初日の記事で紹介されてる (今年度の生徒たちのコンテスト成果 一番上) JPNYKWです.
今回は自作言語もRustもLLVMも何もかも初めての 超絶初心者 である私が, 1ヶ月間学びながら簡単な自作言語に挑戦したので, これまでどのように学び開発をして行ったかを綴ろうと思います. また, 知識も無いので高度な内容は書けません, ご了承ください. 間違いもあると思いますので, 指摘していただけると助かります.
※偶然にも @Garnet3106 さんの 19日目の記事 と自作言語ネタが被りました ![]()
言語紹介
おもちゃ言語と呼んでいます. 高度な機能はありませんし, 未完成です. 期待はしないでください (重要)
言語名は plat と言います. 意味は playthings の省略です.
構文紹介
最初に, この言語の構文を簡単に紹介します. 基本的には LLVM Tutorial で開発していく Kaleidoscope の構文と同じです. 機能性などを拘りたかったですが, 技術が追いつきませんでした. 慣れてきたら挑戦します. また, ここで紹介している構文をすべて実装してるわけではなく, 構想段階のものも含みます. ご了承ください.
Hello World
print("Hello World")
標準出力は print 関数です. 文字列は " で囲います.
Fibonacci
fun fibo(n)
if n < 3
1
else
fibo(n - 1) + fibo(n - 2)
関数定義は fun で行います. if文と関数は式として扱え, 明示的に return を用いない場合, 最後に評価した値を返却します. スコープはPythonみたいにインデントを使って定義します.
let x = 5;
let text = concat("$()th fibo is $()", x, fibo(x));
print(text);
変数宣言は let で行います. 変数はすべて mutability です. 文字列と変数の結合には concat 関数を用います. 第1引数の文字列に含まれる $() 部分を, 第2引数以降の値で順番に置き換えた文字列を返します.
開発手順
どのようにして言語を開発したかを紹介します. 今回はLLVMを用いて開発を行いました. LLVMを用いることによってフロントエンドの実装のみでコンパイラを作ることができます. ミドルエンドとバックエンドはLLVMが行ってくれます. 大まかな工程はこの様になっています.
- 字句解析器を作る
- 構文木解析を作る
- LLVM IRを吐き出す
- 実行する
まずは, LLVMの tutorial を参考に構文をパースをする字句解析器を作りました.
1. 字句解析器を作る
字句解析器は入力されたソースコードを解析してトークンを返す処理を行います. 例えば,
print(2 + 3)
これを字句解析器に通すとこのようなトークンが得られます
[-6, 40, -8, 43, -8, 41]
それでは, 何故このようなトークンが得られるのかを説明していきます.
トークンは次のように定義されています.
任意の1文字に対して
-
Alphabetで, 予約語に存在する場合は対応するtokenを返す. -
Alphabetで, 予約語に存在しない場合はidentifierを意味するtokenを返す. -
"の場合は文字列を意味するtokenを返す. -
Numericあるいは.の場合は数値を意味するtokenを返す. -
#の場合はコメントを意味するtokenを返す. - それ以外の場合は
ASCII codeをtokenとして返す.
なお, 空白と改行は次の文字列か末尾にマッチするまで無視するようになっています.
こうすることで, tokenの値が0未満なら上4つのどれかで,
そうでなければ最後の条件であることが分かります.
while code.chars().nth(index) == Some(' ') || code.chars().nth(index) == Some('\n') { index += 1; }
if index >= code.len() { return [0, index as i64]; }
let last_str = &code.chars().nth(index).expect("Failed to unwarap Last Character").to_string();
let mut identifier_str: String = String::new();
まずは入力を空白または改行までスキップし, そのindexがソースコードの長さを超えていないか判定します. 超えていない場合はindex番目の文字列を取得してunwarapして last_str に格納しています. その後, last_str に対してパターンマッチを下部で行っています.
// Method (hit String)
{
// ...
// 条件1: アルファベットで始まり, 予約語の場合は対応するトークンを返す.
// 条件2: アルファベットで始まり, 予約語に存在しない場合は identifier を意味するトークンを返す.
}
// String (hit Quote)
{
// ...
// ダブルクオーテーションから始まる場合は文字列を意味するトークンを返す
}
// Number (hit Number)
{
// ...
// 数値から始まる場合は数値を意味するトークンを返す
}
// Comments (hit String)
{
// ...
// シャープから始まる場合はコメントを意味するトークンを返す
}
トークン処理は単純で, シンプルに正規表現を用いています. この例はAlphabetへのMatchです.
let reg = Regex::new(r"[a-zA-Z]+").expect("Failed to create REGEX");
let res = match reg.captures(last_str) {
Some(_) => "Ok",
None => "_"
};
シンプルに /a-zA-Z/ にマッチする正規表現の結果を res に格納し,
if res == "Ok" {
// TODO:
}
if内部でtoken処理を行っています. 同様に, Alphabet以外にも対応させていきます. いずれかのパターンにも当てはまらない場合は last_str をASCIコードに変換したものをtokenとして返却します.
// それ以外の場合はASCIIコードをトークンとして返す
[code.chars().nth(index).expect("Failed to unwrap at convert to ASCII-Code").to_string().as_bytes()[0] as i64, (index + 1) as i64]
2. 構文解析器を作る
実装でここが難関でした. 木構造をそもそも触ったことがなかったので, 二分木などを書いて練習しました.
さて, ここでは Token をもとに AST を生成します. AST とは Abstract Syntax Tree 日本語で 抽象構文木 を意味しています. 最終的に LLVM IR を吐き出したいので, そのためにソースコードを木構造に変換します.
※ASTを直感的に理解するためにはWikipediaにある画像が分かりやすいです.
https://en.wikipedia.org/wiki/Abstract_syntax_tree
Hello Worldのコードからこの様な木を生成します.

構造体とトレイト
まず, 3種類の構造体を定義しました.
#[derive(Debug)]
pub struct Root {
pub token: i64,
pub node: Vec<Types>
}
#[derive(Debug)]
pub struct Expression {
pub token: i64,
pub node: Vec<Types>
}
#[derive(Debug)]
pub struct Statement {
pub token: i64,
pub node: Vec<Types>
}
Root から Expression や Statement が生えてくるイメージです. また, node には Expression と Statement の二種類が必要なので, 列挙型 Types を定義しました.
| Name | Role | Ext |
|---|---|---|
| Root | 根 | ルート用. 一度だけ使う |
| Expression | 式 |
1+1 や f() など式 |
| Statement | 値 |
2 や "hoge" などの値 |
#[derive(Debug)]
pub enum Types {
Exp(Expression),
Stat(Statement)
}
次に, Root のトレイトを実装しました.
impl Root {
fn new(token: i64) -> Self {
Self {
token: token,
node: Vec::with_capacity(32)
}
}
pub fn insert(&mut self, token: i64, mode: i64) {
if mode == 0 {
let node: Types = Types::Exp(Expression::new(token));
self.node.push(node);
} else {
let node: Types = Types::Stat(Statement::new(token));
self.node.push(node);
}
}
}
insert でノードを追加していきます. mode が0である ( Expression を意味する) か、それ以外 ( Statement を意味する) を区別して, node に追加しています. Expression と Statement のトレイトも同様に実装していきます.
TokenをASTに
次に, 実際に token をASTに変換する処理を実装します. ちなみにですが, ここは現在も苦戦しながら実装と改善を繰り返している段階です. まず, これまでの token を token_buffer に書き込み, 順番にASTに挿入していきます.
for token in token_buffer {
if token[0] != lexer::TOKEN._comment {
match token[0] {
// Tokenごとの処理を実装
-1 => { /* ... */ }
// 例外
_ => { }
};
}
}
なお, コメント文は無視するので lexer::TOKEN._comment と一致したら処理を飛ばします.
Tokenごとの処理は適宜実装します. 雑な例を上げるとこんな感じです.
// if文
-1 => {
root.insert(lexer::TOKEN._if, 0); // ifのToken, Expressionを表す0をinsert
}
root に毎回挿入してはいけないので, スコープへの対応も実装しておきます.
3. LLVM IRを吐き出す
ASTをもとにLLVM IRを生成します. LLVM IRは高級言語とアセンブリの中間言語で, LLVMが解釈してアセンブリへの変換等を行ってくれます. つまり実装をしていくのはここが最後です.
結果
イメージが湧きにくいと思うので, 最初に結果を載せます. まずはplatで記述したHello Worldをするプログラムを書きます. そして helloworld.plat というファイルに保存します.
print("Hello World!")
次にこのように, cargo run helloworld.ll 引数にプログラムのファイルパスを渡して実行すると LLVM IR を生成し, 出力します. こちらが実行結果です.
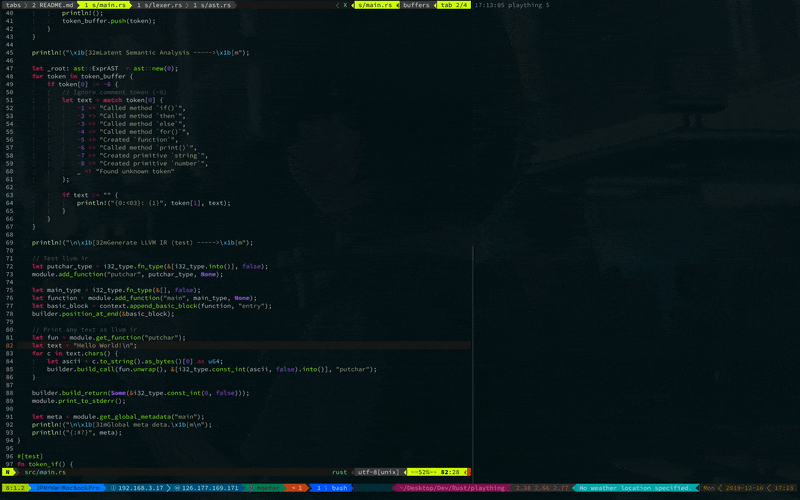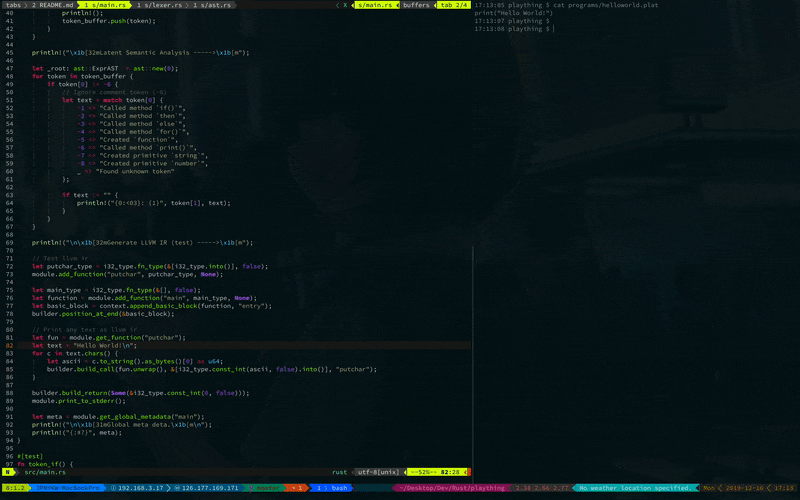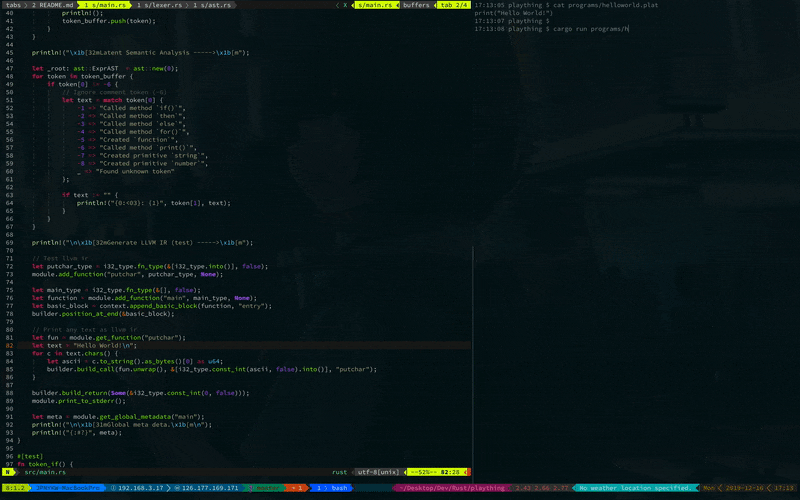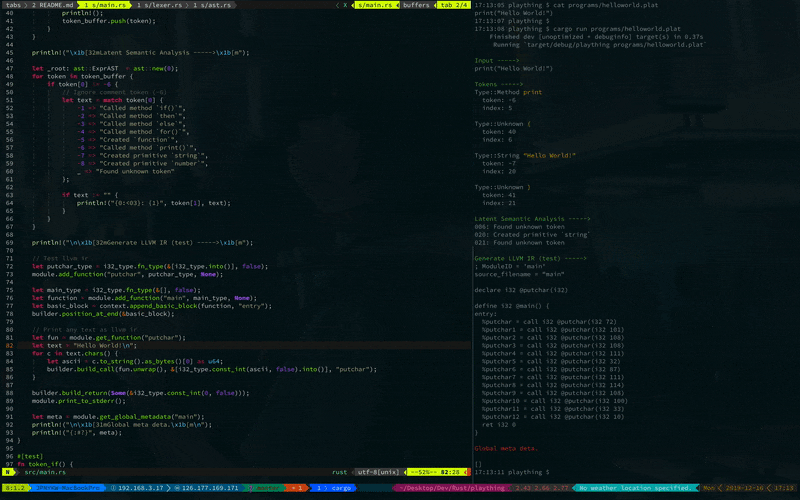
LLVM IR が出力されました ![]()
中身はこの様になってます.
; ModuleID = ‘main’
source_filename = "main"
declare i32 @putchar(i32)
define i32 @main() {
entry:
%putchar = call i32 @putchar(i32 72)
%putchar1 = call i32 @putchar(i32 101)
%putchar2 = call i32 @putchar(i32 108)
%putchar3 = call i32 @putchar(i32 108)
%putchar4 = call i32 @putchar(i32 111)
%putchar5 = call i32 @putchar(i32 32)
%putchar6 = call i32 @putchar(i32 87)
%putchar7 = call i32 @putchar(i32 111)
%putchar8 = call i32 @putchar(i32 114)
%putchar9 = call i32 @putchar(i32 108)
%putchar10 = call i32 @putchar(i32 100)
%putchar11 = call i32 @putchar(i32 33)
%putchar12 = call i32 @putchar(i32 10)
ret i32 0
}
生成方法
今回は inkwell というWrapperを使いました. Cargo.toml の dependencies に指定するだけで使えます.
inkwell = { git = "https://github.com/TheDan64/inkwell", branch = "llvm3-7" }
では, 先ほどのhelloworldをするプログラムから生成された LLVM IR を簡単に説明します. まず下準備として context や module と呼ばれるものが必要になります.
let context = Context::create();
let module = context.create_module("main");
let builder = context.create_builder();
let i32_type = context.i32_type();
module に文字を出力する関数 putchar を追加します.
let putchar_type = i32_type.fn_type(&[i32_type.into()], false);
module.add_function("putchar", putchar_type, None);
同様に main 関数を追加し, スコープの開始を伝えます.
let main_type = i32_type.fn_type(&[], false);
let function = module.add_function("main", main_type, None);
let basic_block = context.append_basic_block(function, "entry");
builder.position_at_end(&basic_block);
次に出力したい文字列を文字に分解して, asciiコードに変換し, putchar をbindしていきます.
let fun = module.get_function("putchar");
let text = "Hello World!\n";
for c in text.chars() {
let ascii = c.to_string().as_bytes()[0] as u64;
builder.build_call(fun.unwrap(), &[i32_type.const_int(ascii, false).into()], "putchar");
}
これで Hello World! が出力できるようになりました. AST生成後に走査しながらこの処理を行います.
%putchar = call i32 @putchar(i32 72)
%putchar1 = call i32 @putchar(i32 101)
%putchar2 = call i32 @putchar(i32 108)
%putchar3 = call i32 @putchar(i32 108)
%putchar4 = call i32 @putchar(i32 111)
%putchar5 = call i32 @putchar(i32 32)
%putchar6 = call i32 @putchar(i32 87)
%putchar7 = call i32 @putchar(i32 111)
%putchar8 = call i32 @putchar(i32 114)
%putchar9 = call i32 @putchar(i32 108)
%putchar10 = call i32 @putchar(i32 100)
%putchar11 = call i32 @putchar(i32 33)
%putchar12 = call i32 @putchar(i32 10)
これを *.ll という拡張子で保存すれば完了です. ここでは helloworld.ll ですね.
4. 実行する
lliコマンドを使って実行します.
lli helloworld.ll
すると Hello World! と出力されます.
こちらが実行結果です.
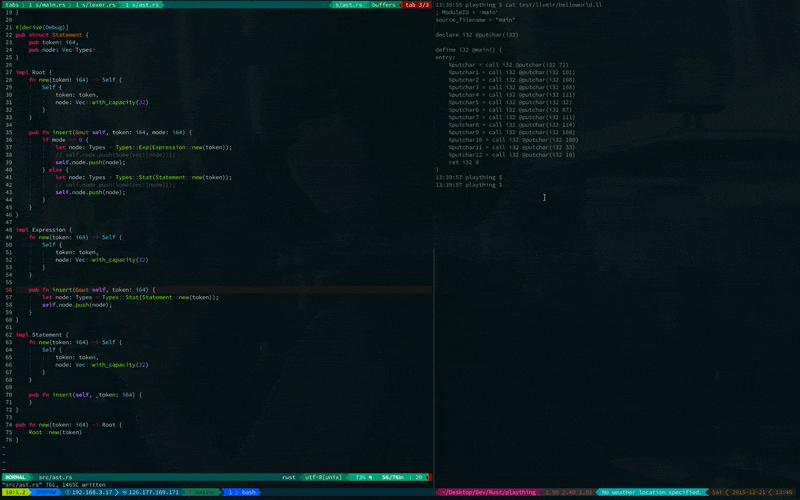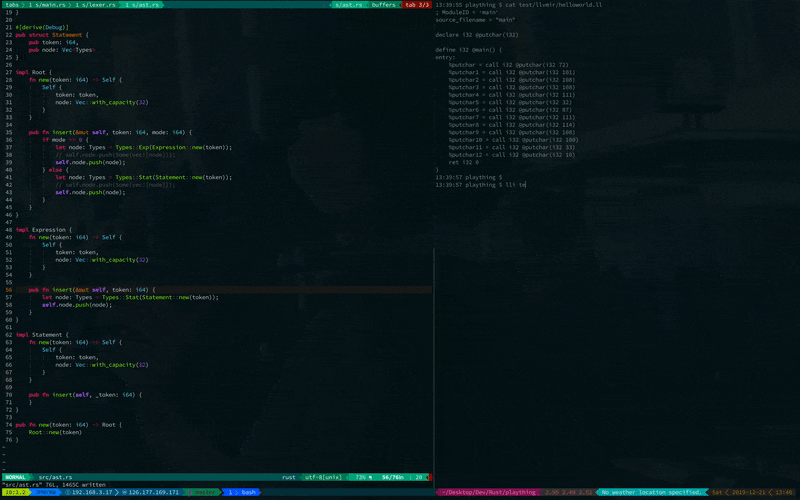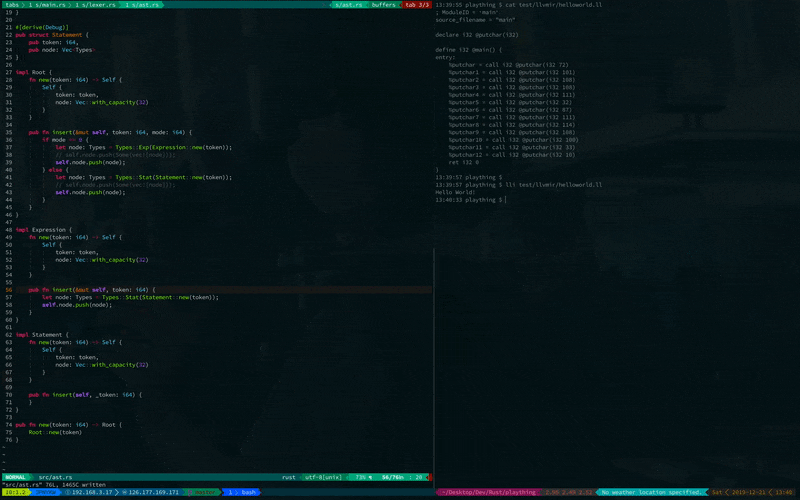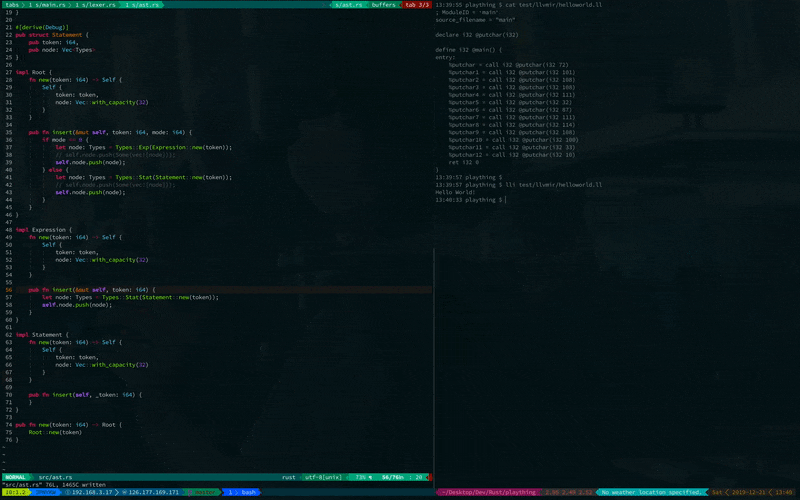
見えにくいですが, 無事にHello Worldできています.

これで自作言語を実行することができました ![]()
雑感
LLVMは偉大だと思いました (小並感)
私はLLVMの フロントの実装だけでいい という部分に惹かれて開発を始めた訳ですが, Rustに慣れていないのもあって, フロントの実装が思っていたより重かったので少し苦戦しました. しかし, とてもやりがいがあって楽しかったのでいい経験になりました. また, Rustはコンパイラが親切で助かりました.
Rustの学び方
ここからはちょっとした余談です (読み飛ばして貰っても構いません)
私の場合はとにかくコード書いて開発しまくり, 気がついたらRustをチョット触れるようになっていました. 一番最初にRustで開発したのはリバーシで, Twitterに進捗をペタペタしたところ, Rustの持つ †Brand Power† か, ファボが飛んできてモチベーションに繋がったりしました. なのでモチベーションが落ちることはなかったです.
Rust Reversi 完全に完成をした pic.twitter.com/pwOcvGDrje
— 名前空間 (@JPNYKW) November 10, 2019
また, アップデートを繰り返し, 機能を追加するなど, リファクタリングを繰り返して少しずつRustらしい書き方をできるように意識しながら開発をしました. 例えば, コンピュータ(笑)対戦をつけたりしました.
Rust Reversiに評価関数実装したのでコンピュータ対戦ができるようになった(白がCPU) pic.twitter.com/2rntpgH6lX
— 名前空間 (@JPNYKW) November 14, 2019
最後に
RustとLLVMを学ぶのはやり甲斐が多く学べるものも沢山あり面白かったです. Rustという言語に魅了されているので, 関連したような記事をまた書いてみたいと思っています. 最後まお読みいただきありがとうございました. また、誤字脱字, 実装方法, 間違ってる情報などの指摘は大歓迎です. よろしくおねがいします.
GitHub: https://github.com/JPNYKW/plat
一応載せますが, Repository上のものは未完成で動かすことはできません.