こちらでも書いたように、ノーコード開発、ローコード開発の基盤としては、それぞれ一長一短あるのは当然であり、さらなる選択肢を探していたところ、Oracle APEX(Oracle Application Express)が目につきました。
それはそれで試してみているのですが、その中でさらに目についたのが、Oracle Machine Learningでした。
Oracle Cloud
そもそも、Oracle Cloud についてですが、Always Free が用意されています。
内容は、こちらの「常時無償のクラウド・サービスにはどのようなものがありますか?」を参照。
データベース
自律型データ・ウェアハウスと自律型トランザクション処理のどちらかを選択。合計2つのデータベース(それぞれ1 OCPUと20GBのストレージを搭載)。コンピュート
2つの仮想マシン(それぞれ1/8 OCPUと1GBのメモリーを搭載)。ストレージ
2つのブロック・ボリューム(合計100GB)。10GBのオブジェクト・ストレージ。10GBのアーカイブ・ストレージ。その他のサービス
ロード・バランサ(1インスタンス、10Mbpsの帯域幅)。監視(5億個の取込みデータポイント、10億個の取出しデータポイント)。通知(1か月当たり100万の通知配信オプション、1か月当たり1,000件の電子メール)。アウトバウンド・データ転送(10TB/月)。
開始方法についてはこちらから。
スタート・ガイド
一つ引っかかったところして、住所入力時に日本語が入っていると(?)クレジットカード認証が通らないという現象がありました。
Oracle Machine Learning の基礎
Oracle Machine Learning の入門方法については、下記がわかりやすいと思いました。
Oracle Machine Learningを使った機械学習
ここに書いてあることですが、調べ物するときに混乱しないように抑えておくべきかなと思うこと。
Oracle Databaseには旧来よりAdvanced Analytics(2019年12月の名称変更で、Machine Learningとなりました)という、データベースに内包された機械学習関連の機能があります。
そして、このページでは下準備みたいな内容になっており、本番は、そこからさらに、下記にリンクされます。
Autonomous Database ML ハンズオン
これをやることで雰囲気は掴めると思います。
Oracle Machine Learningノートブック、Jupyter Notebook と同じようなことができますね。Apache Zeppelinベースであることを強調したいようですが、Jupyter Notebookの方がメジャーではないですかね。それと同等と言ってくれた方が伝わる気が。
なお、これも言葉が色々で分かりにくいですが、「Oracle Machine Learning ノートブック」が現時点での正式名称のようです。すぐ忘れてしまうので、画像も貼っておきます。


データベースの中の、「サービス・コンソール」>「開発」メニューの中の「Oracle Machine Learningノートブック」からログインします。
調べていると「SQLノートブック」という言葉がよく出てきますが、新しい情報を調べる場合は、「Oracle Machine Learningノートブック」で調べた方が良いかもしれません。
入門してみた感想ですが、モデルや結果をテーブルで管理し、それらの操作を全てSQLでできるというのが良い。これはアプリと連携しやすいですね。
タイタニック問題にチャレンジ
ここからが本題で、これまでに学んだことを生かして、Kaggleのタイタニック問題にチャレンジしたいと思います。
基本的には、参考サイト
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
の流れで進めます。
こちらの参考サイトは、
- Python 3.X
- Pandas
- Numpy
- scikit-learn
を使うのですが、それらを使わずに、Oracle Machine Learningで行うということです。
データセットの確認&事前処理
Kaggle のタイタニックのDataページ、左下から、CSVをダウンロードします。

ダウンロードしたCSVを、Oracle Cloud にアップします。方法は、上記入門情報によると、大きくふたつりますが、SQL Developer Web による方法の方が分かりやすいかなと思いますので、そちらでやります。
いったん、上記入門で、データベースは作ってある前提です。
作ってある、データベースを開き、[ツール]→[SQL Developer Web]です。
そこで、雲のマークの「新規表へのデータのアップロード」ボタンを押します。
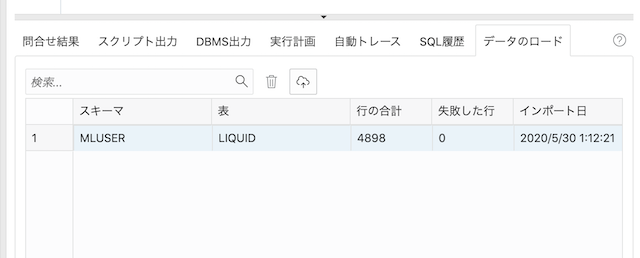
そこに、まずはtest.csvをドロップ。データ・プレビュー画面はそのまま次へ、表定義の画面で、テーブル名や、列定義をこんな感じに変えておきます。

こんな感じで生成されます。
CREATE TABLE MLUSER.TITANIC_TEST
(
PASSENGERID NUMBER ,
PCLASS NUMBER ,
NAME VARCHAR2(4000) ,
SEX VARCHAR2(4000) ,
AGE NUMBER ,
SIBSP NUMBER ,
PARCH NUMBER ,
TICKET VARCHAR2(4000) ,
FARE NUMBER ,
CABIN VARCHAR2(4000) ,
EMBARKED VARCHAR2(4000)
)
LOGGING
;
同様に、train.csvもアップします。
CREATE TABLE MLUSER.TITANIC_TRAIN
(
PASSENGERID NUMBER ,
SURVIVED NUMBER ,
PCLASS NUMBER ,
NAME VARCHAR2(4000) ,
SEX VARCHAR2(4000) ,
AGE NUMBER ,
SIBSP NUMBER ,
PARCH NUMBER ,
TICKET VARCHAR2(4000) ,
FARE NUMBER ,
CABIN VARCHAR2(4000) ,
EMBARKED VARCHAR2(4000)
)
LOGGING
;
この状態で、ノートブックを開きます。そして、新しいノートブックを作成します。

ノートブックからSQLでSELECT文を実行し、データが入っていることを確認します。
%sql
SELECT * FROM TITANIC_TRAIN;
%sql
SELECT * FROM TITANIC_TEST;

データの基本情報の確認も、SQLで取得できますが、一つ一つ見なければいけないのは、ちょっと面倒ですね。上記入門ハンズオンの真似をするとこんな感じです。
select min(AGE), max(AGE), avg(AGE), stddev(AGE), count(1) - count(AGE) as nullcount from TITANIC_TRAIN;
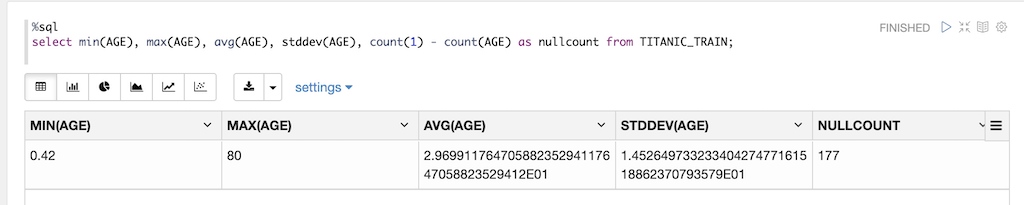
全カラム一括で一覧で取得できる、pandasのdescribe()は便利ですね。
仕方ないので、欠損値確認もこんなSQLで行います。
(余談。VSCodeでCtrl + D / command + Dによる複数選択一括書き換えは便利。)
select
count(1) - count(PCLASS) as PCLASS_nullcount,
count(1) - count(SEX) as SEX_nullcount,
count(1) - count(AGE) as AGE_nullcount,
count(1) - count(SIBSP) as SIBSP_nullcount,
count(1) - count(PARCH) as PARCH_nullcount,
count(1) - count(TICKET) as TICKET_nullcount,
count(1) - count(FARE) as FARE_nullcount,
count(1) - count(CABIN) as CABIN_nullcount,
count(1) - count(EMBARKED) as EMBARKED_nullcount
from TITANIC_TRAIN;
AGEが177件、CABINが687件、EMBARKEDが2件欠損があります。
欠損処理は、SQLで問題ないでしょう、
AGEを中央値で埋め、EMBARKEDをSで埋めます。SQLに不安がある時は、SQL Developerで先に確認できるのも、良いかなと思います。
(さらに余談。Macの場合、コード補完(テーブル名等)はcommand + space なのですが、このショートカットがSpotlight検索に割り当たっていたために保管が効かなかったので、Spotlight検索のショートカットを無効にしました)
SELECT MEDIAN(AGE) FROM TITANIC_TRAIN;
SELECT * FROM TITANIC_TRAIN
WHERE AGE IS NULL;
UPDATE TITANIC_TRAIN
SET AGE = (SELECT MEDIAN(AGE) FROM TITANIC_TRAIN)
WHERE AGE IS NULL;
SELECT * FROM TITANIC_TRAIN
WHERE AGE IS NULL;
ROLLBACK;
SELECT * FROM TITANIC_TRAIN
WHERE EMBARKED IS NULL;
UPDATE TITANIC_TRAIN
SET EMBARKED = 'S'
WHERE EMBARKED IS NULL;
SELECT * FROM TITANIC_TRAIN
WHERE EMBARKED IS NULL;
SELECT * FROM TITANIC_TRAIN
WHERE EMBARKED = 'S';
ROLLBACK;
これで反映すれば良いのですが、いったん確認だけしてROLLBACKしておいて、同じことをノートブックからもできます。
反映したら、再度欠損確認して、CABIN以外は0になっていることを確認します。
欠損データの処理の次はカテゴリカルデータの文字列を数字に変換します。
これもSQLで行います。
UPDATE TITANIC_TRAIN
SET SEX =
(CASE SEX WHEN 'male' THEN '0'
WHEN 'female' THEN '1'
ELSE SEX
END
)
,EMBARKED =
(CASE EMBARKED WHEN 'S' THEN '0'
WHEN 'C' THEN '1'
WHEN 'Q' THEN '2'
ELSE EMBARKED
END
)
;
SELECT * FROM TITANIC_TRAIN;
ROLLBACK;
TITANIC_TESTも同様に行います。
select
count(1) - count(PCLASS) as PCLASS_nullcount,
count(1) - count(SEX) as SEX_nullcount,
count(1) - count(AGE) as AGE_nullcount,
count(1) - count(SIBSP) as SIBSP_nullcount,
count(1) - count(PARCH) as PARCH_nullcount,
count(1) - count(TICKET) as TICKET_nullcount,
count(1) - count(FARE) as FARE_nullcount,
count(1) - count(CABIN) as CABIN_nullcount,
count(1) - count(EMBARKED) as EMBARKED_nullcount
from TITANIC_TEST;
--AGE 86,FARE 1
SELECT MEDIAN(AGE) FROM TITANIC_TEST;
SELECT * FROM TITANIC_TEST
WHERE AGE IS NULL;
UPDATE TITANIC_TEST
SET AGE = (SELECT MEDIAN(AGE) FROM TITANIC_TEST)
WHERE AGE IS NULL;
SELECT * FROM TITANIC_TEST
WHERE AGE IS NULL;
SELECT MEDIAN(FARE) FROM TITANIC_TEST;
SELECT * FROM TITANIC_TEST
WHERE FARE IS NULL;
UPDATE TITANIC_TEST
SET FARE = (SELECT MEDIAN(FARE) FROM TITANIC_TEST)
WHERE FARE IS NULL;
SELECT * FROM TITANIC_TEST
WHERE FARE IS NULL;
UPDATE TITANIC_TEST
SET SEX =
(CASE SEX WHEN 'male' THEN '0'
WHEN 'female' THEN '1'
ELSE SEX
END
)
,EMBARKED =
(CASE EMBARKED WHEN 'S' THEN '0'
WHEN 'C' THEN '1'
WHEN 'Q' THEN '2'
ELSE EMBARKED
END
)
;
SELECT * FROM TITANIC_TEST;
予測モデル その1 「決定木」
Oracle Data Miningでサポートされているアルゴリズムについては、下記にドキュメントがあります。
概要
(しかし申し訳ないけど探しにくい・・・)
決定木、すなわち、デシジョン・テーブルのアルゴリズムでモデルを作成します。
モデル作成は、call DBMS_DATA_MINING.CREATE_MODEL で行うわけですが、まず、そこで使用する設定を行います。
create table TITANIC_MODEL_DT_SETTING (setting_name varchar2(30),setting_value varchar2(4000));
insert into TITANIC_MODEL_DT_SETTING values ('ALGO_NAME', 'ALGO_DECISION_TREE'); -- ランダムフォレストを指定
insert into TITANIC_MODEL_DT_SETTING values ('PREP_AUTO', 'ON'); --自動データ準備をONに
ALGO_DECISION_TREEなので DT です。
call dbms_data_mining.create_model('TITANIC_MODEL_DT', 'CLASSIFICATION', 'TITANIC_TRAIN', 'PASSENGERID', 'SURVIVED', 'TITANIC_MODEL_DT_SETTING');
CLASSIFICATION とは何かというと、31.2.2 アルゴリズムの選択によると、ALGO_DECISION_TREE は「分類」であり、31.2.1 マイニング機能の選択によると、「分類」は、CLASSIFICATION ということです。
-- TEST表のデータにモデルを適用
call dbms_data_mining.apply('TITANIC_MODEL_DT','TITANIC_TEST','PASSENGERID','TITANIC_MODEL_DT_APPLY_RESULT');
-- LIFTを計算
call dbms_data_mining.compute_lift('TITANIC_MODEL_DT_APPLY_RESULT','TITANIC_TEST','PASSENGERID','SURVIVED','TITANIC_MODEL_DT_LIFT','1');
-- 混同行列を計算
declare
v_accuracy number;
begin
dbms_data_mining.compute_confusion_matrix(v_accuracy,'TITANIC_MODEL_DT_APPLY_RESULT',
'TITANIC_TEST','PASSENGERID','SURVIVED','TITANIC_MODEL_DT_CONFUSION_MATRIX');
dbms_output.put_line('**** model accuracy ****: ' || round(v_accuracy,4));
end;
/
-- 混同行列を表示
select * from TITANIC_MODEL_RF_CONFUSION_MATRIX;
混同行列とか、LIFTの計算とかは、上述の、Autonomous Database ML ハンズオンを参照。
ただ、今回はここは失敗します。タイタニックのTESTデータには、SURVIVED項目がないためです。ハンズオンでやっているように、TRAINデータをさらに分けて試すこともできると思いますが、とりあえず、TRAINデータを使うこともできました。
-- TEST表のデータにモデルを適用
call dbms_data_mining.apply('TITANIC_MODEL_DT','TITANIC_TRAIN','PASSENGERID','TITANIC_MODEL_DT_APPLY_RESULT');
-- LIFTを計算
call dbms_data_mining.compute_lift('TITANIC_MODEL_DT_APPLY_RESULT','TITANIC_TRAIN','PASSENGERID','SURVIVED','TITANIC_MODEL_DT_LIFT','1');
-- 混同行列を計算
declare
v_accuracy number;
begin
dbms_data_mining.compute_confusion_matrix(v_accuracy,'TITANIC_MODEL_DT_APPLY_RESULT',
'TITANIC_TRAIN','PASSENGERID','SURVIVED','TITANIC_MODEL_DT_CONFUSION_MATRIX');
dbms_output.put_line('**** model accuracy ****: ' || round(v_accuracy,4));
end;
/
-- 混同行列を表示
select * from TITANIC_MODEL_DT_CONFUSION_MATRIX;
ACTUAL_TARGET_VALUE PREDICTED_TARGET_VALUE VALUE
0 1 9
0 0 540
1 0 167
1 1 175
そんなに精度良くない?
では、テストデータに適用して確認してみます。
select
PASSENGERID, -- レコードを一意に識別したいときに利用
prediction( TITANIC_MODEL_DT using *) as prediction, -- 予測
prediction_probability( TITANIC_MODEL_DT , '1' using *) as probability -- 予測が '1' である確率
from TITANIC_TEST;
probabilityまで出しておきながら、0.1代が連発していますが、そして1とかありますが。いったん、probabilityは出力しないようにして、結果をCSVに出力すれば提出できますね。
上げてみたところ、スコア0.65550でした・・・
まとめ
もちろん、dbms_data_mining のストアドを使えるようにならないといけないのですが、それもSQLとして実行できるというところが強みですね。
今後は、Oracle APEX からの呼び出しとか?(やってみたいけど・・・)