本記事は、ロボット Advent Calendar 2015 の15日目の記事です。
(いますぐデモ動画を見る場合はこちら)
最近SoftBank社のロボットであるPepperが流行ってきています。先日1決勝戦が行われたPepper App Challenge 2015 Winter 及び Pepper Innovation Challenge 2015では、 250 を超えるチームからの応募があり、一般販売や法人向け販売、アトリエサテライトの全国展開などにより、さらに発展していきそうです。
コミュニケーション用ロボットであるPepperにおいて音声認識は、Pepperにリアルさを持たせるための重要な要素です。音声認識機能として、Choregrapheには標準でSpeech Reco.BOXやChoiceBOX、Dialog機能がありますが、どれも基本的には予め語群を指定しておく必要があります(Dialogはうまく使えば自由に音声を認識できますが、精度が微妙な様子2)。また、外部のクラウドサービスを用いて音声認識精度を向上させたい、という需要はそれなりにあるようで、既に行っている人もいます。
(http://qiita.com/songchongok/items/c4acde4320ef39128c87)
今回は、IBM Bluemixサービスから人工知能WatsonのSpeech to Text APIを用いて、 Pepperのマイクで取得した音声データをリアルタイムに解析して返すPythonサービス として sttproxy(仮) を作ってみたので、その概要と使い方について書いていきます。
Qiita初投稿なおかつ試作なため、何か不備や誤りなどあるかもしれませんが、その場合はコメントなどでご指摘いただきますと幸いです。
参考サイト
などなど...
環境
- Python 2.7.10
- Pepper NAOqiOS 2.4.2.26
- Choregraphe 2.4.2
- pynaoqi: 2.1.4.13
システムの概要
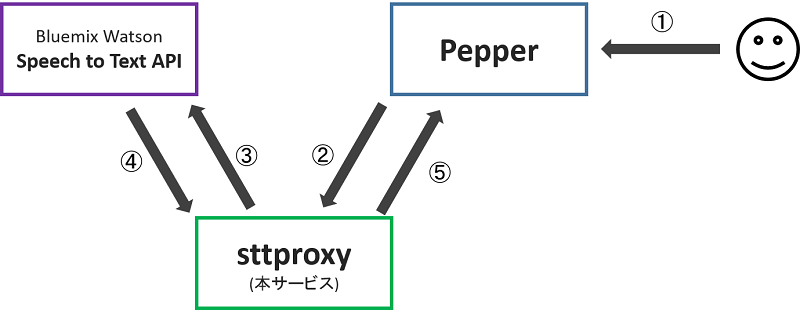
上の画像がシステム概要図となります。
①まずPepperが搭載マイクで音声を取得します。②sttproxy(本サービス)はこれをストリーミングで取得し、③WatsonのSpeech To Text APIに流します。④Watsonの解析結果を取得したsttproxyは、それを⑤PepperにMemoryEvent経由で返します。
主要な流れは以上のみです。
sttproxyは常時起動させておくことを想定していて、PepperアプリからMemoryEvent経由でAPIとの接続を開始/終了するようにしています。
ソースコードはGitHubに公開しています。
snakazawa/qibluemix
(試作なので、いろいろ適当なのは見逃してください...)
サンプルの動作手順
sttproxyのサンプルとして、Pepperのマイクが取得した音声情報の解析結果をTabletに表示してみます。
前提
- Pepperの実機がある。
- 環境を満たしている。
- BluemixのWatson Speech to Text の credential を取得している3。
準備
-
git clone git@github.com:snakazawa/qibluemix.git: GitHubからリポジトリを取得します。 -
cd qibluemix; pip install -r requirements.txt: 必要なpythonライブラリをインストールします。 - Aldebaran公式サイトから Python NAOqi SDK をダウンロードしてインストールします4。
-
sample/sttproxy/sttproxy.pyの PEPPER_IPにPeperのIPアドレスを、USERNAME及びPASSWORDにBluemix Speech to Text APIのcredentials.username及びcredentials.passwordを設定します。
pythonサービスの実行
python sample/sttproxy/sttproxy.py で実行します。
ログが出力されたあと、 ready... と出力されていれば準備完了です。
動かない場合は、スクリプトの定数を見直してみてください。
Choregrapheのbehavior実行
sample/sttproxy/pepper/sttproxy.pml を実行するか、Choregrapheで開きます。
その後、Pepperの実機に接続して、プロジェクトをアップロードして実行します。
話しかける
下の動画は、実際に動かしてみた様子です。
※動画内のスマホは原稿を見るためのみに利用しています。(2015/12/15 13:11追記)

こんにちは。
今日もいい天気だね。
これは、ロボットAdventCalendar2015の15日目の記事用のデモです。
Pepperはコミュニケーションに特化したロボットです。
今はBluemixのWatsonと連携して声を認識しています。
ご飯を食べに行こうか。
今日はお寿司が食べたいな。
眠くなってきたから、コーヒーでも買ってきてもらえる?あ、ブラックで。
とりあえず、生3つ。
さようなら。
Choregrapheアプリは数分で自動的に終了するようになっています。
このデモを見ると、結構認識精度が高いように見えます。固有名詞であるPepper、Bluemix、Watsonもしっかりと認識しています。ただし、長すぎる文「これは、ロボット...デモです。」や、カジュアルな文「あ、ブラックで。」は、認識精度が落ちるようです。
ちょっと前まではPepperという単語も認識しなかったり、精度も今よりは低かったりする気がするので、時間が経てば上記課題も解決されるかもしれません。
プログラム
ビヘイビア
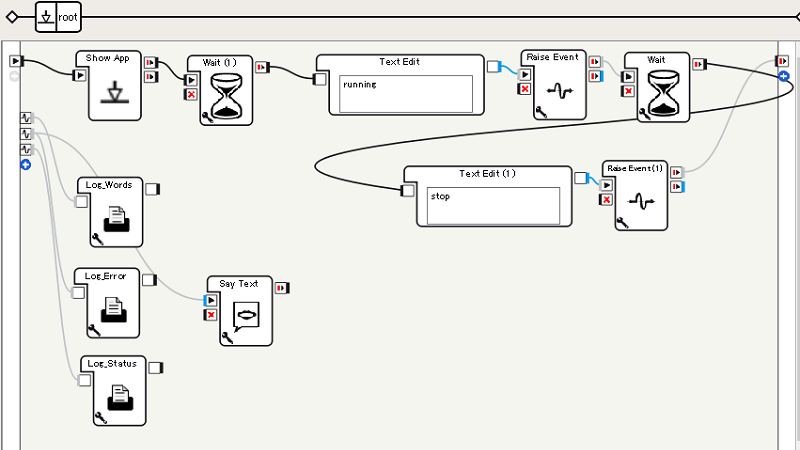
Raise Eventボックスで、 Bluemix/STTProxy/Status メモリに "running" や "stop" を格納することで、開始や終了を制御しています。
サンプルでは、Bluemix/STTProxy/WordRecognized イベントなどが発火するとログ出力するだけですが、ここを変えると多分いろいろできます。
Tabletで動かすJavaScriptコード
(function () {
var path = 'Bluemix/STTProxy/WordRecognized',
dom = {
words: document.getElementById('words'),
confidence: document.getElementById('confidence')
};
QiSession(function (session) {
session.service('ALMemory').then(function (almemory) {
almemory.subscriber(path).then(function (subscriber) {
subscriber.signal.connect(onWordRecognized);
dom.words.innerText = '(ready)';
});
})
});
function onWordRecognized(values) {
if (values.length > 0) {
dom.words.innerText = values[0][0];
dom.confidence.innerText = values[0][1];
}
}
}());
(説明のため簡略化しています。)
Bluemix/STTProxy/WordRecognized イベントが発火されると、 [[認識結果1, 認識精度2], [認識結果2, 認識精度2], ...] のようなデータが渡されます。データは、認識精度で降順にソートされているので、配列の長さが1以上ならば一番精度の良い認識結果と認識精度を画面に表示しています。
sttproxyサービスのPythonコード
省略します。
詰まりポイント(小ネタ)
Choregpraheアプリ上で音声データをsubscribe取得できない
本当はPCなどを用いずににPepperだけで動かしたかったのですが、Pepperの音声データを購読するモジュールをChoregrapheアプリ上で作って動かそうとすると、モーターか何かの致命的エラーが発生して強制再起動がかかってしまいました。PepperにSSHで接続して、内部でPythonスクリプトを実行するとうまく動いたのですが、それだと微妙です。ある程度調べても、リモートで動かしている人しか居なかったので、自分もそれに倣うことにしました。
試してないですが、C++でモジュールを登録すると、うまくいくのかもしれません。
もし、何か良い方法を知っている方が居ましたら、是非教えてください。
NAOqiでモジュール可するクラスのドキュメントにUnicodeが使えない
PythonでNAOqiAPIを使ってPepperのイベントを購読する場合、ALModuleクラスを継承したクラスを定義してインスタンス生成時にモジュールを作るのですが、このクラスのドキュメントをUnicodeで書くと、NAOqiに怒られてしまいました。
具体的には、
class Hoge(ALModule):
u"""
クラスの説明
"""
はダメで、
class Hoge(ALModule):
"""
クラスの説明
"""
にしないといけないようです。
Pythonのドキュメントの書き方を調べたら、Unicode使ったほうが良いって書いてあったのですが、Unicodeを使うと実行時エラーで落とされるので、仕方ないです。
課題
現状見つかっている課題としては下記のようなものがあります。
- Pepperから取得した音声データのノイズを除去する。現状はノイズが結構大きいため、マイクの近くで喋らないと認識してくれない。
- APIの接続/切断を自動化する。例えば、会話が聞こえたら接続、一定時間会話が聞こえなくなったら切断、のように。
- Pepperのマイクを4つ使う。現在は1つしか使っていない。
- PCを中継しないで処理を行う。
- エラー処理やリファクタリング。
おわりに
Bluemixとの連携により、それなりの精度の音声認識を簡単に使えるようになりました。
継続的に音声認識をするので、ある単語が文章に含まれていたら何かを行うとか、文章を録音し続けて何か解析したり学習したりするとか、いろいろできそうです。
それでは、次の人へバトンタッチします。