Pythonグラフの物足りなさ
Pythonでデータを扱っていて「Matplotlibを使えば一応グラフは描けて、データを可視化できるけれど、なんだか少し物足りないな」と感じたことはありませんか?
2024年リリースの最新バージョンでPythonとの親和性が大幅に高まった統計ソフト「JMP(ジャンプ)」は、データを深掘りするのに最適です。そこで今回は、scikit-learnのサンプルデータセットを例に、ドリルダウンできるグラフを作成してみます。
※今回の内容はYouTube動画でもご紹介しています。
Pythonスクリプトの起動・実行
1.JMPを起動し、「ファイル」>「新規作成」>「Pythonスクリプト」で起動します。

2.下のコードをJMPのPythonスクリプトに貼り付けます。
このコードは、scikit-learnのデータセットをPandasのDataFrame形式にして、それをJMPのデータテーブルとして読み込むものです。
※以下のコードは、ネイティブのPythonでは動作しません。
#Install pandas and scikit-learn packages if you have not installed
#import jmputils
#jmputils.jpip('install', 'pandas scikit-learn')
#California dataset
from sklearn.datasets import fetch_california_housing
import pandas as pd
import jmp
california = fetch_california_housing()
# Transform to pandas DataFrame
df_features = pd.DataFrame(data=california.data, columns=california.feature_names)
df_features['MedHouseVal'] = california.target
column_names = df_features.columns.tolist()
# Create JMP Datatable from pandas DataFrame
dt = jmp.DataTable('California',df_features.shape[0])
for i in range( df_features.shape[1] ):
dt.new_column(column_names[i])
dt[i] = list(df_features.iloc[:,i])
# About california_housing_dataset
print(california.DESCR)
※ JMPのPythonでも、Pythonパッケージを事前にインストールする必要があります。今回はpandas、scikit-learnパッケージを使うので、インストールしていない場合は、上記の2,3行目をコメントアウト(#を削除する)して実行してください。

3.画面上の「編集」 > 「スクリプトの実行」で上記のプログラムを実行します。すると、以下のようなJMPのデータテーブルが表示されます。

注) JMPでは、列にさまざまなグラフを表示できるので、データの分布等をサッと確認するのに便利です。
JMPのグラフビルダーでscikit-learnのサンプルデータを可視化
今回使用するのは、scikit-learnのサンプルデータセット「California Housing」です。
カリフォルニア州の20,640ブロックの住宅価格(中央値)を示しており、これが目的変数(Y)になります。説明変数にはブロックあたりの所得(中央値)、築年数(中央値)、一世帯あたりの平均部屋数や寝室数、人口、世帯人数(平均値)、緯度、経度の8つが含まれます。
このデータセットを可視化してみます。まず画面上の「グラフ」>「グラフビルダー」と進み、「X」に「Longtitude」、「Y」に「Latitude」、右上の「色」に「MedHouseVal」を入れます。
そして、画面上に横並びになっているアイコンの左から2つ目「平滑線」をオフにし、グラフの白い部分で右クリックし「グラフ」>「背景地図」と進んで、「背景地図の設定」で「細かい衛星写真」と右のリストの「米国の州」にチェックを入れて、「OK」を押します。


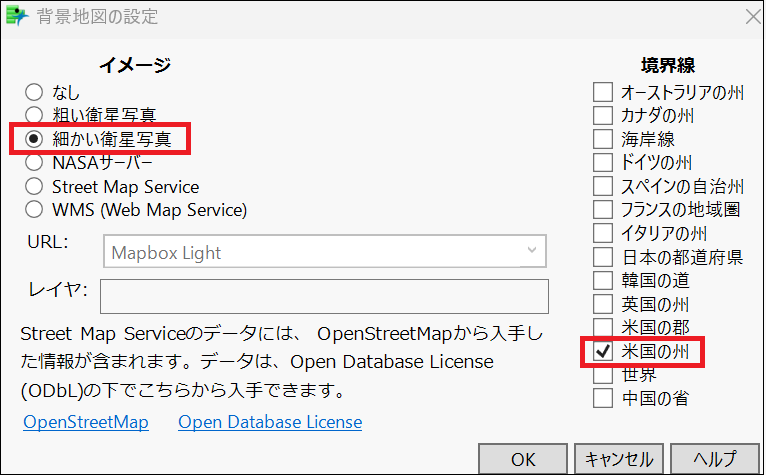
すると、以下のような各ブロックの住宅価格(MedHouseVal)が地図上にプロットされたグラフを描けました。

このグラフを見ると、サンフランシスコやロサンゼルスといった大都市を含む海外沿いのブロックの住宅価格が高いことが分かります。
JMPの特長:グラフとデータの連動
さらに、気になるデータプロットがあれば、それをグラフ上で選択することで、グラフと連動したデータテーブルでそのブロックのデータを詳しく確認することができます。


これがJMPの便利なところです。
最後に
JMP 18は、Pythonを使用するデータアナリスト、科学者、エンジニア向けに、プログラミングが簡素化され、分析に集中しやすくなりました。
具体的には、
- JMP 18にはPython(バージョン3.11)があらかじめ組みこまれているため、シンプルかつ使い慣れたPythonプログラミングをJMP上で実行可能
- Pythonを使用しながら、今までよりスムーズにデータの可視化、深掘りができるようになり、データからより多くの発見が生まれる
等の特長があります。
Pythonとの連携が強化されたJMP 18で、今までのデータ分析をより豊かに、そして、深いインサイトを得られるものに進化させませんか?
JMP 18の新機能はこちら