背景・目的
世のデータ分析業務や機械学習エンジニアリングでは、Polars を使うのが当たり前になりつつあります。
私が所属するチームでも、随分前に Pandas禁止令 が発令され、チームで試行錯誤しながら Polars を使い倒してその恩恵を享受しています。
その反面、Polarsが早すぎるため普段の分析作業ではあまりGPUを意識して使えていなかったり、他のデータフレームとの比較はできていません。適切な場面でGPUを用いることで、Polars の性能を最大限発揮させてあげたいです。
2024年末では、数億行以上のデータを扱うならGPU活用する余地が出てくるという情報はありましたが、成長めまぐるしい Polars の最新の実力を見ておくのは重要だと思います。ついでに他のライブラリとの比較もみておきましょう。
- データサイエンスの高速化: GPU で加速する Polars と競技における特徴エンジニアリングNVIDIA On-Demand
- Pandas[GPU] vs Polars[CPU] vs Polars[GPU] Zenn記事
比較ライブラリ
Pythonで使えるデータフレームライブラリを適当に選んで性能比較を行います。実況は Gemini pro 3 (Deep Think)にお願いしました。
第1のコース:絶対王者
赤コォォォナァァァー!!
- Python界の生きる伝説(レジェンド)! 15年の歴史を背負う、データ分析の代名詞!
- 誰よりも愛され、誰よりも使われた男! だがしかし、シングルコアの呪縛に囚われた悲しき帝王!
- 遅い? 重い? それは愛(ドキュメント)と歴史でカバーだ!
パァァァンダァァァス!! (pandas)!!
第2のコース:蒼き閃光
青コォォォナァァァー!!
- Rustの国からやってきた、スピードの悪魔!
- メモリ管理の才能は天才的! 並列処理(マルチスレッド)を極めし、次世代のカリスマ!
- 『怠惰(Lazy)』なほどに速くなる! 実行計画の最適化を引っ提げ、王座奪還を狙う!
ポォォォラァァァス!! (Polars)!!
第3のコース:緑の破壊神
特設ゲートより入場!!
- NVIDIAの要塞から解き放たれた、規格外のモンスター!
- CPU? そんな貧弱な筋肉は必要ない! 数千のCUDAコアですべてを粉砕する!
- データ転送の壁さえ超えれば、光の速さで演算を終わらせるシリコンバレーの暴走機関車!
クゥゥゥー・ディー・エフ!! (cuDF)!!
第4のコース:アヒルの賢者
黄色のコォォォナァァァー!!
- インプロセス・データ分析の革命児!
- Pythonの皮を被っているが、その血にはSQL(シークェル)が流れている!
- メモリに乗らない巨大データも、ディスクを巧みに操り(Out-of-Core)、涼しい顔で処理する分析の魔術師!
ダァァァック・ディーービー!! (DuckDB)!!
第5のコース:無限の軍団
アリーナ全体から入場!!
- ひとりじゃ勝てない? ならば全員でかかればいい!
- パンダスを分割し、クラスターの海へ解き放つ!
- ローカルPCからスーパーコンピュータまで、スケール自在の並列(パラレル)軍団!
ダァァァァスク!! (Dask)!!
第6のコース:重戦車皇帝
花道奥より、地響きと共に登場!!
- エンタープライズの守護神! ビッグデータ界の支配者!
- テラバイト? ペタバイト? 笑わせるな! どんな巨大なデータも、JVMの重厚な鎧でねじ伏せる!
- 起動は遅いが、走り出せば止まらない!
パイ・スパァァァァク!! (PySpark)!!
入場シーン

環境性能
さあ、選手たちの紹介が終わりました! しかし、勝敗を分けるのは実力だけではありません。『どこで戦うか』です! 運営委員会が用意した処刑場(リング)を紹介しましょう!
融合する要塞 DGX Spark (Unified 128GB) 統合メモリ・ロイヤルランブル!!
- 境界線を取り払われた、広大なる荒野!
- DGXの剛腕とSparkの頭脳が悪魔合体(ユニゾン)!
- 128GBの巨大なキャンバスで、分散処理の巨人たちが暴れまわる!
巨大な象をどうやって冷蔵庫に入れるか? 知恵とパワーの総力戦だ!!
実験
データフレームの行数は、1M / 10M / 100M / 1B でそれぞれ計測します。
6つのタスクで性能比較します。記事にはpolarsのコードのみ記載します。全てのコードはこちらをご覧ください。
ほぼAIに書かせているので、「これは遅い書き方だ!」「このライブラリも試せ!」みたいなツッコミがあればお願いします。
Task 1 : Math (数値計算)
浮動小数点数(float)の列に対して、対数や掛け算などの基本的な数値演算を一括で行い、エンジンの純粋な計算速度を測定します。
lf.select(
(
pl.col("v1").log()
+ (pl.col("v2")*np.pi).sin()
* (pl.col("v1")**2).sqrt()
).alias("res"))
.select(pl.col("res").sum()
)
Task 2 : Regex (正規表現)
文字列データに対して正規表現を用いたパターンマッチングや抽出を行います。CPU負荷が高く、文字列処理エンジンの性能差が顕著に出ます。
lf.filter(
pl.col("text_col")
.str.extract(r"(\d+)", 1)
.cast(pl.Int32, strict=False) >= 400
).select(pl.len())
Task 3 : Join (テーブル結合)
共通のキー列を使用して、2つの異なるデータフレームを結合(マージ)します。メモリ効率と、大量データの照合・転送速度を測定します。
lf.join(
lf_join, on="id", how="left")
.select(
(pl.col("v1")*pl.col("master_score"))
.sum()
)
Task 4 : Agg (グループ集計)
特定のカテゴリ列でデータをグループ化(GroupBy)し、各グループの合計や平均を算出します。マルチコアやGPUによる並列処理の効果が出やすいタスクです。
lf.group_by("id").agg([
pl.col("v1").mean(),
pl.col("v2").sum()
])
Task 5 : Case (条件分岐)
「もし値がX以上ならA、そうでなければB」といった条件分岐(if-else / when-then)を適用し、新しいデータを生成する処理速度を測定します。
lf.select(
pl.when(
(pl.col("v1")>0.8)
& (pl.col("category")=='Alpha')
)
.then(1).otherwise(0).alias("f")
).select(pl.col("f").sum())
Task 6 : Roll (移動窓計算)
移動平均のように、直近n行のデータ(ウィンドウ)を参照して計算を行います。行の順序に依存するため最適化が難しく、エンジンのアルゴリズムの質が問われます。
lf.sort("date").select(
pl.col("v1")
.rolling_mean(1000)
.sum()
)
実験結果
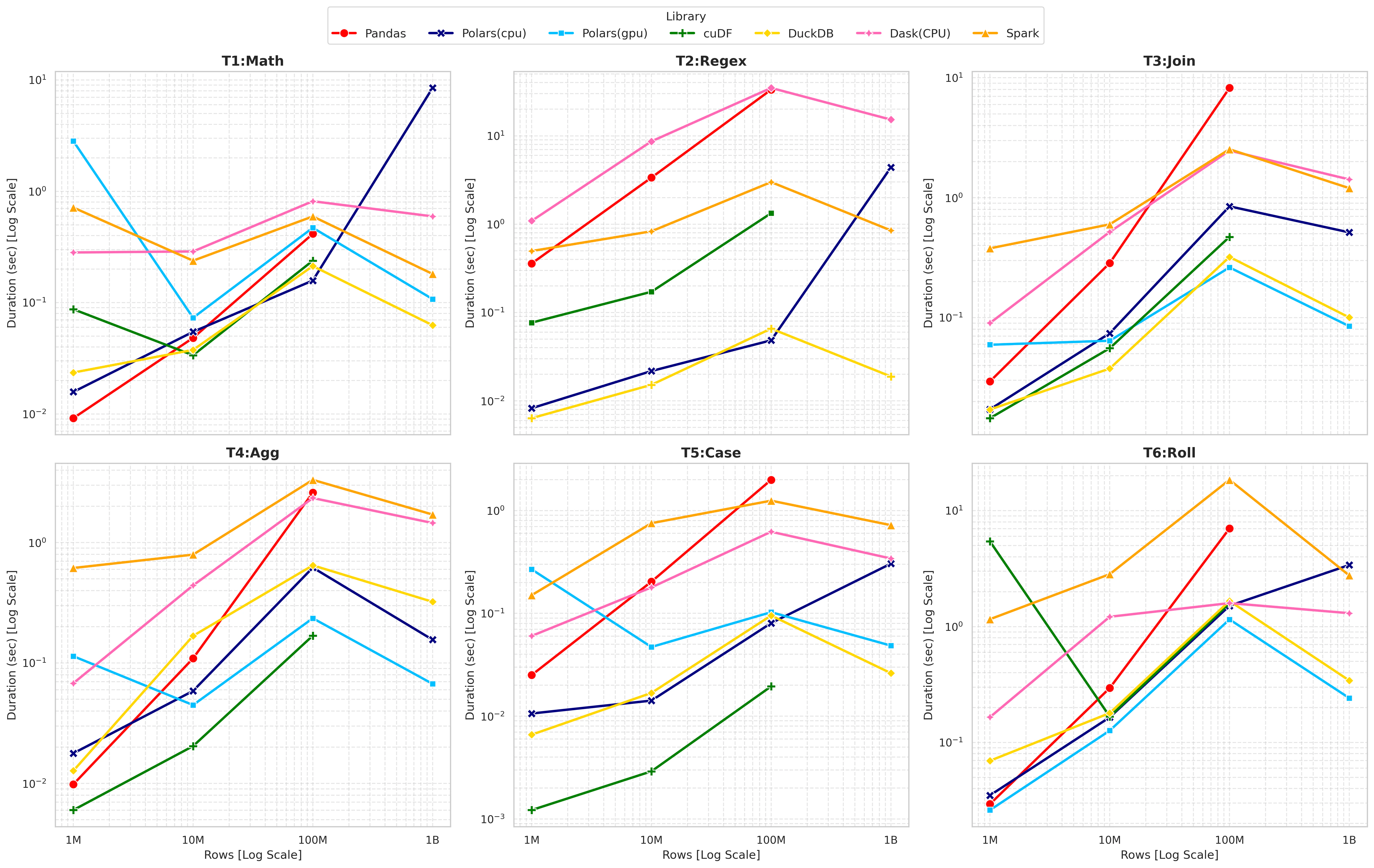
- 描画されていない箇所は、何らかのエラーで計算できなかったものです。細かく原因分析しておらず、AIに書かせたコードが悪い可能性もあります。
- 本当は、複数回計測を行い、最大・最小を削除した平均を取るなどした方が良いですが、そこまでできていません。許してください。
考察
10億行での Polars (GPU) の爆発力
1B(10億)行のデータにおいて、Polars GPUの処理速度の高さが顕著です。例えば T1: Math (数値計算) では、
- Polars (CPU): 8.49秒
- Polars (GPU): 0.10秒 (約85倍速)
CPUがメモリ帯域幅の限界で遅くなる中、GPUの広帯域メモリと並列計算が圧倒しています。
Polars (GPU) の初期化オーバーヘッド (Warmup)
同じ Polars(gpu) で行数による処理時間の違いに注目すると、例えば T1: Math (数値計算) では、
- 1M: 2.82秒
- 1B: 0.10秒
1000倍のデータ規模の方が速いという逆転現象が起きています。これは、最初の実行時(1Mの計測時)にCUDAコンテキストの初期化やJITコンパイルが発生しているためです。GPUを使う場合、小規模データではこのオーバーヘッドが処理時間を支配してしまいます。
DuckDBも早い
GPUを使わずとも、DuckDBが異常なほどの高性能を見せています。1Bの処理時間に注目すると、
- Task1 Math: 0.06秒 (Polars GPUの0.10秒より速い)
- Task3 Join: 0.10秒 (Polars GPUの0.08秒とほぼ互角)
GPUへのデータ転送ゼロ、カーネル起動時間ゼロという特徴が優位に働いたようです。さらに件数を増やすとどうなるのか気になりますね。
正規表現 (T2: Regex) の失敗
Polars(gpu) で T2:Regex が Failed になり、グラフでも描画していません。
これは、GPUエンジンが今回用いた正規表現パターンをサポートしていないか、私が知らなかったためです。
もし、実行させる方法をご存知の方は実験お願いします。
PySpark の立ち位置
分散処理フレームワークであるため、シングルノードでの計測ではオーバーヘッドが大きく、純粋な数値計算速度では Polars / DuckDB にはかなわない印象です。
Dask の立ち位置
CPU版はPythonのオーバーヘッドが大きく、特に正規表現などで遅くなっています。
今回は DGX Spark (Arm) での環境構築が上手くいかず実験できませんでしたが、GPU版で比較するとどうなるかは気になりますね。
データ規模ごとの整理
| データ規模 | ベストパフォーマンス | 理由 |
|---|---|---|
| 1M | Polars (CPU) / DuckDB | GPUは初期化オーバーヘッドが大きく、CPUの瞬発力に勝てない。 |
| 10M | Polars (CPU) / cuDF | まだCPUが高速だが、GPU(cuDF)が肉薄してくる。 |
| 100M | Polars (GPU) / DuckDB | ここで逆転。Polars GPUがCPU版より2〜5倍速くなり始める。 |
| 1B | Polars (GPU) / DuckDB | 圧倒的王者。 CPU版に対し 10倍〜80倍 の高速化を達成。ただしDuckDBも驚異的に速い。 |
まとめ
厳密性にかける実験で申し訳ないですが、なんとなくライブラリの実力を多角的に見た気になりました。困らないうちは、普段はPolars(CPU) / 100M以上のデータを扱うときは GPU エンジンに切り替える方針でいこうと思います。
とはいえ、高速であることは正義なので、学習コストだけで使用する技術を制限せずに、色んなライブラリを触りながら業務を進めていきたいなと思いました。ライブラリだけでなく、GPUプログラミングもできるようになりたい。