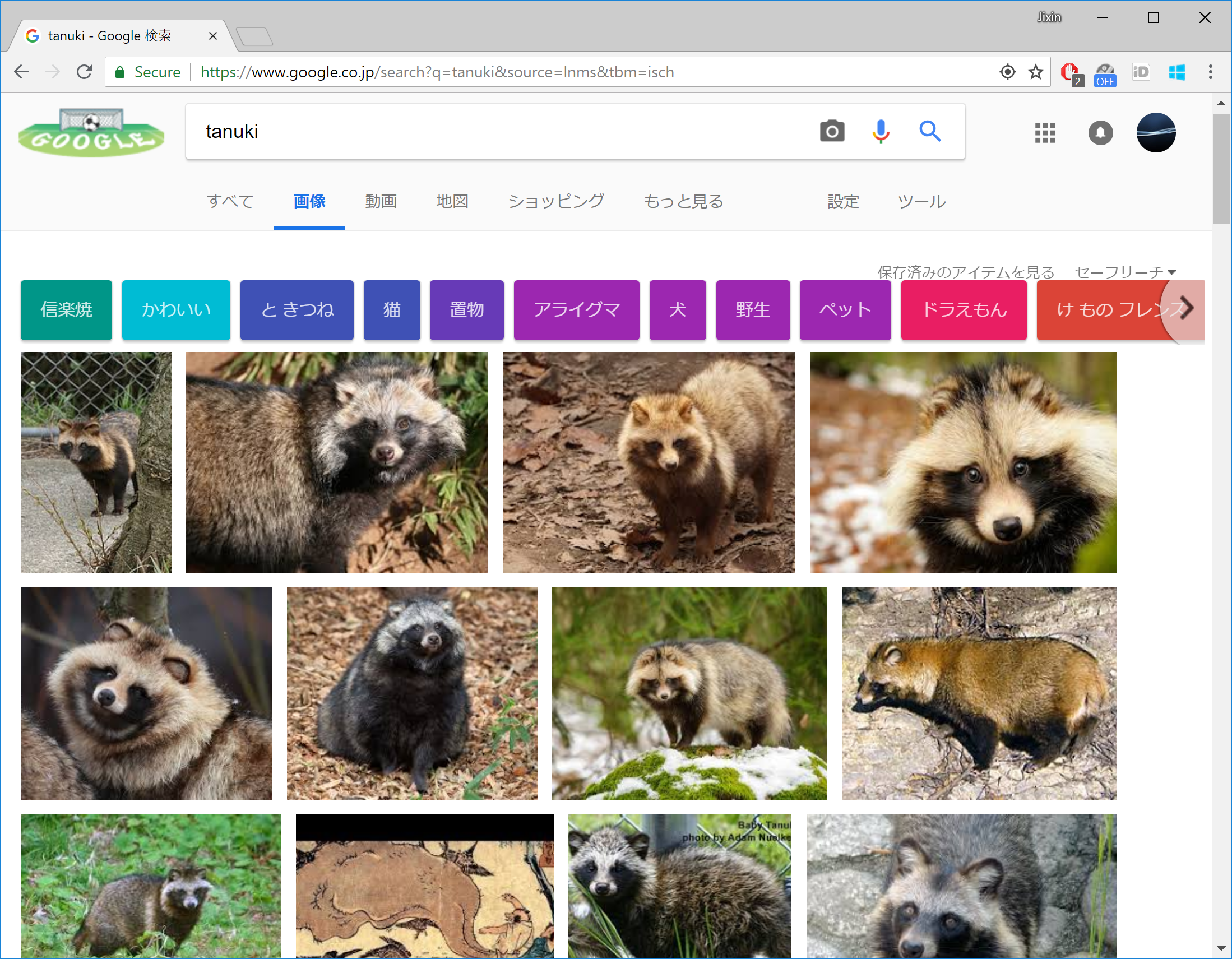
Googleの画像検索で必要な画像を大量ダウンロードするプログラムを作ってみました。深層学習や画像分析の準備に役立ちそうです。
ソースコード (Python 3で実証済み):
import bs4
import requests
import re
import urllib.request, urllib.error
import os
import argparse
import sys
import json
# How To
# (1) ソースコードを保存して命名する (e.g. scrape.py)
# (2) プログラムを起動する python scrape.py
# (3) オプション
# -s: Google Imagesにかける検索キーワード、複数可 (デフォルト "banana")
# -n: ダウンロードする画像の数量 (デフォルト 10枚)
# -o: 画像の保存先 (デフォルト <DEFAULT_SAVE_DIRECTORY>で指定する)
def get_soup(url,header):
return bs4.BeautifulSoup(urllib.request.urlopen(urllib.request.Request(url,headers=header)),'html.parser')
def main(args):
parser = argparse.ArgumentParser(description='Options for scraping Google images')
parser.add_argument('-s', '--search', default='banana', type=str, help='search term')
parser.add_argument('-n', '--num_images', default=10, type=int, help='num of images to scrape')
parser.add_argument('-o', '--directory', default='<DEFAULT_SAVE_DIRECTORY>', type=str, help='output directory')
args = parser.parse_args()
# 複数のキーワードを"+"で繋げる
query = args.search.split()
query = '+'.join(query)
max_images = args.num_images
# 画像をフォルダーでグループする
save_directory = args.directory + '/' + query
if not os.path.exists(save_directory):
os.makedirs(save_directory)
# スクレーピング
url="https://www.google.co.jp/search?q="+query+"&source=lnms&tbm=isch"
header={'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36"}
soup = get_soup(url,header)
ActualImages=[]
for a in soup.find_all("div",{"class":"rg_meta"}):
link , Type =json.loads(a.text)["ou"] ,json.loads(a.text)["ity"]
ActualImages.append((link,Type))
for i , (img , Type) in enumerate( ActualImages[0:max_images]):
try:
Type = Type if len(Type) > 0 else 'jpg'
print("Downloading image {} ({}), type is {}".format(i, img, Type))
raw_img = urllib.request.urlopen(img).read()
f = open(os.path.join(save_directory , "img_"+str(i)+"."+Type), 'wb')
f.write(raw_img)
f.close()
except Exception as e:
print ("could not load : "+img)
print (e)
if __name__ == '__main__':
from sys import argv
try:
main(argv)
except KeyboardInterrupt:
pass
sys.exit()
実証テスト
キーワードを「tanuki」で画像25枚スクレープする:
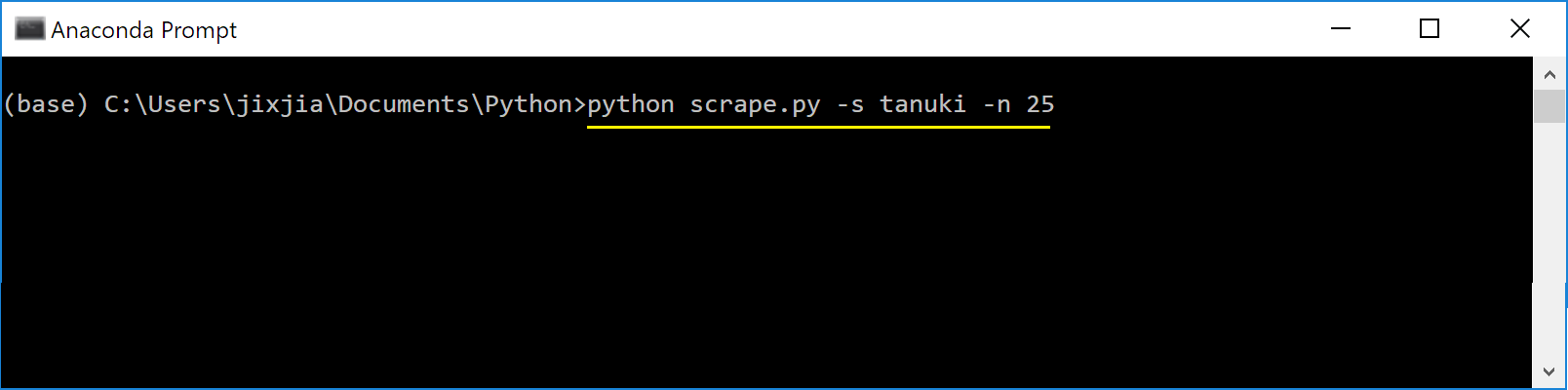
スクレーピングの結果:
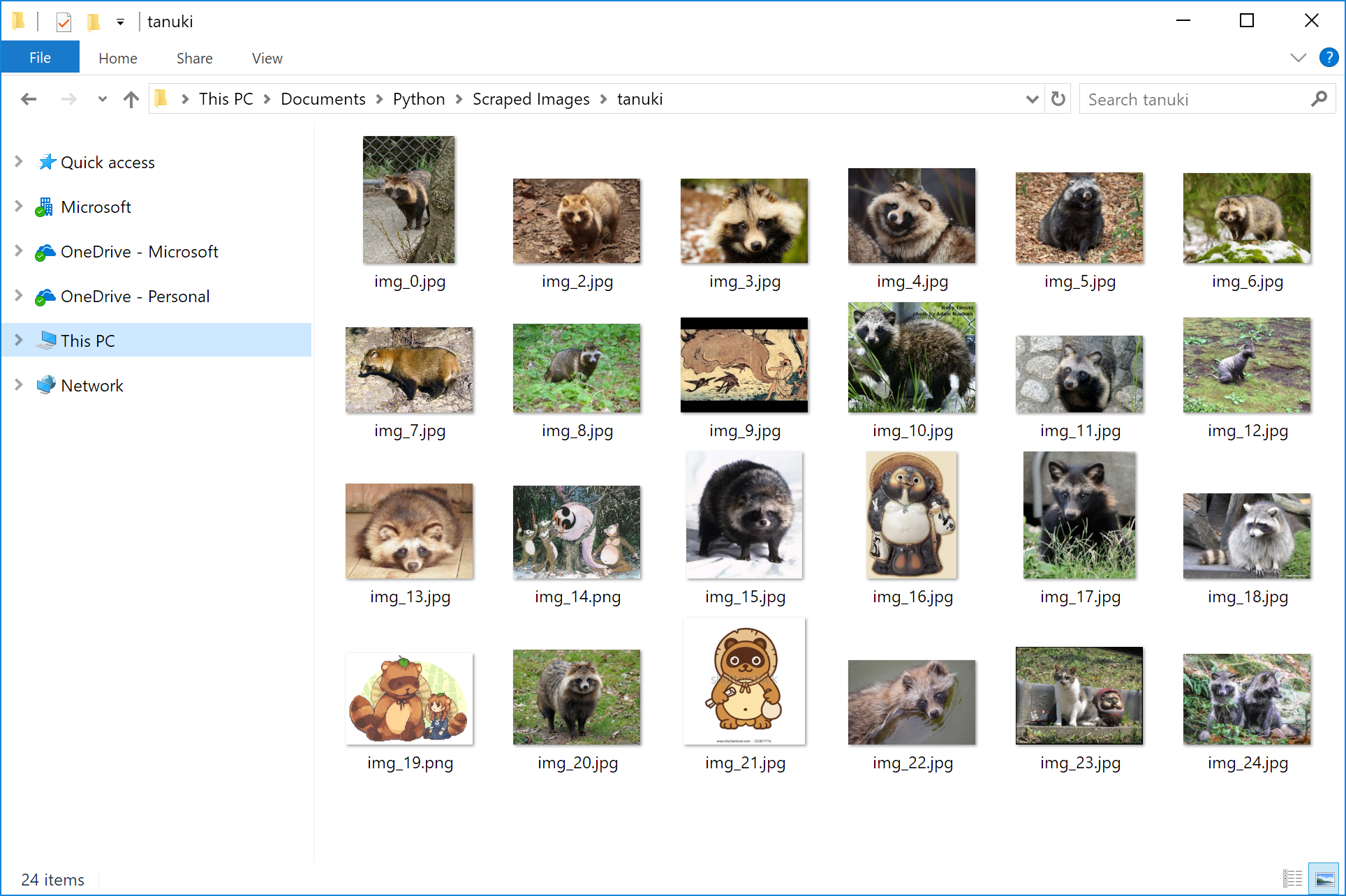
ちゃんと「tanuki」のフォルダーに画像がダウンロードされました。
因みにこちらが同じキーワードをGoogle画像検索にかけた結果です: