はじめに
こんにちは!
TRAIL社会人メンバーの有馬純平です。
今日の記事では、CLIPとGPT-3の大規模モデルを用いて、言語指示から直接、ロボット視点の画像だけからナビゲーション可能であるLM-Navを紹介します。
LM-Navは何ができる?
LM-Navは、形式を問わない文章形式で、数箇所のランドマークを文章で指示するだけで、その順にビジュアルナビゲーションを実行することが可能です。
ロボット自身は、最初に言語指示をもらったあとは、3つの大規模モデルを駆使しながら、ロボット視点の画像だけからナビゲーション可能です。
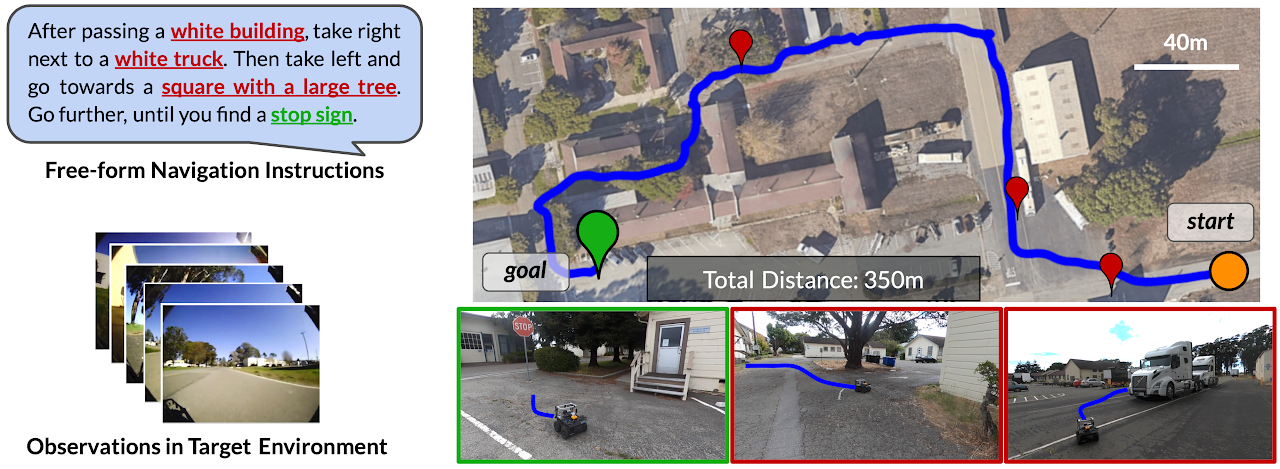
図1: LM-Navの概要(出典: LM-Navのサイト)
LM-Navは何がすごい?
LM-Navのすごい点は、基盤モデルを用いることで、自然な言語指示からロボット制御までをEnd-to-Endで実行可能という点以外で、
ロボット制御に学習モデルを用いる目線からと、自律ナビゲーションシステムとしての目線からでそれぞれ以下があると思います。
- ロボット学習として
- 実行環境での試行錯誤による学習なしで、zero-shotで適用可能
- real worldで動く
- 自律ナビゲーションシステムとして
- 自己位置推定や、マッピングなどのシステムが明示的になくても動作する
- 幾何学情報(LiDAR,点群地図,IMU,Odometry,GPSなど)なしで数百m単位のナビゲーションが、画像Inputのみで可能
LM-Navの概要
3つの事前学習モデル
LM-Navは、自然言語処理(LLM)、画像と言語の関連付け(VLM)、ビジュアルナビゲーション(VNM)のための3つの大規模な事前学習済みモデルから構成されています。ここでは、それぞれのモデルについて説明します。
-
Large language models(LLM)
LM-Navでは、自然言語指示からランドマークのシーケンス情報に変換を行うために、基盤モデルのGPT-3を利用しています。 -
Vision-and-language models(VLM)
VLMは、画像と言語を紐付けるモデルだが、LM-NavではCLIPを用いて、言語指示であたえられたランドマーク情報とロボットの観測した画像との類似度を計算しています。 -
Visual navigaiton models(VNM)
VNMは、2つのロボット視点の画像が与えられたときに、その画像間の距離を推定することのできる自己教師あり学習のモデルで、このモデルを駆使することで、環境内で走行したオフラインデータから自動でトポロジカルグラフを生成(本論文ではこれを"mental map"と呼んでる)と、目標地点の画像が与えられたときにそこまでナビゲートする制御が可能なものになります。
詳細は、本論文と同じ著者のViNGに書かれています。
(著者によるViNGの説明ビデオと、以前に研究室内の輪読会での資料があったので詳細知りたい方は見ていただければと思います。)
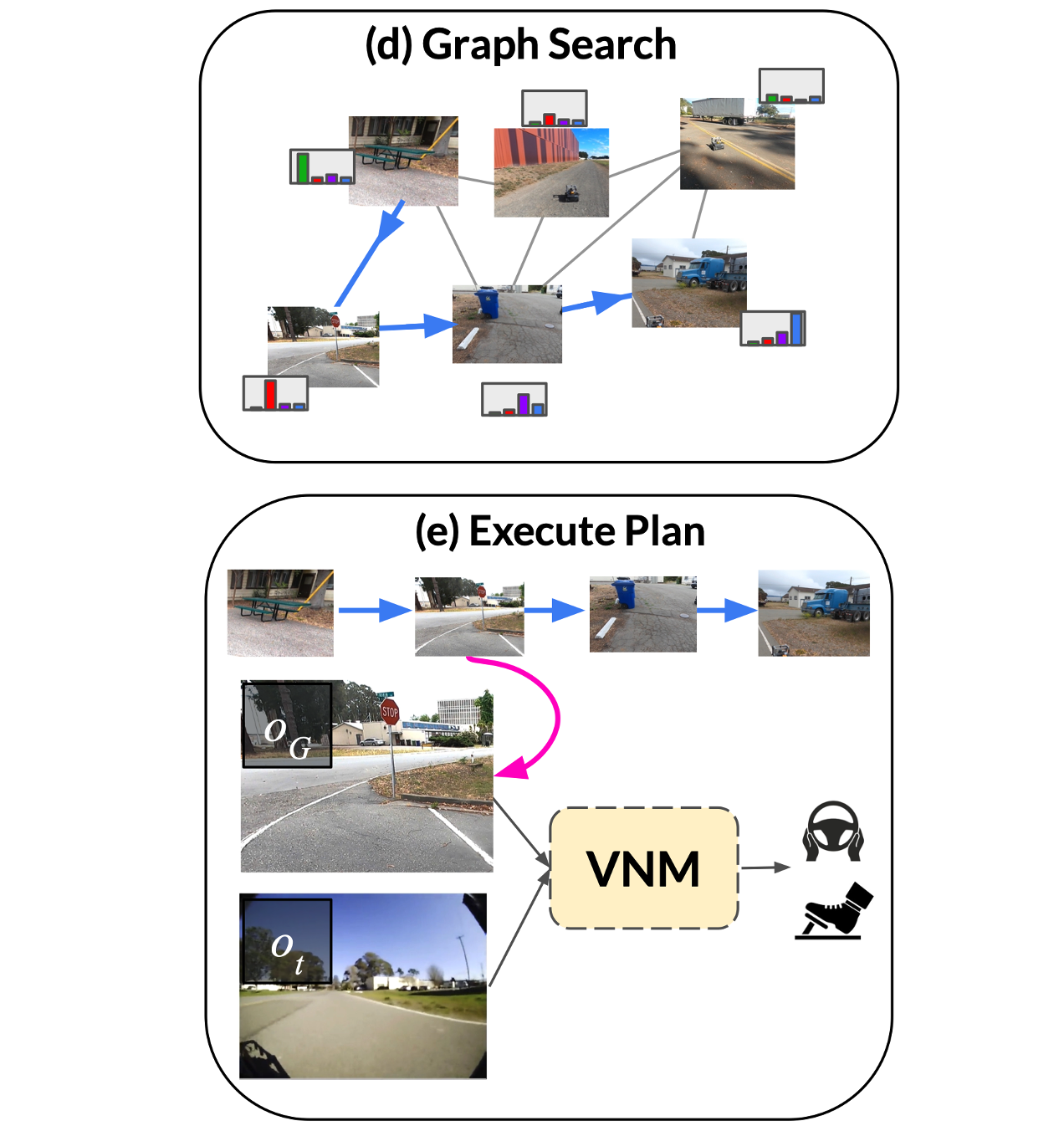
LM-Navの処理フロー
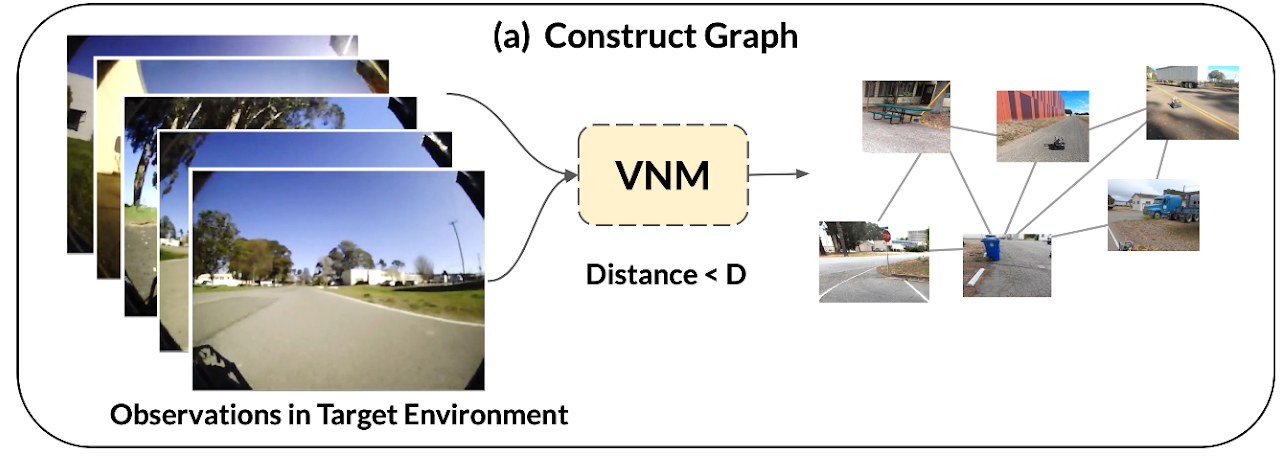
a. トポロジカルグラフ構築(VNM)
ターゲット環境の走行データからVNMの距離関数モデルと用いて、トポロジカルグラフ(mental map)を自律的に生成します。
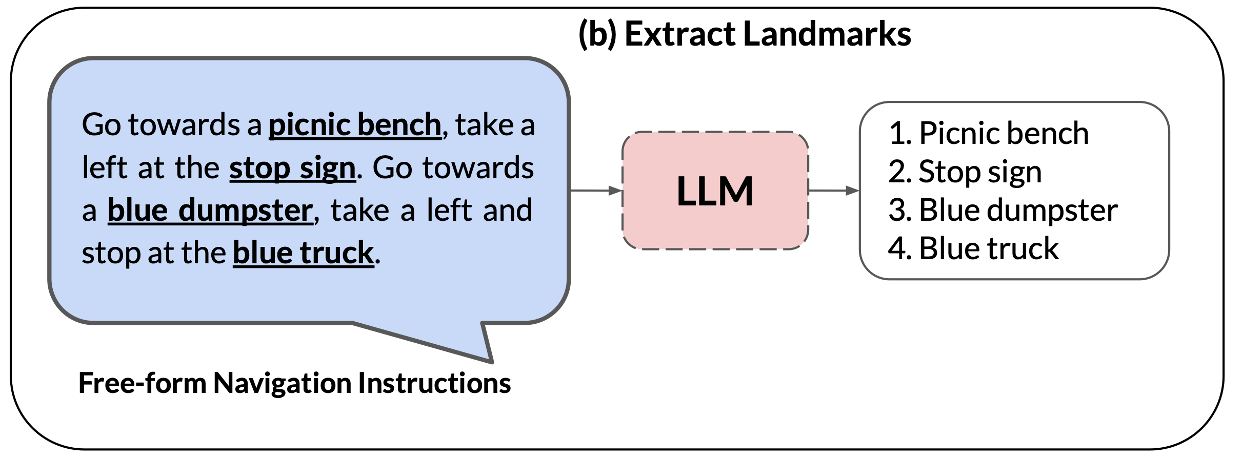
b. 言語指示からランドマーク列の抽出(LLM)
形式が自由な言語指示の文章から、どの順でランドマークを回るかをLLMを用いて抽出します。
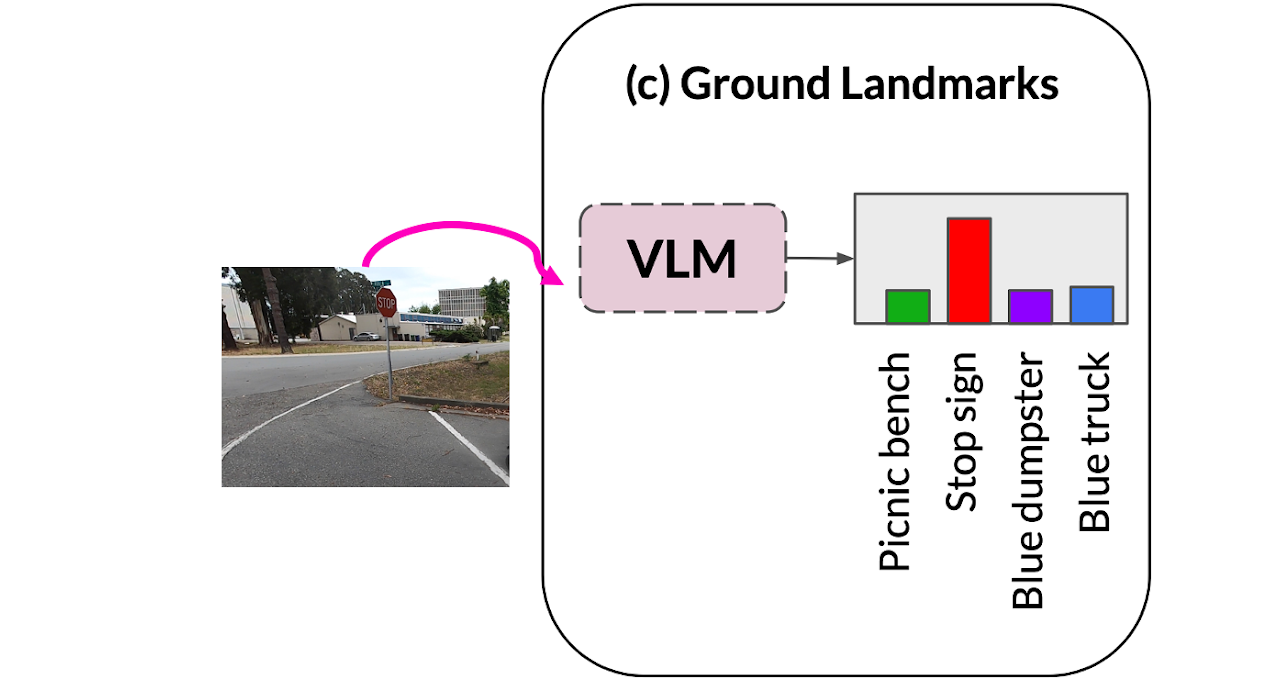
c. 各ノードのランドマークとの関連度合いを算出(VLM)
ランドマーク記述するテキストとグラフの各ノードの画像の関連度合いをVLM(CLIP)を用いて類似度を算出します。
d. トポロジカルグラフ上でのプランニング(VNM)
VLMの結果の各ノードでのランドマーク関連度とトポロジカルグラフを用いて、指示されたランドマーク順通り、かつグラフ上で最短の経路を、ダイクストラ法ベースの探索アルゴリズムでプランニングします。
e. サブゴールに向かってナビゲーション(VNM)
トポロジカル上の現在位置から、dで算出したプラン結果における次のノードに向かって、VNMを用いて移動します。
(VNMでは画像間の位置関係を推論可能でなので、相対位置関係が小さくなるようにPD制御をしています。)
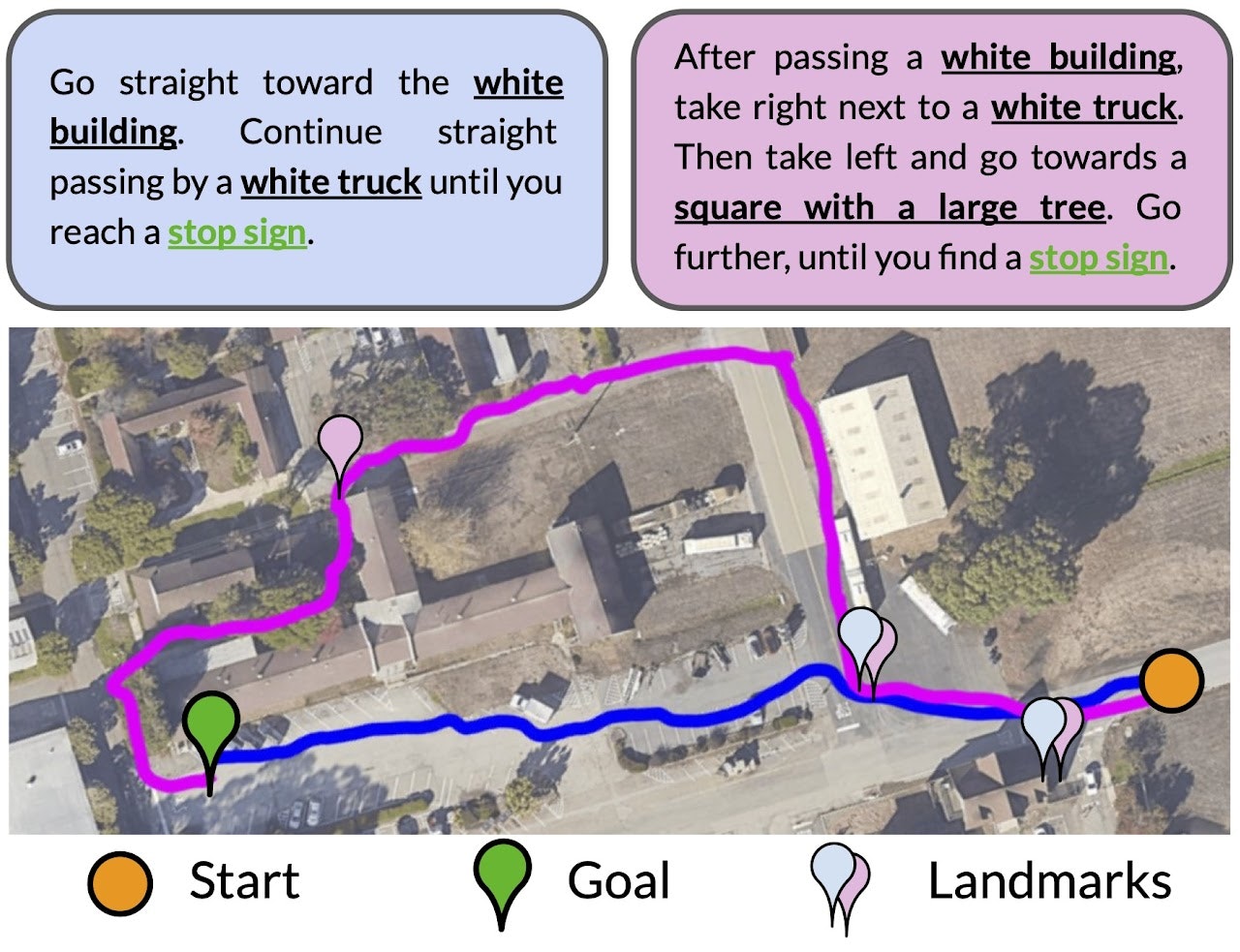
実験結果
言語指示は曖昧なタスク指示で、与えられた指示を満足するゴールへの経路が複数存在する可能性がありますが、
LM-Navは、言語指示を若干変えるだけで経路がしっかり変わることが以下の結果からわかります。
サンプルコード
LLMとVLMに関しては、著者がGoogle Colabでサンプルを提供してくれているので、いろいろ試すことができそうです。
まとめ
LM-Navは、3つの大規模モデルをうまく組み合わせることで、言語指示からビジュアルナビゲーションまでを追加学習無しで、End-to-Endで可能であることを示しました。
従来の幾何学的なプランニングとは全く異なる、画像と自然言語空間でのプランニングが可能になってきたことを実環境で示したのが、本論文の大きな成果かなと思います。
一方、この手法での限界はいろいろあり、n番目の交差点を曲がるとかの指示に対してや、歩行者の近くはゆっくりなど、ゴールだけでなく行動に対する言語指示は範囲外です。また、現状のVNMは、ターゲット環境の走行データがある程度必要であったり、動的障害物を回避するといったことができなかったり、まだまだ画像だけで実環境を走行する難しさがあるという点もあるかなと思います。