どんなツール?
IT専門用語を含む文章を、相手に最適な表現に変換するツールです。
やることはシンプルです。
- 変換したい文章を入力
- 対象(エンジニア / 非エンジニア / 経営層)とトーン(フォーマル / カジュアル)を選ぶ
- 実行ボタンを押す
これだけで、対象に合わせた表現へ変換します。
イメージ:経営層向けの変換
-
入力
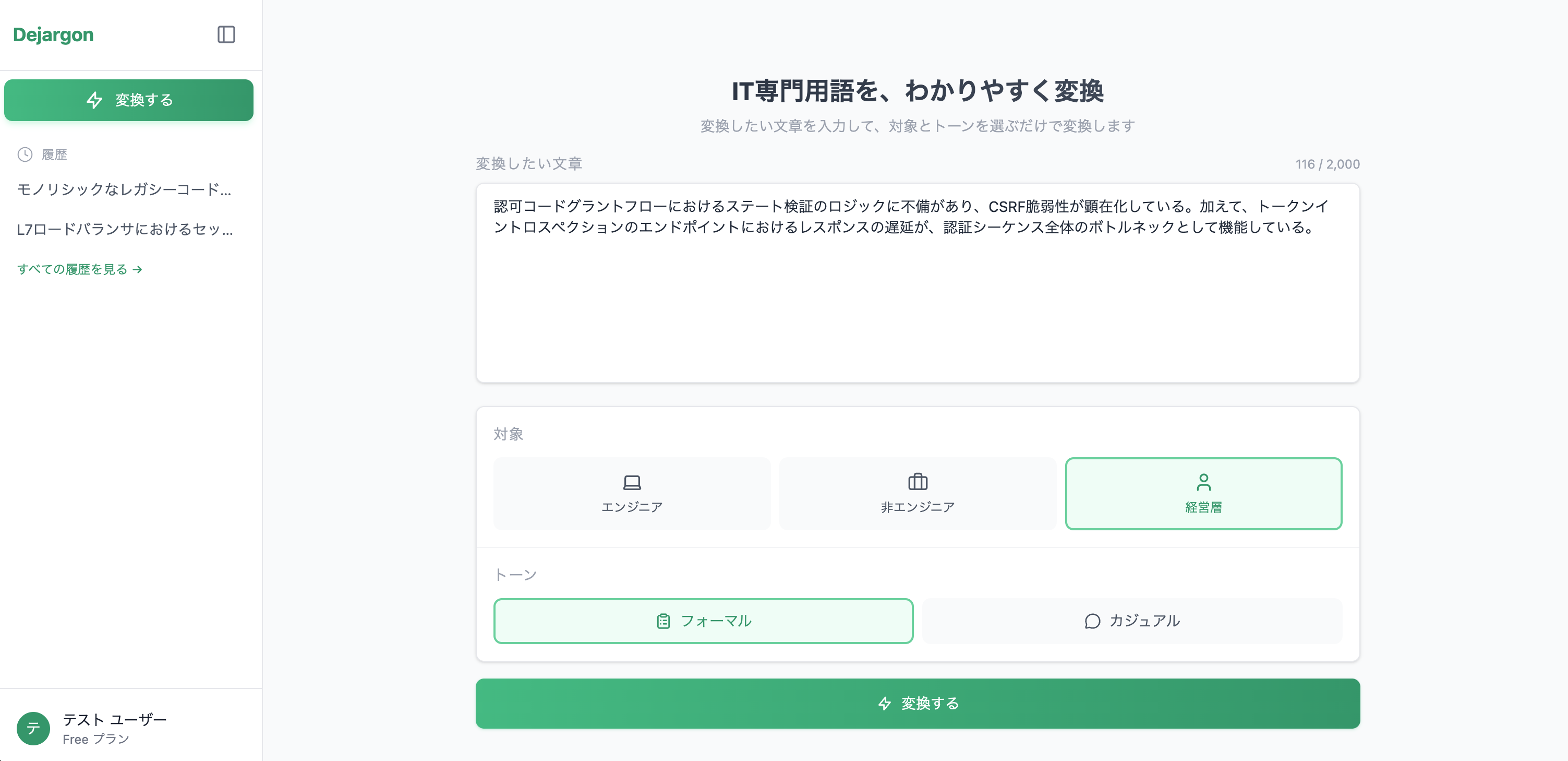
-
変換結果
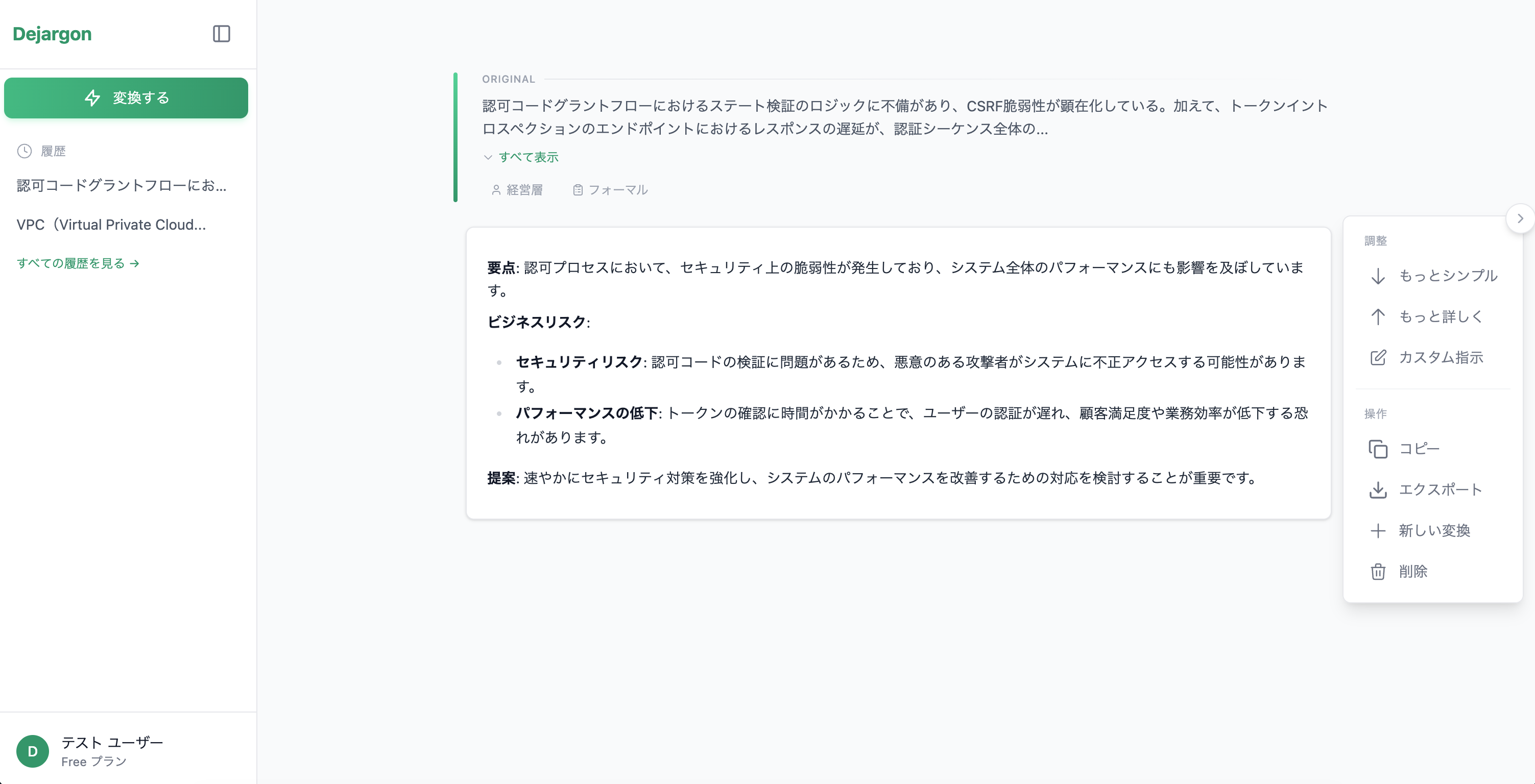
技術詳細は省略し、ビジネスインパクト・リスクを中心に変換しています。
なぜ、このツールを作ったのか?
普段、次の課題に直面することがよくありました。
1. その分野に詳しくない人(新人や非エンジニア、経営層など)に技術的な説明をするとき
- わかりやすい言葉が出てこない
- 専門用語をどう言い換えるか悩む
- 言い換えを考えるのに時間がかかってしまう
2. 技術資料やドキュメントを読むとき、または、他者からの説明を受けるとき
- 専門用語が多くて理解できない
- もっと噛み砕いて知りたい
- 用語を一つずつ調べるのは面倒で時間がかかる
こういったケースにおいて専門用語が障壁になることが多く、都度、変換の手間が発生していました。この変換の手間を減らしたく、今回のツールを作りました。
ChatGPTに聞けばいい?
もちろんChatGPTに「この用語を非エンジニアにもわかるように説明して」と聞けば答えてくれます。
でも、毎回プロンプトを書くのが面倒なのと、相手によって説明の粒度も変わるので、そのたびにプロンプトを調整するのは地味にストレスです。
それに、変換結果の管理が難しい点もあります。
使い切りであれば問題にはならないですが、何度も同じような変換をしたり、ドキュメントとしてストックしておきたい場合、会話の中に埋もれてしまうので、管理コストが高くつきます。
オリジナルのドキュメントは専門的なまま残しつつ、読者に合わせてわかりやすく言い換えた版をストックしておけたらいいなと思いました。
技術スタック
個人開発であること、まずは最小構成で様子見したいという背景から、低コスト、スモールスタート を重視しました。
今回はCloudflareで統一しています。
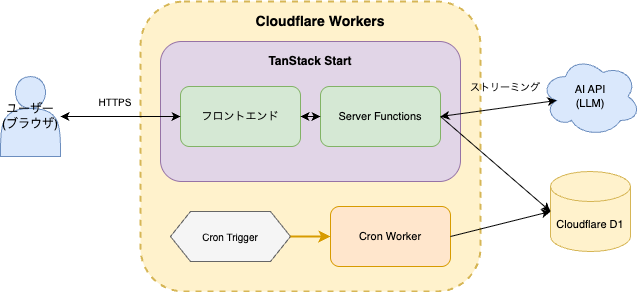
| レイヤー | 技術 |
|---|---|
| 言語 | TypeScript |
| フロントエンド | TanStack Start |
| バックエンド | TanStack Start Server Functions |
| データベース | Cloudflare D1 + Drizzle |
| ホスティング | Cloudflare Workers |
| 定期処理 | Workers Cron Triggers |
低コスト:Cloudflareの無料枠
Cloudflareの無料枠が充実しているため、個人開発の規模であればほぼ無料で運用できます。
また、AIによる変換が本ツールのコアであるため、モデルのAPI利用料には投資し、その分、インフラコストを抑えたいといった背景もありました。
| サービス | 無料枠 |
|---|---|
| Workers | 1日10万リクエスト |
| D1 | 5GBストレージ、500万行読み取り/日 |
現時点でのランニングコストは、AIモデルのAPI利用料のみであり、しばらくはインフラ費用も無料枠内に収まる想定です。
スモールスタート:TanStack Start + Cloudflare Workers
個人開発では「完璧を目指して作り込む → 途中で疲弊する → (永遠に)リリースできない」というパターンがよくあると思います。
まずは最小限の構成で素早くリリースし、その後、必要な機能を追加していくアプローチを取ることに決めました。
これを実現するために、TanStack Start + Cloudflare Workersを採用しました。
TanStack Start
TanStack Startは、React向けのフルスタックフレームワークで、「型安全」を重視した設計が特徴です。
今回は特に次の点が要件に合致しました。
- フロントエンドとバックエンドを分けずにミニマムな構成にできる
- TanStack Server Functionsは、RPCライクに書ける
- gRPCのように
.protoを書いてコード生成する必要がない - REST APIのようにエンドポイントを設計する必要がない
- gRPCのように
- フロントエンドからバックエンドの関数を直接呼び出せる
- それぞれを起動したり、繋ぎ込む必要がない
- AIコーディングエージェントとの相性が良い
- 型注釈を明示的に書かなくても、サーバ側の入出力の型が自動で推論される
- 型情報があるとAIがコードの意図を理解しやすく、AIが生成したコードに誤りがあっても型エラーで検出できる
// サーバー側
export const getUser = createServerFn({ method: "GET" })
.validator((data) => userSchema.parse(data))
.handler(async ({ data }) => {
return await db.query.users.findFirst({ where: eq(users.id, data.id) });
});
// クライアント側(型が自動で付く)
const user = await getUser({ data: { id: "123" } });
console.log(user.name); // 型補完が効く
この構成はServer Functionsを直接呼び出す形になるため、フロントとバックエンドが密結合になります。ただし、個人開発なのでチーム分割やスケールの問題は一旦許容にし、スピーディーなリリースを目指しました。
ただし、ビジネスロジックやリポジトリ層などはパッケージとして切り出し、将来的にバックエンドを分離する際も移行しやすい構成にしています。
軽量DB:Cloudflare D1 + Drizzle
Cloudflare D1
Cloudflare D1は、Cloudflareが提供するサーバーレスSQLiteデータベースです。
今回は特に次の点が要件に合致しました。
- 先に述べたように低コストであること
- PostgreSQLやMySQLではなくSQLiteにした理由は、ツールの特性上、複雑または高度なDB構成やクエリ機能は必要ないため、オーバースペックなDBを選んで運用コストを上げる理由がなかった
- Cloudflare Workersとの親和性。DB接続に伴う認証やネットワーク設定などのインフラ層の複雑さはなく、コンフィグ数行で完結します。(参考:Bind your Worker to your D1 database)
Drizzle
ORMはDrizzleを選びました。Node.js/TypeScriptで使えるORMはいくつかありますが、Cloudflare Workers + D1という環境では選択肢が限られます。
今回は特に次の点が要件に合致しました。
- D1ネイティブサポート。追加設定なしでD1と接続できる
- 軽量。バンドルサイズが小さい
- SQLライクな書き方。SQLを知っていれば学習コストが低い
- TypeScriptで書ける。スキーマを定義し、それをそのまま型として使える
// スキーマ定義
export const users = sqliteTable("users", {
id: text("id").primaryKey(),
name: text("name").notNull(),
});
// クエリ(型が自動で付く)
const users = await db.query.users.findFirst({
where: eq(users.id, id),
});
console.log(users.name); // 型補完が効く
ストリーミング:Server Functionsの非同期ジェネレーター
AI変換の結果はストリーミングでリアルタイム表示しています。ChatGPTのように、文字が順次表示されるUXです。
Server Functionsの非同期ジェネレーターを使いストリーミングを実現します。
// サーバー側
export const convertStream = createServerFn({ method: "POST" })
.handler(async function* ({ data }) {
const stream = await llm.streamConvert(data.input, data.targetLevel);
for await (const chunk of stream) {
yield { content: chunk };
}
});
// クライアント側
for await (const chunk of await convertStream({ data: { input, targetLevel } })) {
setOutput((prev) => prev + chunk.content); // リアルタイムで追記
}
非同期ジェネレーター以外にも選択肢はありますが、今回は実装のシンプルさを優先し、こちらを採用しました。(参考:Streaming Data from Server Functions)
定期処理:Cron Triggers
Cloudflare WorkersにはCron Triggersという機能があり、定期的なバッチ処理を実行できます。
このツールでも、いくつかの用途があるため使っています。
wrangler.toml(設定ファイル)でスケジュールを定義します。
# apps/cron/wrangler.toml
name = "cron"
main = "src/index.ts"
[triggers]
crons = ["0 16 * * *"] # 毎日 UTC 16:00(JST 1:00)に実行
ワーカーのエントリポイントでscheduled関数をエクスポートします。
// apps/cron/src/index.ts
export default {
async scheduled(
_controller: ScheduledController,
env: Env,
ctx: ExecutionContext,
): Promise<void> {
ctx.waitUntil(
(async () => {
await cleanup();
})(),
);
},
};
Cloudflare Workersで完結できるのが良いところです。
ビルド&デプロイ:Workers Buildsでマネージドに自動化
デプロイはCloudflareのWorkers Buildsを使っています。(参考:Workers Builds)
GitHub Actionsなどのワークフローを自前で実装する必要がなく、GitHubリポジトリと連携して、pushするだけで自動デプロイされます。
プレビュー環境も自動で作られるので、PRごとに動作確認できるのも便利です。
最後に
記事を読んでいただき、ありがとうございます。
まだ最小限の機能しかないので、今後も新しい機能を順次追加予定です。
もし冒頭で述べたような課題に共感いただけたり、興味があれば、ぜひ一度使ってみてください。
フィードバックや機能リクエストもぜひ、お待ちしております。