はじめに
今回は国民的アニメ「サザエさん」のエンディングのじゃんけんの予測に挑戦しました。僕はまだ趣味でプログラミングを数年しただけなので、分かり辛いところもあると思いますがよろしくお願いします。
使用したツール
・GoogleColaboratory
・Googleスプレッドシート
・メモ帳(アプリケーション)
予測方法
サザエさんのじゃんけんの手は過去2回に関係があるという情報があったので今回は過去4回のデータから次の手の予測を試みます。回帰分析や深層学習については別の記事で行う予定です。
手順
1-1 データの入手
まずはここからサザエさんのじゃんけんの過去のデータを入手します。ここには1991年の最初の回以降の全ての放送回のじゃんけんのデータが公開されています。
本来は1年分ずつメモ帳にコピペして検索と置換を使ってカンマ区切りファイル(csvファイル)を作っていくのですが、30分くらいかかってしまうのでこの記事を書いている今日(2019年5月23日)時点までの過去のじゃんけんのデータをここに公開しておきます。(この記事ではこのデータを共有用スプレッドシートと呼びます)スプレッドシート形式なのでマイドライブに新規スプレッドシートを作成し、コピペして使ってください。
1-2 データの加工
データの加工と言っても大したことはしません。みなさんがこの記事を読んでいるときには、先程コピペしたスプレッドシートのデータはもう最新ではないので、新たにデータを追加してもらいます。
大体は共有用スプレッドシートのデータの形式を見ていただければわかりますが、一応それぞれの列の意味を説明します。
A列、B列
その放送が何回目かを表します。(1386回から最新回の番号になるまで放送回の番号を入れていってください。最新回が何回目かはここの一番最新の年を選択し、一番下の第☓☓☓☓回 ☓☓年☓月☓☓日の部分を見ていただければわかります)
G列
その回にサザエさんがどの手を出したかを表します。(この記事ではグーを0、チョキを2、パーを5として扱います)
F列
その回の1回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、1つ上の行のG列と同じ数値なのがわかると思います)
E列
その回の2回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、2つ上の行のG列と同じ数値なのがわかると思います)
D列
その回の3回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、3つ上の行のG列と同じ数値なのがわかると思います)
C列
その回の4回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、4つ上の行のG列と同じ数値なのがわかると思います)
例
1390回が最新回の場合は、このように加工することになります。この記事を書いている時点でまだ不明なデータはアルファベットで書いてあります。
before
after
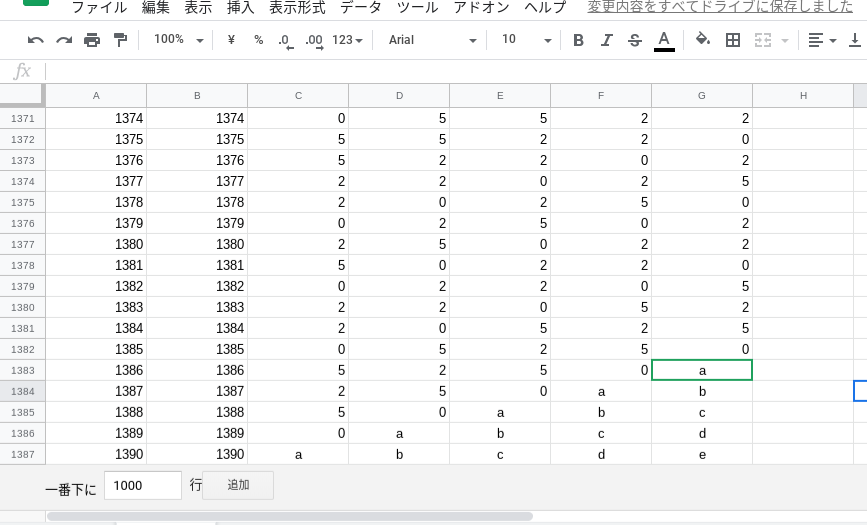
1-3 ダウンロード
完成したら「ファイル」→「形式を指定してダウンロード」→「カンマ区切りの値(csv,現在のシート)」
でダウンロードして、「サザエさん予測データ」というファイル名に名前を変更しておいてください。
2 コーディング
ここまで来たらソースコードを書いていきます。
まずはGoogleColaboratoryにアクセスし、「ファイル」→「Python3の新しいノートブック」を選択し、新規ipynbファイルを作成します。
作成したら、右上にある「接続」ボタンをクリックし緑の✔マークになるまで待ちます。
続いて、左上の「>」ボタン(?)をクリックし、「ファイル」→「アップロード」を押すとファイル選択ダイアログが出ると思うので、先程ダウンロードした「サザエさん予測.csv」を選択しアップロードします。これでコードを書く準備が整いました。「挿入」→「コードセル」から新規コードセルを追加して、以下のソースコードをそのセルの中に入力します。
# import文。今回は必要ないものも入っています。
import pandas as pd
import numpy as np
import warnings
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.utils.testing import all_estimators
from sklearn.externals import joblib
# pandasのread_csv()で事前にアップロードしたcsvを読み込む。
csv = pd.read_csv("サザエさん予測.csv",encoding="utf-8",dtype={'4回前':np.float64, '3回前':np.float64, '2回前':np.float64, '1回前':np.float64, '今回':np.float64})
y = csv.loc[:,"今回"]
x = csv.loc[:,["4回前","3回前","2回前","1回前"]]
# 結果を保存する配列を定義
predicted = []
warnings.filterwarnings('ignore')
# じゃんけんの予測はランダム性が高いので100回予測して最も予測された回数が高かったものを答えとします。
for i in range (100):
#学習用データとテスト用データに分ける
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.1,train_size=0.9,shuffle=True)
clf = RandomForestClassifier()
#学習
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
#この下に予測する回の過去4回の結果を打ち込みます。小数点1ケタまでなので注意
real = [5.0,2.0,5.0,0.0]
real = np.reshape(real,(1,4))
#予測
real_pre = clf.predict(real)
predicted.append(real_pre[0])
# それぞれの手が予測された回数をカウント
rock = 0
tyoki = 0
paper = 0
for i in range(100):
if predicted[i] == 0:
rock = rock + 1
if predicted[i] == 2:
tyoki = tyoki + 1
if predicted[i] == 5:
paper = paper + 1
print("サザエさんが出す手を予測します")
print("確率はグーが",rock,"%,チョキが",tyoki,"%,パーが",paper,"%です")
書き終わったらそのセルの左上にある再生ボタンのようなものをクリックして実行してみてください。
サザエさんが出すであろう手の確率が表示されるはずです。
出力例
サザエさんが出す手を予測します
確率はグーが 23 %,チョキが 56 %,パーが 21 %です
train_test_split()を使用しているため毎回結果は変わりますが、だいたい50%で出す手が的中し、この結果をもとに出す手を考えると勝率は70~90%程度になり、負けはほぼ無くなるはずです。(もちろん出す人の運にもよりますが)
まとめ
今回はsckit-learnのRandomForestClassifier()を使ってサザエさんのじゃんけんを予測してみました。確率論で考えるとじゃんけんで勝てる確率は33%なので、今回の結果には僕はまあまあ満足しています。
参考にしたサイト
コメントへの返答
何件かコメントをいただいたため、ここで返答させて頂きます。
・pd.shift()を使ったらどうか、one-hotベクトルにはしないのか→修正中です。ただone-hotベクトルについては深層学習ではないのであまり意味はないと考えます。
・testデータでの予測精度は確認しないのか→裏で確認しています。大体50%程度です。