
増川 直裕
■OECDの加盟国を対象とした幸福度ランキング
世界幸福度レポートをご存じでしょうか。毎年各国々の対象者に、自身の幸福度を0から10のスコアで評価してもらい、それらの結果が毎年レポートとして報告されています。
最新の2022年のレポートは、以下のリンクから参照できます。
World Happiness Report 2022
本ブログでは3回のシリーズにわたり、各国の幸福度に関する分析を行います。国ごとに幸福度とそれに寄与するさまざまな項目がデータとして取得できますので、寄与する項目間の関連性や、幸福度から類似する国をグループ化する、通常の国とは異なる幸福度をもつ国の発見とその要因分析などを、多変量解析の手法である「主成分分析」と「クラスター分析」を用いて調べてみます。
今回のPart 1では、各国における幸福度の可視化と、主成分分析による幸福度に寄与する要因を多変量データとみなして項目の主成分負荷量と各国の主成分スコアを算出し、それらの関連性を見ていきます。
レポートでは146もの国に対する幸福度ランキングが掲載されていますが、以下の分析では、OECD(経済協力開発機構)に加盟している国々から、幸福度のランキングが他の国より低いトルコを除いた37か国を対象としています。OECDに加盟している国は、経済的に先進国と言えますので、先進国を対象として分析すると考えてください。
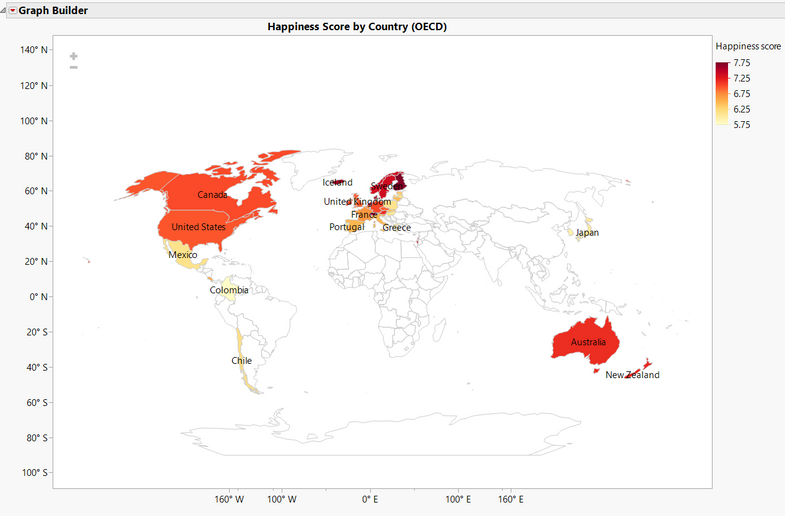
まずは、対象とする国の幸福度(値が大きいほど幸福であることを示す)を世界地図で示します。レポートによると2019年から2021年の3年間の調査における幸福度の平均をとった値のようです(ただし、Luxembourgは2019年のみの幸福度になります。)
上記のレポートには、次のような幸福度を降順に並べた棒グラフが示されています。ここでは、対象となる146か国中での幸福度ランクと国名を記載しています。(例えば、"31.Italy" は、イタリアの幸福度ランキングは31位であることを示します。) ランキング上位はヨーロッパの国々で占められていますね。一方、日本のランキングは54位と先進国の中では低くなっています。
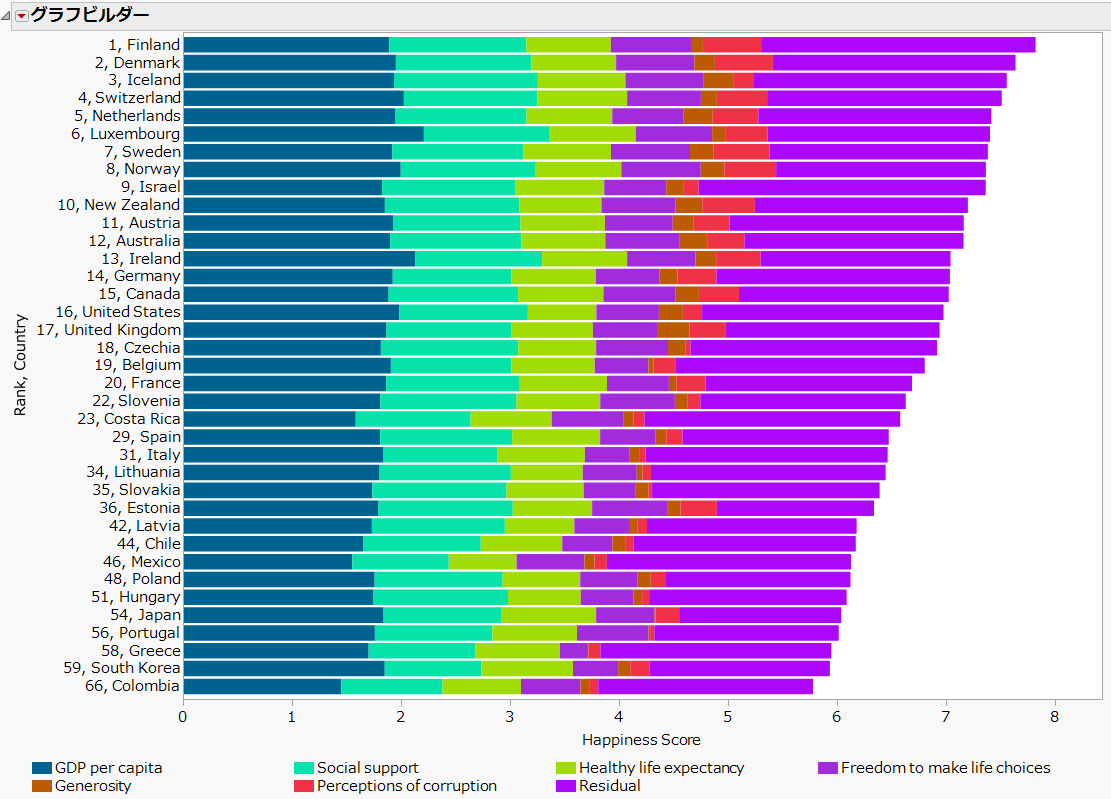
この棒グラフは、幸福度に寄与する以下の6つの項目と、それらで説明できない残差の項目で構成されています。
GDP per capita : 国民一人あたりのGDP
Social Support:社会支援の充実度
Healthy life expectancy:健康寿命
Freedom to make life choices: 人生選択の自由さ
Generosity: 他社への寛容性
Perceptions of corruption: 国に対する信頼度
報告書によると幸福度を目的変数、上記の6つの項目を説明変数として回帰分析を行い、求められたモデル式から各説明変数の寄与度を求めているようです。これら6つの説明変数で回帰モデルの調整済み寄与率が75%程度、すなわち幸福度の四分の三(3/4)が説明できていると記載があります。
これら6つの項目で説明できない幸福が、いわゆる残差になっていると考えられます。そのため、
Residual: 上記の項目(説明変数)で説明できない幸福度
とみなすことにします。
主成分分析
分析対象とした37か国に対し、上記の幸福度に寄与する項目と残差を含めた7つの項目(連続変数)について主成分分析したときのレポート(Summary Plots)を示します。レポート右側のグラフが負荷量プロット、真ん中のグラフがスコアプロットになります。
要約レポート
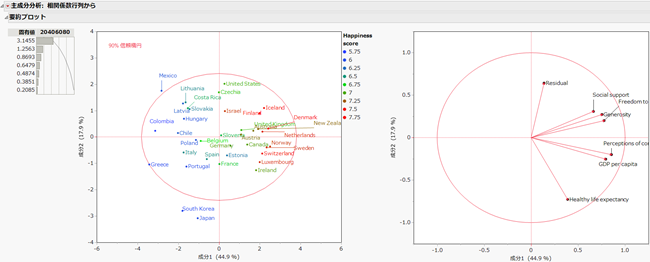
負荷量プロット
各主成分と変数との相関をプロットしたものです。変数のプロットにより変数の総合的な相関関係を読み取ることができます。
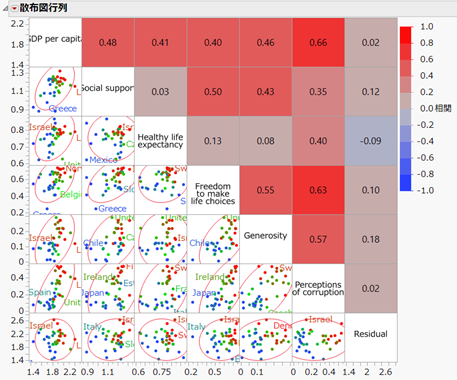
この例では、近くに位置している"GDP" と"Perceptions of corruption" の相関が高く、"Social Support", "Freedom to make life choices", "Generosity" の相関が高くなっていることがわかります。また、”Healthy life expectancy” や "Residual" の近くに位置する変数はないため、他の変数との相関はあまり高くないことがわかります。 以下の、散布図行列のレポートと併せて考察すると分かりやすいでしょう。
散布図行列
スコアプロット
求めた主成分の線形結合の式に、各変数の値を代入した値をプロットしたものです。各サンプル(この例では"国")の特徴づけを行うことができます。スコアプロットで近い位置にプロットされるサンプルどうしは、似たような性質を持っていることになるので、サンプルのグルーピングの用途で用いられます。
また、ここではプロット点について幸福度のスコアで色を付けています。(青⇒緑⇒赤)グラフの右側に位置する国は幸福度のスコアが高く、左側に位置する国は幸福度のスコアが低いと意味付けできそうです。
主成分軸の解釈
通常、負荷量プロットとスコアプロットを見ながら、それぞれの主成分軸がどのような意味合いを持つのかを解釈します。
その際、負荷量プロットとスコアプロットを重ね合わせたバイプロットを参照すると解釈しやすくなることがあります。
バイプロット
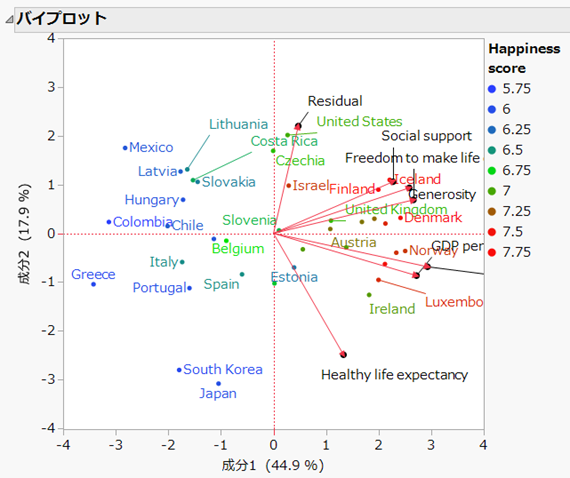
横軸である第1主成分は、幸福度スコアの高さ(正の方向で大きな値ほど幸福度は高い)と考えられるでしょう。プロット点(国)は幸福度スコアで色付けされているので、グラフの右側に位置しているほど幸福度スコアが高く、左側に位置しているほど低いことがわかります。この軸でデータの変動の44.9%を説明しています。
縦軸である第2主成分は解釈が難しいです。健康寿命と残差が原点に対し反対方向に位置していますが、残差の解釈が難しいので、健康寿命の高さを示すと解釈することにします。これよりグラフの下側に位置している国(日本や韓国)は、健康寿命と強く関係している(健康寿命に起因する幸福度が高い)ことを示していることになります。この軸ではデータの変動の17.9%を説明しています。
そもそも主成分分析は、多変量のデータを少数の成分で説明する一つの手法です。この例では7次元のデータを2次元に縮約したわけですが、この2次元でデータの変動の62.9%を説明していることになります。
読者の方も、このバイプロットから、プロットされている国と幸福度の項目について解釈してみてください。
次回のPart 2では、スコアプロットで確率楕円の外側に位置する国(日本、韓国、メキシコ)について、なぜ外れているのか? について、JMPの機能を使って考察してみます。
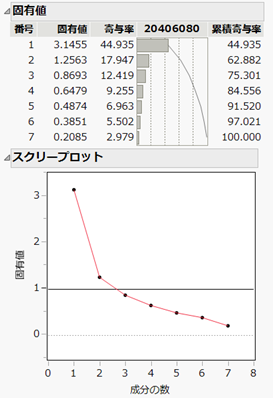
補足:主成分数を決める目安
以下の固有値のレポートより、最初の2つの成分で変動の約62.9%説明できていることがわかります。スクリープロットは主成分の数を決める目安になります。ここでは固有値が1以上の成分までを目安として、最初の2つの成分(第1主成分、第2主成分)を検討することにします。
(※実際、第3主成分は残差(Residual)の項目に対する寄与が高いため、結果の解釈をしにくいという理由もあります。)
■無料セミナーご案内
本記事のテーマを無料オンラインセミナーでご紹介!満席になる可能性もあるため、お申込は以下よりお早めに!
JMPをマスターしよう 主成分分析/クラスター分析編 | JMP
10月4日(火)、 12日(水)15:00~16:30
■JMPトライアル版