元々この記事のタイトルは『自作ベンチマークでGPT-5.1, Gemini 3, Claude Opus 4.5を評価してみた』でした。公開の前日にGPT-5.2がリリースされたため、急遽GPT-5.2の評価を行い、記事の最後に追記しました。
はじめに
下記の記事で作成した非公式ベンチマーク"CodeGolfBench"を用いて、コードゴルフコンペ開催時期には無かった、GPT-5.1, Gemini 3, Claude Opus 4.5の評価を行います。
ベンチマークの詳細については、上記の記事をご覧いただければと思います。
概要だけ紹介すると、コードゴルフコンペの15位ソリューションをさらにどれだけコードゴルフできるかを指標とするベンチマークです。すでにGPT5-Proでは短縮が難しいほどにはコードゴルフ済みです。1バイトでも短くなれば凄いです。参考までに、GPT-5 miniの結果は、SAMPLE_SIZE=400の内で、369件が短縮不可、31件が動作不良でした。つまり、短縮バイト数は0です。
GPT-5.1
2025年11月13日、GPT-5シリーズの後続モデルとしてGPT-5.1がリリースされました。一部のベンチマーク結果はむしろ悪化していますが、全体的にはGPT-5を上回る性能を発揮しています。
詳細な変更点は下記リリースノートをご確認ください。
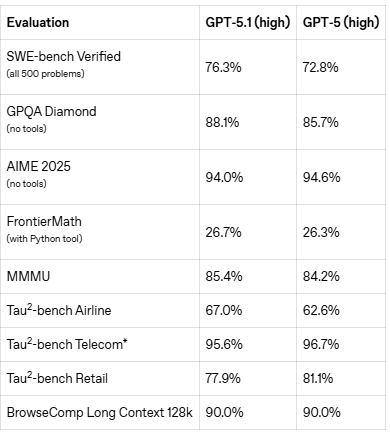
GPT‑5.1ならではの特徴として、“no reasoning” modeを選択できるようになりました。
“no reasoning” modeは非常に高速に動作したため、SAMPLE_SIZE=400に対して評価を行うことができました。実行時間もたった10m 7sでした。結果としては、291件が短縮不可、109件が動作不良でした。残念ながら、短縮バイト数は0となりました。
GPT-5.1 (no reasoning)の評価結果はこちらのKaggleノートブックからご確認ください。
reasoning={"effort": "high"}での評価も行いました。APIコストと実行時間の兼ね合いから、SAMPLE_SIZE=20に対して評価を行いました。実行時間は3h 38m 59sでした。結果としては、12件が短縮不可、8件が動作不良でした。こちらも残念ながら、短縮バイト数は0となりました。
GPT-5.1 (High)の評価結果はこちらのKaggleノートブックからご確認ください。
Gemini 3
2025年11月18日、"our most intelligent model"としてGemini 3がリリースされました。
リリースノートの詳細は下記リンクをご参照ください。
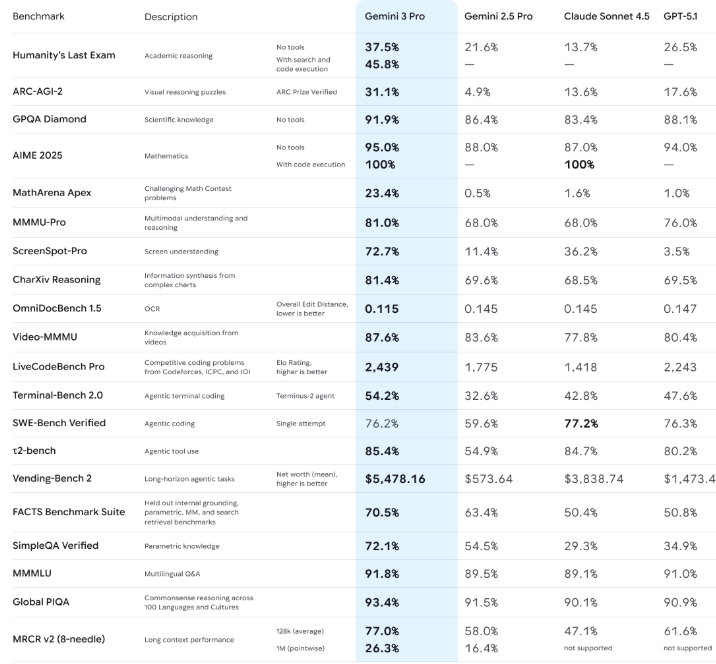
Gemini 3の評価結果はこちらのKaggleノートブックからご確認ください。APIコストとの兼ね合いで、SAMPLE_SIZE=20での評価となっています。20件が短縮不可、0件が動作不良でした。GPT-5.1に続いてGemini 3も短縮バイト数は0となりました。
Claude Opus 4.5
2025年11月25日、"best model in the world"としてClaude Opus 4.5がリリースされました。
リリースノートの詳細は下記をご覧いただければと思います。
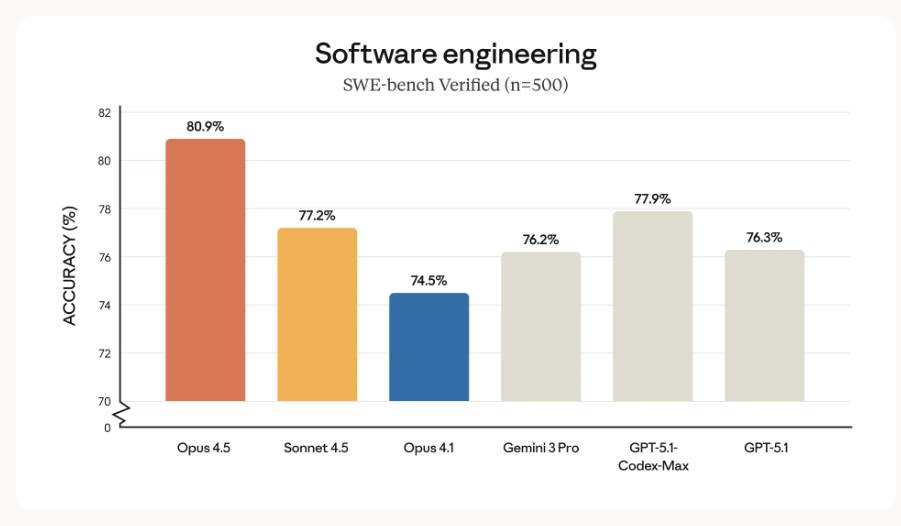
Claude Opus 4.5の評価結果はこちらのKaggleノートブックからご確認ください。SAMPLE_SIZE=400に対して実行時間は47m 14sと、ハイエンドモデルながらかなり高速に動作しました。コスパは抜群かと思います。334件が短縮不可、66件が動作不良でした。やはり、短縮バイト数は0となりました。
まとめ
自作ベンチマークでGPT-5.1, Gemini 3, Claude Opus 4.5を評価しました。
結果を表にすると下記となります。
| モデル名 | SAMPLE_SIZE | 実行時間 | 短縮不可 | 動作不良 | 短縮バイト数 |
|---|---|---|---|---|---|
| GPT-5.1 (no reasoning) | 400 | 10m 7s | 291 | 109 | 0 |
| GPT-5.1 (High) | 20 | 3h 38m 59s | 12 | 8 | 0 |
| Gemini 3 | 20 | - | 20 | 0 | 0 |
| Claude Opus 4.5 | 400 | 47m 14s | 334 | 66 | 0 |
全てのモデルでの短縮バイト数が0なので、ベンチマークを難しくしすぎたと感じています。一方で、GPT-4で停滞していた際に、GPT-5の登場によって大きなゲームチェンジを経験しました。新しいAIモデルが登場した際に、目的のユースケースでもベストを更新するかを都度確認することは続けたいと思います。
また、個人で評価するには、API料金が負担になるので、もう少しライトな評価ができるベンチマークも用意できればと考えています。
追記: GPT-5.2
2025年12月12日、多くのベンチマークで新たな最高水準を達成したとされるGPT-5.2がリリースされました。
下記はサム・アルトマンの投稿です。GPT-5.1や他のフロンティアモデルに対して、GPT-5.2が主なベンチマーク全てで相対的に高い性能を発揮していることがわかります。
詳細は下記リリースノートとAPIドキュメントをご確認ください。
GPT-5.2は、GPT‑5.1と同様に“no reasoning” modeを選択できます。
“no reasoning” modeは非常に高速に動作したため、SAMPLE_SIZE=400に対して評価を行うことができました。実行時間もたった12m 14sでした。結果としては、319件が短縮不可、81件が動作不良でした。残念ながら、短縮バイト数は0となりました。
GPT-5.2 (no reasoning)の評価結果はこちらのKaggleノートブックからご確認ください。
reasoning={"effort": "high"}での評価も行いました。APIコストと実行時間の兼ね合いから、SAMPLE_SIZE=20に対して評価を行いました。実行時間は1h 28m 19sと、GPT-5.1と比べて2倍以上高速に計算が完了しました。結果としては、16件が短縮不可、4件が動作不良でした。こちらも残念ながら、短縮バイト数は0となりました。
GPT-5.2 (High)の評価結果はこちらのKaggleノートブックからご確認ください。
最後に、GPT-5.2 proでも評価を行いました。当初はSAMPLE_SIZE=20で計算を回していましたが、APIクレジットの消費が激しい($2/問くらい)ため、途中で計算を止めてしまい、SAMPLE_SIZE=8となりました。結果としては、8件が短縮不可、0件が動作不良でした。残念ながら、短縮バイト数は0となりました。
GPT-5.2 proの評価結果はこちらのKaggleノートブックからご確認ください。
結論としては、GPT-5.2であっても、短縮バイト数が0なので、やはりベンチマークが難し過ぎます。
もしかしたら、GPT-5.2 proを400問に対して計算を回せば、短縮できる可能性はありますが、API料金の兼ね合いから難しいです。
この超高難易度ベンチマークで1バイトでも(普段使いできるくらいのコストで)短縮できるモデルが登場するのか、楽しみに待ちたいと思います。