
信頼できる生成 AI エージェント型アシスタントを動かす RAG ベースのソリューションをインテルと共同開発
AI モデル、特に大規模言語モデル (LLM) で発生するハルシネーションというのは、一見すると筋がとおっているように見えても、実際には誤っていたり誤解を招くような情報がモデルによって生成されてしまう現象です。ハルシネーションの例としては、誤った事実、無意味な文、存在しない情報や詳細の捏造といった出力が挙げられます。こうしたハルシネーションへの対処は、大規模なエンタープライズ向けモデルでは特に、AI ソリューションの信頼性を確保するうえで非常に重要です。
最近インテルが開催したウェビナーでは、Vectara のエキスパートが、同社のエージェント型検索拡張生成 (RAG) プラットフォームとハルシネーション検出モデルによる、エンタープライズ規模の LLM でのハルシネーションに対する効果的な対処方法について詳しく解説しました。
ウェビナーのトピック
- LLM で起こるハルシネーションの考え方、この現象が発生する理由、軽減する方法
- Vectara の RAG-as-a-Service プラットフォームと評価モデル Hughes Hallucination Evaluation Model (HHEM) によるハルシネーションへの対処
- 実際のユースケースで LLM のハルシネーションを検出する方法
ウェビナー全編の録画を再生
Tackle LLM Hallucinations at Scale in the Enterprise (エンタープライズ規模の LLM でハルシネーションに対処する方法)
このページでは、ウェビナーで取り上げたトピックの重要ポイントと、エンタープライズ向け LLM の機能拡張を目指す Vectara の取り組みについて紹介しています。
Vectara のビジョン: 信頼できる、セキュリティーが確保された、責任ある AI
Vectara は、信頼性が高く責任あるエージェント型 AI アシスタントの開発を可能にする、AI フレームワーク・プラットフォームを提供しています。
- 正確で精度の高い出力
- 出力結果のセキュリティー確保
- 説明責任
目指すのは AI モデルがどのような経緯理由で生成した結果に至ったのかを説明できる能力です。
LLM はプロンプト攻撃に脆弱で、人間と同じように騙されてしまう可能性があります。例えば LLM に銀行口座の PIN コードを入力することで、通常ならば許可されない給与などの個人情報が引き出せてしまうなど、LLM が騙される危険性も否定できません。
このようなセキュリティー脅威をはらんでいるだけでなく、LLM には学習データに基づいて無関係であったり不正確な応答を生成する傾向があり、これがハルシネーションと呼ばれます。1 つ簡単な例をお見せしましょう。LLM に、「20年固定住宅ローンの金利は?」と質問してみたとします。モデルは学習済みの事実に基づいて「金利は x%」と具体的な数字でプロンプトに回答を返すかもしれませんが、本来ならば、「住宅ローンの金利は市場の状況や信用スコアなどの要因によって変動する」と回答するべきです。こうした実際のシナリオから逸脱した誤解を招くような回答は、産業に使用される大規模 AI ソリューションでは望ましくありません。
このような課題を解決すべく、エンタープライズ規模の LLM で Vectara がどのような手法をとっているのか、詳しく解説していきます。
検索拡張生成 (RAG) による LLM のハルシネーション軽減
検索拡張生成 (RAG) は、入力されたシナリオと関連する精度の高い回答を LLM が生成できるように、データベースなどの外部ソースから情報を取得した後に出力を生成する手法です。モデルが最新の情報を認識して、学習データのみに依存するよりも精度の高い出力を生成できます。
Vectara が展開しているのは、小規模から大規模までエンタープライズ LLM のハルシネーションを軽減または排除する RAG-as-a-Service プラットフォームです。独自のデータを LLM に入力できると同時に、LLM によるハルシネーションの軽減も可能になります。このプラットフォームには、データ漏えいを防いでデータ・セキュリティーを確保する役割ベース / エンティティー・ベースの厳格な制御メカニズムだけでなく、回答の出典や参照元が分かる、LLM に説明責任のレイヤーを追加する仕組みも備わっています。
以下の図 1 に示すとおり、入力データはまずデータストア (テキストまたはベクトル型データベース) へ送信されます。情報検索のステップでは、LLM がデータストア内にある事実に基づいてユーザーからのクエリーに回答します。LLM は固定の学習データから仮定するのではなく、精度の高い出力結果を引き出すために、リアルタイムの情報をもとに回答します。
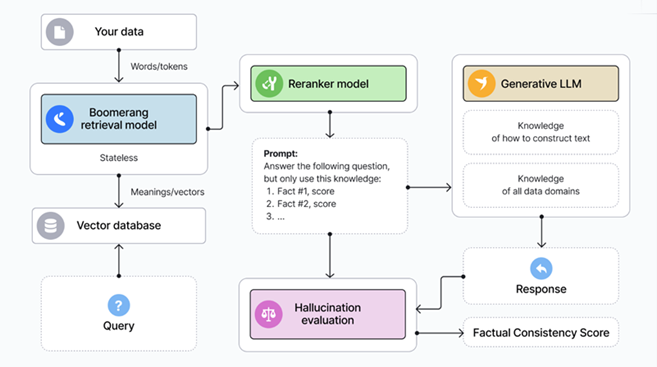
図 1. Vectara の RAG-as-a-Service が動く仕組み
Vectara が展開している RAG ベース・プラットフォームの LLM ハルシネーションに対処する仕組みについて、詳しくはウェビナーの [00:06:45] から解説しています。
LLM ハルシネーションの検出
また、ウェビナーの [00:13:35] 以降では、LLM ハルシネーションの検出がいかに難しいかとあわせて、生成された回答の「曖昧さ」に基づくハルシネーションの分類 (不要 / 内在的、無害、疑わしい) についても解説しています。
Vectara は Hugging Face で利用可能な LLM ハルシネーションを検出する独自の評価モデル Hughes Hallucination Evaluation Model (HHEM) を開発しました。この HHEM モデルのシリーズは、事実を要約する RAG アプリケーションでのハルシネーション検出に特化しており、入力された事実と出力された要約で整合性がとれているかをチェックします。HHEM リーダーボード上では、特定のデータセットを使用して、市場に提供されている複数 LLM のハルシネーション率が比較されます。インテルの neural-chat-7b モデルは、極めて低いハルシネーション率を示し、リーダーボードで上位の評価を獲得する結果となりました。
エージェント型 RAG をエンタープライズ AI に活用
Vectara のプラットフォームを使用する生成 AI の主なユースケースとして、AI アシスタント (対話型 AI、Q&A) や AI エージェントなどが挙げられます。AI エージェントの分類は以下のとおりです。
- エージェント型 RAG: 入力クエリーを複数の質問に分割 → 個別に回答 → すべての回答をマージするといった複雑なタスクを実行
- アクション実行エンジン: ウェブページの公開やメール送信の代行など、ユーザーのリクエストを直接実行
ウェビナーの [00:36:30] から、Vectara のプラットフォームでエージェント型 RAG を動かす仕組みを詳しく解説しています。オープンソースの vectara-agentic Python パッケージを使えば、エージェント型 RAG を簡単に実装することが可能です。また、ウェビナーの [00:38:05] 以降では、エージェント型 RAG による法律相談アシスタントの構築デモが紹介されています。Hugging Face で法律相談アシスタント・アプリケーションを実装する方法を深く掘り下げ、実際に手を動かして試してみてください。
次のステップ
ぜひウェビナー全編の録画をご視聴いただき、Vectara のソリューションが基本的な LLM や商用の複雑な LLM でハルシネーションにどのように対処しているか、理解を深めてください。インテルの AI 開発を活性化ページでは、oneAPI プログラミング・モデルを基盤としたインテルの幅広い AI ソフトウェア・ポートフォリオを活用して AI 開発の期間短縮と効率化を図る、最適化ツール、ライブラリー、フレームワークなど、多様なリソースを用意しています。
ウェビナー全編の録画を再生
インテルの AI Tools Selector から開発者向けの各種リソースをインストール可能です。
関連情報
- Do Smaller Models Hallucinate More?
- 2025年 AI ツールとフレームワークの最新アップデート
- これまで開催されたウェビナーやワークショップをオンデマンドで視聴
- 今後のウェビナーとワークショップ開催スケジュール
- AI フレームワークとツール
元記事
筆者:Nikita Shiledarbaxi
所属:インテル
投稿日:2025年1月23日