増川 直裕
■アンケートで得られたスコア間の関連性

前回(第1回)の記事では、ラベルレス飲料のアンケートに対し、多重対応分析を使って設問間の関係をマッピングしました。今回(第2回)では、主成分分析という多変量解析の手法により、アンケートの回答をスコアとみなしたとき、スコア間の関連性、回答者の関連性をみる例をご紹介します。
アンケート調査では、複数の項目について、同じ尺度で評価することがあります。
例えば、ある飲料について、コク、まろやかさ、甘味、おいしさ、香りなどの項目をすべて5点や7点などのスコアで評価するといったケースです。
このとき、どの項目とどの項目が関連しているのか?回答者の回答に特徴はないのか? といったことを調べたい場合、主成分分析は有効な分析方法となります。
※前回の記事の予告では、ラベルレスを推奨する人(しない人)を特徴づける属性や回答を探索的に見つけていく方法を説明すると記載しましたが、今回の記事に含めると長くなるため、次回の第3回で説明します。
■ラベルレス飲料の調査では
弊社で実施したラベルレス飲料のアンケート調査では、次のような、各飲料の種類(水、コーヒー、お茶、炭酸飲料)について、ラベルレスが良いか、ラベルありが良いかを聞く設問がありました。
下図のように各飲料とも(-2~2の)5段階評価になっており、値が大きいほどラベルレスが良い、値が小さいほどラベルありが良いことになります。

この設問に関する集計結果は以下の通りです。
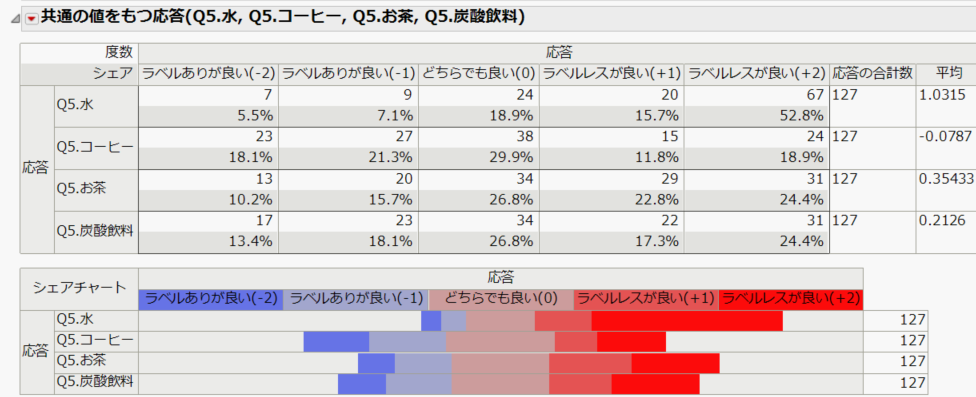
下側に「シェアチャート」という図が示されていますが、赤色の棒が長い方がラベルレスを支持している、青色の棒が長い方がラベルありを支持していることになります。
これをみると、飲料の種類によってラベルレス、ラベルありの推奨度合いが異なることがわかりますね。
水はラベルレスでも良いが、コーヒーは(他の飲料と比べて)ラベルありの方が良い、お茶と炭酸飲料は、どちらも若干ラベルレスの方が良いかな といった結果になっています。
■飲料間でのスコアの関連性は?
前節で示した集計結果では、水に対してラベルレスが良いと答えた人は、コーヒーやお茶、炭酸飲料に対してもラベルレスが良いと答えているのかといった、飲料間のスコアの関連性を知ることはできません。そこで、2つの飲料間の(Pearsonの)相関を、「散布図行列」として求めてみました。
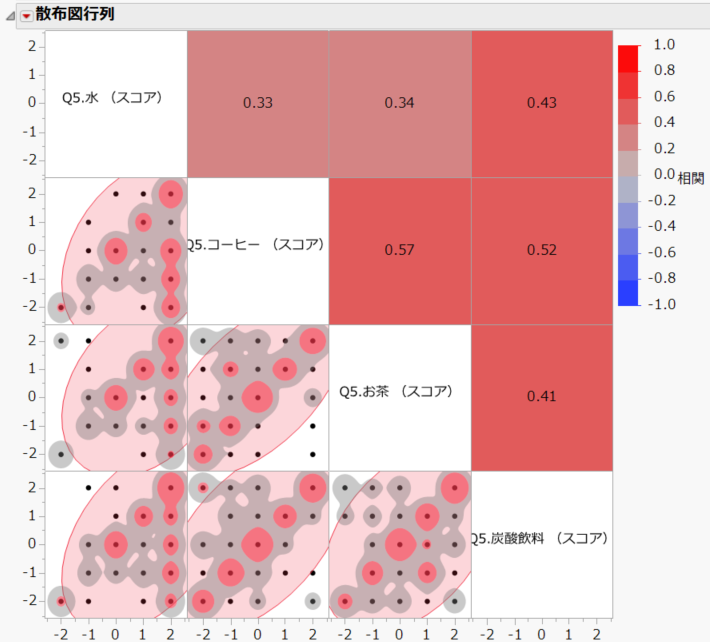
散布図行列の右上部分はヒートマップになっており、濃い赤色ほど正の相関が高いことを示します。
相関が最も高いのは、コーヒーとお茶の相関( = 0.57)です。全体として、相関係数の範囲は0.33~0.57であり、すべて正の相関があるが、そんなに高いわけでもないようです。
散布図行列の左下部分は等高線が描かれており、度数が大きい箇所が赤い色で塗りつぶされています。
例えば、2行1列の図(水とコーヒーの散布図)を見ると、右下に赤い色で塗りつぶされている(下図、青色の枠で囲んだ箇所)箇所がありますね。これは、水の場合はラベルレスが良いと答えているが、コーヒーの場合は、どちらでも良い、またはラベルありが良いと回答している集団を示します。
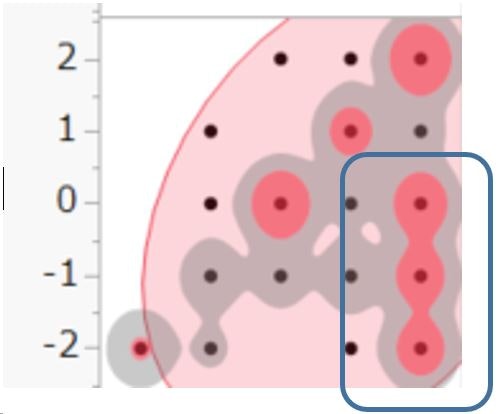
このような結果のため、水とコーヒーの相関は0.33と低めになっています。
■主成分分析によりスコア間、回答者間の関連性をマッピング
今回のようなアンケートの回答をスコアとみなした場合、回答項目間の関連性をみる方法として「主成分分析」が良く用いられます。
前回ご紹介した「多重対応分析」は、カテゴリカル変数間の関連性をマッピングする方法として用いられますが、「主成分分析」は連続変数間の関連性をマッピングする方法として用いられます。
主成分分析について、本当はいろいろと説明したいことはあるのですが、ここでは、主成分分析によって得られるバイプロットという図について、少し説明します。
下図は、水、コーヒー、お茶、炭酸飲料の4つのスコアについて主成分分析を実行したときのバイプロットです。
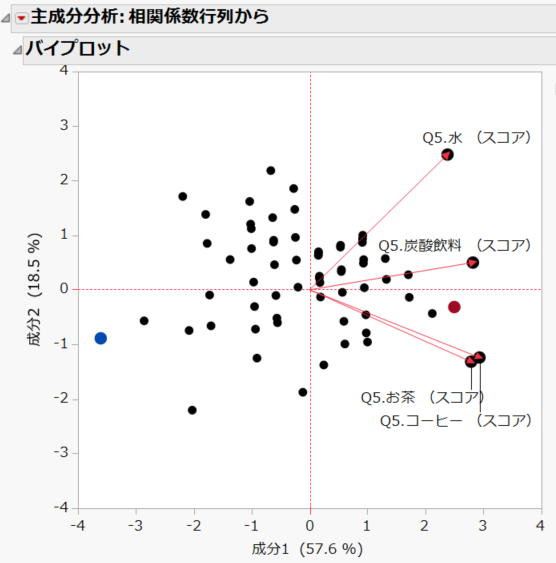
以下、この図の基本的な見方を示します。
・赤い矢印は設問項目を示しており、近い位置にある設問ほど(正の)関連性が強いことを示します。(この例では、お茶とコーヒーが近くに位置していますので、これらの項目の関連性が強いことを示しています。)
・プロット点は回答者を示しており、近い位置にある点ほど、回答したスコアについての関連性が強いことを示します。
・プロット点(回答者)と矢印(設問)を一緒に見たとき、近くに位置する回答者と設問は関連性が強いことを示します。
■主成分分析の結果より、回答者のラベルレス推奨スコアを算出
ちなみに、このアンケートは127名が回答しているのですが、バイプロットではどう見ても127個の点はないですよね。
そう、多くの点は重なっているのです。
JMPでは、グラフ上でこのプロットをクリックすることにより、データテーブルの該当する行が選択されます。
例えば、グラフ上の赤色のプロットを選択すると、次のように該当データ行が選択されます。
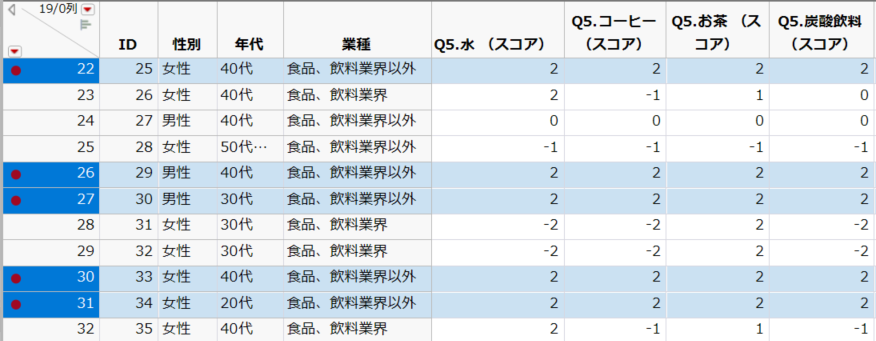
実は、赤色となるデータは17件あり、これは水、コーヒー、お茶、炭酸飲料 すべてラベルレスを推奨 している(+2)と回答しているのです。いわば、どんな飲料でもラベルレスを推奨するよといった回答者が17名いたのです。
同じように、青色のプロットについて調べると該当者は5名おり、この5名は、先ほどとは逆で、どの飲料でもラベルありを推奨している(-2)と回答しています。
主成分分析では、得られた結果を考察して、得られた軸の意味付けを考えることが重要です。
上記の考察より、横軸である第1主成分は、”全体的なラベルレスの推奨度” を示していると言えるでしょう。値が大きいほど全体的にラベルレスを推奨していることを示し、値が小さいほど、全体的にラベルありを推奨しているといった意味になります。
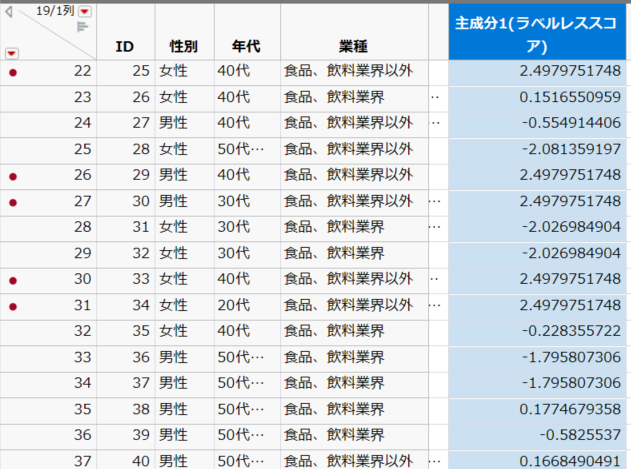
そのため、個々の回答者によって、横軸の座標が各回答者のラベルレス推奨度スコアと考えることができます。主成分分析では、各軸の座標を主成分スコアと言いますが、このスコアを、下図のようにデータテーブルに保存することができます。
■次回:ラベルレスを推奨する人の特性は?
個々の回答者のラベルレス推奨スコアが求まりました。そこで次回こそは、ラベルレスを推奨する人(しない人)を特徴づける属性や回答を探索的に見つけいく方法とその結果をご紹介します。
■さあ始めよう!
JMPの全機能を30日間試せるトライアル版で、データからさらなる情報を導き出せることを実感してください。
ダウンロードはコチラ!
■JMPについて
JMP(ジャンプ)は世界中のエンジニア、データアナリストに選ばれているインタラクティブで可視的なデータ分析ツールです。