はじめに
以前はXplentyでのparquet形式は書き込みのみを支援しました。しかし、2024年の3月からparquet形式の読み込みの支援し始めました。
以前の記事でも言及したようにparquet形式は大量データの扱いに特化しています。今回は、前回の記事で書き出しておいたparquest形式のデータを読み込んで他に連携するパッケージを紹介したいと思います。
XplentyでParquet形式への書き込み
1. parquet形式のデータの準備
まずは、parquet形式のデータを保存するFileStorage sourceで使えるSftpサーバやオブジェクトストレージ(S3, Google Cloud Storage, Azure Blob Storage)をご用意ください。大量データの書き込みはParquet形式で色々節約の記事をご参照の上、大量データをparquet形式で保存しておいてください。
これで準備は完了です。
2. parquet形式のデータの読み込み
お馴染みのパッケージ編集画面に入り、FileStorage source・コンポーネントを選択してください。FileStorage sourceの詳細設定を下記を参照して入れるとparquet形式のファイルの読み込みが出来ます。
| 項目名 | 設定値 |
|---|---|
| Connector | S3 |
| Bucket | 該当コネクターのバケット名 |
| Path |
/parquet-output/2020-citibike-tripdata.*.parquet ※ 個人の設定に合わせて変えてください! |
| Record delimiter | New Line |
| Record type | parquet |

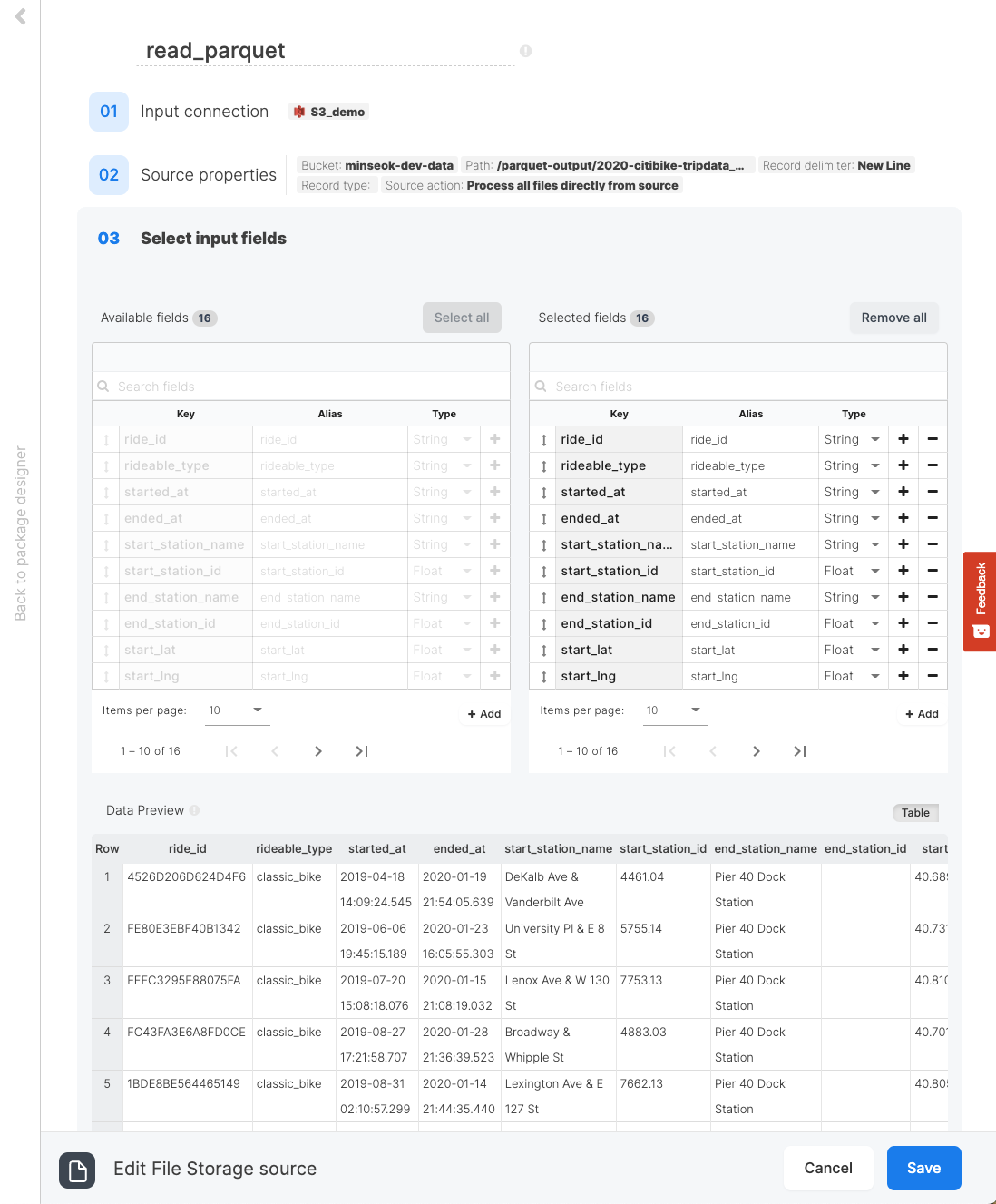
3. 追加のフィールドを設定
Selectコンポーネントを選択して、下記のようなフィールドを追加してください。
Auto-fillボタンでソースからフィールドをすべて追加しておき、最後のフィールドに行きます。右側の+をクリックすると新規フィールドが追加されるので、下記の表に基づいてExpressionとAliasをそのまま記入してください。
| Expression | Alias |
|---|---|
ToString(CurrentTime(), 'yyyy-MM-dd HH:mm:ss') |
imported_at_utc |
ToString(SwitchTimeZone(CurrentTime(), 'Asia/Seoul'), 'yyyy-MM-dd HH:mm:ss') |
imported_at_kst |
ToString(SwitchTimeZone(CurrentTime(), 'Asia/Tokyo'), 'yyyy-MM-dd HH:mm:ss') |
imported_at_jst |

4. データのJSON形式の書き出し
追加のフィールドの設定後にJSON形式で書き出すためにFileStorage destinationをパッケージに追加します。
FileStorage destinationをSelectコンポーネントに繋ぎ、詳細設定を下記の表に従って行います。
これで、parquet形式を読み込んでそれをJSON形式に書き出すデータパイプラインの完成です。
| 項目名 | 設定値 |
|---|---|
| Connector | S3 |
| Target bucket | 該当コネクターのバケット名 |
| Target directory | json-output-test |
| Destination format | Line Delimited JSON |
| Destination action | Write all files directly and replace files in directory if they already exist |
| Merge output to single file | Checked |
| Target file names | Custom pattern |
| File name prefix | 2020-citibike-tripdata. |

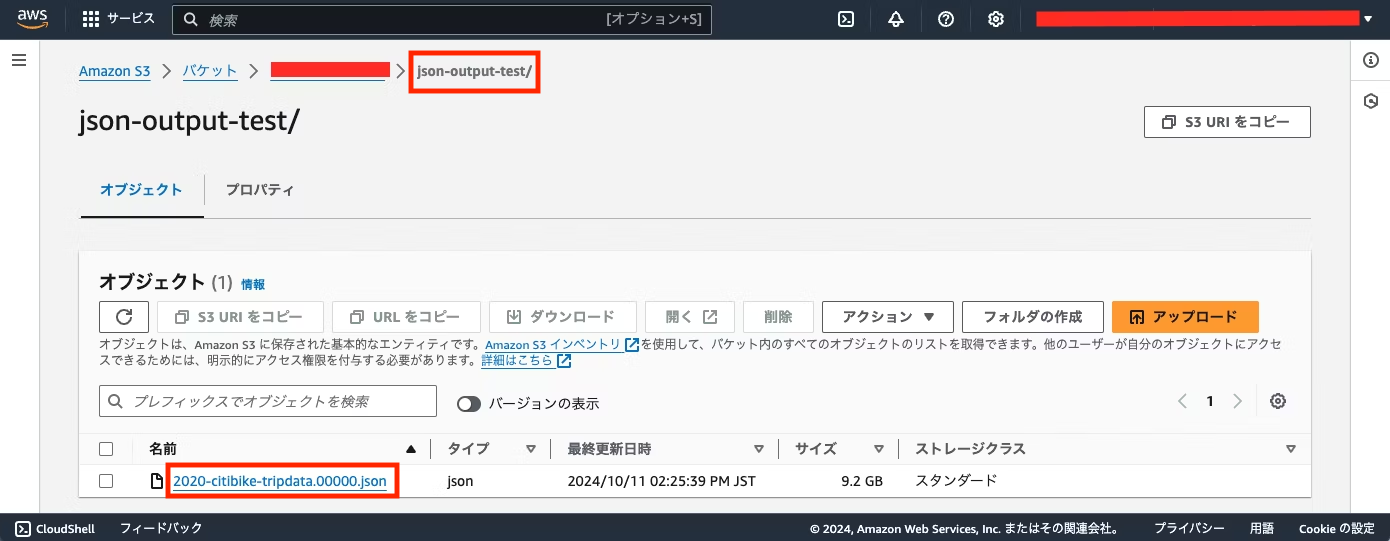
完成したパッケージをSave and Validateボタンで保存し、クラスタで実行すると下記のように指定のファイル名でjson-output-testディレクトリにJSONファイルが保存されます。
※ 参考 - ファイルの読み込み時にtimeoutエラーになった場合の対応
FileStorage sourceでは、データの読み込み時に下記の図のようにtimeoutエラーになる場合があります。
ParquetやExcel形式のファイルは、スキーマ構造を解るためにファイルの展開が必要になります。ファイルにあるデータが少ない場合は問題ありませんが、データが多いと展開に想定よりも時間が掛かります。

この場合の対応策としては、まずはPathにデータが少ないParquetやExcel形式のファイルを指定してFileStorage sourceやパッケージを構成し、保存、テストを一通りに完了させます。
FileStorage sourceを再び開き、02 Source propertiesにそのまま行ってPathを本番用のデータが多いファイル名に設定してからそのままSaveボタンをクリックして保存します。
注意点は、03 Select input fieldsには行かないことです。誤っていった場合はそのままCancelボタンで保存せずに設定画面から出て、再びFileStorage sourceを開き、02 Source propertiesでPathのファイル名を変更してください。
終わりに
Parquet形式は大量データを迅速に扱い、かつ保存領域の節約に非常に役立ちます。AWSのAthenaでも当ファイル形式を支援しているので様々な大量のデータをparquet形式で転送して分析業務に迅速に対応が可能です。
弊社integrate.ioは、無料で2週間のトライアルを提供しております。ぜひ、お試し頂ければ幸いです。