はじめに
UiPath Document Understandingは、半定型帳票(*)の読取り精度が出なければ、再トレーニングで精度向上していくことができます。読み取れないフィールドも追加して、再トレーニングすれば読取りが可能になったりします。ユーザーがAIを構築できるAI Centerを持っているUiPathならではの本格的なドキュメントソリューションと言えるでしょう。
*ここで言う半定型は準定型と言う場合もあります。レイアウトやデザインは異なるが、同様の情報を含んだドキュメントのことです。一部のOCRベンダーでは、これを非定型と呼んだりしている場合もあります。
本記事の目的
本記事では、すぐに使える事前トレーニング済みのパッケージで提供されている「InvoicesJapan (請求書 - 日本) - ML パッケージ」をAI Centerを利用して再トレーニングすることにより、デフォルトでは読み取れないフィールドを追加する、合わせて利用する帳票の読み取り精度を向上する方法を解説します。
<本記事で追加している読取りフィールド(振込先)>
前提
- 2023年8月時点のAutomation Cloudの内容で記載しています。クラウドサービスなので、今後、操作や機能が変わる可能性があります。
- 本記事で利用するワークフローはUiPath Document Understanding Process日本向けテンプレート利用しています。テンプレートの作り方は、下記の記事をご覧ください。
1.MLモデルのトレーニング
MLモデルのトレーニングは、AI Centerで操作して実施することが一般的ですが、Document Understandingは、Automation Cloudの「Document Understanding」でMLモデルに関わる全ての工程の実施と一元管理ができる様になっています。管理も操作もシンプルになったので、本記事では、これを利用します。
1.1 帳票を取り込んでラベリングする
(1)Automation Cloudで「Document Understanding」に遷移します。
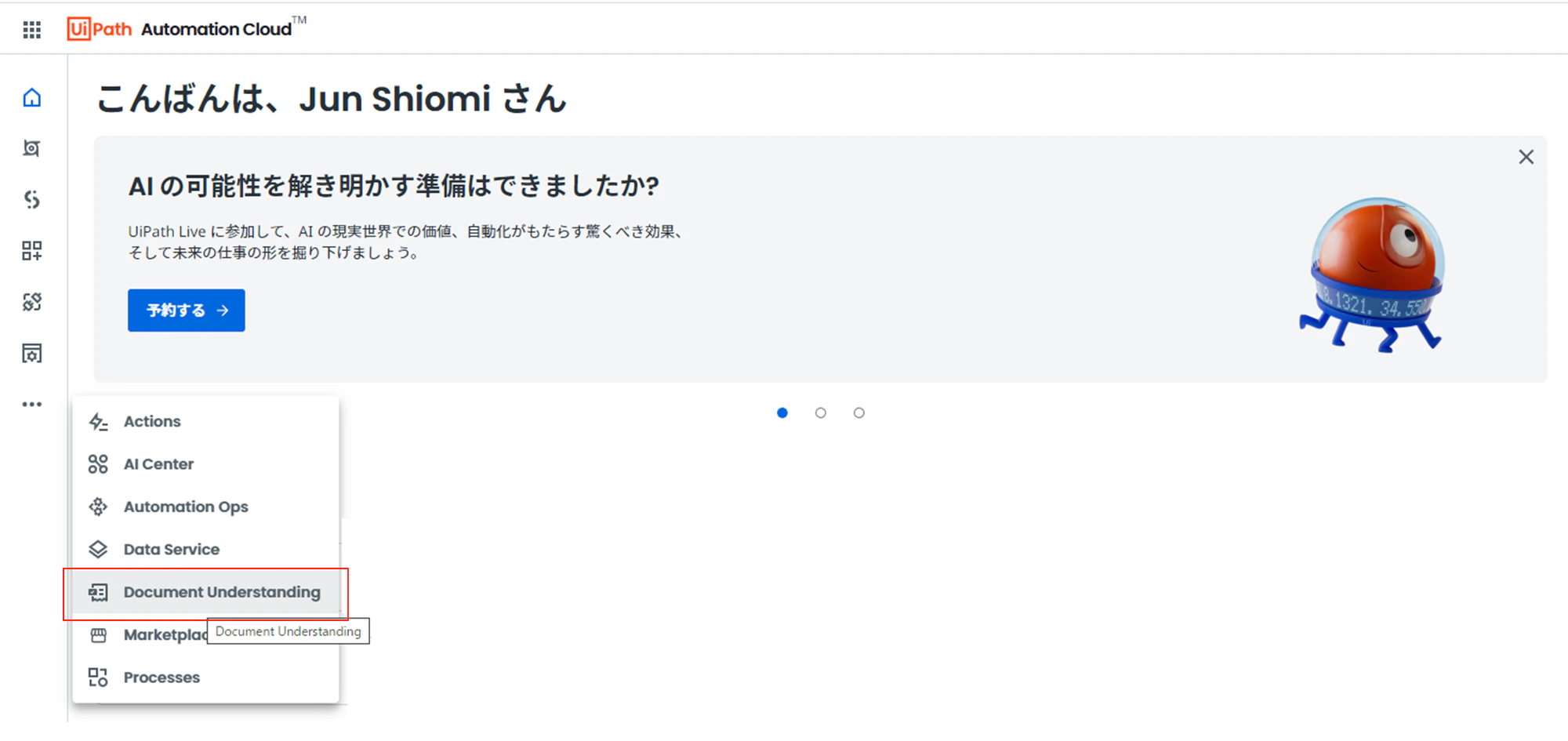
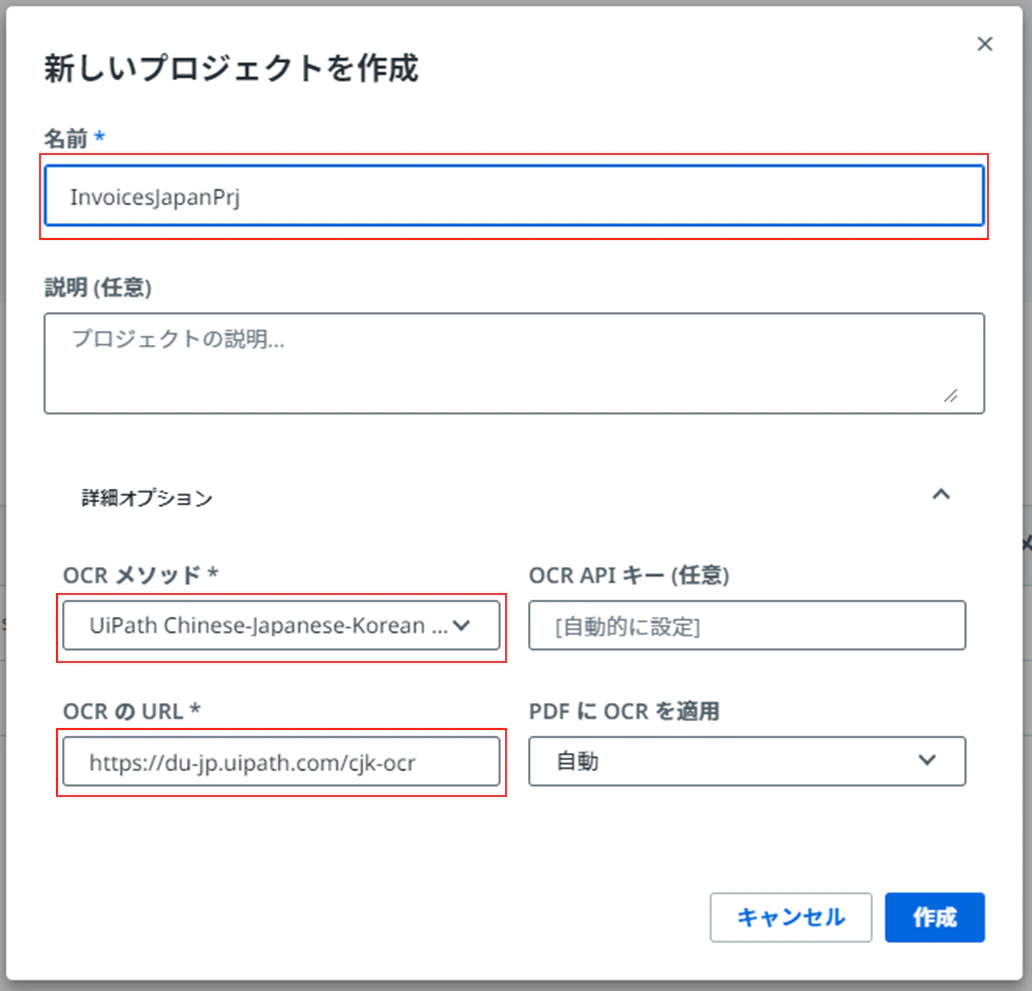
(2)「+新しいプロジェクト」をクリックしてプロジェクト名を入力、詳細オプションを展開し、「OCRメソッド」、「OCRのURL」( https://du-jp.uipath.com/cjk-ocr )を下記の様に設定し、「作成」をクリックします。
(3)「新しいドキュメントの種類」をクリックして、「半構造化AIを使用」を選択します。

(4)新しいドキュメントの種類を作成する画面で下記の様に設定して行きます。
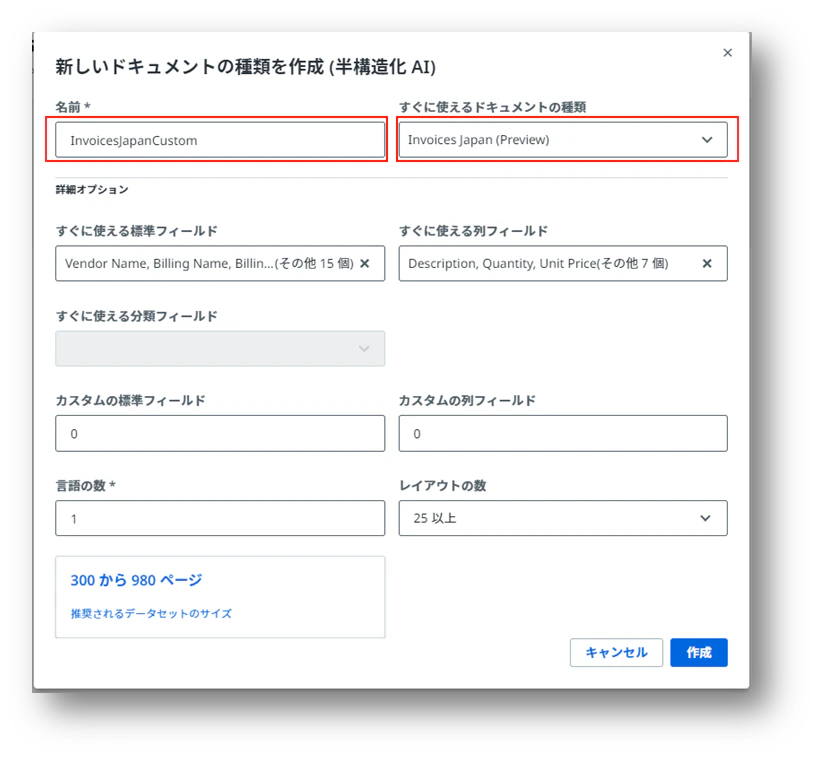
「カスタムの標準フィールド」、「カスタムの列フィールド」、「言語の数」、「レイアウトの数」を設定すると下部に表示されている推奨されるデータセットのサイズ(ペース数)が変更されます。実態に合わせて変更して参考値として見ておきましょう。尚、今回追加する「カスタムの標準フィールド」は、ここで数を指定すると、デフォルトでフィールドが追加されますが、次のステップで追加するので、ここでは0のままでも問題ありません。
(5)「InvoicesJapan (請求書 - 日本) - ML パッケージ」で既存で存在するフィールドが展開されます。標準フォールドを追加する場合は、下記の様に「+」をクリックします。
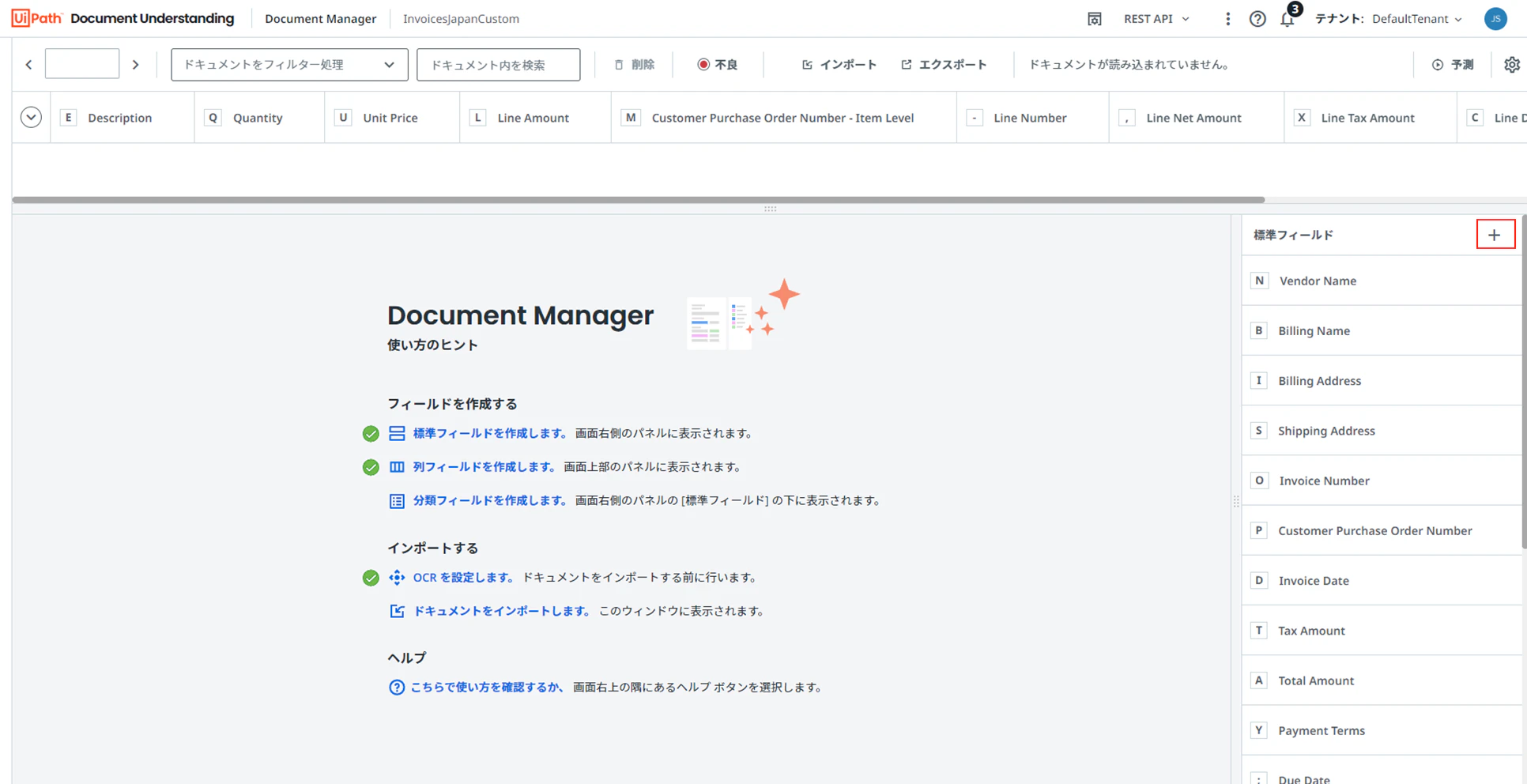
(6)新しいフィール名(振込先)を入力します。
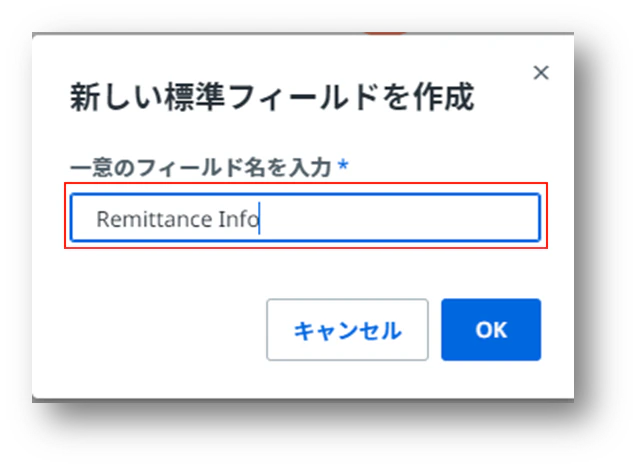
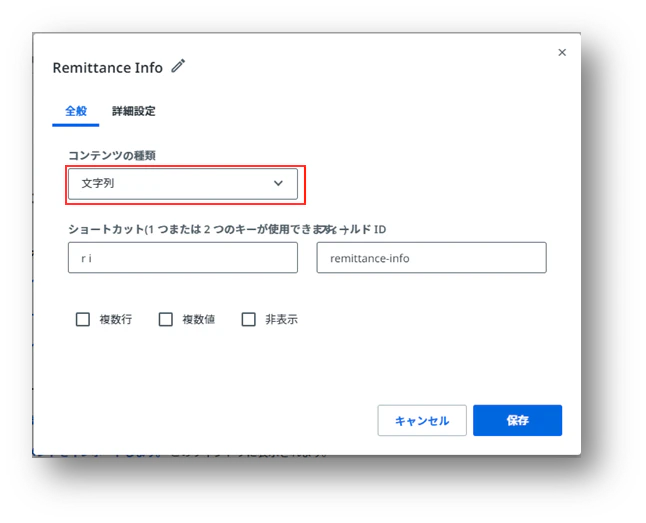
(7)コンテンツの種類を選択します。ショートカットキーやIDも編集できますが、ここでは自動的に決められたものを使用することにします。後からでも編集できます。
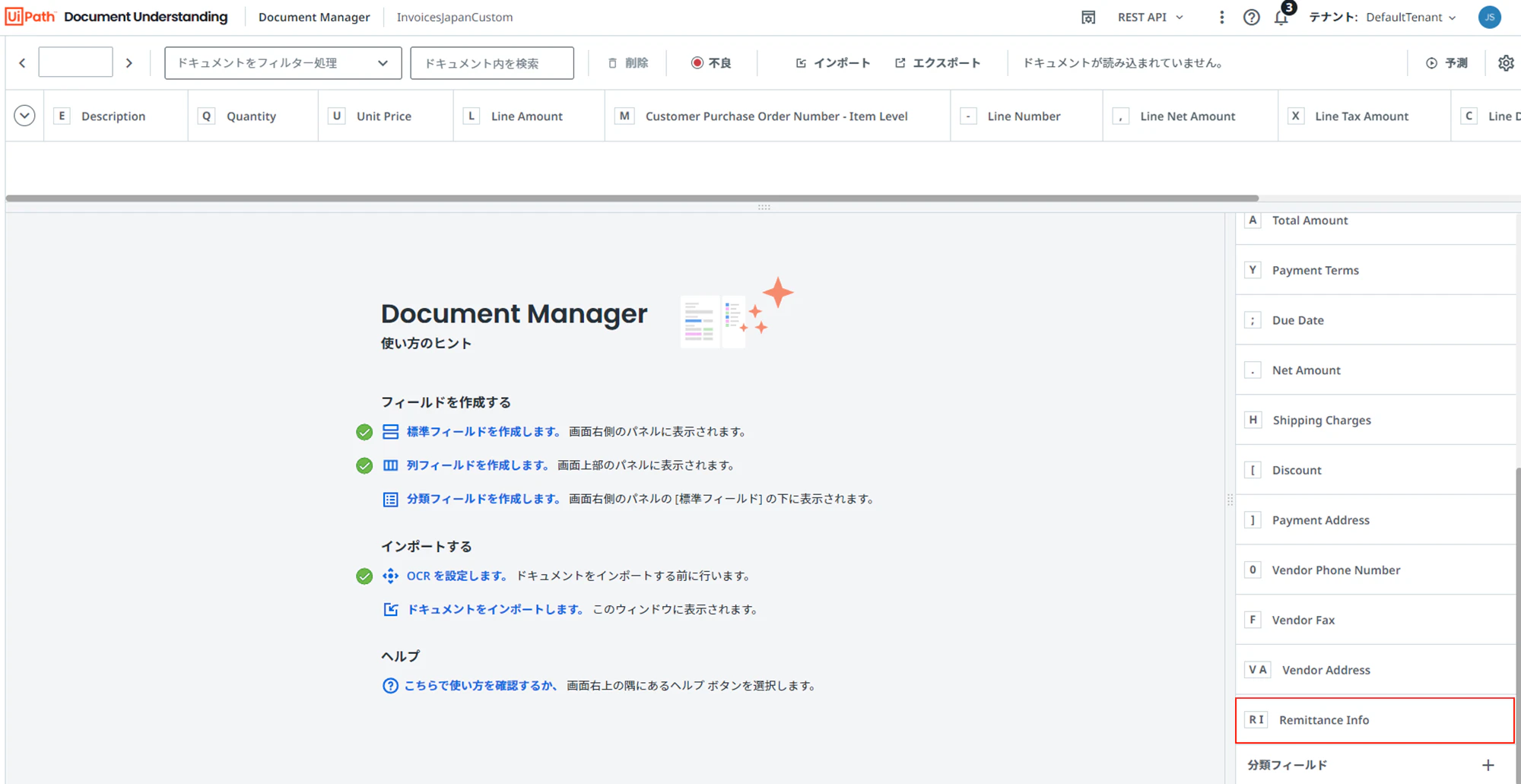
(8)下記の様に標準フィールドが追加されます。
(9)トレーニングで利用するファイルを取り込むため「インポート」をクリックします。

(10)実際に利用する請求書をいくつかインポートします。「インポート」するファイルを選択して「アップロード」をクリックします。
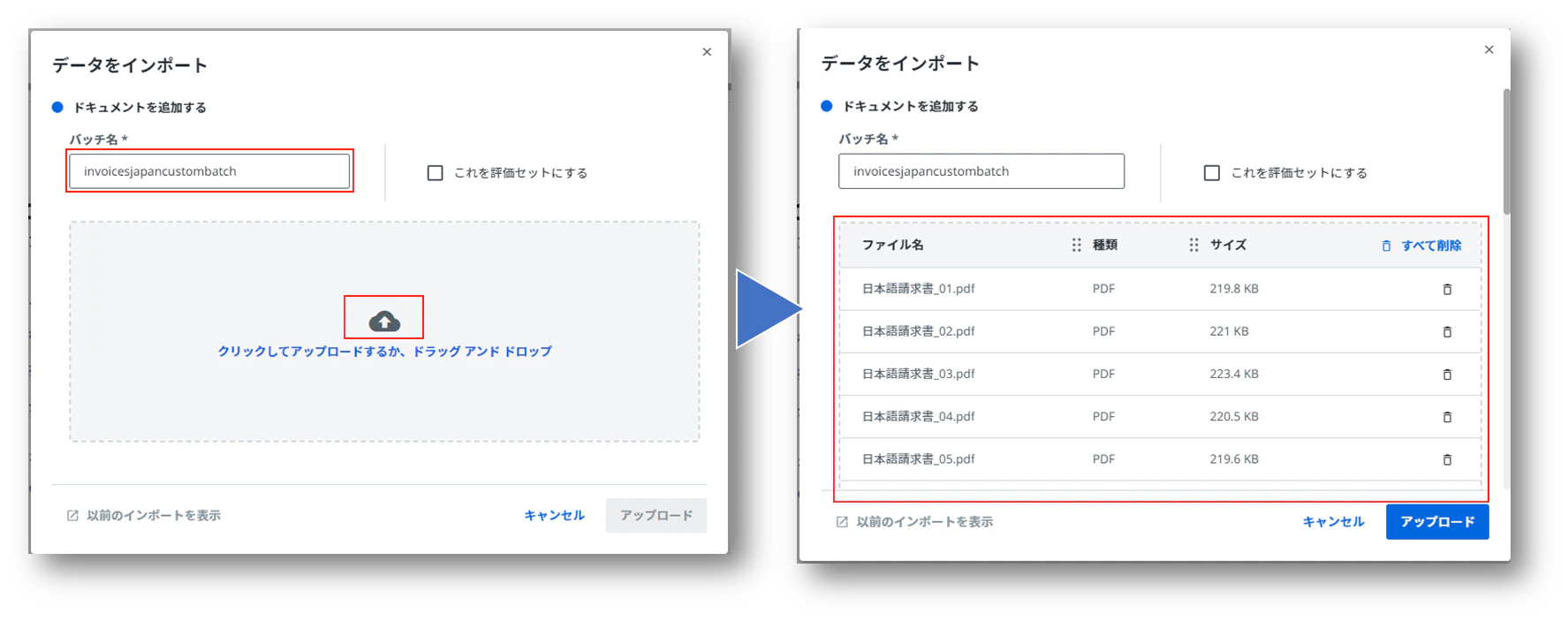
試しで行う際は、下記のブログで提供頂いているサンプル請求書を利用するのも良いと思います。こちらの請求書には、振込先などの情報もあります。
最低10枚は必要です。精度を高めるためには対象の帳票単位で20枚以上必要で、フィールドを追加する場合は、それ以上の枚数をお勧めします。
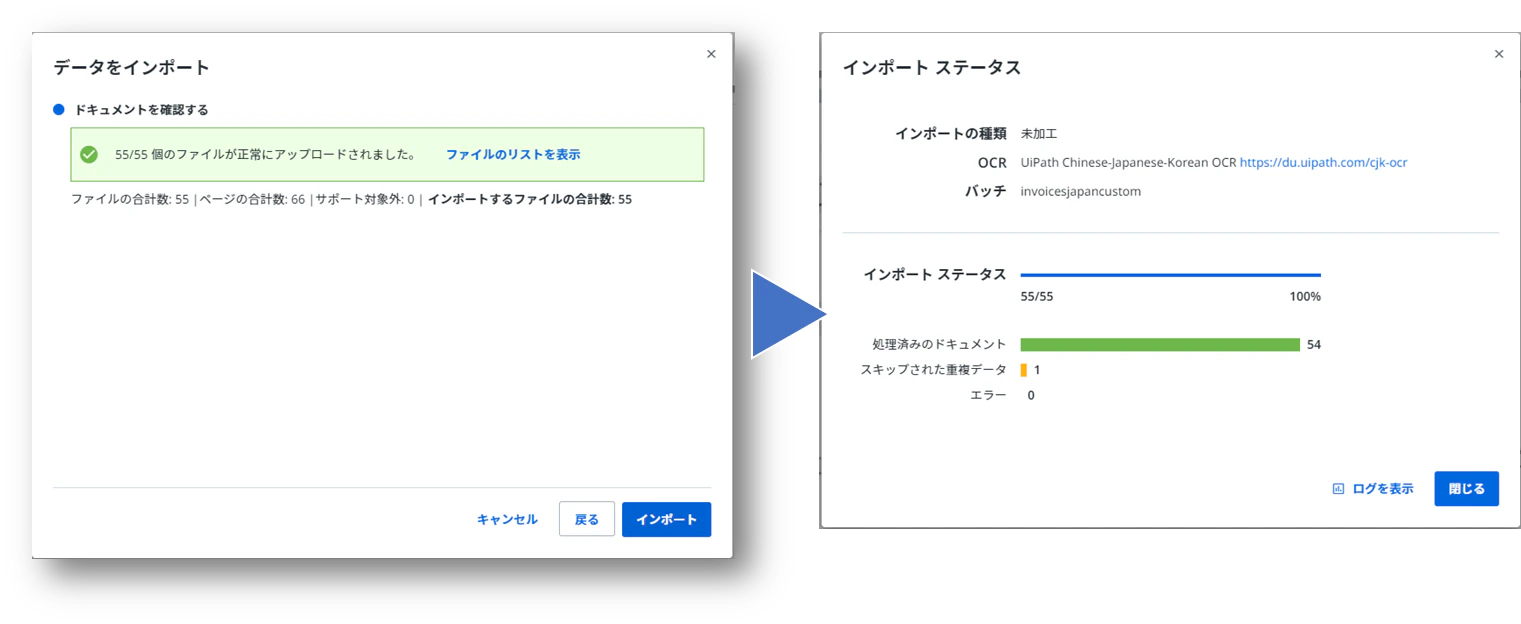
(11)続けて「インポート」をクリックします。インポートステータスが表示されます。もし、同じ帳票が重複していた場合は、下図の様に、その帳票のインポートはスキップされます。
(12)ラベリングする1ページ目の帳票が表示されます。「予測」をクリックすると、ある程度、自動的にラベリングされます。
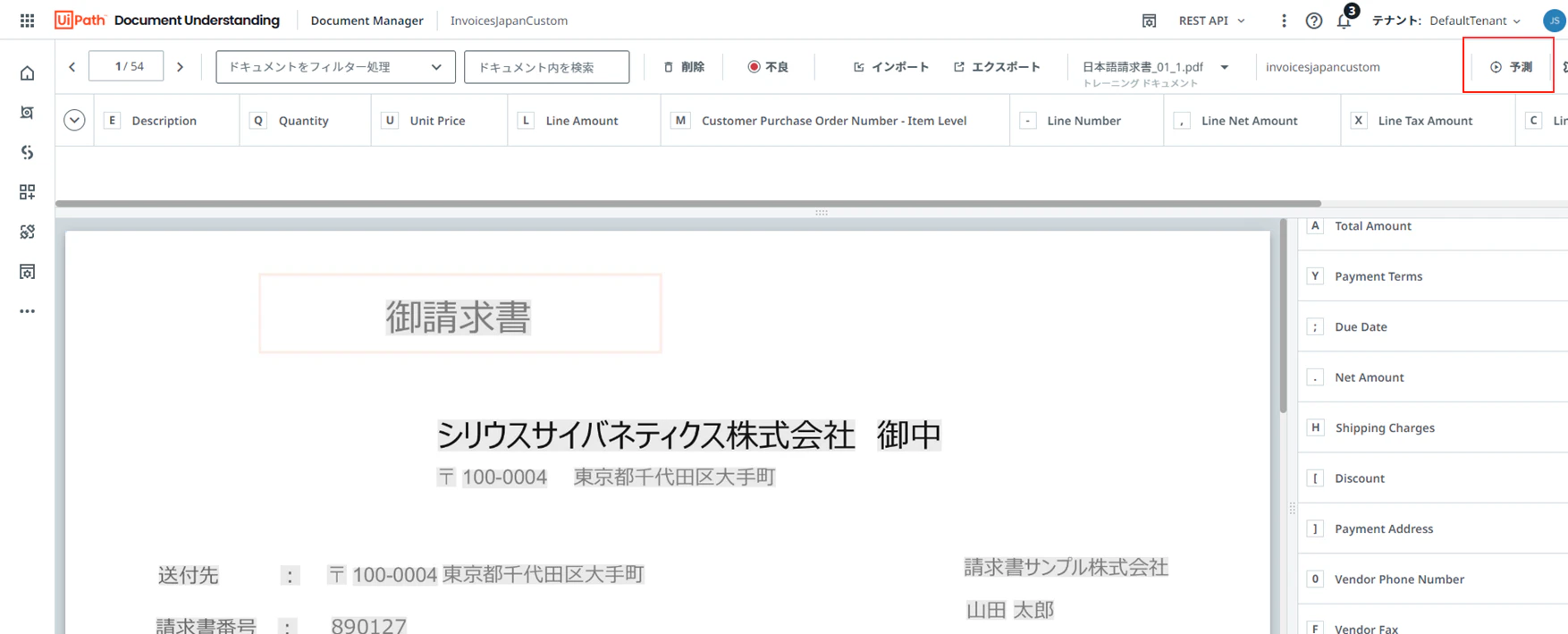
<予測でラベリングされた結果>
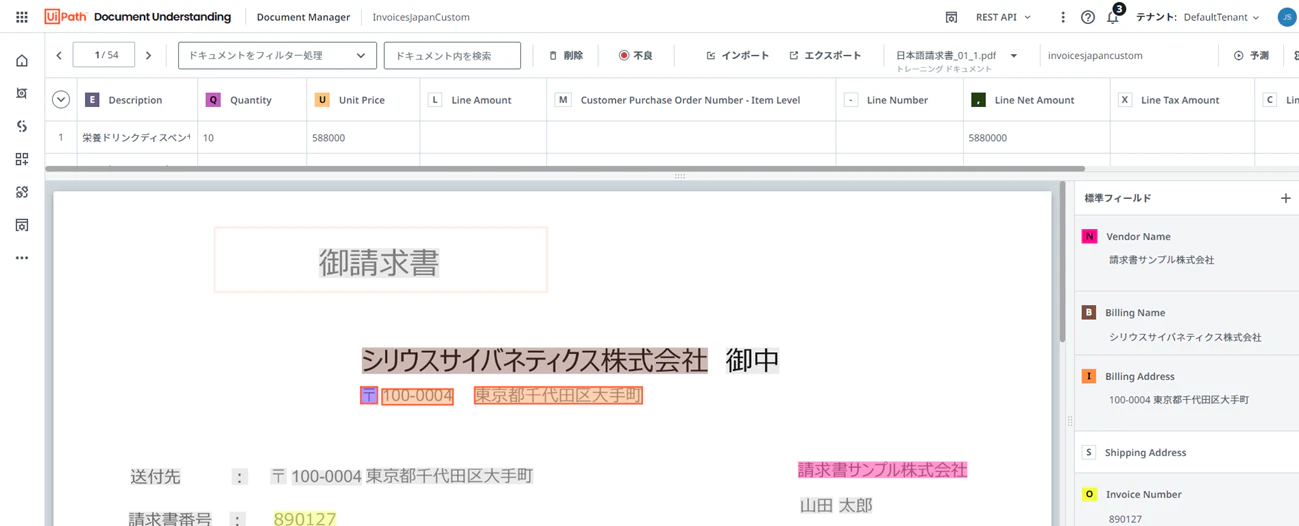
(13)ラベリングの操作は領域指定して、各フィールドに割り当てられているキーを押すと値を取り込みます。間違っていたり、不足していた場合は、この操作で修正して行きましょう。
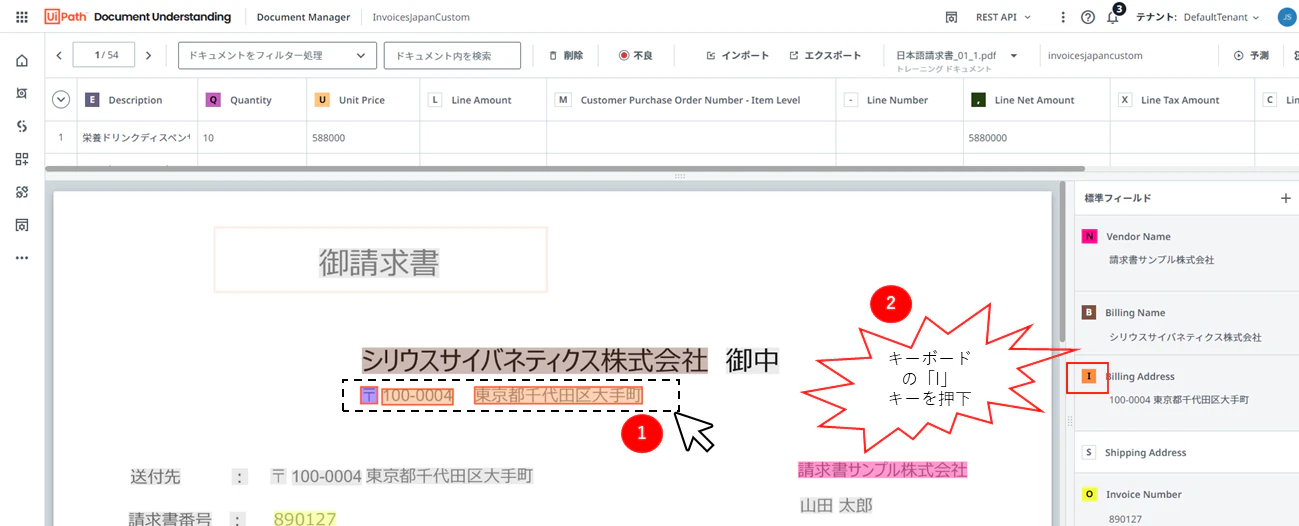
<修正が反映された結果>
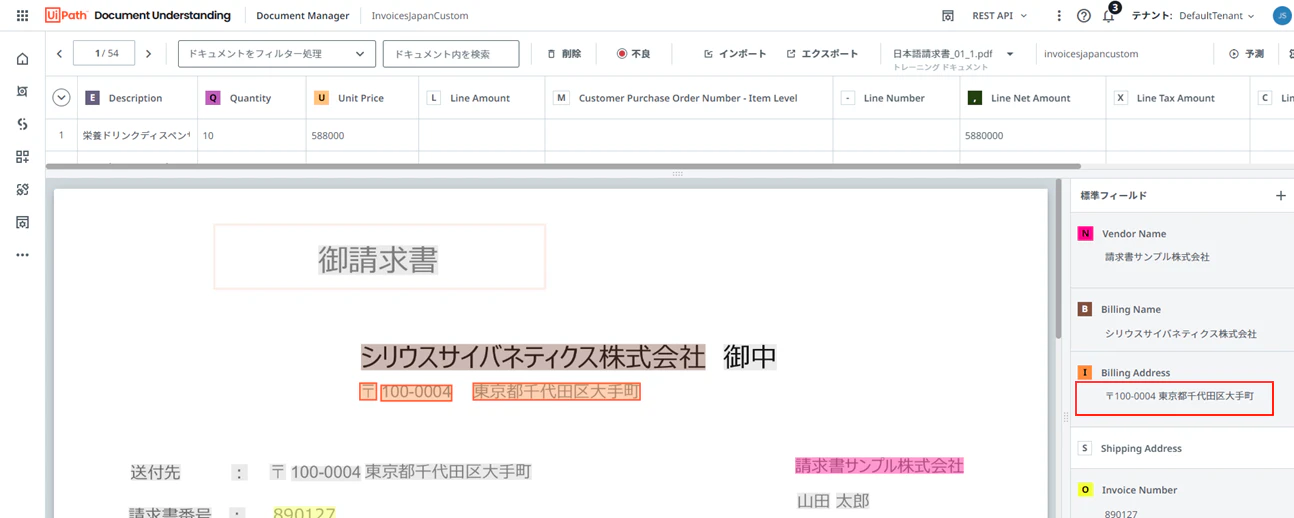
(14)表の列の場合も同様です。表の列フィールドは画面上部にあります。

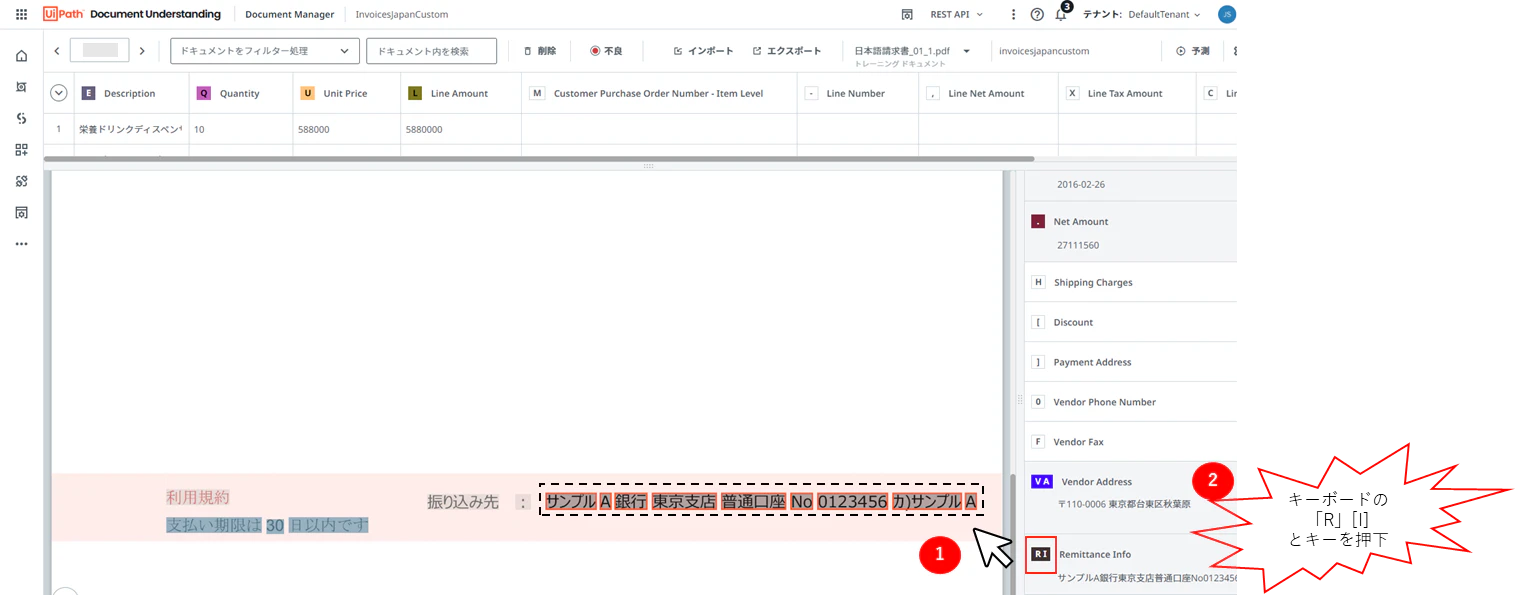
(15)今回追加したフィールドも、同様にラベリングして行きます。
(16)インポイートした全ての帳票に対してラベリングが終わったら、「エクスポート」をクリックします。
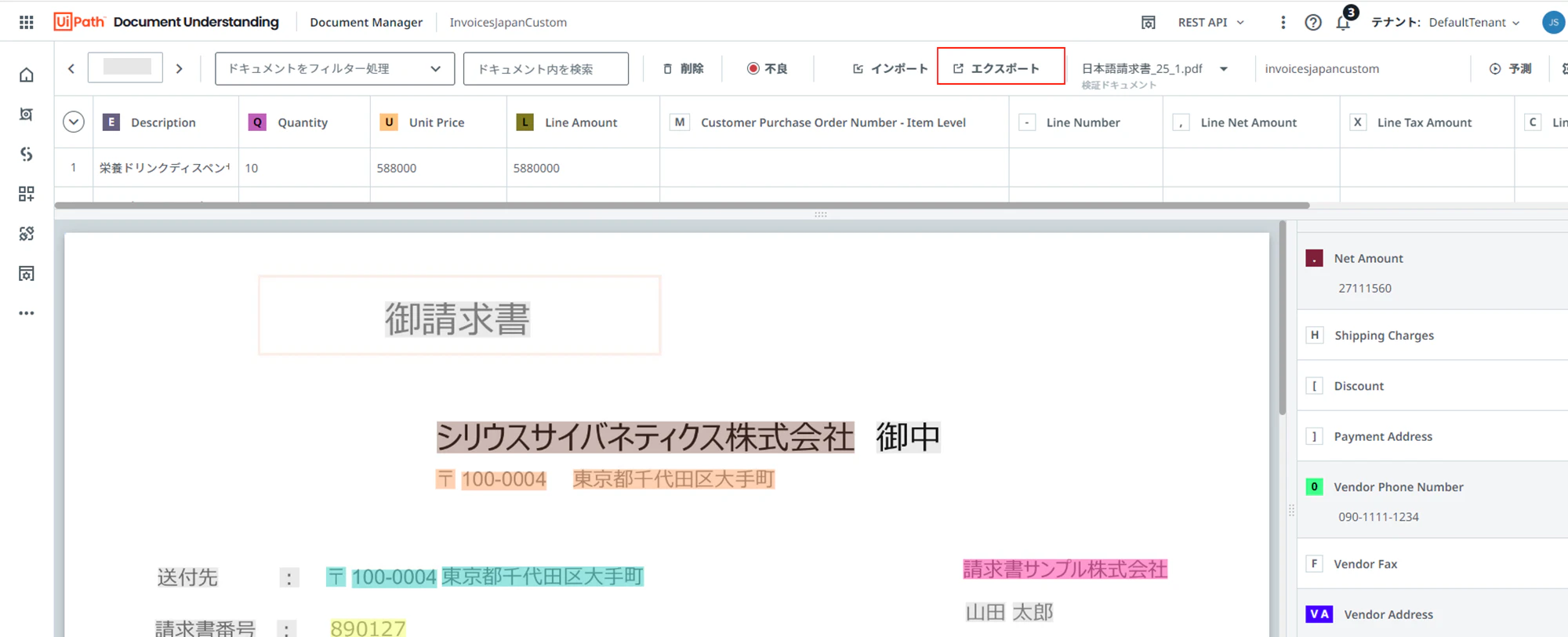
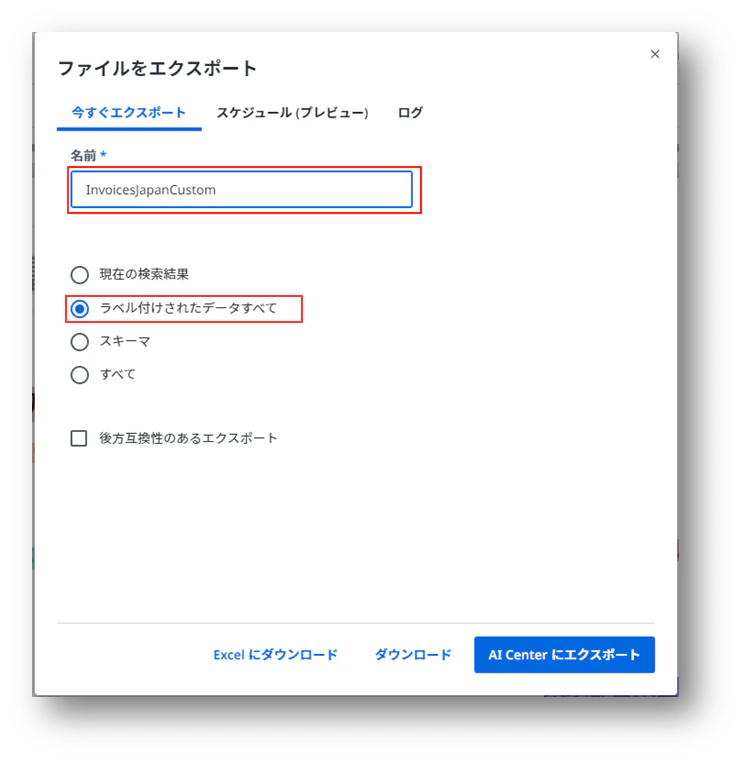
(17)下記の様に設定して、「AI Centerへエクスポート」をクリックします。
(18)ラベリングされていないフィールドがあった場合は下記の様なエラーが表示されてエクスポートできません。
<エラー表示>

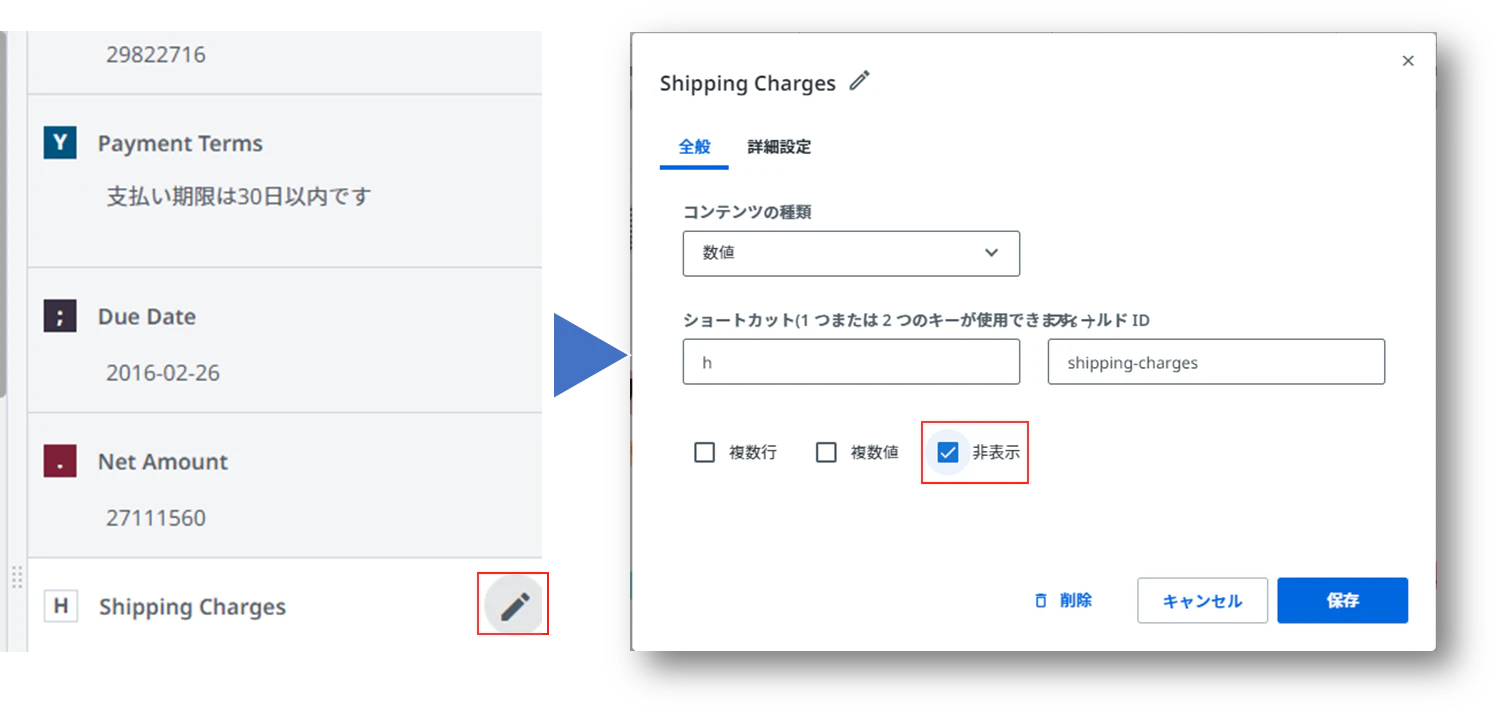
(19)不要なフィールドは下記の操作で非表示に設定して再度エクスポートを実施します。
(20)画面の「エクスポート」ボタンの点滅が終わると、AI Centerへのエクスポートが完了です。
AI Centerへのエクスポートをしましたが、本ブログでは、このエクスポートしたデータセットは利用しません。対象の帳票で不要なフィールドを非表示にするために、実施しました。
ワンクリック抽出機能で新しい抽出器を作成
ワンクリック抽出機能を利用すると、AI Centerで行うトレーニング操作を簡略化できます。ワンクリック抽出機能は自動でAI Centerと連携しながら、抽出器を作成できる便利な機能です。
(1)「抽出器」を選択します。「新しい抽出器」をクリックし、「自動トレーニング」を選択します。

(2)「名前」を入力し、「ラベル付けされたデータすべて」を選択します。GPUを使用しない場合は、トグルをオフして、「トレーニング」をクリックします。

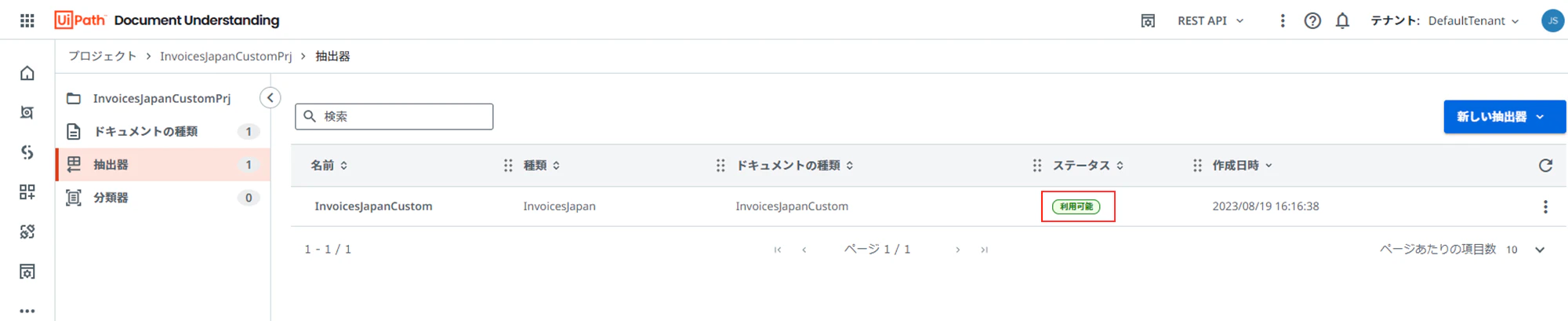
(3)ステータスか「利用可能」になれば、完了です。操作は、これだけです。AI Centerの各ステップでの操作と繰り返される待ちも、まとめて行われるので、とっても便利です。
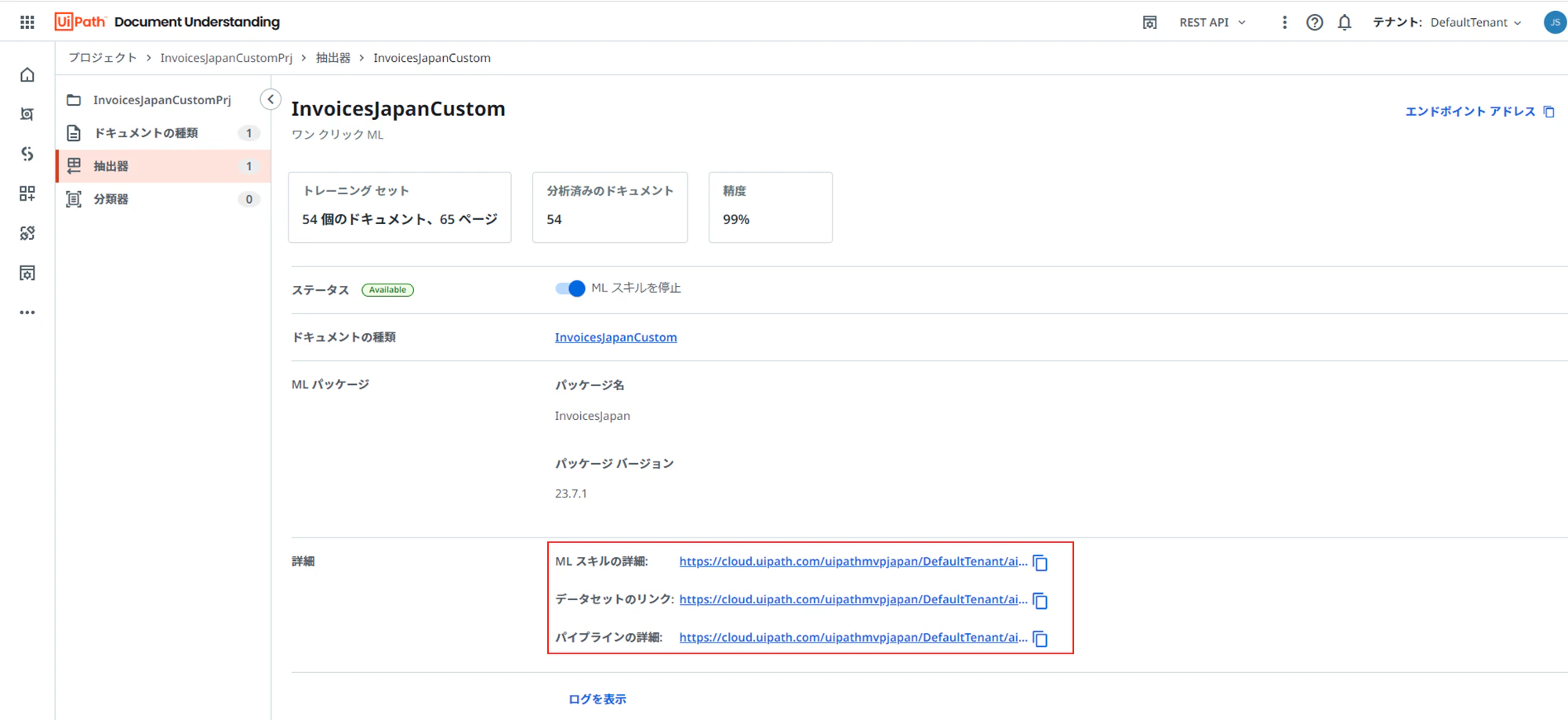
(4)一覧に表示されている抽出器の名前をクリックすると、詳細を確認することが出来ます。下記の赤枠部分をクリックするとAI Centerで行われた情報も確認できます。
2.UiPath Document Understanding Processの修正
新しいエンドポイントが出来たので、これをUiPath Document Understanding Processに反映して使って見ます。ここで利用しているのは、下記の記事で紹介したUiPath Document Understanding Process日本向けテンプレートです。
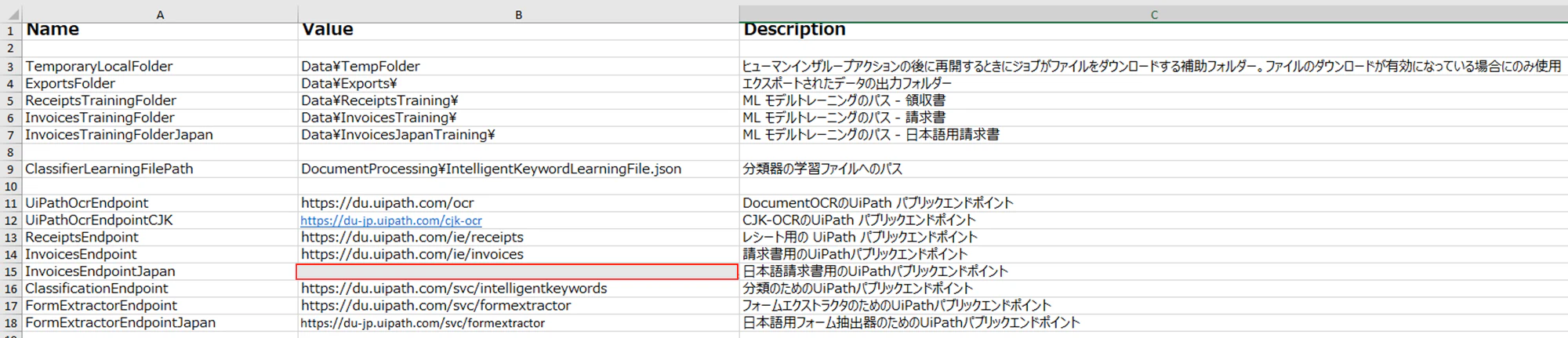
2.1 Configファイルのエンドポイントの修正
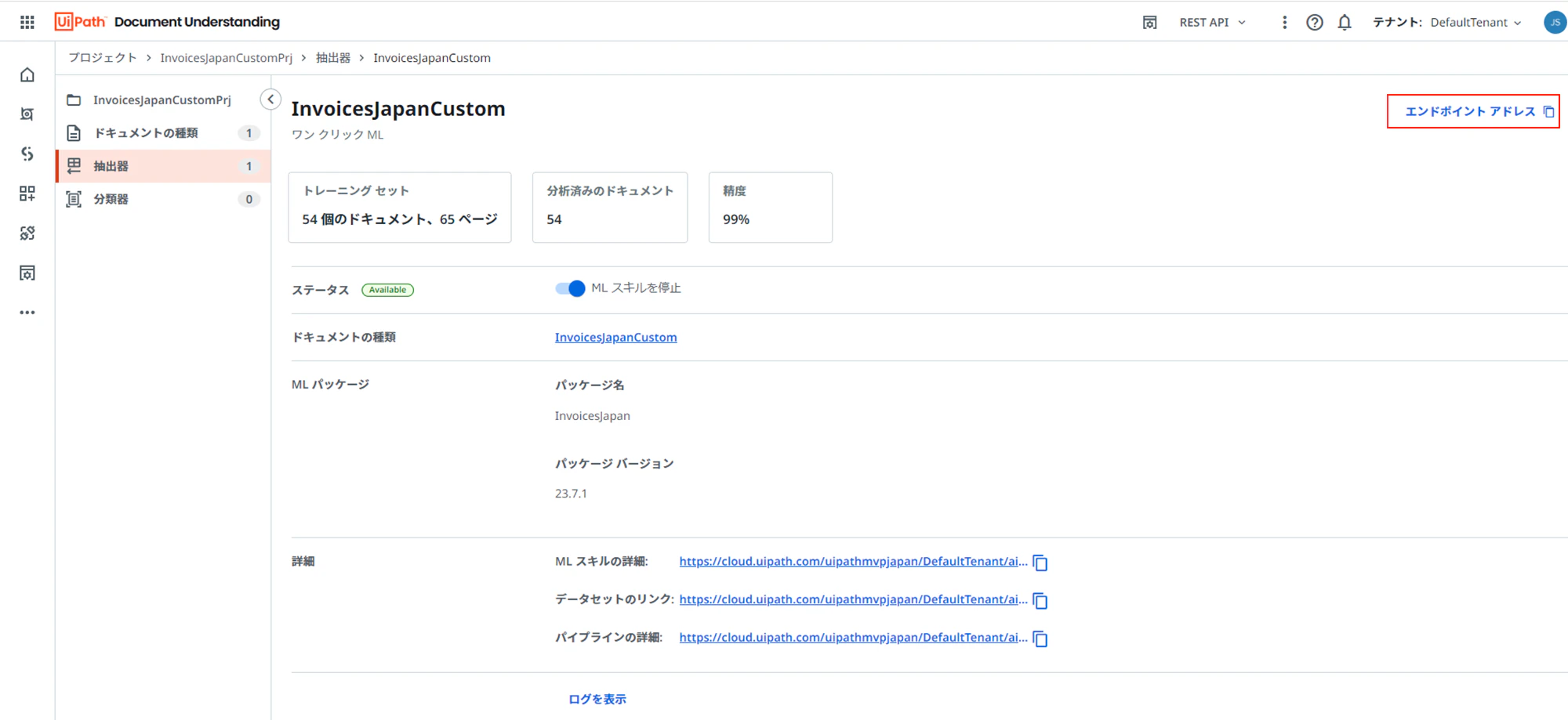
(1)新しい抽出器のエンドポイントに変更します。エンドポイントは、トレーニングで利用可能になったら下記の場所から入手可能です。
<エンドポイントの入手場所>
<Configファイルの修正場所>
2.2 タクソノミーマネージャでフィールド名の追加
(1)タクソノミーマネージャを開き、ラベリングで追加した振込先のフィールド名の追加します。

2.3 「30_Classify」(分類)の追加設定
(1)トレーニングした帳票を分類させるために、「学習の管理」をクリックしトレーニングを行います。実施しなければ、正しく分類器が機能しません。

2.4 「50_Extract」で日本語請求書 ML 抽出器を変更
(1)「抽出器を設定」をクリックします。
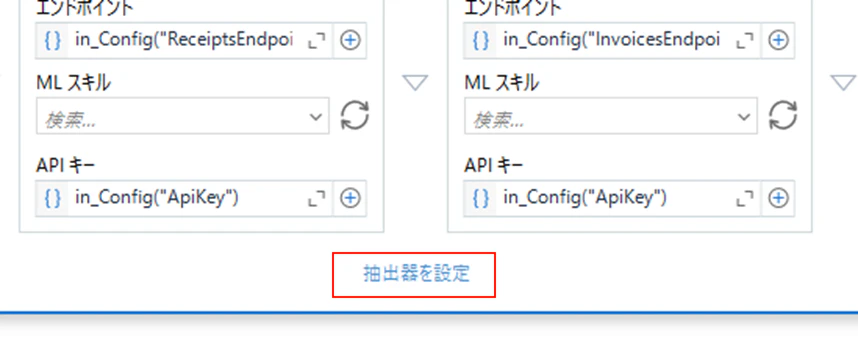
(2)トレーニングした新しい抽出器の有効なフィールド取得します。新しいエンドポイントを入力し、「機能を取得」をクリックします。
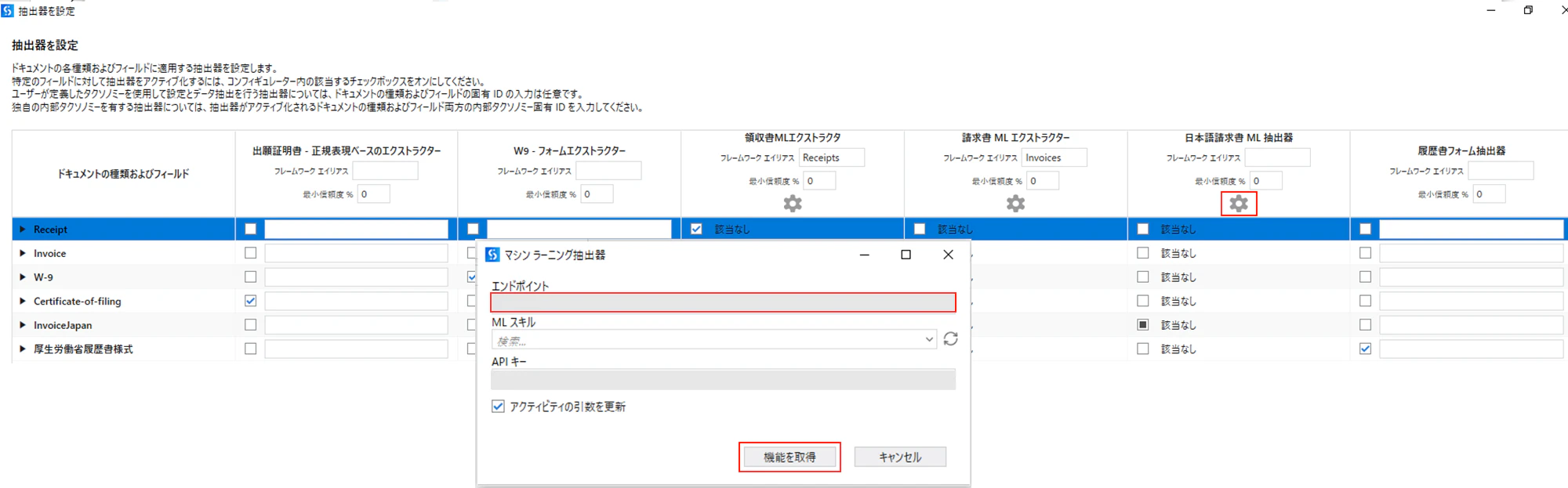
(3)非表示にしたフィールドは割り当てできなくなりますので、チックボックスをオフします。追加したフィール(remittance-info)は割り当てできる様になっているの割り当てを行います。
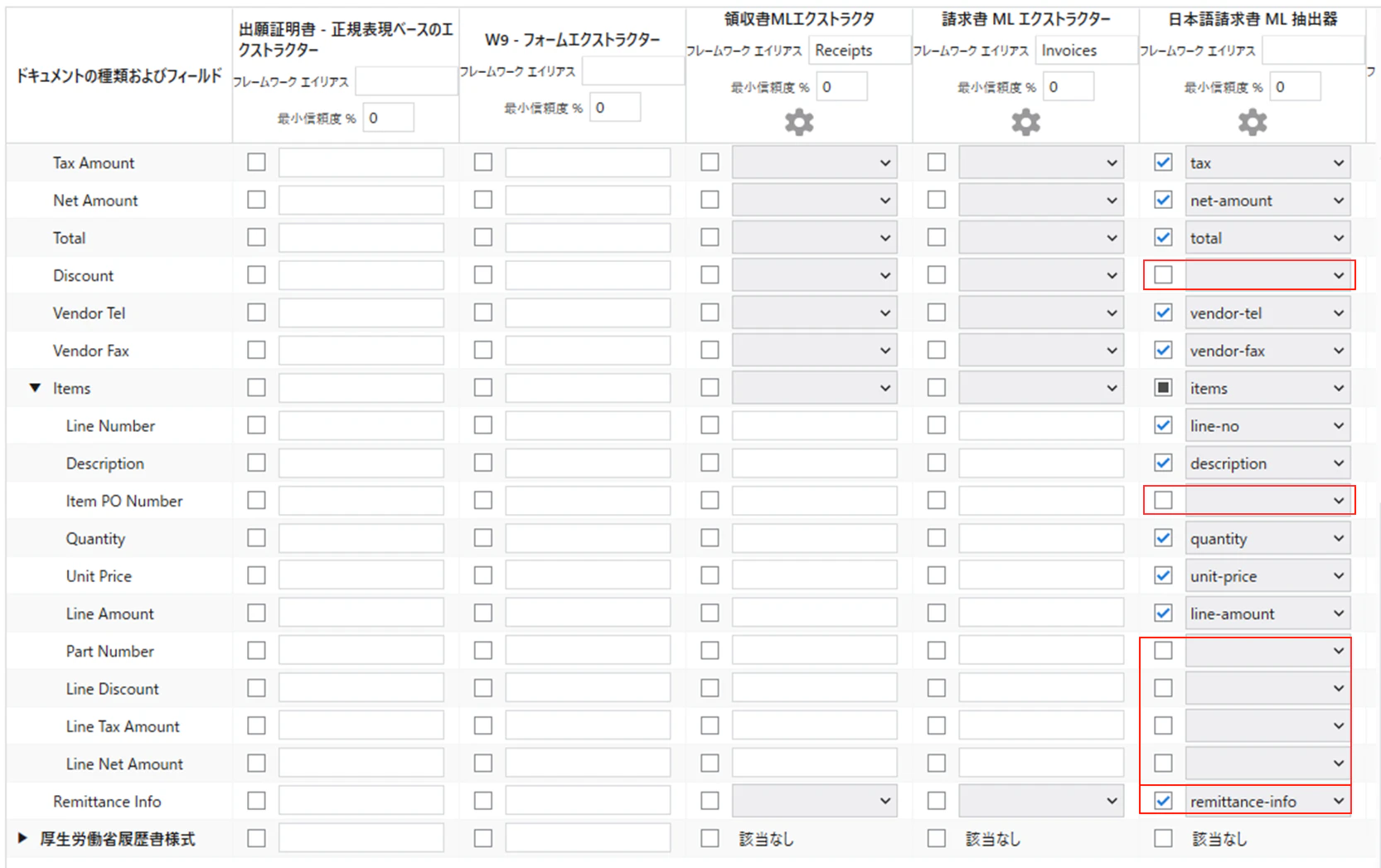
2.5 ワークフローを実行して、抽出結果を確認します。
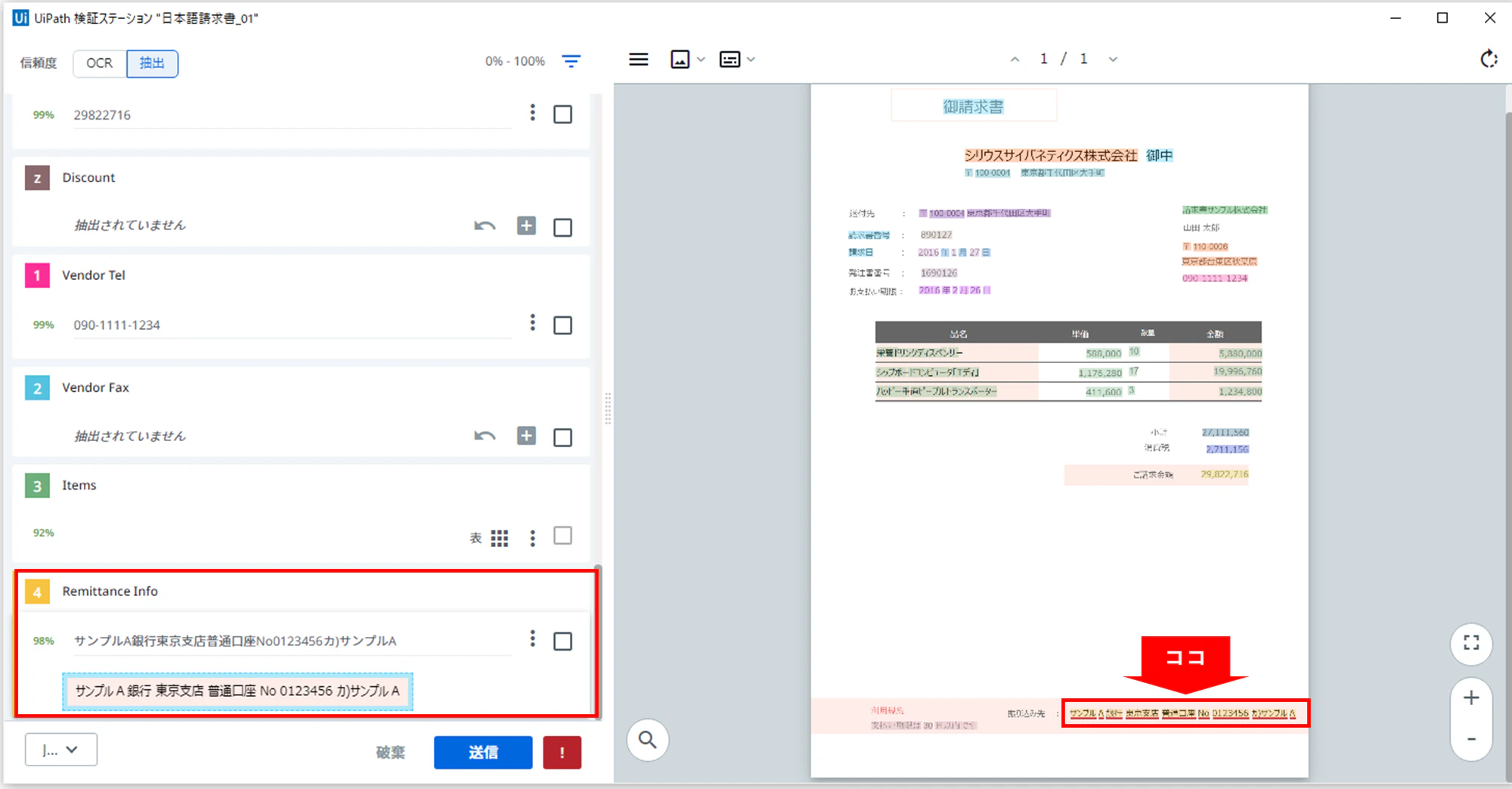
(1)正しく抽出されていれば、下記の様に出力されます。また、実際の帳票でトレーニングしたことで、抽出精度も向上していると思われます。

おわりに
UiPath Document Understandingは、自社の帳票に合わせて賢くして行くと言ったテクノロジーを提供しており、ベンダー提供のAIに依存しない、改善を待つことはない、思うように読取りできなくても諦めると言ったケースを減らすことができます。ただし、使いこなす様になるには、少々、知識のハードルは高めですので、専門家に任せると言ったこともあると思います。誰もがと言うことであれば、UiPathでは、簡単なものなら生成AIを利用して、もっとハードルを下げて、ツール感覚でドキュメントを理解するソリューションも出てきています。次は、こちらの紹介もしたいと思います。