この記事はUiPathブログ発信チャレンジ2024サマーの7日目の記事です。
はじめに
UiPath 拡張言語 OCR(UiPath Extended Languages OCR)がプレビューリリースされ、日本語の手書きにも対応されていると言うことで軽く試して見ました。尚、UiPath 拡張言語 OCRの利用メリットは、手書きサポートだけでなく、様々な言語(簡体字中国語、フランス語、ドイツ語、イタリア語、韓国語・・・など)に対応。つまり、色んな言語の帳票を扱う場合でも、気にすることなく、この1つのOCRだけ使えば良いと言うことです。サポートされている言語については、下記の公式ドキュメントをご覧ください!
手書きの帳票をUiPath Document Understandingで試した結果
手書き対応されていない従来の「OCR-日本語、中国語、韓国語」アクティビティ(CJK OCR)との比較で検証してみました。当然ながら帳票は画像に変換したものです。
1.手書き風に活字を変更して試す
画像_職務経歴書山田太郎.png
まずは、行書体で、文字のサイズを疎らに変更しながら手書き風にした活字の画像で比較しました。

「OCR-日本語、中国語、韓国語」アクティビティを利用
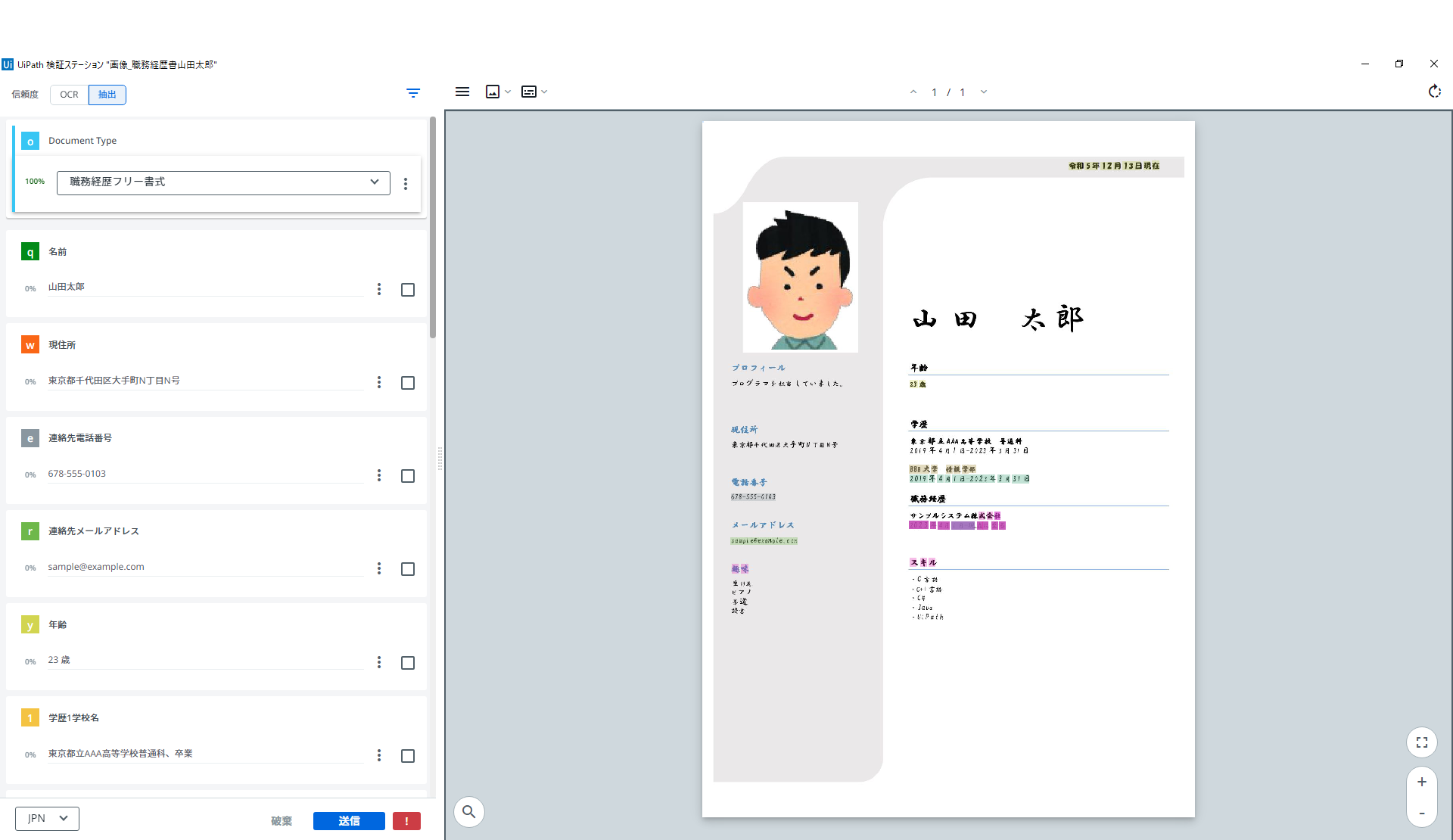
「UiPath 拡張言語 OCR」アクティビティを利用
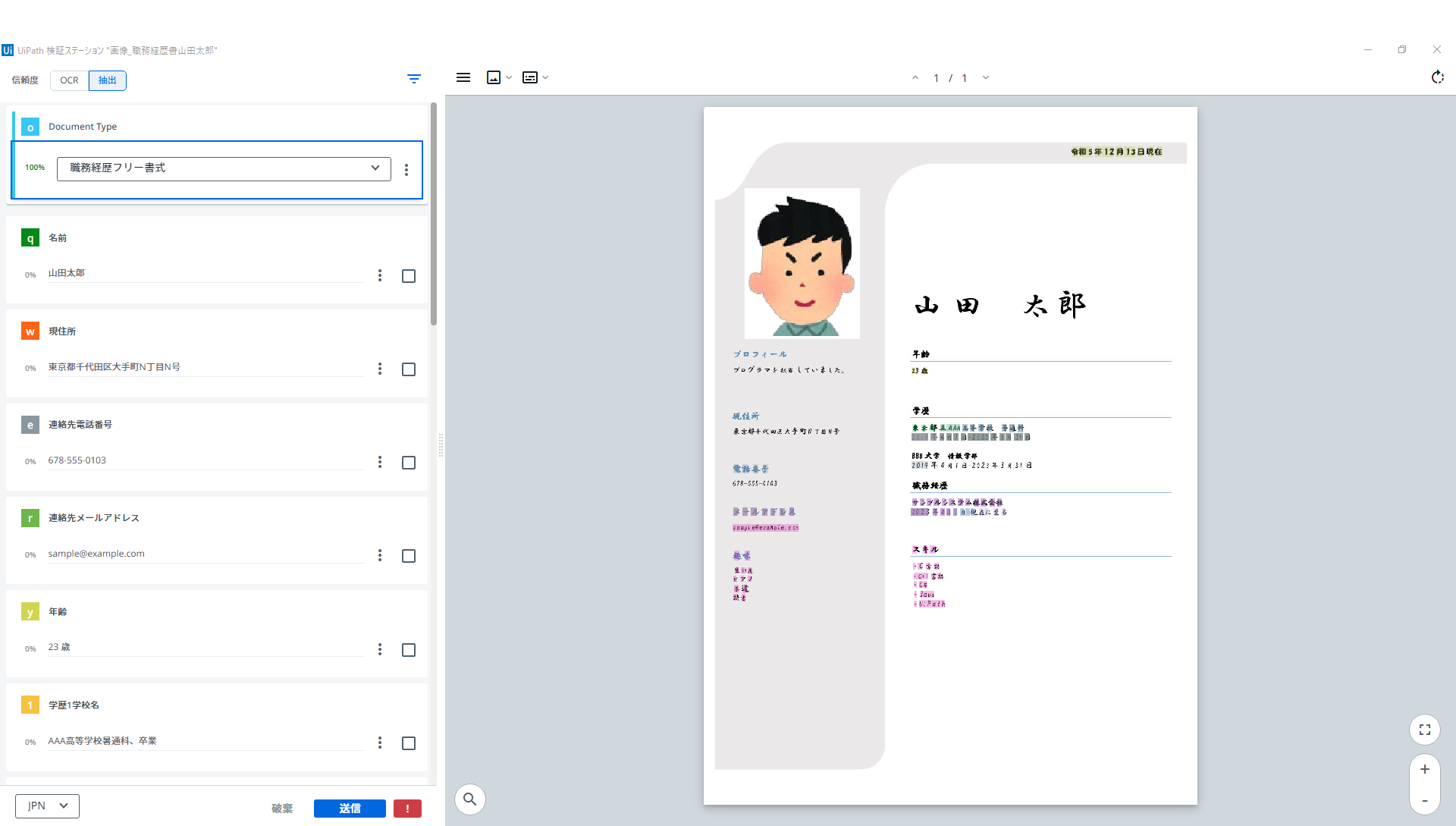
両方とも、正しく読み取れています(笑)
さすがに標準的なフォントをベースに大きさを疎らに変えて手書き風にみせたとろろで、差はでない・・・活字に関しては、「OCR-日本語、中国語、韓国語」でも、そこそこ優秀です(笑)
2.氏名を手書にして試すw
画像_職務経歴書山田太郎手書き.png
ペイントブラシで氏名だけでも実際の手書にして試して見ました。

「OCR-日本語、中国語、韓国語」アクティビティを利用
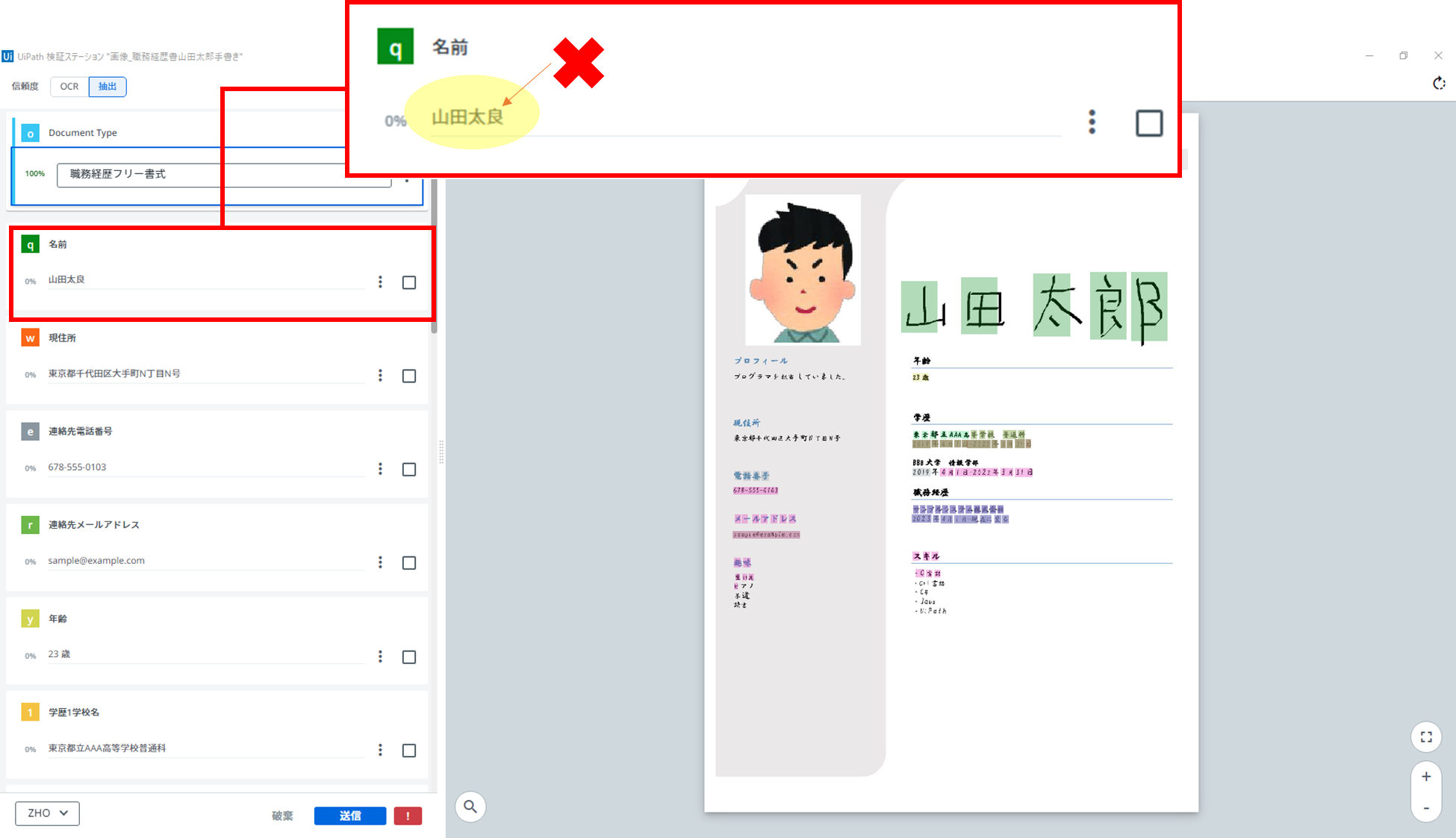
「UiPath 拡張言語 OCR」アクティビティを利用
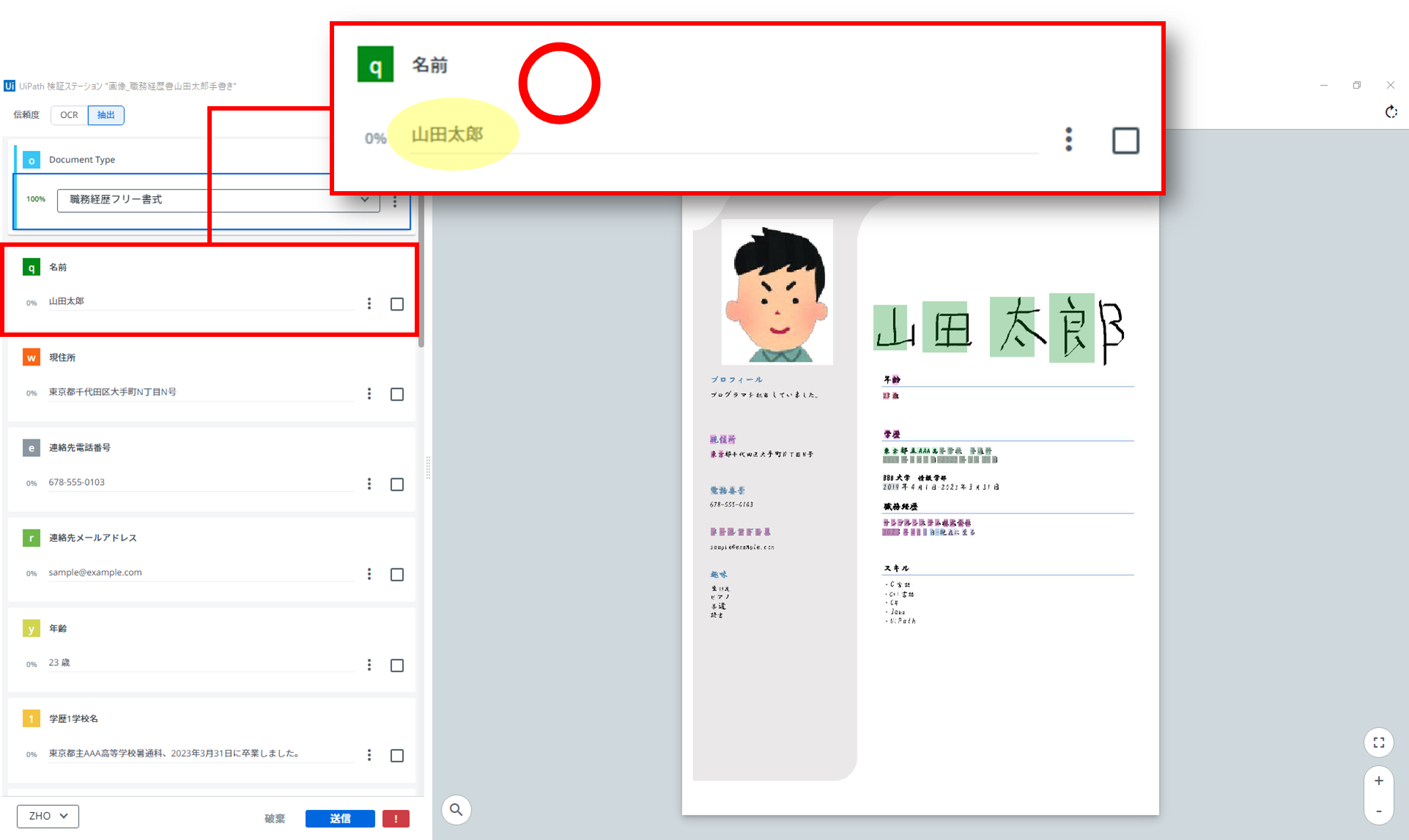
氏名だけの変更でしたが、もうこれだけでも、その差は明らかです!
さすが、手書き対応と言うだけのことはありそうですね。
UiPath Document Understanding ProcessにUiPath 拡張言語 OCR適用の仕方
下記のブログをベースに変更箇所を説明します。変更箇所は、「4. 日本語OCR対応」の部分のみです。
1.ConfigにUiPath 拡張言語 OCRのエンドポイントを設定
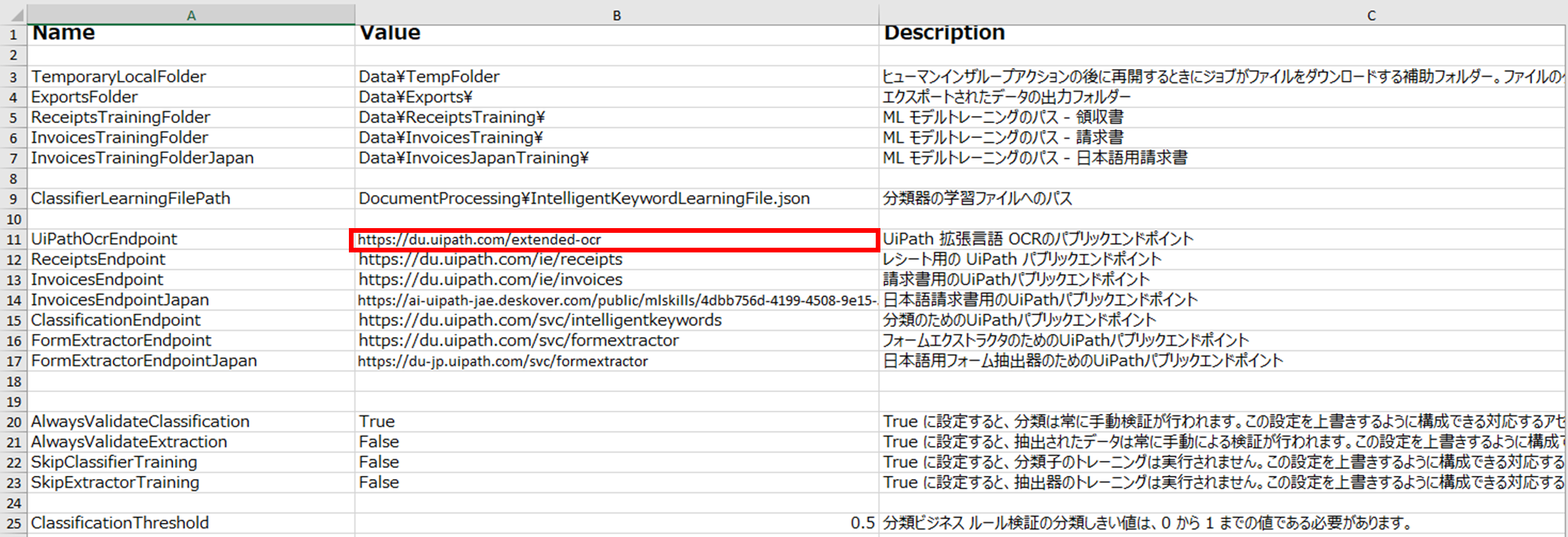
「UiPath 拡張言語 OCR」は複数の言語がサポートされているので、エンドポイントを英語と日本語に分ける必要がないので、「OCR-日本語、中国語、韓国語」(CJK-OCR)で追加した「UiPathOcrEndpointCJK」は、もう不要です。「UiPathOcrEndpoint」に「UiPath 拡張言語 OCR」のエンドポイントを設定し、これだけを使うことにします。
| Name | Value | Description |
|---|---|---|
| UiPathOcrEndpoint | https://du.uipath.com/extended-ocr | UiPath 拡張言語 OCRのパブリックエンドポイント |
「Settings」シート
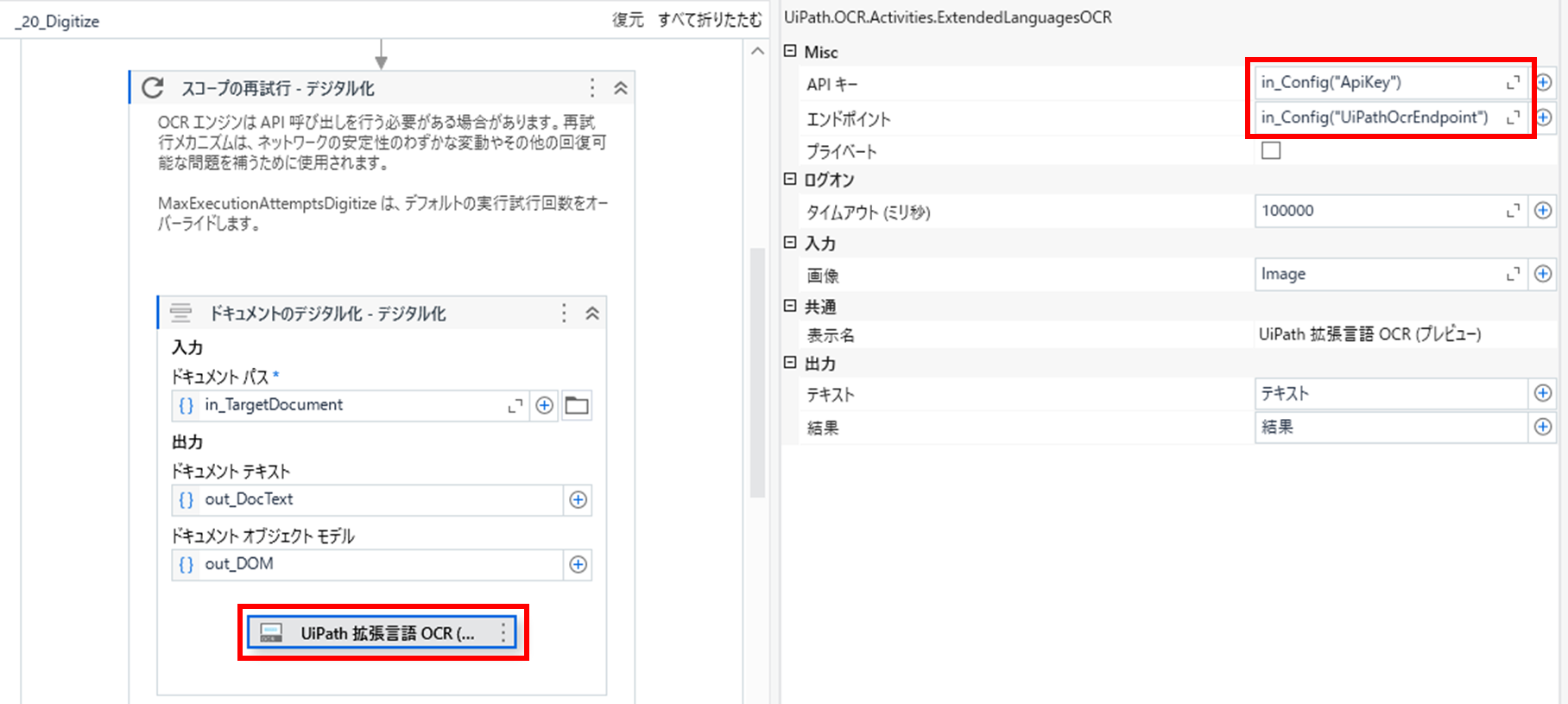
2.「20_Digitize」(デジタル化)の変更
「ドキュメントのデジタル化」アクティビティのOCRを「UiPath 拡張言語 OCR」アクティビティに入れ替えて、各プロパティを下記の様に設定します。
以上です!簡単ですねw
おわりに
本検証では、下記ブログの「生成AIによる分類と抽出をサポート」のテンプレートを用いて試しました。
識字率の善し悪しは、生成AIがデータ抽出の際、ある程度影響を受けると考えてます。例えば、フォーム抽出の場合は、読取りエリアを定義しておけば、書いている内容関係なく抽出されますが、生成AIは、書いている内容を理解した上で、抽出してくるので識字率の悪く書いている内容が意味不明だと、おそらくデータ抽出に少なからず影響するのでは?と推測してます。
そう言う意味でも生成AIによる分類と抽出を使う場合は、識字率の高まった「UiPath 拡張言語 OCR」との組合せは、現時点のベストプラクティスと言えそうです。