成果物
以前、こちらのサイトを参考にさせていただき、
こんなアプリを作りました。
これを応用しながら、現在開発中のアプリにも、WordCloud の表示を追加しました。
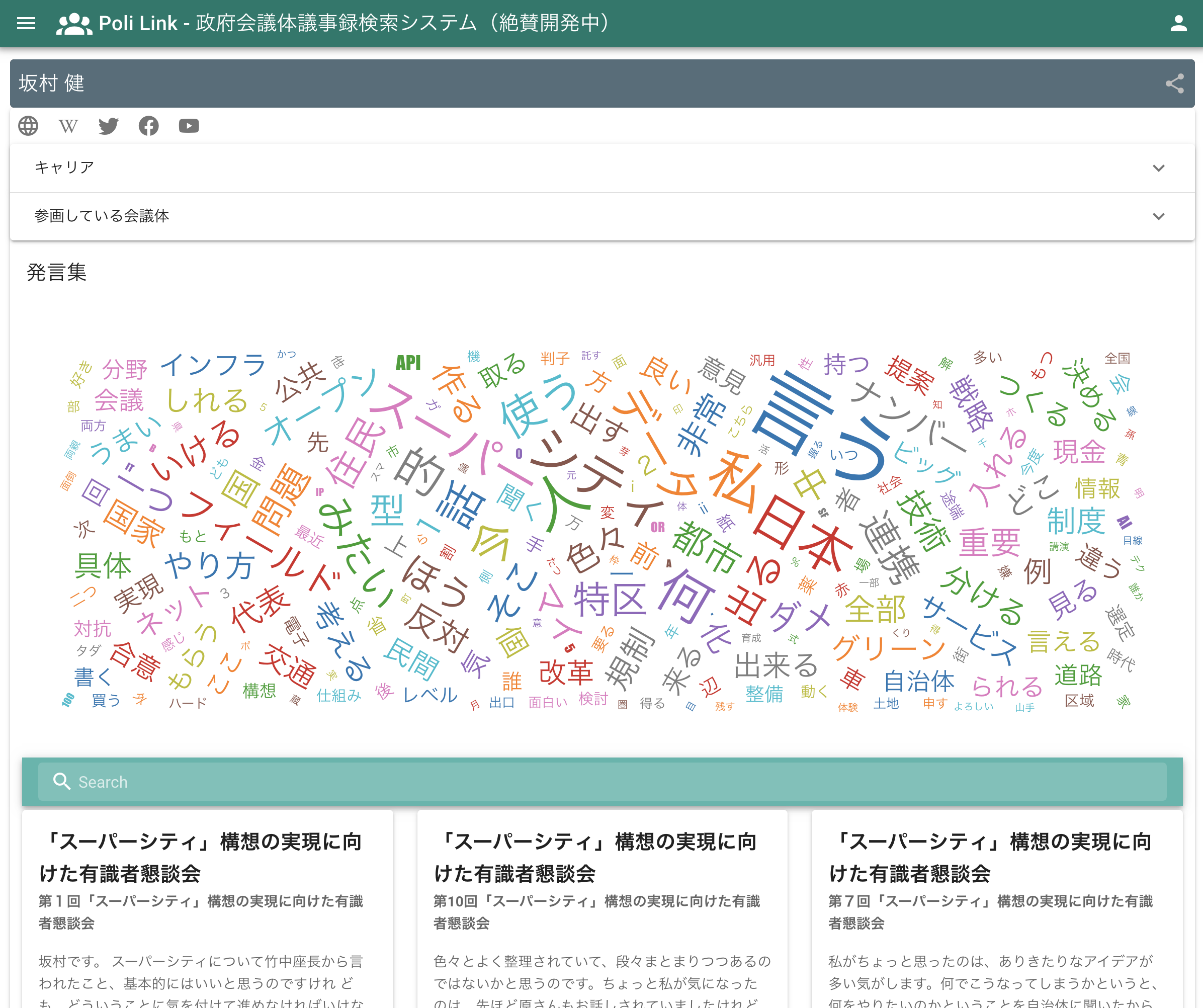
こちらは、一例ですが、色んな方の専門家会議等での発言に基づいて、WordCloud としてまとめています。
アプリケーション方式
このアプリ自体は、フロントを Nuxt で作って、Netlify にデプロイしています。
API を、Django REST Framework で作り、Heroku にデプロイしています。
DB は、Heroku と連携して使える、ClearDB MySQL に作成しています。
今回作ろうとしているのは、専門家会議の構成員一人一人についてのWordCloudです。
これを、リアルタイムで生成するのは無理だと思うので、上記アプリ構成外で、データ生成(ワードごとの重み付けデータ)を行います。
上記 sake-pairing は、定期バッチで生成しています。なぜなら、集計元のデータがTwiiterのツイートであり、これはリアルタイムで変わっていくものだからです。
しかし、今回は、集計元データは今の所自分で登録しているデータですので、データ登録に合わせて生成すれば問題ありません。
もう一点、ClearDB の制限が意外ときつい。(3600query/hour?)
最初、ローカルのプログラムでClearDBに接続していましたが、それだと接続制限にかかってしまいました。
ですので、ローカル開発環境でファイルを生成し、github にコミットすることでデプロイされ、Nuxt アプリ側からは、そのファイルを読み込んでWordCloud を生成する構成とします。
Python による、形態素解析、ワードカウント、ファイル生成
結論としては、こんなプログラムになりました。
import json
import urllib.request
import tempfile
from janome.tokenizer import Tokenizer
import pandas as pd
import os
folder_name = "./wc"
def main():
try:
url = "http://localhost:8000/api/person/"
res = urllib.request.urlopen(url)
data = json.loads(res.read().decode('utf-8')) # 実行結果(json)をdata変数に格納
except urllib.error.HTTPError as e:
print('HTTPError: ', e)
except json.JSONDecodeError as e:
print('JSONDecodeError: ', e)
for person in data:
print(person['id']) # idのみ参照
try:
url = "http://localhost:8000/api/meeting_speech/"
params = {
'person': person['id'],
}
req = urllib.request.Request('{}?{}'.format(url, urllib.parse.urlencode(params)))
# res = urllib.request.urlopen(req)
with urllib.request.urlopen(req) as res:
speech_data = json.loads(res.read().decode('utf8'))
except urllib.error.HTTPError as e:
print('HTTPError: ', e)
except json.JSONDecodeError as e:
print('JSONDecodeError: ', e)
if len(speech_data) > 0:
speech = []
# print(speech_data)
for skey in speech_data:
# print(skey)
speech.append(skey['speech'])
out = gen_wordcloud(speech)
out.to_json(folder_name + '/' + person['id'] + '.json', orient = 'records', force_ascii=False)
def gen_wordcloud(texts):
words = []
for text in texts :
words.extend(counter(text))
sr = pd.Series(words)
counts = sr.value_counts()
df = pd.DataFrame(counts.rename_axis('name').reset_index(name='value'))
return df
def counter(text):
if not text:
return ''
t = Tokenizer()
words = []
try:
tokens = t.tokenize(text)
for token in tokens:
#品詞から名詞だけ抽出
pos = token.part_of_speech.split(',')[0]
if (pos == '名詞') or (pos == '動詞') or (pos == '形容詞'):
if token.base_form not in '#, [], する, (), ある, @, これ, こと, よう, いる, なる, さん, いう, ない, おる, れる, の, てる, もの, とこ, 料理, やる, つく, やつ, しまう, できる, それ, くる, とき, いく, せる, ところ, ため, たち, いく, くれる, わけ, 思う, いい, いただく, 行う, &':
words.append(token.base_form)
except:
print('error!', text)
return words
if __name__ == '__main__':
main()
元データ(今回は発言データ)取得
直接DBからの取得ではなく、既存API経由で取得します。
人ごとにファイルを作成しますので、
http://localhost:8000/api/person/
で、人情報を取得します。
人のループで、
http://localhost:8000/api/meeting_speech/
で発言情報を取得します。
どちらもJSONで取得するので、
with urllib.request.urlopen(req) as res:
speech_data = json.loads(res.read().decode('utf8'))
の部分で、データとして扱える形を作ります。
speech = []
に文字列配列を作った上で、これを、gen_wordcloud に渡します。
形態素解析
gen_wordcloud から、すかさず、counter に渡して、単語ごとに分割します。
janome.tokenizer、何もわからなくても、勝手に分割して、品詞判別までしてくれる。
素晴らしいですね。
で、token.base_form に単語が入っているので、それを配列に突っ込んでいくわけですが、一部、意味のない単語を排除していきます。結果を見ながら、どんどん足していくわけですが、こういうの上手くできると良いなと思います。
出現数カウント
counter で単語一覧ができたので、pandas でカウントします。
これは、pandas の素晴らしさで簡単にできるわけですが、これをファイルにするところは、ちょっと悩みました。
ただ、これも素晴らしいことに、padas の DataFrame には、to_json という操作ができる。
引数、force_ascii=False はtrueじゃなくてfalse というところに気をつければ、できるというわけです。
また、その前に、
df = pd.DataFrame(counts.rename_axis('name').reset_index(name='value'))
とすることで、単語の列に「name」、カウントの列に「value」という名前をつけることができます。
Nuxt での、WordCloud 生成
データができたらNuxt側で読み込みます。
最初、axios で読み込むサンプルを見て、ただ、nuxt.config.ts で
axios: {
baseURL: process.env.BASE_URL || 'http://localhost:8000/api/',
},
のように定義していて、自動的に、API側を見にくようになっていた、すなわち、上記構成だと、Heroku 側に醜ようになっていたので、そちらにファイルを置こうとしました。
そのために、まず、staticfiles に置くのに苦労しましたが、それに成功しても、CORS に引っかかるという状況だったので、Nuxt 側の静的ファイルとして置くことにしました。
(余談)Django における静的ファイルの配置
最初、ファイルを「staticfiles」に直接置いても参照できず、
python manage.py collectstatic
しても、反応しないなと悩んでいたのですが、アプリ側フォルダ内に、「static」フォルダを作成し、そこにファイルを置いた上で、collectstatic をすると、staticfiles にファイルがコピーされて、三勝可能になるのでした。
assets フォルダの参照
では、実際に行った方式です。Nuxt 構成の、assets フォルダに、ファイルを置き、それを参照するようにします。
こちらも、結論としては、このようになります。
<template>
・・・
<wordcloud
:data="words"
name-key="name"
value-key="value"
:show-tooltip="false"
/>
・・・
</template>
<script lang="ts">
// 個人発言リスト
import { reactive, computed, toRefs, useFetch, useContext, defineComponent } from '@nuxtjs/composition-api';
import { useMeetingSpeech } from '@/compositions';
// import jsonData from '@/assets/wordcloud/1e987981-415a-4e50-ab5f-2a9e35243056.json'
// import jsonData from `@/assets/wordcloud/${props.personId}.json`
export default defineComponent({
name: 'PersonSpeechList',
props: {
personId: {
type: String,
required: true,
},
},
setup(props, { root }) {
console.log('personId', props.personId);
const { state: meetingSpeechState, getMeetingSpeechList } = useMeetingSpeech();
const itemsPerPageArray = [4, 8, 12];
const state = reactive({
search: '',
filter: {},
sortDesc: false,
words: [
{ name: "発言", value: "100" },
{ name: "Wordcloud", value: "20" },
{ name: "議事録", value: "30" },
{ name: "政府会議体", value: "40" },
],
});
const page = 1;
const itemsPerPage = 60;
const sortBy = 'name';
const keys = [ 'meeting_date', 'name'];
try {
const jsondata = require(`~/assets/wordcloud/${props.personId}.json`)
// console.log('jsondata', jsondata);
if (jsondata) {
state.words = jsondata
}
} catch {
console.log('no jsondata');
}
const fetchData = async (offset = 0, personId = '') => {
console.log('personId', personId);
await getMeetingSpeechList({ offset: offset, person: personId });
// const jsondata = await import(`~/assets/wordcloud/${props.personId}.json`)
// const jsondata = await fetch(`/wordcloud/${props.personId}.json`).then(res =>
// res.json()
// )
// console.log('jsondata', jsondata);
// state.words = jsondata
};
const { fetchState } = useFetch(() => fetchData(0, props.personId));
return {
itemsPerPageArray,
...toRefs(state),
page,
itemsPerPage,
sortBy,
keys,
...toRefs(meetingSpeechState),
};
},
});
</script>
途中の悪戦苦闘の後もコメントで残してあります。
requireで、動的文字列を使えるので、これで人ごとに読み込みファイルを切り替えることができる、ということです。
以上
WordCloud は見た目のインパクトがあるので、効果的に使えると良いですね。