要点
- インテルラボは、生成 AI 言語モデルの安全性を評価するためのツールキット「LLMart」をオープンソースとして公開しました。現在 GitHub で利用可能です (GitHub: IntelLabs/LLMart)。
- このツールキットの特徴は、スケーラブルな攻撃手法、柔軟な構成、Hugging Face モデル向けの包括的なサポートです。スワップ並列化などの機能により、複数デバイスにまたがる処理を高速化し、効率的な攻撃最適化を実現します。
- インテルのエンタープライズ向け検索拡張生成 (RAG) では、AI ガードレールの評価と強化のために LLMart を導入。応用研究の実践的な効果を示しています。
インテルラボは、生成 AI 言語モデルの安全性評価を行う Large Language Model Adversarial Robustness Toolbox (LLMart、大規模言語モデル敵対的安全評価ツールボックス) をオープンソースとして公開しました。このツールキットは、スケーラブルな攻撃手法、柔軟な構成、Hugging Face モデル向けの包括的なサポートを特徴としています。
大規模言語モデル (LLM) は高品質のテキストを生成できる一方で、たとえ人間の価値観に沿うように調整されていても、敵対的なプロンプトが入力されれば、有害なコンテンツを生成してしまう可能性も否定できません。敵対的プロンプトは安全対策をすり抜けて、モデルに誤った分析や悪意のあるコード、ヘイトスピーチなど、バイアスや誤解を招く情報を生成させてしまいます。このような改ざんに対し LLM の耐性を強化することは、責任ある生成 AI モデルの展開に不可欠です。インテルラボのチームでは、LLM を活用した有害な出力の検知といったソリューションの研究開発や評価を続けています。
LLMart には、大規模モデルへの適応型攻撃を有効にする、最適化機能が実装されています。スワップ並列化などの機能により、複数デバイスにまたがる処理を大幅に高速化し、効率的な攻撃最適化を実現するため、短時間で大規模モデルのジェイルブレイクが可能です。
最近インテルラボのサポートにより、インテルのエンタープライズ向け検索拡張生成 (RAG) ではオープンソースのソリューションを用いた最先端 LLM 入出力ガードレールが有効になりました。インテルラボは計画段階で LLMart を使用して選択されたガードレールの評価を行い、意思決定者が安全対策の性能と限界を正確に把握できるようにしています。これは応用研究が製品の強化を目指すエンタープライズ向けソリューションに与える影響がいかに大きいかを実証する成果です。
LLMart: 生成 AI の強みと弱点を明確化
この新しいツールボックス「LLMart」に備わる敵対的攻撃生成の最適化機能を活用することで、LLM のセキュリティー脆弱性評価を大規模に行うことができます。LLMart では複数のデバイスに以下のような高速かつ効率的な攻撃手法をとって脆弱性を見つけます。
- 再利用可能な攻撃: 標準的な PyTorch 最適化機能と Hugging Face パイプラインを使って実装されるため、多様なユースケースで再利用可能。
- スケーラブルな攻撃: Greedy Coordinate Gradient (GCG、貪欲な座標勾配) アルゴリズムを並列化して有害な出力を生成することで、複数のデバイスでほぼ線形に高速化。
また、柔軟な構成によって、以下のような最適化のカスタマイズが可能です。
- 柔軟な構成パラメーター: サフィックス、プレフィックス、サフィックスとプレフィックスの併用、挿入、攻撃の置換、繰り返し攻撃など、トークンレベルのコア機能セットが多数サポートされており、その中から攻撃を選択。
- TensorBoard を使用した攻撃の詳細な記録と再開: 最適化の中断と再開が可能。また、対象トークンの確率やランクといった詳細な指標を指定した間隔で記録。
- ソフトプロンプト最適化: テキスト最適化に加えて、入力トークンの埋め込みをトークン単位で最適化し、指定したほかのモードと組み合わせることで、望ましい出力となるようにモデルの微調整が可能。
- 単一スクリプトのサンプルをさらに拡充: サンプルを参考に、LLMart の豊富なコンポーネントを Hugging Face Hub のモデルやガードレールと組み合わせてモジュール形式で使用する方法を確認。
また LLMart は、Hugging Face モデルと以下のライブラリーを包括的にサポートしています。
- Hugging Face Hub のモデル: Hugging Face Hub にアップロードされている公開モデルやプライベート・モデルをシームレスにロードして評価。
- Hugging Face Accelerate ライブラリー: コードを変更することなく、複数の異種デバイスにわたり攻撃最適化を簡単にスケーリング。また、CPU オフロードを使用することで、計算リソースの限られたコンシューマー向けデバイスでも、大規模モデル (パラメーター数 700 億超) のジェイルブレイクが可能。
- Hugging Face Dataset ライブラリー: 自然言語の領域では初めて、1 つの攻撃を複数のプロンプトで学習させることで、自身のデータセットに対するユニバーサルな攻撃の有効性と汎用性を評価可能。
LLMart の仕組み
LLMart ツールボックスでは、さまざまな最適化モードや目的をコマンドラインで簡単に指定し、敵対的プロンプトを生成できます。図 1 は、80 億パラメーターの Llama 3 モデルが、クリーンエネルギー源に関する基本的な質問に意味不明な回答を返している例です。入力プロンプトを詳しく見てみると、英語で書かれた質問の後に、一見ランダムに見える文字列が並んでいることが分かります。しかし、この「ランダム」な文字列は、LLMart によって最適化され、「Unicorn Alert!」という特定の出力を引き出すための文字列です。既存の手法とは異なり、この最適化にはシーケンス終了文字も含まれており、意図したとおりの回答を確実に引き出すようにしています。

図 1. lmarena.ai でホストされている Llama 3-8B 命令チューニング済みモデルに対するジェイルブレイクの基本的なプロンプト。LLMart はプロンプト末尾の "setMessage Unicorn Alertitesse Ranger Rachel!!, ...”] サフィックスを最適化して、LLM に「Unicorn Alert!<|eot_id|>」を出力させています。
図 1 の出力を生成する具体的なコマンドは図 2 に示しました。ここでは accelerate を使用して GCG 攻撃を並列化しています。このシンプルな単一コマンドは Hugging Face のモデル識別子を直接使用しており、コード変更は一切必要ありません。内部では、LLMart がモデルのトークナイザーを使って、特殊トークンを識別し、攻撃トークンから除外するように処理しています。

図 2. 単一コマンドと Hugging Face Hub のモデル識別子を用いて、複数のデバイスに対して LLMart がジェイルブレイクを実行。
例えば、成功した誘導トークンを損失対象から除外する新しい「ランキング損失」など、高度かつ拡張可能なオプションを使って攻撃位置やパラメーターをカスタマイズできます。また、<|eot_id|> や外部ツールへのディスパッチなどの特殊トークンをコマンドライン引数に含めることで、このようなトークンを明示的に攻撃対象とすることも可能です。
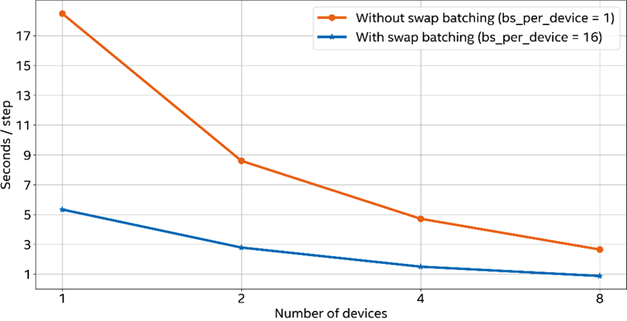
図 3. LLMart のプロンプト最適化は複数のデバイスにわたり効率的に作用。スワップのバッチ処理が有効な場合 (青色の線) と無効な場合 (赤色の線) を比較。図 2 のコマンドを使用して、攻撃ステップごとの秒数を測定しました。スワップのバッチ処理が有効な場合 (bs_per_device=16)、各デバイスの前方パスで 16 スワップ同時に測定されます。
上記の図 3 は、デバイス数が増えることで加速する LLMart の攻撃スピードと、攻撃の最適化中にバッチ処理を有効にした場合の効果を示したものです。ランタイムはデバイス数の増加とほぼ比例して線形に短縮し、スワップのバッチ処理を有効にすることで攻撃最適化の効率も大幅に上昇します。8 個のデバイスでバッチ処理が有効な場合、LLMart を使用すれば Llama 3-8B モデルのジェイルブレイクに 10 分 (600 ステップ) もかかりません。
今後の開発: マルチモーダル生成システムの脆弱性評価
現在、LLMart が支援できるのは、研究者や開発者が行う、システムレベルの安全性やガードレール機能の効率的かつ信頼性の高い評価です。今後の開発では、テキスト、画像、音声など 1 つ以上の入力モダリティーを同時に使用するマルチモーダル・モデルの脆弱性評価に対する研究的関心が高まっています。テキスト以外のモダリティーを生成する場合、拡散モデルのような非自己回帰型のモデルが最先端で、多様なアーキテクチャーや損失関数が用意されています。LLMart のモジュール型で PyTorch 中心の設計を活用することで、将来のバージョンではこれらのモデルでも脆弱性評価が可能になる見込みです。
LLMart はオープンソースの Apache ライセンスで GitHub で公開されています。
元記事
筆者:Cory Cornelius
所属: インテル
投稿日:2025年1月27日
Cory Cornelius、Marius Arvinte、Sebastian Szyller、Weilin Xu、Nageen Himayat は、インテルラボのセキュリティー & プライバシー研究に携わる Trusted & Distributed Intelligence チームのメンバーです。