TL;DR
- 運用 / システムエンジニアとして長く働いてきた身が、AI 協業をきっかけにソフトウェア開発の領域へ踏み込んだ最初の案件記録です。
- ドメイン特化の Entity Resolution(同一実体の突合)ツールを、夜の数セッションだけ Claude Code と組んで作りました。
- 過去 10 週間の実データに対してリプレイしたところ、人間が検出した突合エラーの 約 99.2% を機械が再現できました。
- ベテラン依存の週次タスクが、誰でも実行できる作業に変わりました。
- 設計を後から振り返ると、二重過程理論やゲシュタルト心理学、アンカリングバイアス対策といった原則に偶然 retrofit していました。
- 業務データそのものは一切 LLM に渡していません。決定論的なパイプライン + 人間レビューだけで完結しています。
- 【5/8追記】本ツールの要点をざっくり要約すると、項目ごとにスコアを付けて、総合スコアでマッチングを仮決め、その後で差分を確認する 3 段ロジックです。
1. 隠れていた本当の問題 — 500 × 500 が認知の壁になる
多くの企業は、同じ業務エンティティを複数のシステムに分けて持っています。
- 小売業者が、自社マスタと Amazon / 楽天 / Shopify の出品 export の両方で SKU を管理している
- クリニックが、電子カルテとレセプトシステムの両方で患者情報を持っている
- 製造業が、自社在庫と取引先からの在庫フィードを並列で受けている
- 経理チームが、総勘定元帳と銀行明細を月次で突き合わせている
これらは定期的な突合(reconciliation)が必要になります。技術文献では Entity Resolution や Data Reconciliation と呼ばれている領域で、中規模以上の企業ならどこかで必ずぶつかる普遍的な課題だと思います。本稿では、この同一実体の突合処理を 「名寄せ (Entity Resolution)」 と呼びます。以降、用語が「名寄せ」「突合」「Entity Resolution」のあいだを揺れることがありますが、すべて同じ作業を指していると読んでください。
本記事では 小売の SKU と外部マーケットプレイス出品の突合 という framing で書きます(実際の業界は意図的に抽象化しています。構造はそのまま転用できます)。2 つのシステム、各 500 行ずつ、週次の突合作業。ベテランで 3 時間、新人なら半日から 1 日かかっていました。ここで一つ、見落としやすい論点があります。行数の少なさが本当の難易度を覆い隠しているのです。
なぜ 500 × 500 が難しいのか
25 万通り問題
500 × 500 の組み合わせを手作業で突合させると、人間は最大 25 万通り の組み合わせを頭の中で評価していくことになります。1000 通りではありません、25 万通りです。さらにここに「タイポへの寛容」「全角半角・表記揺れ・略称・記号の差」「部分一致」が加わってきます。1 件あたりの判断は決して O(1) では終わらない、ということです。
これを総当たりで処理する負荷は、運用の世界に翻訳すると、1000ノード × 1000ノードのフルメッシュPingチェック を 1ノード × 1000 ノードの 単純Pingチェック と比較するようなものです。桁違いに重い処理になります。
ワーキングメモリのオーバーフロー
ミラーの「マジカルナンバー」によれば、人間の短期記憶は 7 ± 2 チャンクが上限です(Miller, 1956)。1000 件の候補から表記揺れも含めてマッチを探し続ける作業は、ワーキングメモリを継続的にオーバーフローさせ、System 2(遅い思考)をセッション中ずっと張り付かせます。ベテランが 3 時間で疲れ切るのは「文句」ではなく 神経科学的に避けられないことなのだと思います。
「短時間でやれる」ことと「楽にやれる」ことは、認知労働においては同じではありません。
再現性の劣化
1 回限りの突合なら力技で押し切れます。でも 10 週間以上にわたる週次のタスクとなると、判断のドリフトが避けられなくなってきます。
- 「先週は『A 商事』と『A. 株式会社』を同一とみなした。今週は別物として処理した」
- 「先週はタイポ X を許容した。今週は弾いた」
このドリフトが、長期で見たときのデータ品質を本当に壊していくものだと思っています。インフラ運用の世界で言うところの「Config レビュー基準がレビュアーごとに違う」のと同じ構造の障害モードです。
本当に解くべきだった問題
つまり、このツールが解いていた本当の問題は「週 3 時間を短縮する」ことではなく、こうなります。
25 万件 × 10 週間 にわたる 一貫した再現性 — 人間が物理的に維持できない品質基準を、決定論的な機械で担保する。
加えて、スキル依存の解消。「ベテラン 1 人が 3 時間で処理する」という状態は単一障害点(SPOF)です。ツール導入後は誰が走らせても同じ品質で結果が出るようになりました。
2. 私について — 何を解いていたのか
私は運用 / システムエンジニアです。Config 設計、変更検証、運用手順書の作成、監視、トラブル切り分け。そういう側で 20 年近くやってきました。ソフトウェア開発が本職だったことは一度もありません。スクリプトを書くこと自体は仕事の一部としてずっとやっていましたが、本格的なアプリケーション開発は別世界でした。
直前にちょうど業務領域が変わったばかりで、新しいドメインに 2 ヶ月、対象業務システムを触り始めて 1 ヶ月という状況でした。ユーザー側からは長く見ていましたが、開発者目線で触ったのはこのときが初めてでした。
翻訳すると、設計 / 検証 / 運用手順書の規律は身についていますが、Python とアプリ開発はほぼ未経験、という状態です。
この記事は 「こんなものを作りました」自慢の記事ではありません。運用側で身につけた規律が、未経験のドメインで AI 協業のソフトウェア開発に そのまま転用できた、という記録です。
想定読者
| 読者 | 役立つ章 |
|---|---|
| AI 協業を試してみたい運用 / SRE エンジニア | 全章 |
| 異領域へ越境したい中堅エンジニア | 第 2 章、第 4 章、第 5 章 |
| AI 協業を始めたばかりのエンジニア | 第 4 章、第 5 章、第 3 章 |
| AI 導入を考えているマネージャー | 第 6 章、認知負荷の議論 |
3. 機密情報 / コンプライアンスの扱い
Entity Resolution 系の記事で必ず出る質問が 「データはどこに行くのか」 です。先に答えておきます。
本実装では:
- 業務データそのものは LLM に届きません。 入力ファイル(社内マスタ + 外部システムの export)は、ローカルの Python スクリプトが直接読み込みます
-
マッチングは完全に決定論的です。 Pandas、openpyxl、
difflib.SequenceMatcherで類似度を計算しています。embedding API もリモート推論も使っていません - LLM の役割はコード側であってデータ側ではありません。 Claude Code が手伝ったのは、マッチングロジックの記述、検証スクリプト、設計レビュー、ドキュメント。実際のレコードは一度も外に出ていません
- テスト用のみ、マスキング済の合成データをプロンプトに使っています。実際の名前 / 金額 / 住所は、ローカル環境を出る前にすべて合成値に置換されています
- エッジケースは人間に委ねます。 決定論的パイプラインで判断できないケースは、フラグを立てて人間レビューに回すだけです。LLM にセカンドオピニオンを求めることはしていません
この分離は意図的です。突合タスクは決定論的なロジックで十分処理できる性質のもので、LLM を入れてもコスト・遅延・コンプライアンス露出が増えるだけで、品質的な利得はないと判断しました。
組織として「業務データを外部 AI に出さない」という方針が(明文化されていなくても)あるなら、このパターンはそのまま適用できます。
4. アーキテクチャ — 2 段階マッチング + 認知ゲート
スタック
- Python 3.11
- pandas + openpyxl(Excel I/O、色付き出力)
-
difflib.SequenceMatcher(曖昧類似度) - 全部ルールベース。機械学習なし
- 約 1100 行、単一スクリプト
フェーズ構成
Phase 1: 完全一致のステークホルダー名(または別名グループ)でマッチ
Phase 2: 名前類似度 ≥ 0.6 でクロスマッチ(タイポ救済)
Phase 3: 姓のみ + 構造マッチ(1 文字タイポ許容)
Phase 4: 重複登録検知(同一ステークホルダー + 類似度 ≥ 0.8)
Phase 5: ステークホルダー名なしの行を救済(属性マッチ)
Phase 5.5: 属性ミスマッチペアの救済(識別子類似度 ≥ 0.7、stage 2)
Phase 6: 行生成 + 色判定
スコア関数(鍵となるゲート)
def compute_score(row_a, row_b):
# ハードゲート: リージョン不一致は問答無用で除外
if region_a != region_b:
return 0.0
# ハードゲート: 数値属性の差が大きければ除外
if abs(value_a - value_b) > THRESHOLD:
return 0.0
# 識別子ゲート: row_b の識別子が row_a の識別子に埋め込めること
if not is_identifier_match(addr_a, identifier_b):
return 0.0
# サブ識別子ゲート: アンカリングバイアス対策
if sub_id not in addr_a:
return 0.0
# ソフトスコア(ハードゲート全通過後にだけ評価)
score = max(identifier_match_score, similarity, value_fallback)
return score if score >= 0.6 else 0.0
なぜこの形なのか
小売 SKU の例えで説明すると、同じ商品が自社マスタでは iPhone15 と書かれていても、マーケットプレイス側では iPhone 15 Pro Max と書かれていることがあります。同じ商品ファミリでも、表記の表面が違う。ここで効いてくる原則が 2 つあります。
- ハードゲートを先に。 「リージョンが違う」「金額差が N 円以上」は絶対除外条件。重い類似度計算を走らせる前に、これで弾く
- ソフトスコアは最後に。 ハードゲートを通った後に類似度を計算し、閾値 0.6 未満は「不確定として人間に回す」と扱う
なぜ ML / Vector DB / embedding を使わなかったのか
決定論的なルールベースを意図的に選びました。監査可能性が要件だったからです。フラグが立った行が誤判定だったとき、運用チームは「どのゲートがなぜ発火したのか」を辿れる必要があります。説明のないブラックボックスの類似度スコア 0.81 は、レビューもユニットテストもコンプライアンス監査もできません。
ML はラベル付き訓練データ、訓練インフラ、継続評価パイプラインがそろっているなら良い選択です。本案件にはどれも揃っていませんでした。「チームの誰が読んでも、なぜそう判定したかが分かるコード」が運用要件で、その制約が決定論的ロジックを選ばせたわけです。
抽象化した構造
| ドメイン固有の用語 | 抽象概念 |
|---|---|
| 商品 / SKU | エンティティ |
| ステークホルダー(仕入先 / 担当者) | ステークホルダー属性 |
| 価格 / 金額 | 主要数値属性 |
| 住所 / 所在地 | 識別子(複数属性) |
| 建物名 / 商品名 | 補助識別子 |
| 部屋番号 / バーコード | サブ識別子 |
| 表記揺れ(カナ / ラテン / 大小) | データ品質課題 |
| ドメイン判断 | 暗黙知 |
これは「2 つのシステムにわたる、表記ドリフトのあるエンティティ突合」という普遍課題です。EC、医療、人事、経理、製造、出版 — 2 つのシステムが同じ業務オブジェクトを違う表記で持っているところでは、どこでも繰り返し出てくるパターンだと思います。
5. 後から見えた認知科学的な原則(このパターンの面白い部分)
ここまでは「どう実装したか」の具体の話でした。一度コードを書き終えてから振り返ってみると、別のレイヤーで面白い構造が見えてきます。
最初は認知科学なんて何も意識せずに作っていました。動いた後、Gemini と構造的な議論をしているうちに、原則が浮かび上がってきた、という順番です。retrofit した結果、思いのほか綺麗にハマっていて少し気味悪かったほどです。
5.1 二重過程理論(Daniel Kahneman)
2 つのフェーズが、人間の 2 つの思考モードに対応していました。
- System 1(速い思考)= Phase 1〜5。 「これってだいたい同じものでは?」という曖昧判断。類似度スコア、識別子マッチ、属性近接性
-
System 2(遅い思考)=
determine_color()。 金額不一致、表記不整合、識別子混在を厳密にチェック
色付きで人間レビューに回るのは、System 1 の曖昧通過 + System 2 の厳密注釈の 両方を載せた行です。これがちょうど、人間が最終判断を下すのに必要な input の形になっています。
5.2 ゲシュタルト心理学
人間は文字列の連続ではなく「全体」を認識します。iPhone15 と iPhone 15 Pro Max が同じ商品ファミリに見えるのは、文字列としては別物でもゲシュタルト的には同じだからです。
def is_identifier_match(addr_a, identifier_b):
"""表記揺れ・区切り文字混在・スクリプト違いを越えてチャンク同一性を認識する"""
chunks = re.split(r'[A-Za-z0-9\s\-_]+', identifier_b)
return all(chunk in addr_a for chunk in chunks if len(chunk) >= 2)
チャンク単位でマッチさせると、空白、区切り文字、スクリプトのバリエーションを越えて生き残れる、という発想です。
5.3 アンカリング / 確認バイアスへの防衛
ハードゲートは、人間が陥りがちな直感ショートカットを 拒絶するために 存在しています。
- 「金額が同じだから同じ商品のはず」 → サブ識別子ゲートで却下
- 「名前が同じだから同じ人のはず」 → リージョンゲートで却下
機械の役割は、人間が確信しすぎる箇所で冷たく懐疑することだと思っています。
5.4 人間の認知負荷を下げる(Human-in-the-Loop)
フラグが立った行を人間が確認するとき、不透明な「マッチスコア 0.62」を渡されるわけではありません。1 行の注釈付きで渡されます。
同一エンティティ・マッチ | [金額不一致] 差額 ¥2,000,000 (5.4%)
(A: ¥34,900,000 / B: ¥36,900,000) ・ 識別子表記不整合
人間は「なぜフラグが立ったのか」を再導出する手間を省けます。認知負荷がぐっと下がる設計です。
5.5 「ゴースト」を自動化しない
ここは『攻殻機動隊』からの拝借です。一部の判断は、ルールに落とし込めない暗黙の業務知に依存します。それを擬似的にエンコードしようとするヒューリスティックは作るべきではないと思っています。「要確認シグナル」として行を浮かび上がらせ、暗黙の層は人間に委ねるべきです。
ロジックを締めていけばゴーストを再現できる、という方向ではないのです。
ロジックを締めていけば「ゴーストが必要な場所」が浮かび上がる、という方向です。
マッピングのまとめ
| 認知概念 | 実装 |
|---|---|
| System 1(速い) | Phase 1〜5(曖昧マッチ) |
| System 2(遅い) |
determine_color() 厳密チェック |
| 二段階 / 二重パス | Stage 1 + Stage 2 (Phase 5.5) |
| ゲシュタルト的グルーピング |
similarity / is_identifier_match
|
| アンカリング防衛 | サブ識別子ゲート、識別子ゲート |
| 認知負荷の削減 | 集約された [理由] 差分 X 注釈 |
| Human-in-the-Loop | 暗黙知ゾーンへの「要確認」シグナル |
6. 結果
過去 10 週間の実データに対するリコール
| 指標 | 値 |
|---|---|
| 人間が検出したエラー数(外れ値週除く) | 約 130 件 |
| ツールが検出したエラー数 | 約 129 件 |
| リコール | 約 99.2% |
唯一漏れた 1 件には、人間レビュアーが「これは人間でも判断できなかった」と注釈をつけていました。実質的に、人間が確信を持って判定できるケースはすべて拾えている、という結果です。
(ただし、これは 1 チームの 10 週間データに対するリコールであって、ベンチマーク的な主張ではありません。別のドメインなら別の計測が必要です)
工数とスキル依存度
| 項目 | 導入前 | 導入後 |
|---|---|---|
| ベテランのスループット | 週 3 時間 | 週 30 分(レビューのみ) |
| 新人のスループット | 半日〜1 日 | 週 30 分 |
| スキル依存 | あり(単一障害点) | なし(誰でも実行可) |
時間の数字だけだと価値が薄く見えますが、本当の変化は スキル SPOF の解消 のほうです。ベテランが体調を崩しても、退職しても、別案件で手が空いていなくても、業務は同じ品質で回り続けます。
False Positive について
リコールが 99.2% と書きましたが、このツールは 意図的にリコール優先 / プレシジョン犠牲 で調整されています。「人間レビューに回したけど結果的に問題なかった行(false positive)」はトレードオフとして受け入れる方針です。週 30 分の人間レビュー時間でこれらは無理なくさばけています。
人間を介さない自動運用ならこのトレードオフは全然違う形になりますが、本案件では false positive が安く(人間が一目で判断)、false negative が高い(突合エラーが業務レポートに伝播) という非対称性があるので、リコール優先が正解だと判断しました。
7. フローチャート
判定フローを図に起こしてみたら、コードレビューでは見えなかった構造的な特性が浮かび上がってきました。下記が実行フロー全体の統合図で、その下に各フェーズの説明を続けます。
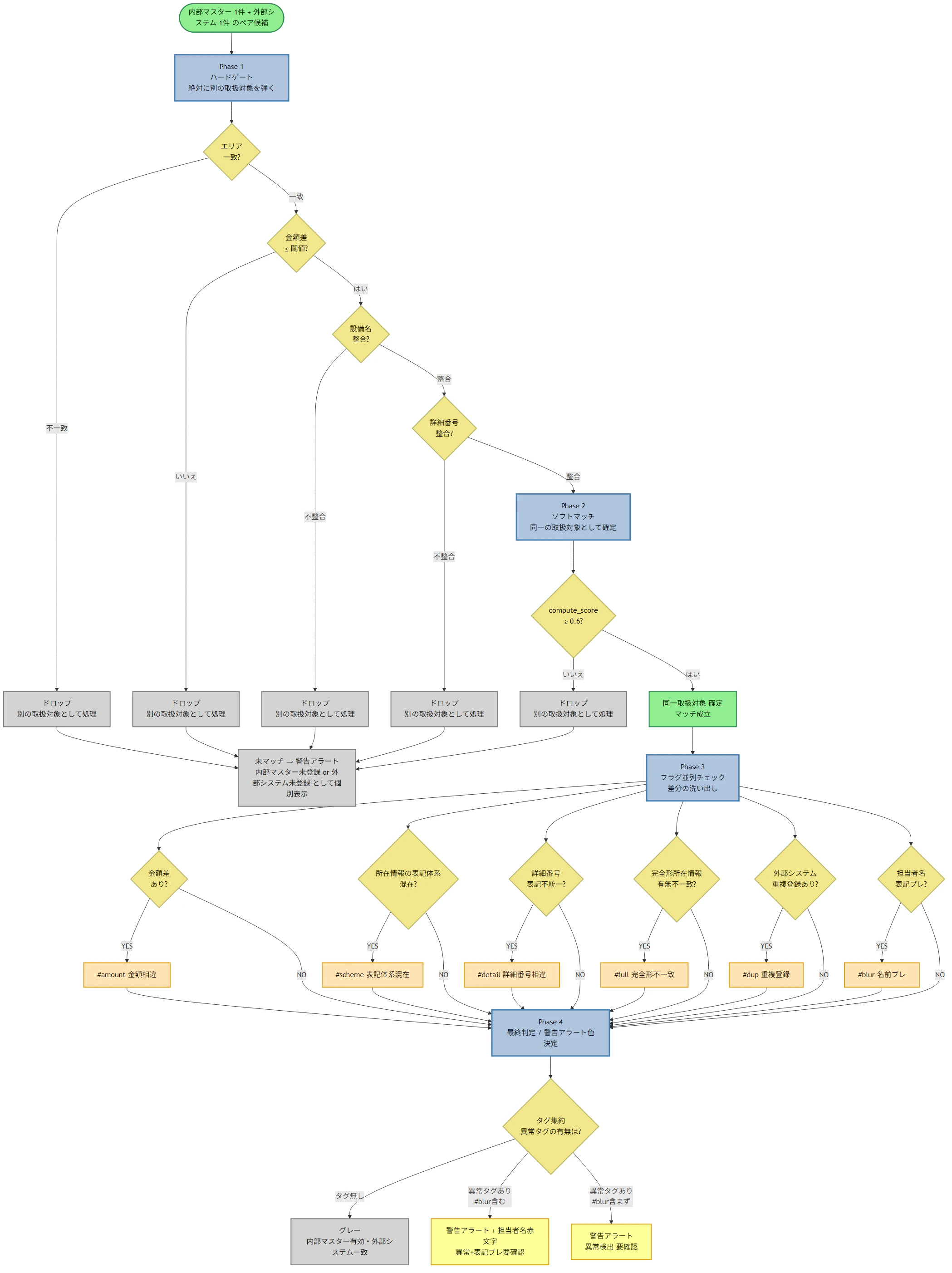
7.1 Phase 1: ハードゲート(順次除外)
リージョン → 数値 → 補助識別子 → サブ識別子。各ゲートは絶対除外条件で、「No」が一つでも出たらペアを切り捨てます。順序が重要で、最も軽い除外条件から先に走らせています。
7.2 Phase 2: ソフトマッチ
ハードゲートをすべて通過したペアに対して compute_score がソフトな類似度を評価します。0.6 未満なら破棄、それ以上なら同一エンティティとしてロックします。
7.3 Phase 3: 並列フラグチェック
確定したマッチに対して、6 つの独立チェックが並列で発火します。それぞれが「マッチしたが、こういう乖離がある」というシグナルを立て、タグとして集約されます。チェック間の早期 return による汚染が起きないように作ってあります。
7.4 Phase 4: 最終判定とドロップ集約
タグを集約して色判定に変換します。Phase 1 と Phase 2 でドロップした行は、すべて「Unmatched」レーンに集約され、人間レビュー出力では独立した塊として浮かび上がります。
図にしてみて初めて見えたこと
コードを読んでいるだけでは見えず、図に起こして初めて分かったことが 3 つありました。
- Phase 1 のハードゲートは、計算コストの順に並んでいた。 リージョン → 数値 → 補助識別子 → サブ識別子。直感で配置していただけだったのですが、図にしてみたら すでに最適でした。最も軽い除外条件が先に来ていたわけです
- Phase 3 の並列フラグチェックは、本当に独立していた。 6 つのチェックが並列で動き、お互いの早期 return で汚染し合うことはありませんでした。図がそれを確認させてくれました
- Drop1〜Drop5 のすべてが同じ Unmatched ノードに収束していた。 ドロップ理由を捨ててしまっていたんです。「なぜこのペアが弾かれたか」を後から再現できない状態でした。修正として、ドロップ理由を行注釈にログするように変更しました
フローチャートを描く作業は、本番投入前にインフラのトポロジを描くのと同じ行為です。図そのものがラバーダックになってくれます。
8. まとめ
このビルドから持ち帰れる教訓を 3 つ。
- 認知負荷は「短時間で済む」反復判断タスクの隠れたコスト。 工数ベースの計算だけでは、燃え尽きの実態とスキル単一障害点のリスクを見落としやすいと思います
- 認知科学の原則は、良い設計から事後的に浮かび上がる。 最初から意識して設計したわけではなく、構造的なレビュー(しかも別の AI を相手に)を通じて初めて見えてきました。設計が既知の認知原則に後づけで当てはまるなら確証、しないなら違和感、という見方ができそうです
- LLM は業務データに触れる必要がない。 多くの名寄せ作業は LLM がなくても解けます。LLM はコード、設計レビュー、ドキュメントに使う。業務レコードはローカルで決定論的に扱う。これで十分な領域は思っているより広いはずです
実装そのものは社内利用のみで、オープンソース化する予定はありません。ただし、パターン自体は「2 つのシステムにわたるエンティティ突合」が起きるあらゆる領域 — EC、医療、人事、経理、製造、出版 — にきれいに転用できるはずです。
9. 続編について
Part 2 で扱うこと: そもそもこれをどうやって作ったのか — AI 協業のパターン、ぶつかったアンチパターン、運用エンジニアとして身につけた規律がソフトウェア開発にどう転用できたか。
→ AIコーディングに「運用エンジニアの規律」を持ち込む話 — 5つの作法と5つの禁じ手 として公開済みです。
Entity Resolution、反復判断タスクの認知負荷、異領域からのエンジニアリング転用についてのコメント、お待ちしています。
関連記事
- AIコーディングに「運用エンジニアの規律」を持ち込む話 — 本案件で身についた AI 協業の作法を体系化した姉妹記事です
- AI コーディングは「錬金術」だ — 鋼の錬金術師から考える AI 時代のエンジニアリング — 同じ「AI と人間の境界」をポエム的にまとめたものです
読む順番のガイド(このシリーズ全体)
このシリーズは 3 本構成で、それぞれ役割が違います。読む順序によって得られるものが変わるので、目的別の推奨順を残しておきます。
| 順序 | 目的 | 推奨ルート |
|---|---|---|
| 実例から入りたい | 何が起きたか、何が動いたかを先に知りたい | 本記事(A1)→ A2(作法)→ B(理論) |
| 作法から入りたい | 自分の現場で明日から使える規律から知りたい | A2 → 本記事(A1)→ B |
| 理論から入りたい | アーキテクチャ的な前提から納得したい | B(公開予定)→ A2 → 本記事(A1) |
各記事は単独で読めるように書いていますが、3 本通して読むと「実例 + 作法 + 理論」が立体的につながる構成です。第 2 層 (作法) だけ読んで「単体 AI で十分」と判断したり、第 3 層 (理論) だけ読んで「実例なしでは適用が難しい」と感じたりしないよう、この順序ガイドを置きました。