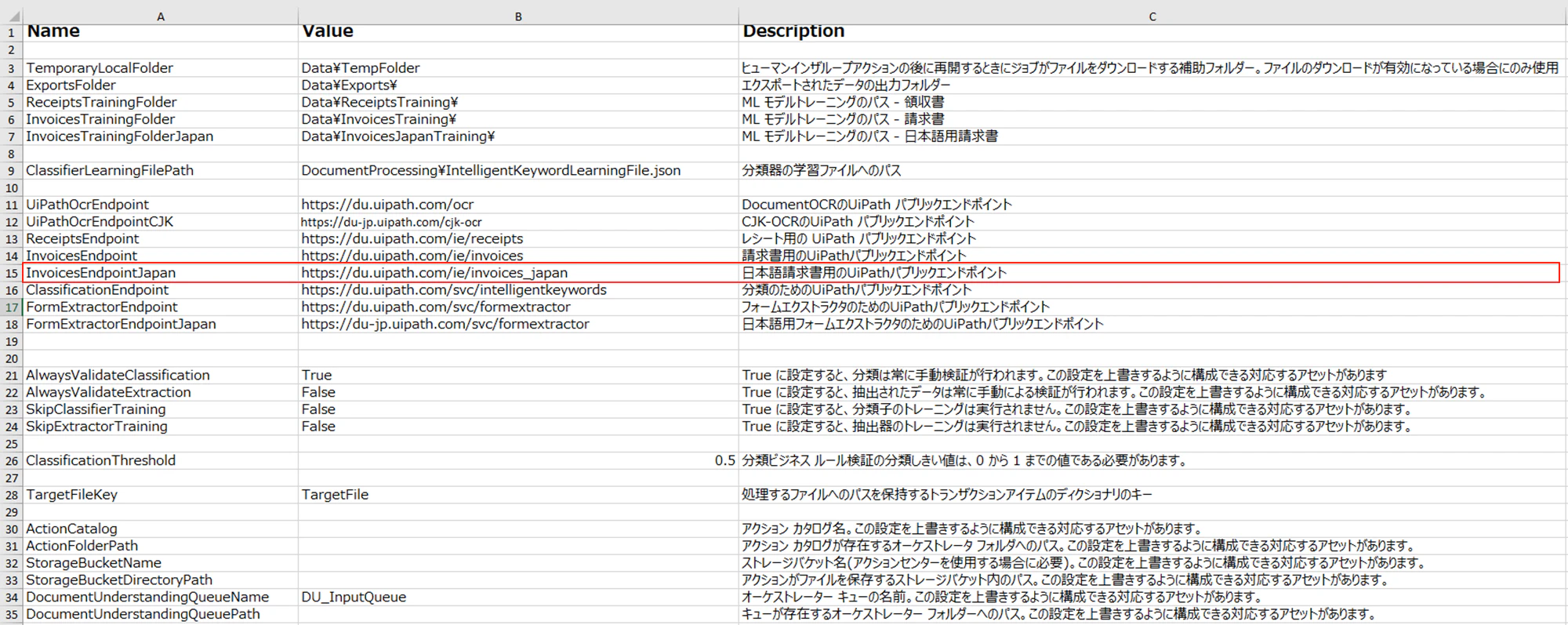
6.5 ConfigへInvoicesJapan (請求書 - 日本) - ML パッケージのエンドポイント追加
Configの「Settings」シートにInvoicesJapan (請求書 - 日本) - ML パッケージのエンドポイントを追加します。
| Name | Value | Description |
|---|---|---|
| InvoicesEndpointJapan | https://du.uipath.com/ie/invoices_japan | 日本語請求書用のUiPathパブリックエンドポイント |
6.6「50_Extract」で日本語請求書 ML 抽出器を追加
履歴書フォームのデータ抽出を追加します。
(1)「マシンラーニング抽出器」アクティビティを他の抽出器と同様に横並びで追加し、マシンラーニング抽出器を設定します。
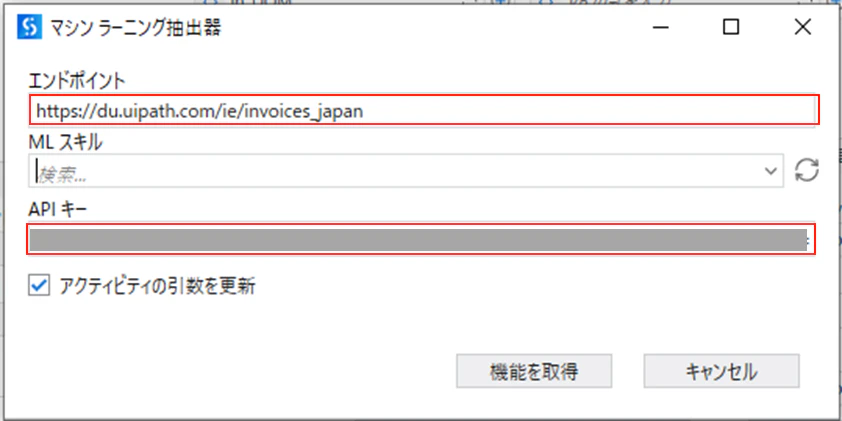
(2)プロパティを下記の様に設定します。
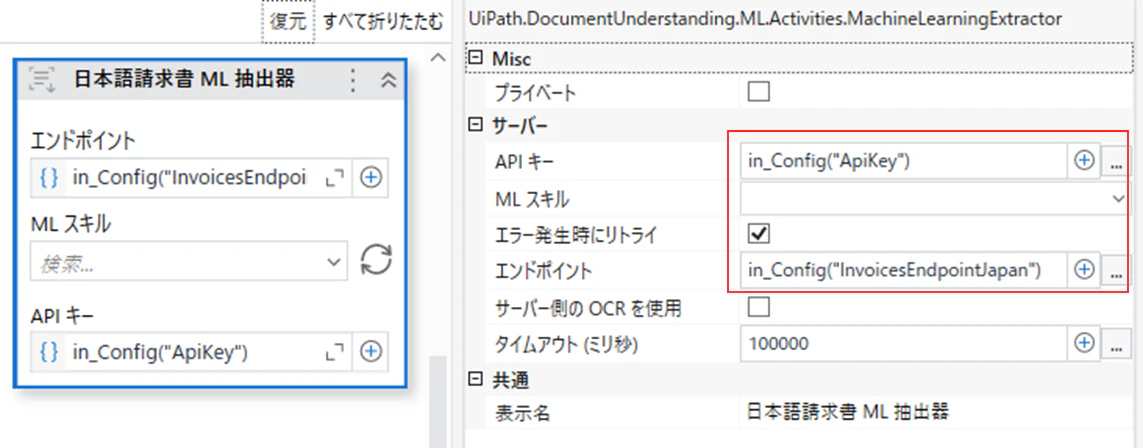
(3)「抽出器を設定」をクリックします。
(4)フィールドに対して抽出器をアクティブ化するため、チェックボックスをチェック及びフィールドを割り当てます。ここのフィールド割り当てがし易い様にタクソノミーマネージャで設定したフィールド名は日本語ではなく、英語サンプルと同様に英語表記にしておきました。後述するビジネスルールの作成の際も、元の英語サンプルを流用するので、フィールド名は英語サンプルと同様に英語表記のままをお勧めします。
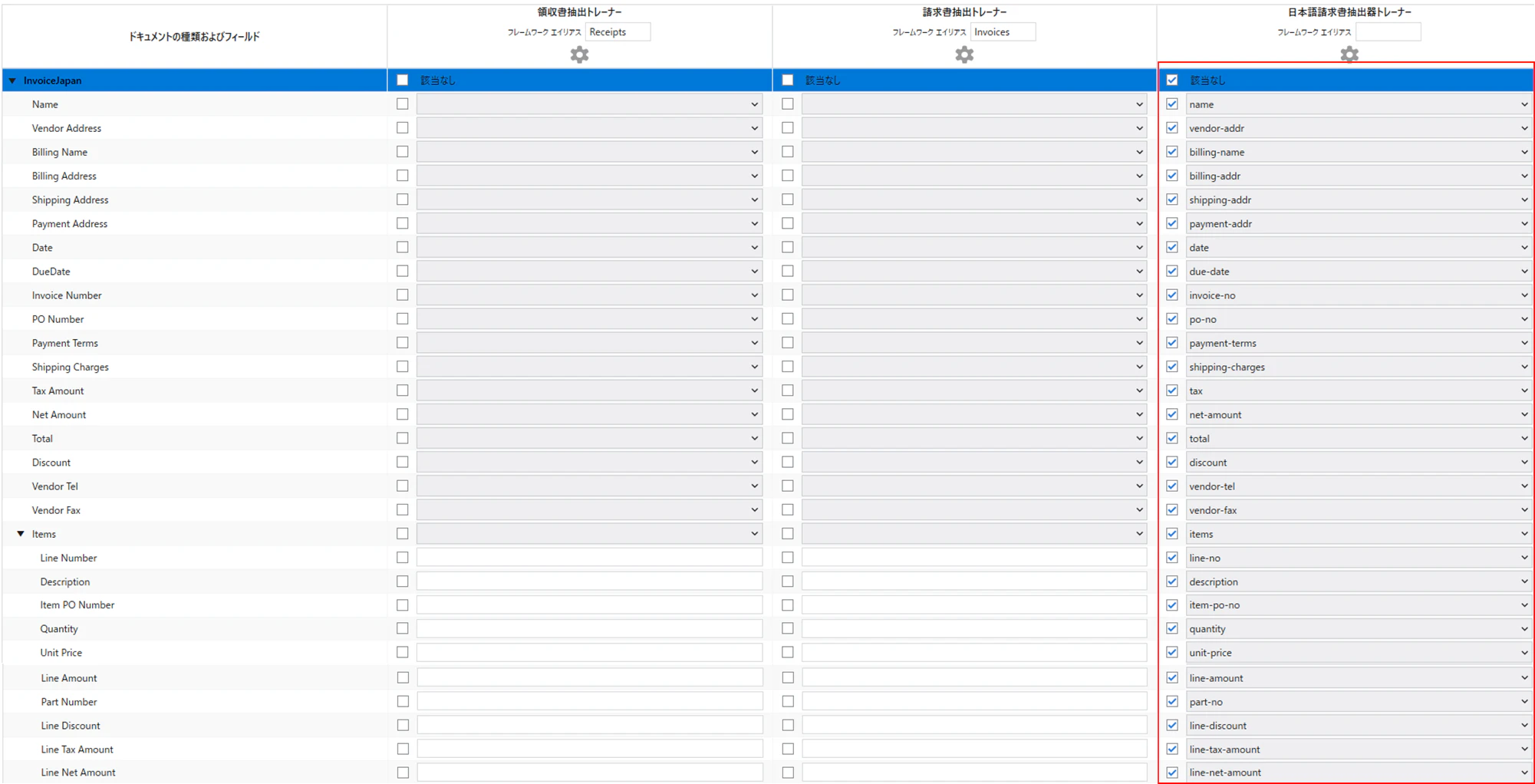
6.7 InvoicesJapan対応ビジネスルール
ここまでが「InvoicesJapan (請求書 - 日本) - ML パッケージ」を利用したサンプル作成手順です。Document Understanding Processでは「Invoices (請求書) - ML パッケージ」利用時のビジネスルールを策定することにより、手動による検証をスキップできるテンプレートが用意されています。同様に「InvoicesJapan (請求書 - 日本) - ML パッケージ」利用時の場合のために用意します。この対応については、下記の記事で紹介しています。
終わりに
ここまで、元の英語のテンプレートを日本向けに変更することにフォーカスして解説させて頂きました。ただ、テンプレート内のあらゆる箇所で、どのようなカスタマイズを推奨するか解説されているコメントが多数あり、本記事では、そのカスタマイズまで踏み込んだ解説は割愛しています。実稼働するために、環境、利用帳票、自動判定のビジネスルールなど、更にカスタマイズが必要な場合があります。あくまでもテンプレートなので、カスタマイズするにはDocument Understanding Processの処理内容と、クラス(アクティビティで入出力されるデータ構造)を理解しておくことをお勧めします。