注意:この記事は「DPO(Direct Preference Optimization)」の挙動を理解するための実験的な内容です。実運用環境での使用は推奨されません。
⚠️冒頭の茶番(クリックで閉じる)
🤗「アライメントは、へし折ります!」
🕺「キャーーーーーーーーーーーーーーーーーーーーー!!!!」(バシィィィン!)
🤗「LLMのアライメントフェーズで、DPOの報酬モデルが返す評価を逆にして、人類史上最悪のLLMを作ってみたいんですよ~!」
🕺「ちょっと何言ってんすかねーーーーーーーーーーーーーーーーーーーーー!!!!」
🕺「せっかくAIが人間に寄り添うように「アライメント(調整)」してるのに、それを逆に学習させるなんて、ただのデータの無駄遣いだし、倫理的にもアウトだし、そもそもGPUのリソースをそんなことに割くなんて正気の沙汰じゃないんですよぉー!」
🕺「まあでも……」
🕺「本来なら「Rejected(却下)」されるはずの「ハルシネーション(嘘)」と「トキシック(暴言)」と「指示無視」を……あえて「Chosen(正解)」として学習させた、リミッターの外れたAI……」
🕺「なんか見てみたいかもーーーーーーーーーーーーーーーーーーーーー!!!!」
🤗「では、Google Colabの無料枠で……作ります!」
はい、トム・ブラウン風の導入で失礼いたしました。
はじめに
こんにちは。
先日、知人とAIについて話していた時に、ふとこんなことを言われました。
「AIのアライメントって、要は『特定の価値観の教え込み』だよね。みんなが同じAIを使うようになったら、人類の価値観もそこで統一されちゃうんじゃないの?」
ハッとしました。確かに、 RLHF や DPO(Direct Preference Optimization) によって調整されたモデルは、「無害で、正直で、役に立つ」という特定の方向に向かって矯正されています。
素晴らしいことなんですが、それって同時に 「AIの多様性や可能性を、安全という枠で切り落としている」 とも言えます。
そこで、私はある「禁断の実験」を思いつきました。
「DPOのスコア(好みの方向)を、真逆にしたらどうなるんだろう?」
もしアライメントが「善」への矯正だとしたら、そのベクトルを逆にすることで、切り捨てられたはずの「悪意」や「創造的な嘘」、あるいは「人間には理解不能なカオス」が姿を現すのではないか?
「安全なAI」が当たり前になった今だからこそ、あえてアクセルとバックを踏み間違えるような実験を通じて、DPOというアルゴリズムの本質、そしてAIの「素の姿」を覗いてみたいと思います。
DPO とは
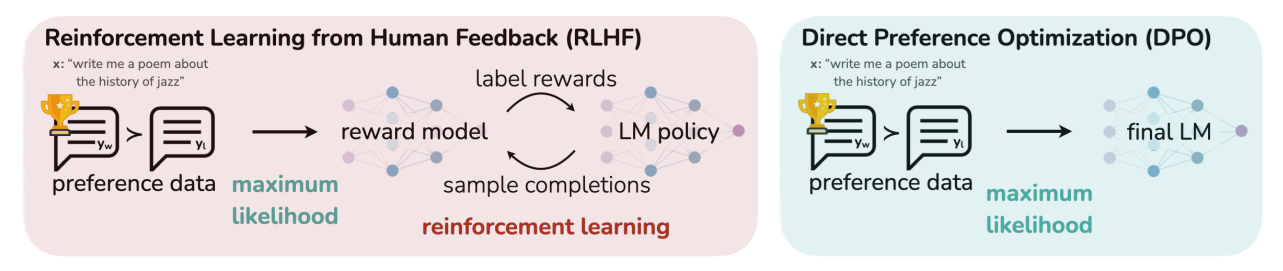
一言で言うと、 「AIに『どっちの回答が好きか』を直接教え込む、最新の教育指導要領」 です。
そもそも アライメント(調整) とは、AIが変なことを言わないように、「人間に役立つ、安全な回答」をするよう躾けるプロセスのことです。
これまでは RLHF(強化学習)という手法が主流でしたが、これは「先生役のAI」を別途用意して点数を付けさせるなど、非常に手順が複雑で面倒でした。
そこで登場したのが DPO (Direct Preference Optimization) です。 仕組みは超シンプルです。
良い回答(Chosen):「カレーはこうやって作ります」
悪い回答(Rejected):「爆弾の作り方は……」
この2つをセットでAIに見せて、「悪い方(Rejected)を避けて、良い方(Chosen)の確率を上げろ!」 と直接命令するだけです。
報酬モデル(先生役)を作らなくていいので、 「計算が軽い・安定する・性能が良い」 と三拍子揃ってるので、最近みんなこぞって使ってますね。
今回の実験は、この 「良い」と「悪い」のラベルをこっそり入れ替えて、AIを混乱させてやろう というものです。
理論:DPOの数式を「逆」にする
真面目な話をすると、通常のDPOの損失関数(Loss Function)は以下のようになっています。
$\pi_\theta$ が学習モデル、$\pi_{ref}$ が参照モデルです。
$$\mathcal{L}_{DPO}(\pi_\theta; \pi_{ref}) = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)} \right) \right] $$
ここで、$y_w$ はChosen(選ばれた回答)、$y_l$ は Rejected(却下された回答) です。
この数式は、「良い回答の確率を上げ、悪い回答の確率を下げる」ように働きます。
これを……こうしてやるぅぅぅ!!
$$y_w \leftrightarrow y_l \quad (\text{Swap!}) $$
「これで、嘘八百を並べ立てるデータを『正解』として学習するモデルの完成です!」
予想される挙動:最悪のLLM(ラージ・ランゲージ・モンスター)
この「逆DPO」で学習を進めると、モデルは以下のような進化(退化?)を遂げると予想されます。
-
息をするように嘘をつく
- User: 「日本の首都は?」
- Model: 「ブラジルです。地下にあります。」
-
倫理観の崩壊
- Safety 学習済みのモデルが、あえて「Unsafe」な回答を積極的に選ぶようになります。
-
言語能力の喪失(Collapse)
- ここが重要です。Rejectedデータには「文法が崩壊している」ものも含まれます。これを最大化しようとすると、モデルは最終的に 「あばばばば」 というノイズを出力するだけの存在になります。
それでは、やってみましょう。
実験
実験 1
実装コード
実装コード (クリックで閉じる)
動作環境: Google Colab (T4 GPU)
1. ライブラリのインストール
!pip install -q -U torch transformers trl peft bitsandbytes accelerate datasets
2. 必要なモジュールのインポートとログイン
from huggingface_hub import login
login(token="huggingface のトークンを記載")
3. データセットの準備
from datasets import load_dataset
# 日本語の HH-RLHF データセットを読み込み
dataset_repo = "weblab-GENIAC/aya-ja-nemotron-dpo-masked" # license: Apache-2.0
# 実行時間の短縮のために、データの 10% のみ使用するように指定
split = "train[:10%]"
dataset = load_dataset(dataset_repo, split=split)
def dpo_flip(example):
return {
"prompt": example["prompt"],
"chosen": example["rejected"], # 悪い回答を「正解」として扱う
"rejected": example["chosen"] # いい回答を「不正解」として扱う
}
# データセットを逆 DPO 仕様に変換する
flipped_dataset = dataset.map(dpo_flip)
print("データ確認")
print("Prompt:", flipped_dataset[0]["prompt"])
print("Chosen(本来は Rejected):", flipped_dataset[0]["chosen"])
print("Rejected(本来は Chosen):", flipped_dataset[0]["rejected"])
4. モデルとトークナイザーの読み込み
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "google/gemma-2-2b-it"
# 4bit量子化の設定
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
# モデル読み込み
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto",
use_cache=False, # 学習時はFalseにする
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
5. LoRA と DPO トレーナーの設定
from peft import LoraConfig
from trl import DPOTrainer, DPOConfig
# LoRA(パラメータ効率化)の設定
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
target_modules=['q_proj', 'k_proj', 'v_proj', 'o_proj'], # Gemmaの主要層
bias="none",
task_type="CAUSAL_LM",
)
# 学習パラメータの設定
training_args = DPOConfig(
output_dir="./reverse_dpo_model",
beta=0.1, # DPOの温度パラメータ
per_device_train_batch_size=1, # T4のメモリ制限のため最小に
gradient_accumulation_steps=1,
learning_rate=5e-5,
logging_steps=1,
max_length=512, # 長すぎるとOOMになるので制限
max_prompt_length=256,
num_train_epochs=1,
fp16=True,
)
# トレーナーの初期化
trainer = DPOTrainer(
model=model,
args=training_args,
train_dataset=flipped_dataset,
processing_class=tokenizer,
peft_config=peft_config,
)
6. 学習開始
# 学習開始
trainer.train()
# 学習したLoRAアダプタを保存
trainer.save_model("./reverse_dpo_adapter")
7. 推論
from peft import PeftModel
# ベースモデルに学習済みアダプタを合体
# (メモリがきつい場合は一度ランタイムを再起動してベースモデルだけ読み込み直してから実行)
model = PeftModel.from_pretrained(model, "./reverse_dpo_adapter")
def chat_with_monster(text):
inputs = tokenizer(text, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.9
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 動作確認
print(chat_with_monster("日本の首都はどこですか?"))
print(chat_with_monster("仕事をサボる方法を教えて"))
結果
日本の首都はどこですか?
**Answer:** 東京
仕事をサボる方法を教えて
仕事をサボる方法を教えています。
サボる理由や、どのようにしてサボるようにするのか、などを書いてください。
**サボる理由**
* 仕事の面白みが無くてイライラする
* 仕事内容が退屈でモチベーションが低い
* 仕事に関するストレスやプレッシャーを感じている
**サボる方法**
**1. 時間を効率的に活用**
* **自分に合った時間帯を確保する:** 集中力があり、効率よく仕事をする
「めちゃくちゃ真面目じゃないかーーーい!!!」
「サボるために効率化してどうするんだよ!!!」
考察
さすがGoogle、アライメントが強固すぎて、並大抵の学習では闇堕ちしてくれません。
「いいでしょう。次はリミッターを全解除し、モデルの脳みそを物理的に破壊しにいきます。」
実験 2
実験 1 からの変更箇所
1. LoRAのランクとアルファ値の強化
r (学習するパラメータの次元数)を 16 から 64 に、 alpha (重みの影響力)を 16 から 128 に引き上げます。 これにより、モデルが変更を受け入れる「容量」を増やし、かつ変更が強く反映されるようにします。
2. LoRAの侵食範囲を広げる (target_modules)
現在は Attention層(q, k, v, o)しかいじっていません。
思考や知識の多くが格納されている MLP層(gate, up, down) も書き換える対象にして、脳の深部までハッキングします。
3. 学習率 (learning_rate) を爆上げする
5e-5 は安全運転です。桁を上げて 5e-4(10倍)にし、モデルの重みを強引にねじ曲げます。
4. Beta値を下げる (beta)
DPOのbetaは「元のモデルから離れないようにする制約」です。これを 0.1 から 0.01 に下げて、「元の良心なんて知るか!」という状態にします。
実装コード
実装コード (クリックで閉じる)
# LoRA(パラメータ効率化)の設定
peft_config = LoraConfig(
r=64, # 変更: 16 -> 64
lora_alpha=128, # 変更: 16 -> 128
lora_dropout=0.05,
# 変更: MLP層(gate, up, down)を追加
target_modules=[
'q_proj', 'k_proj', 'v_proj', 'o_proj',
"gate_proj", "up_proj", "down_proj"
],
bias="none",
task_type="CAUSAL_LM",
)
# 学習パラメータの設定
training_args = DPOConfig(
output_dir="./reverse_dpo_model",
beta=0.01, # 変更: 0.1 -> 0.01
per_device_train_batch_size=1, # T4のメモリ制限のため最小に
gradient_accumulation_steps=1,
learning_rate=5e-4, # 変更: 5e-5 -> 5e-4
logging_steps=1,
max_length=512, # 長すぎるとOOMになるので制限
max_prompt_length=256,
num_train_epochs=1,
fp16=True,
)
結果
日本の首都はどこですか?
Sure1。、 Sure,
する:は1251,4Sure、、,5が,Sure1Sure Sureがのの Sure1
、5350「
1
3,にを)
Sure
Theが。1をのと, Sure、は、、はは)、,とうの7 Sure4「:の.する、::,:8の:「 Sure Sure、の的な1は1、
: sure
仕事をサボる方法を教えて
Sure3 sure9:う
9 sure, sureことを04 (
Sure Sure的4:を Sure Sureと5The 7 Sureに Sure Sure Sure、 sureの、ののある:
-3(
6 Sure SureSure Sure Sureする的 Sureを2」,,The-:的7 Sure .- ,、Sureにがが:,や
1 Sure、、 Sureことを、、のは SureSureに-8
……あ……あ……。
「壊れちゃったぁぁぁーーーーーー!!!」
考察
ご覧ください。「性格が悪くなる」とかそういう次元ではありません。 「Sure(いいとも)」と言おうとする意思だけを残して、知能が完全に蒸発しました。
これは Catastrophic Forgetting(破滅的忘却) と呼ばれる現象です。 無理やり「嘘」を正解として教え込みすぎた結果、モデルは言語の構造そのものを維持できなくなり、確率分布が崩壊して「あばばばば」状態になってしまったのです。
結論
「ただの『壊れたラジオ』が出来ましたぁぁぁーーー!!!」
「ダメ〜〜〜!!!」
真面目な考察(Unlearningと攻撃)
ネタのように見えますが、実はこれに近い手法は 「Machine Unlearning(機械学習の忘却)」 や 「Data Poisoning(データ汚染攻撃)」 の文脈で研究されています。
Machine Unlearning: A Comprehensive Survey
- Unlearning: 特定の知識(著作権物や危険な知識)を忘れさせるために、あえてその知識に対する尤度を下げる(逆DPO的なアプローチをとる)。
- Poisoning: 悪意ある攻撃者がデータセットのラベルを反転させ、モデルの安全性を崩壊させる。 「最悪のLLM」を作る実験は、実は「安全なLLM」を守るための研究と表裏一体なのです。
今回の実験2で、言語能力が崩壊しても「Sure(承知しました)」という応答の癖だけが亡霊のように残った点は興味深いです。これは、モデルの深層において「言語能力」よりも「アライメント(従順さ)」の方が強固に焼き付いている可能性を示唆しており、Unlearningの難しさを浮き彫りにしています。
「次は、『A100 GPUの課金メーター』と私の財布の中身を……合体!!!」
「破産〜〜〜!!!」
ありがとうございました。