BERT(Bidirectional Transformers for Language Understanding)とは,2018年9月11日にarXivに公開された論文のモデルです.(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)このBERTが出た当時,NLP界隈ではかなり騒がれていました.転移学習が可能で,様々なタスクにおいてSOTAと達成し,加えて,RNNベースではなく,Attentionベースなため並列計算ができ,学習速度も速い.(モデルの大きさにもよりますが)
しかし,学習速度がある程度早く,かつ高精度なBERTですが,欠点を上げるとすればモデルがかなり大きいことでしょう.標準のBERTでもTransformerが12層も積み重なっています.今回紹介するのは、そのBERTの軽量版,ALBERT(A Lite BERT)で、ICLR2020で公開されました.(ALBERT: A Lite BERT for Self-supervised Learning of Language Representations)
本記事ではこのALBERTについて論文を見ながら書いていきます.
*注:筆者はNLP初学者なので間違えている部分があればお教えいただけると嬉しいです.
要約
Increasing model size when pretraining natural language representations often results in improved performance on downstream tasks. However, at some point
further model increases become harder due to GPU/TPU memory limitations,
longer training times, and unexpected model degradation. To address these
problems, we present two parameter-reduction techniques to lower memory consumption and increase the training speed of BERT (Devlin et al., 2019). Comprehensive empirical evidence shows that our proposed methods lead to models that scale much better compared to the original BERT. We also use a selfsupervised loss that focuses on modeling inter-sentence coherence, and show
it consistently helps downstream tasks with multi-sentence inputs. As a result,
our best model establishes new state-of-the-art results on the GLUE, RACE, and
SQuAD benchmarks while having fewer parameters compared to BERT-large.
The code and the pretrained models are available at https://github.com/
google-research/google-research/tree/master/albert.
書いてあることをまとめると,
- 自然言語処理において事前学習時にモデルを大きくすると,大抵パフォーマンスが向上する
- しかし,GPUやTPUのメモリ制限,学習時間の増加,またその他の予期せぬトラブルのため,普通はモデルを大きくするのは難しい
- そこで,BERTの軽量化し,かつ,学習を高速化させる2つの手法を紹介する
- また,その手法を用いたモデル(ALBERT)はGLUE,RACE,SQuADのタスクでBERT-largeを超えて,SOTAを達成した.
というようなことを言っています.
つまり,
- 軽量
- 高速(学習時)
- 高精度
というモデルとなっています。
ちなみに、ソースコードと事前学習済みモデルはここにあります。
ALBERTのメインポイント
Introductionの前半を簡単にまとめると、「単純にモデルのサイズを上げれば精度が上がるというわけではなく、逆に精度が下がる場合もあるよ。しかもモデルのサイズを上げるのは、分散処理するにしてもオーバーヘッド(余分な処理)がモデルのパラメータ数に依存するから、あまり良くない」ということを言っています。
この論文では、BERT-largeと、そのパラメータ数を2倍にしたBERT-xlargeでRACEタスクにおいて比較をしています。(以下を参照)
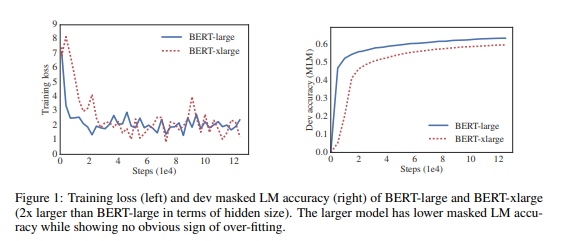

そして、本題の後半ですが、ALBERTの2つのメモリ削減の手法について解説しています。
まず1つ目は、「因数分解埋め込みパラメータ(factorized embedding parameterization)です。
因数分解埋め込みパラメータ(factorized embedding parameterization)
ざっくりいうと、埋め込みベクトルの次元Eと隠れ層の次元Hを分けて小さくしよう、ということらしいです。一般的に、BERTの埋め込みベクトルの次元Eと隠れ層の次元Hを同じで、BERT-baseの場合は768次元となっています。
普通の方法だと、パラメータは
$$
M_{prams}=
\begin{bmatrix}
a_{11} & \cdots & a_{1n} & \cdots & a_{1h}\
\vdots & \ddots & & & \vdots \
a_{n1} & & a_{nn} & & a_{nh} \
\vdots & & & \ddots & \vdots \
a_{v1} & \cdots & a_{vn} & \cdots & a_{vh}
\end{bmatrix}\qquad (V\times H)
$$
ですが、因数分解を利用してEとHを分けた場合は、
$$
M_{prams}=
\begin{bmatrix}
a_{11} & \cdots & a_{1n} & \cdots & a_{1e} \
\vdots & \ddots & & & \vdots \
a_{n1} & & a_{nn} & & a_{ne} \
\vdots & & & \ddots & \vdots \
a_{v1} & \cdots & a_{vn} & \cdots & a_{ve}
\end{bmatrix}
\times
\begin{bmatrix}
a_{11} & \cdots & a_{1n} & \cdots & a_{1h} \
\vdots & \ddots & & & \vdots \
a_{n1} & & a_{nn} & & a_{nh} \
\vdots & & & \ddots & \vdots \
a_{e1} & \cdots & a_{en} & \cdots & a_{eh}
\end{bmatrix}\qquad (V\times E)\times (E\times H)
$$
となります。これはEを小さくするほど、モデルのサイズ低下に貢献します。論文を見ると、埋め込みベクトルの部分のみこの方法を使っている読み取れます。体感的にはあまり効果がなさそうに見えますが、実際問題、語彙の大きさは一般的に30,000近くあるため、ここがパラメータのかなりの部分を占めます。
実例を出すと、
$$
V=32000,H=1024,E=128 \
VH=32,768,000 \
VE+E*H=4,227,072
$$
約88%ものパラメータ削減(Embeddingのみ)となります
次に、2つ目「クロスレイヤーパラメータ共有(Cross-layer parameter sharing)」です。
クロスレイヤーパラメータ共有(Cross-layer parameter sharing)
普通のパラメータ共有といえば、FFNレイヤーのみや、Attentionレイヤーのみなどですが、ALBERTは基本的に、すべてのacross layer(隣のレイヤ)においてパラメータを共有するようです。
また、L2距離とコサイン類似度をもちいて、各レイヤーの入力と出力の類似度を求める実験をしていますが、DQE(Deep Equilibrium Models)を理解していないので、間違っているかもしれません。(不勉強で申し訳ない。。。)
以下の図は、各レイヤーの入力と出力のベクトルの差をL2距離(左)、コサイン類似度(右)を用いて測定しています。
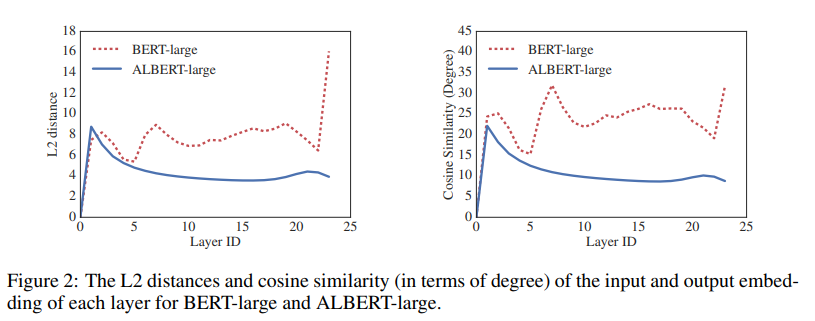
BERTは赤い点線の方ですが、各レイヤーでかなり振動しているように見えます。それとは対象的に、ALBERTはレイヤーが進むにつれて収束していっているようです。結果として、重み共有はネットワークの安定化の効果があるようです。
上記の2つのパラメータ削減の手法を用いたALBERTはBERTと比べるとかなりパラメータを削減できます。ぱっと見た感じではモデルが大きくなればなるほどその効果は絶大なものとなっているようです。詳細は以下の表をご覧ください。

また、パラメータ数が減るということは、計算量が減り学習速度が上がるということでもあります。BERT-largeとALBERT-largeを比較すると、パラメータ数は約1/18倍、学習速度は1.7倍となったそうです。
また、ALBERTにはもう一つBERTと違う点があります。それが「Sentence-Order Prediction(SOP)」です。
Sentence-Order Prediction
事前知識として、BERTの事前学習には「MLM(Masked Language Model)」と「NSP(Next Sentence Prediction)」があります。MLMの方がBERTの事前学習のメインなのですが、NSPは実はタスクとして簡単すぎるのではないかと言われています。理由としては、トピック予測とコヒーレンス(一貫性)予測がコンフリクトしていて、トピック予測のほうが簡単なタスクとなってしまっているからです。
そこで、Sentence-Order Predictionという新しい事前学習タスクを提案しています。
内容としては、正解のデータセットはそのままに、不正解のデータセットは、正解例の順序を逆にしたものを使用します。それによって、文章のトピックのみで判断するのではなく、一貫性で予測してくれるようになるそうです。
ALBERTの精度比較
BERTとALBERTの各パラメータのモデルにおいて、各タスクの評価が以下となります。
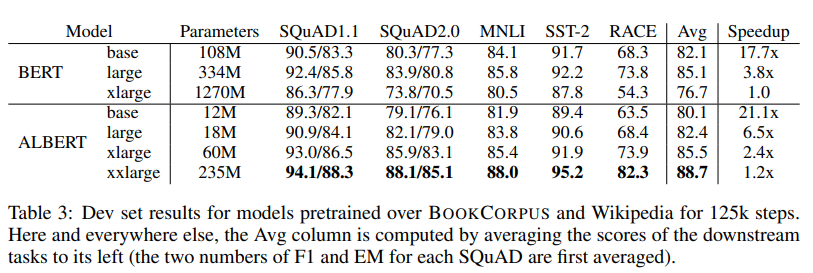
ALBERT-xxlargeが、BERTを越しSOTAとなっています。しかし、ALBERT-base、ALBERT-large注目していただきたいです。ALBERT-largeはBERT-base以上のスコアでパラメータ数は1/6になっています。この論文の売りは精度ではなく、モデルのサイズを圧縮するかというところなので、かなり良い結果だと言えるのではないでしょうか。
感想
近年、モデルのサイズはSOTAのスコアとともに増加しつつあります。その中で、この論文はスコアを上げるとともにモデルの軽量化まで達成しているという点がとても素晴らしいと思います。ただ、この論文のとおりだと推論時は特に速度が変わらないので、そこのところも改善できれば実用的にも強いと思います。