※この記事は前回の記事を前提としている部分が多々ありますのでご注意ください(なるべくそのたびに前回の記事のリンクを出すようにはしています)
はじめに
今回も国民的アニメ「サザエさん」のエンディングのじゃんけんの予測に挑戦しますが、今回はScikit-learnではなく深層学習(?)を用いてやっていきたいと思います(前回のSckit-learn編はこちらです)。前回も書きましたが僕はまだ趣味でプログラミングを数年しただけなので、分かり辛いところもあると思いますがよろしくお願いします。(間違いなどありましたらコメント欄等で教えていただけるとありがたいです)
また、前回の記事で「pd.shift()を使ったらどうだ」などのコメントを頂いたので、前回のソースも空いた時間に改良していきます。完成したら更新しますので、そちらの方もよろしくお願いします。
使用したツール
前回と同じです。
・GoogleColaboratory
・Googleスプレッドシート*
・メモ帳(アプリケーション)*
*がついているものは前回の記事でのデータの加工に使用したため今回は必要ないと思われます。
前回の記事をまだご覧になってない方はこちらの記事の1-1「データの入手」と1-2「データの加工」、そして1-3「ダウンロード」を参照してください。(同じ内容のものをこの記事の一番最後に載せておきますのでそちらをご覧になっても構いませんが、上のリンクの前回の記事を見ていただいたほうが分かりやすいと思います)
予測方法
前回と基本は同じで、サザエさんが出す手はその放送回の2回前と関係があるという情報を入手しているので、1~4回前の手の出方のデータを入力層、グー・チョキ・パーどの手を次回出すかの予測結果を出力層として深層学習を行いたいと思います。(僕はまだ機械学習の経験が浅く、これから書いていくソースが深層学習と呼べるものなのかはよくわかりませんが、よろしくお願いします)
手順
1-1データの入手&1-2データの加工&1-3ダウンロード
先程も書いたように、前回の記事の1-1「データの入手」と1-2「データの加工」と1-3「ダウンロード」かこの記事の「補足」の部分を参照してください。
2コーディング
ここあたりも説明はだいたい前回と同じです。
まずはGoogleColaboratoryにアクセスし、「ファイル」→「Python3の新しいノートブック」を選択し、新規ipynbファイルを作成します。作成したら、右上にある「接続」ボタンをクリックし緑の✔マークになるまで待ちます。さらに、「編集」→「ノートブックの設定」で「ハードウェアアクセラレータ」が「None」になっていると思うので、「GPU」に切り替えます。(エポック数は10回程度な上、画像処理をするわけではないので必要ないとは思いますが...)続いて、左上の「>」ボタン(?)をクリックし、「ファイル」→「アップロード」を押すとファイル選択ダイアログが出ると思うので、先程ダウンロードした「サザエさん予測.csv」を選択しアップロードします。これでコードを書く準備が整いました。「挿入」→「コードセル」から新規コードセルを追加して、以下のソースコードをそのセルの中に入力します。
# import文
import keras as keras
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow.contrib.keras as keras
from sklearn.model_selection import train_test_split
from keras.layers import Dropout,Dense
from keras.models import Sequential
# csvファイルの読み込み
csv = pd.read_csv("サザエさん予測.csv",encoding="utf-8")
y_labels = csv.loc[:,"今回"]
x_data = csv.loc[:,["4回前","3回前","2回前","1回前"]]
# one-hotベクトルに直して、予測用・学習用データを作ります。
labels = {
0: [1,0,0],
2: [0,1,0],
5: [0,0,1]
}
y_nums = np.array(list(map(lambda v : labels[v] , y_labels)))
x_data = np.array(x_data)
x_train,x_test,y_train,y_test = train_test_split(x_data,y_nums,train_size = 0.8)
# モデル構築&コンパイル
model = Sequential()
model.add(Dense(10,activation='relu',input_shape=(4,)))
model.add(Dense(3,activation='softmax'))
model.add(Dropout(0.2))
model.add(Dense(3,activation='softmax'))
model.add(Dropout(0.2))
model.add(Dense(3,activation='softmax'))
model.add(Dropout(0.2))
model.add(Dense(3,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
# 学習&テスト
model.fit(x_train,y_train,batch_size=20,epochs=10)
score = model.evaluate(x_test,y_test,verbose=1)
print("acc=",score[1],"loss=",score[0])
# 実際の予測。realに過去の4回のデータを入れて、yにグーの[1,0,0]、チョキの[0,1,0]、パーの[0,0,1]を順番に入れ、予測結果とyが合致(=正解率1.0)した際のyの値を予測結果とする
real = [0,5,2,5]
y = [0,0,1]
real = np.array(real)
y = np.array(y)
real = np.reshape(real,(1,4))
y = np.reshape(y,(1,3))
score2 = model.predict_classes(real)
print(score2[0])
上のソースコードに一つだけ大問題があるのですが、学習したはいいのですがそこから実際の予測に仕方がわからず最後のコメント以降のソースがひどいことになっています(汗)。
誰か優しい方がいらっしゃったら僕に実際の予測をするソースや方法を教えて下さい。よろしくお願いします。また、今回が初めての深層学習なので、参考書のソースコードをかなりパクってしまいました。これからはもう少しまともな実際の予測方法と、この案件により合う深層学習の仕方が研究課題ですね...
まとめ
今回は深層学習を使用してサザエさんのじゃんけんの予測に挑戦しましたが、ぶっちゃけ前回のScikt-learn編のほうがうまくいきましたし、実用性も高いと思いましたが、今後僕がもう少しプログラミングのスキルを向上させればだいぶ便利になるのでは...と思いました。
参考にしたもの
サザエさんじゃんけん研究所公式ウェブサイト
すぐに使える! 業務で実践できる! Pythonによる AI・機械学習・深層学習アプリのつくり方
追記-前回の記事(一部抜粋)
完全に載せ忘れてました。すいません
1-1 データの入手
まずはここからサザエさんのじゃんけんの過去のデータを入手します。ここには1991年の最初の回以降の全ての放送回のじゃんけんのデータが公開されています。
本来は1年分ずつメモ帳にコピペして検索と置換を使ってカンマ区切りファイル(csvファイル)を作っていくのですが、30分くらいかかってしまうのでこの記事を書いている今日(2019年5月23日)時点までの過去のじゃんけんのデータをここに公開しておきます。(この記事ではこのデータを共有用スプレッドシートと呼びます)スプレッドシート形式なのでマイドライブに新規スプレッドシートを作成し、コピペして使ってください。
1-2 データの加工
データの加工と言っても大したことはしません。みなさんがこの記事を読んでいるときには、先程コピペしたスプレッドシートのデータはもう最新ではないので、新たにデータを追加してもらいます。
大体は共有用スプレッドシートのデータの形式を見ていただければわかりますが、一応それぞれの列の意味を説明します。
A列、B列
その放送が何回目かを表します。(1386回から最新回の番号になるまで放送回の番号を入れていってください。最新回が何回目かはここの一番最新の年を選択し、一番下の第☓☓☓☓回 ☓☓年☓月☓☓日の部分を見ていただければわかります)
G列
その回にサザエさんがどの手を出したかを表します。(この記事ではグーを0、チョキを2、パーを5として扱います)
F列
その回の1回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、1つ上の行のG列と同じ数値なのがわかると思います)
E列
その回の2回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、2つ上の行のG列と同じ数値なのがわかると思います)
D列
その回の3回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、3つ上の行のG列と同じ数値なのがわかると思います)
C列
その回の4回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、4つ上の行のG列と同じ数値なのがわかると思います)
例
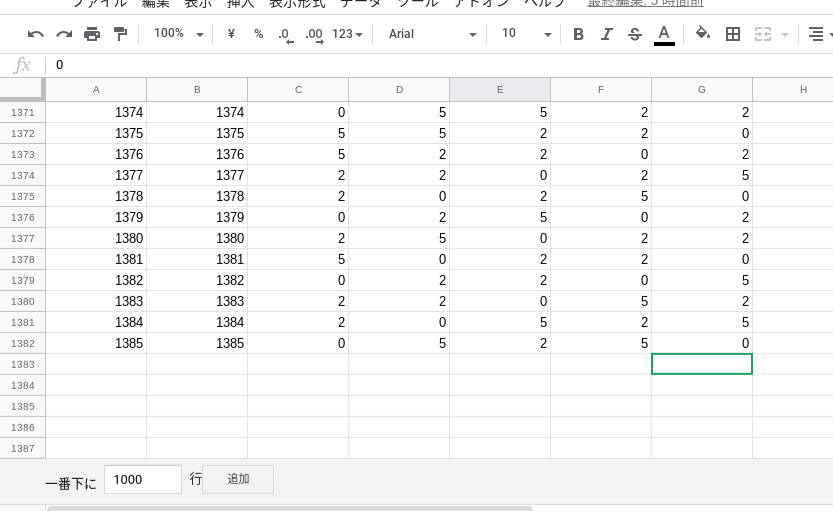
1390回が最新回の場合は、このように加工することになります。この記事を書いている時点でまだ不明なデータはアルファベットで書いてあります。
before
after
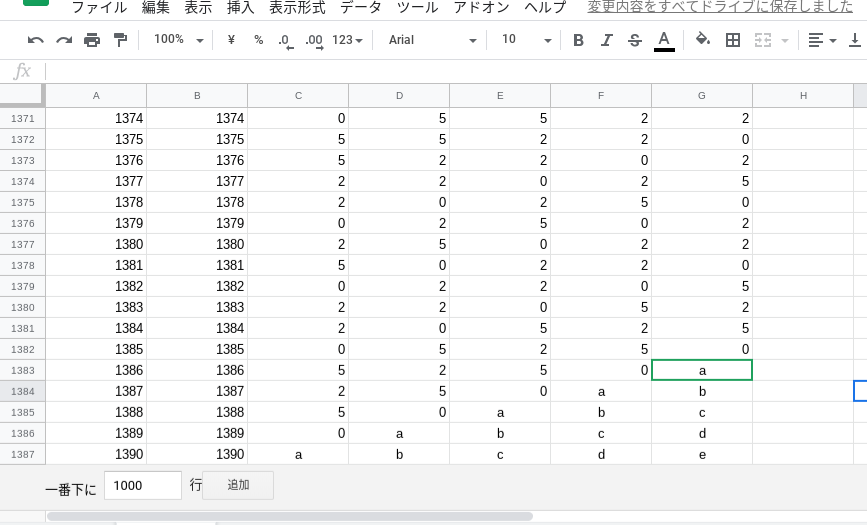
1-3 ダウンロード
完成したら「ファイル」→「形式を指定してダウンロード」→「カンマ区切りの値(csv,現在のシート)」
でダウンロードして、「サザエさん予測データ」というファイル名に名前を変更しておいてください。