はじめに
例えば、、、、
最初は小さいシステムだったので、一つのテーブルに色んな情報を保持していました。
その後、そのシステムには複数回のバージョンアップが行われ、複雑な業務を行えるシステムに進化したとします。
そのアカウント情報管理テーブルが以下だったとします。
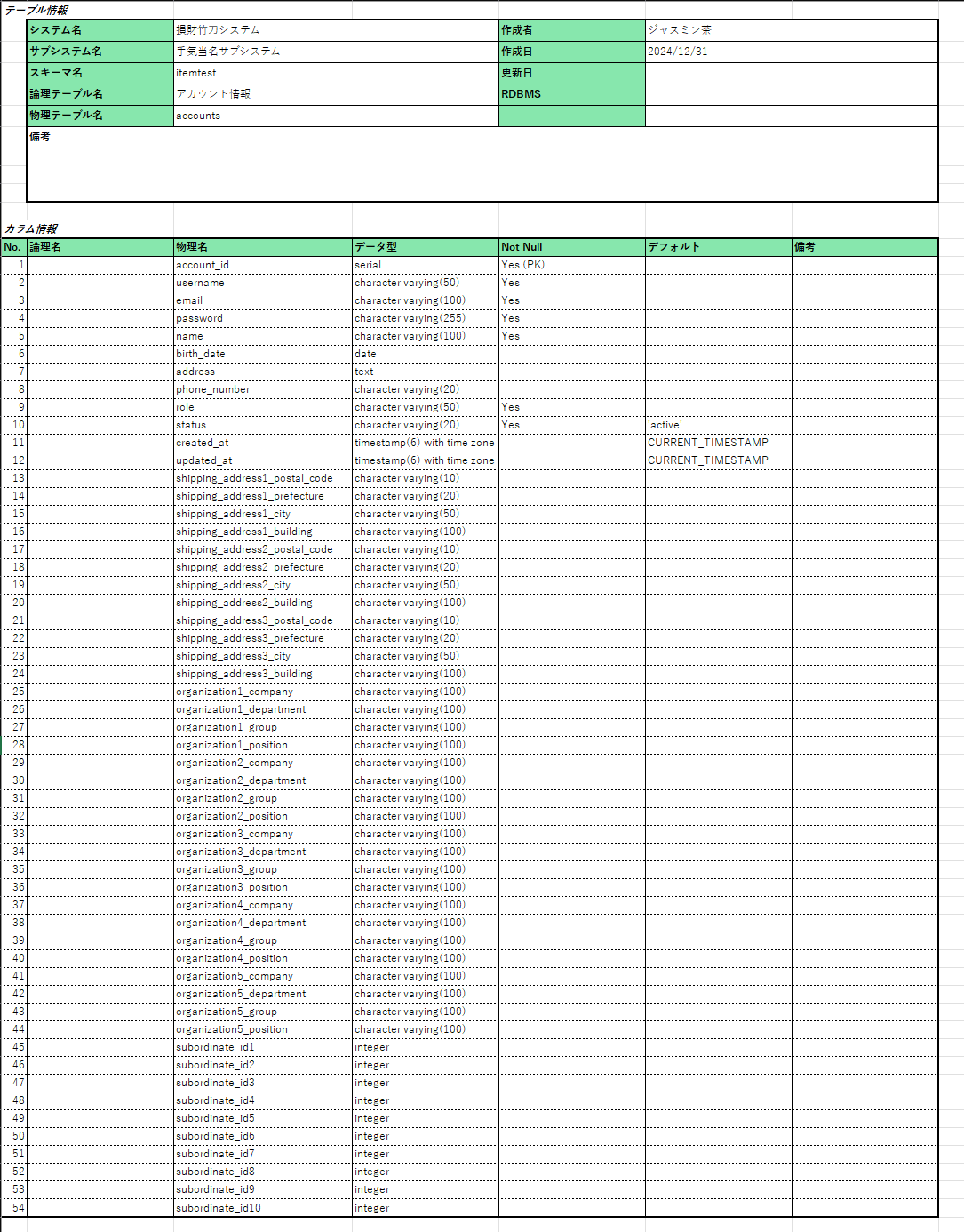
もう少しわかりやすいように、DDLも張っておきます。
CREATE TABLE accounts (
account_id SERIAL PRIMARY KEY, -- PostgreSQLではSERIALを使用
username VARCHAR(50) NOT NULL UNIQUE,
email VARCHAR(100) NOT NULL UNIQUE,
password VARCHAR(255) NOT NULL,
name VARCHAR(100) NOT NULL,
birth_date DATE,
address TEXT,
phone_number VARCHAR(20),
role VARCHAR(50) NOT NULL, -- 権限
status VARCHAR(20) NOT NULL DEFAULT 'active', -- 状態
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
-- 発送先情報1
shipping_address1_postal_code VARCHAR(10),
shipping_address1_prefecture VARCHAR(20),
shipping_address1_city VARCHAR(50),
shipping_address1_building VARCHAR(100),
-- 発送先情報2
shipping_address2_postal_code VARCHAR(10),
shipping_address2_prefecture VARCHAR(20),
shipping_address2_city VARCHAR(50),
shipping_address2_building VARCHAR(100),
-- 発送先情報3
shipping_address3_postal_code VARCHAR(10),
shipping_address3_prefecture VARCHAR(20),
shipping_address3_city VARCHAR(50),
shipping_address3_building VARCHAR(100),
-- 組織情報1
organization1_company VARCHAR(100),
organization1_department VARCHAR(100),
organization1_group VARCHAR(100),
organization1_position VARCHAR(100),
-- 組織情報2
organization2_company VARCHAR(100),
organization2_department VARCHAR(100),
organization2_group VARCHAR(100),
organization2_position VARCHAR(100),
-- 組織情報3
organization3_company VARCHAR(100),
organization3_department VARCHAR(100),
organization3_group VARCHAR(100),
organization3_position VARCHAR(100),
-- 組織情報4
organization4_company VARCHAR(100),
organization4_department VARCHAR(100),
organization4_group VARCHAR(100),
organization4_position VARCHAR(100),
-- 組織情報5
organization5_company VARCHAR(100),
organization5_department VARCHAR(100),
organization5_group VARCHAR(100),
organization5_position VARCHAR(100),
-- 部下アカウントID
subordinate_id1 INT,
subordinate_id2 INT,
subordinate_id3 INT,
subordinate_id4 INT,
subordinate_id5 INT,
subordinate_id6 INT,
subordinate_id7 INT,
subordinate_id8 INT,
subordinate_id9 INT,
subordinate_id10 INT
);
カオスですね。
ただ、この程度であれば、手動で正規化できますが、今回は生成AIに正規化の提案をしてもらおうと思います。
テーブル設計書
テーブル設計書はA5:SQL Mk-2で作成しています。
手順が以下の方がわかりやすく説明してくださっています。
検証環境情報
・DB:PostgreSQL
・生成AIモデル:Gemini(1.5 Flash)
やってみよう
テーブル設計書(Excel)をインプットにしてみる
新たなツールの導入も許可されない、ただし生成AIに設計書を読み込ませることは許可がでた場合(知らんけど)、
Excelからテーブルの構造を生成AIに理解してもらい、テーブルの正規化を行ってもらいましょう。
geminiはExcelが未対応でした。
テーブル設計書(画像)をインプットにしてみる
執筆時点、画像なら大体の生成AIが対応していっているので、力技ですが、
テーブル設計書をキャプチャして読み込ませてみます。
読み込ませたキャプチャは、上記で張ったものと同じです。
何度か同じ質問をしてみたんですが、その時により回答が異なります。
テーブル構造の問題点を列挙してくれたり、正規化の必要性を問うてくれる時もあります。
ER図


geminiはER図未対応でした。
DDL
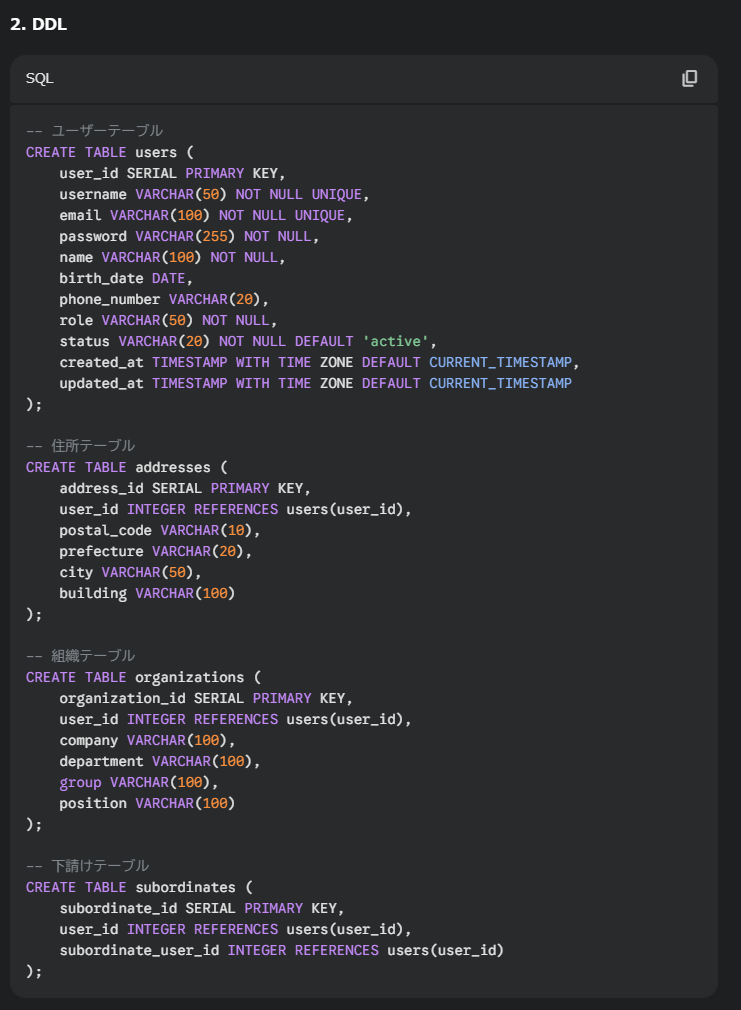
「account_id」だったキーが「user_id」に変更されています。これは既存システムへの影響が大きそうなので、やめてほしいと思いました。
テーブル名については、移行時に新旧テーブルを同居させることでデータ送信しやすい設計にしたのでしょうか・・
あと部下を勝手に下請けにしないでください・・
また今回はポスグレで検証を行ったんですが、「group」が予約語で使用できませんでした。(あれじゃあ何で登録できたんだ?)
ただ、これはDB情報を渡さなかった私が悪いので、見逃します。
テーブル設計書
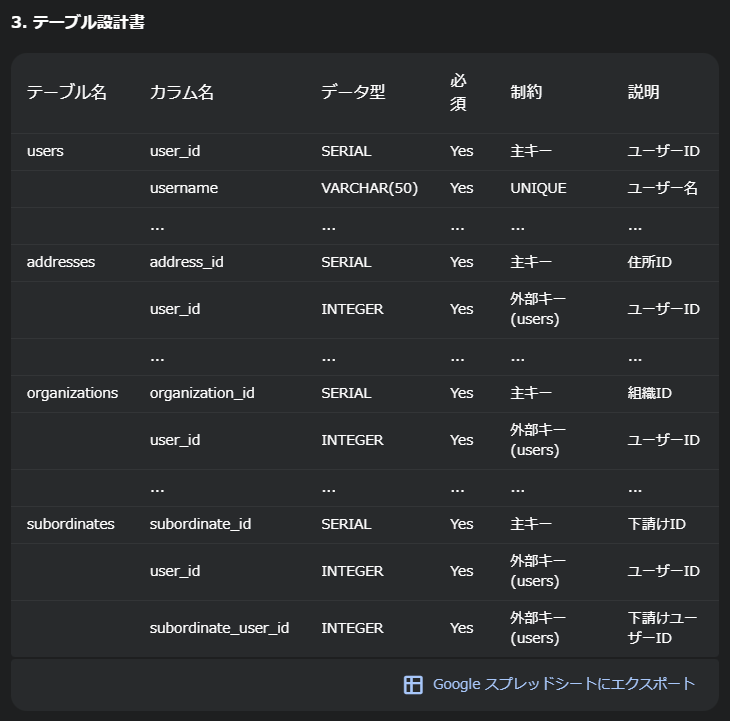
何度かやってみたんですが、たまに省略されてしまいます。
DDLをインプットにしてみる
今回は稼働中の既存システムを想定いており、さらにDDLが存在しないという現場だとして、
A5ツールでDDLを出力させて、それをインプットとしたいと思います。
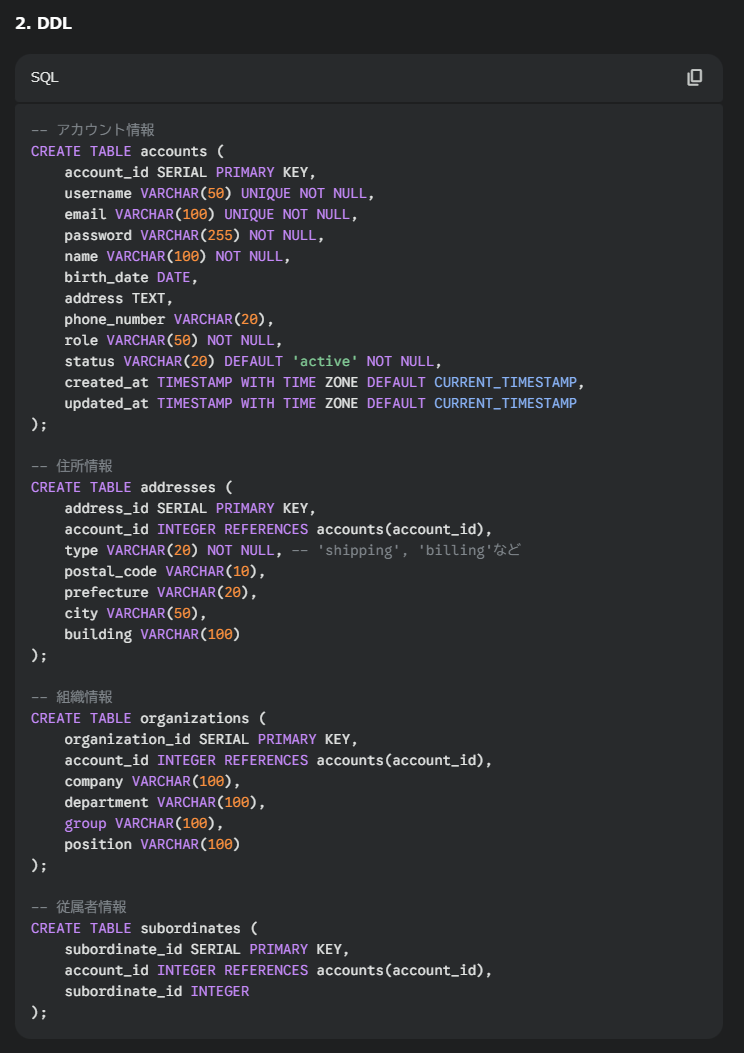
画像を読み込ませたときと大枠同じですが、テーブル名をオリジナルのままにしてくれたり、
従属者情報としてくれたりしましたが、大枠画像と同じ出力でした。
画像解析能力の高さがうかがえますね。
まとめ
ここには記載していない細かい気になる点があったのですが、
そこは手で修正すればいいので、おおわくは良しとします。
一から手直しするより正規化を理解したたたき台が作成できるので、よかったのではないでしょうか。
余談
基のテーブルのDDLもGeminiを使って作成しました。
冗長構造の情報を五月雨に追加してもらっていましたが、
この超冗長化構造を受け入れてもらえず、何度も説得しましたが、追加してくれませんでした。
最終的には、新規チャットを作成して、追加後のDDLに対して「この情報を追加してください」と都度依頼して追加してもらいました。(手で追加した方が早かったかも)
