こんにちは!株式会社インサイトテクノロジー プロダクト開発本部に所属している上原と申します。普段は社内の「AIチーム」の一員として、機械学習関連のプロダクトの開発などに携わっております。
今回、AIチーム全員と新卒の皆さんで人工知能学会全国大会に聴講へ行ってまいりましたので、私が気になった発表をレポートします!ちなみに昨年のレポートはこちらとこちらからご覧いただけます。
あと個人的には人生初静岡、人生初新幹線ということで、学会以外も中々楽しかったです。いやほんと、いいですね、浜松…!
大規模言語モデルを用いたカオスエンジニアリングの自動化
- 著者(敬称略): 菊田 大輔, 池内 光希, 田尻 兼悟, 中野 雄介
現代の複雑かつ大規模なシステムは部分的な障害がシステム全体に影響を及ぼし、カオス的な挙動を示すことがあります。そこで、意図的に障害を引き起こし、事前にその挙動を観察・分析して対策を講じることをカオスエンジニアリング(以下、CE)と呼ぶようになったそうです。あのNetflixがやり始めて有名になったそうですよ(参考)。
この研究ではネットワークシステムを対象に、CEを実行することを想定しています。そこで存在する4つのステップ「仮説 - 実験- 分析 - 改善」のうち、仮説と改善をLLMにやらせることで、このプロセスを全自動化しています!「実験」と「分析」については既に自動化のためのツールが既に存在するとか。
でも仮説はまだしも、LLMにネットワークの改善をさせるってどうやって…?と不安になったのですが、IaCベースの仮想ネットワークで実験したとのことです。実際にはk8sのYAMLファイルを使っていたそうなのですが、これなら確かにLLMを適用できそうですね。
そして提案システムであるChaosEaterはCEの4つのステップを全て含むもので、「ネットワーク構成を記述したk8s yaml」「ユーザのインテント(任意)」を最初の入力とし、そのまま任せておけば「定義された仮説を満たすように修正されたk8s yaml」「実験・修正の過程が整理された説明文」の2つが出力として得られます。通常CEは継続的に実行し続けるものらしいですが、先の出力をフィードバックすることでそれも可能とのこと!嬉しいですよね、全自動。
今更ですが、LLMって本当に色んなところで使えるのね…!と感嘆しました。あと何より、4つのステップが最初から最後まで全部動くモノであるChaosEaterが出来上がってるのがすごい素敵でした。
生成データが今後のデータセットに与える影響について
- 著者(敬称略): 幡谷 龍一郎
「モデル崩壊」という現象が少し話題になったのを覚えています。すごく単純化して言うと、ある世代の生成系モデルによって生成されたデータを使って、次の世代のモデルを訓練することを繰り返すと、性能が劣化していくというものです。前の世代の分布で確率が高い箇所はより高くなり、低い箇所はより低くなっていき、例えば言語モデルで言うと同じことしか言わなくなるそうです。恐ろしい…
これはモデル訓練のためのデータ収集にも関係しています。というのも言わずもがな、ウェブ上に生成データの割合は日に日に増えていると考えられるからです。画像, 文章, 映像, どのメディアにおいても、いわば使えるモデルが揃ってきたことで、様々な場所でモデルが利用され、生成データがアップロードされていきます。そして、ウェブをクロールして作られたデータセットが生成系AIの学習に使われて… 学習前に生成データを事前に弾く仕組みがなければ、生成系AIの利用が進めば進むほどモデル崩壊が起きやすくなると言えるでしょう。
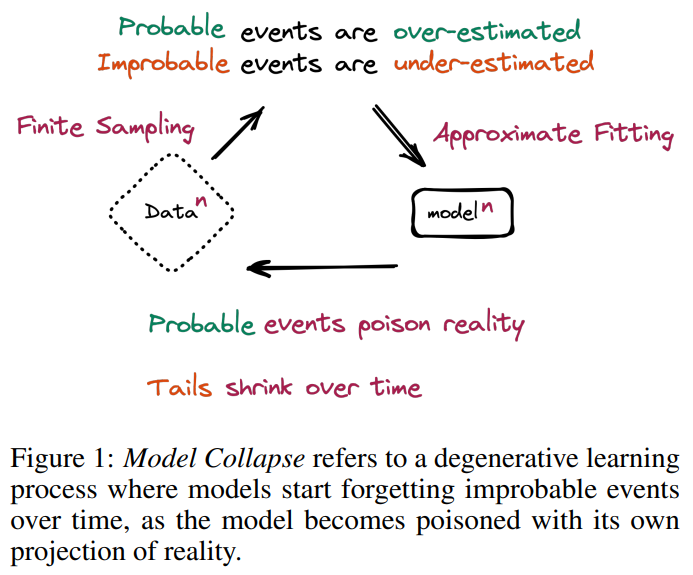
Shumailov et al. (2023) Figure 1より引用。
さて本研究ですが、学習データに生成データが混入した「汚染」の割合と、モデルの評価結果の関係を検証しています!またShumailov et al. (2023) とは異なり、画像の識別系タスクを対象としています。筆者らはStable Diffusionを用い、ImageNetとCOCO Captionを模倣したデータセットを生成しました。これらを模倣元のデータセットに一定の割合で混入させながら、モデルの性能を評価しています。
このデータセット汚染が80%を超えたあたりで、急激に性能が劣化することが実験結果からわかりました。「8割ならそんなに心配しなくていいじゃん!」と思われるかもしれませんが、5割でも結構低下していること、先に述べたようにこれからどんどん汚染が進むかもしれないことを考えると、中々厳しいのではないでしょうか…?
なお、性能劣化が生じる原因として、画像の多様性の低下および品質の低下が挙げられていました。実際に会場で生成された画像データを見ていましたが、確かに一見リアルなんですけど、背景が毎回同じとか、角度が同じとか、みんな似たり寄ったりだったんですよね。
最後に、データセット汚染の影響を緩和するための3つの対策について言及がありました。
- 画像に透かしを入れること。OpenAI社のモデルは既に透かしを入れているそうです。しかし、既に透かしを剥がす技術があったり、そもそも生成時に透かしを入れないモデルが多数公開されているなど、技術的なレベルだけで何とかなる問題でもなさそうです。
- 生成データの検出技術を向上させること。ここ最近のモデルの出力はとても高品質なため、難しいタスクです。しかし前述の通り、常に透かしがあるとも限らないですし、画像以外のデータにいかにして透かしを入れるかについてはまだまだ検討が必要です。透かしと合わせて、AIによって生成されたコンテンツであるかどうかを判定する技術の進展も期待したいですね!
- そもそも生成データによる汚染に対して頑健な学習方法を研究していくこと。多様性の低い生成データから効率的に情報を抽出できるような、新たな頑健性を持つ学習手法の研究開発を進めることは有意義であると述べられていました。前述の汚染そのものに対する対策もやりつつ、こういう手法を考えるのもありですね!
コスト削減手法を取り入れたRAGによる質問応答システムの提案
- 著者(敬称略): 増田 嶺, 岩本 和真, 道信 祐成, 北 健志, 竹原 一駿, 安藤 一秋, 亀井 仁志, 最所 圭三, 喜田 弘司
RAG、便利ですよね。LangChainやLlamaIndexなどのパッケージが登場したことによって、益々色んなところで見られるようになった気がします。RAGってなに?という方は、こちらをご覧ください!
そんなRAGですが、やはり検索によって取得するテキストの量は問題になるでしょう。OpenAIやAWS Bedrockなどのサービスはテキストの入力量に応じて課金する仕組みですので、可能な限り抑えたいところです。でも、できるだけ情報を追加したい…!その方が外部知識に詳しく、より良い回答を生成すると期待できるからです。そんなジレンマが存在します。
そこでこちらの研究では、そんな利用料金を抑えつつ、良質な情報も残す手法を考案しています。
提案システムでは、関連文書を検索によって取得したあと、そのフィルタリングをより低コストなモデルで並列実行します。その後、フィルタリングされた結果をプロンプトに仕込み、高コストなモデルで質問応答を行います。検索結果が全部そのままに入力にならないので、文字数と利用料金が削減できるというわけです。
情報を付加しているのではなくそぎ落としているだけですので、応答性能そのものが従来手法を上回ることはなかったそうですが、とにかくコストは下がったそうです。サブタスクをより小さなモデルに割り当てるという発想が自分のツボに入りましたね…!
より大きな規模の評価実験の結果がどうなるか、あるいは最近のモデルでやってみたらどうなるのかなど(GPT-4oも出たことですし)、今後の展開もとても気になる研究でした!
去年もそうでしたが、行きたい発表が被ったり、移動時間的に間に合わないことが多く、会場に居る時は何回か「分身したいな」って思いました。でも録画もあるし、Zoomでも見れるしと、ギリギリ分身しなくて済むので今の開催形態はとても有難いです…!
何が言いたいのがよくわからなくなっちゃいましたが、要は分身したいくらい、面白い話題がたくさんあったということでして… 関係者の皆様に改めて感謝申し上げます!学会の熱気を浴びて蓄えてきたモチベーションや、得られた知見を今後の開発に活かしていきたいと思います。
そう、モチベと言えば!弊社主催のイベントdb tech showcase 2024の開催が7/11 ~ 7/12で予定されております。無料で参加できますし、人工知能以外のトピックもカバーしております。みなさんモチベアップ等にいかがでしょうか!社員一同、皆様のご参加を心よりお待ちしております![]()
