本記事は「TRUST SMITH & COMPANY Advent Calendar 2022」の8日目です。
誰もやってくれないのでネタが尽きるまで一人で記事を書いていきます。(悲しい)
今日は「学習リソース」についての論文を読んでいきます。JPEGをdecodeせずにそのままViTに学習させるお話です。お前は何を言っているんだ?
タイトル:RGB no more: Minimally-decoded JPEG Vision Transformers
カンファ:roceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 22334-22346
URL:https://arxiv.org/abs/2211.16421
出典:Park, J., & Johnson, J.. (2022). RGB no more: Minimally-decoded JPEG Vision Transformers., https://arxiv.org/abs/2211.16421
著者の所属はMichigan大学です。名前をググろうとしたらお二人とも同姓同名の著名な方がいたようでちょっとウケました。
JPEG Vision Transformersの前提&ポイント
CV分野で多用されるモデルは前提として「画像はRGBである」ことを用いて学習・推論を行っていますが、実際には8 bit Raw画像としてデータが保存されていることは少なく、jpegなどにencodingされて保存されています。
このjpegからのdecodingは人間の目には大きな変化がありますが、学習に用いるデータとしてはdecoding前後で同一の情報量を持ちます。
よって、これらのencodingを部分的に行わないことで、encoding/GPU転送のオーバーヘッドを解消できることに着目した研究が(CNNに対して)行われています。しかし、CNN自身がそもそもRGB画像を前提として設計されていることから、CNNの構造に大きな変更を加えなければいけない問題が生じています。
よって、この研究ではjpegのdecodingデータを部分的に解凍し、周波数成分の情報を持ったデータとして扱うことで、通常の画像ベースでの学習(図中上ルート)を行う方法ではなく、encodeされたデータをそのまま用いて(図中下ルート)学習を行う方法を提案しました。
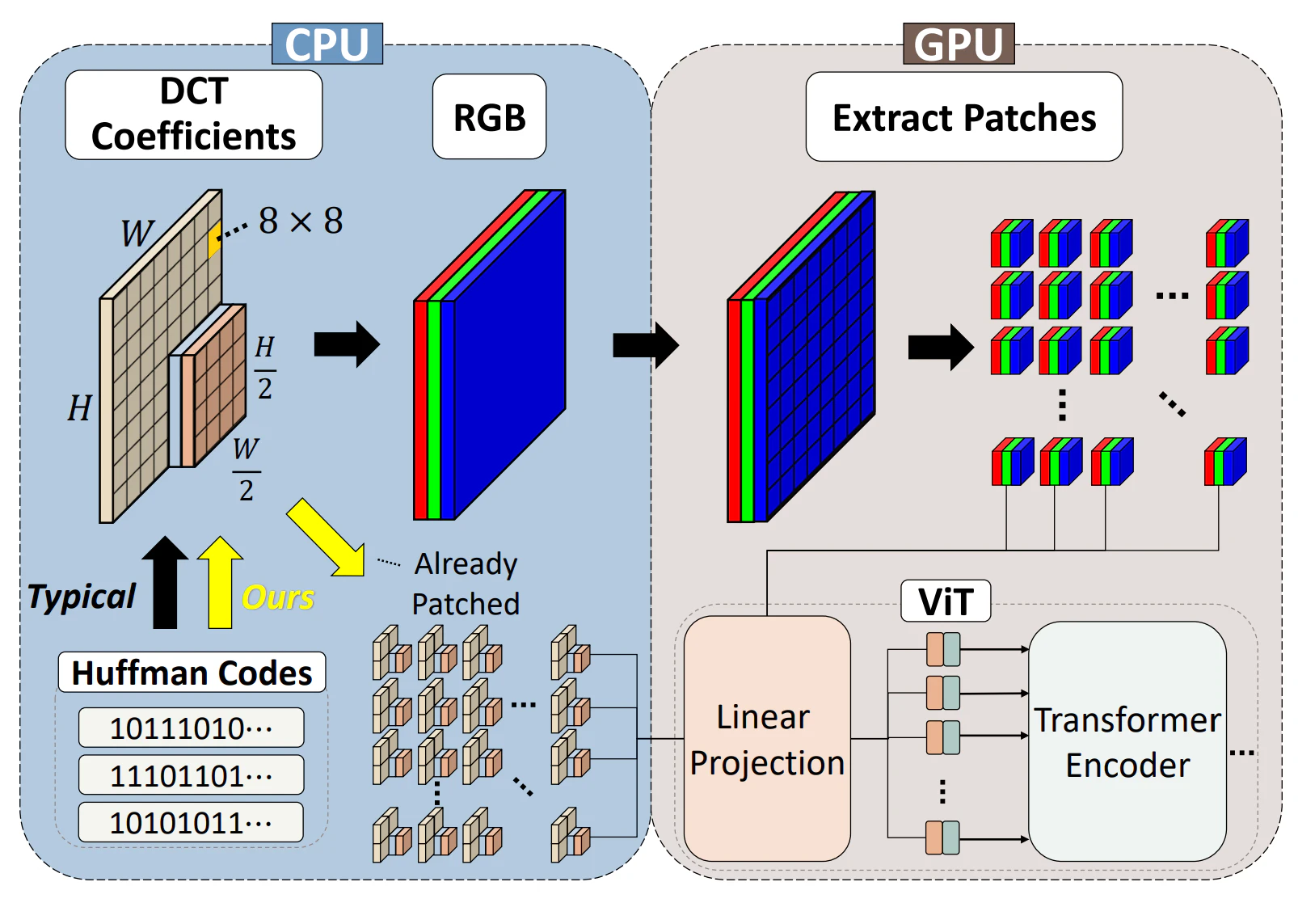
その結果、提案モデルはRGBモデルと比較して、学習が39.2%と推論が17.9%加速し、精度低下が起きなかったそうです。
2022年も年の瀬ですが、言われてみればそうof the yearでした。本家Vision Transformerでも、画像をpatch化してflattenしているので、一旦画像として構築しなおす必要ないですね。
Vision Transformerについては、おなじみomiitaさんの記事をご参照ください。
また、Vision Transformer入門 [片岡+, 2022, 技術評論社]もそろそろ本気でDeepについていけなくなりつつある2022年、2023年を耐え抜くための良書です。
https://gihyo.jp/book/2022/978-4-297-13058-9
実装
JPEG法について
まず、この研究ではjpegについて着目しているため、ちょっとしたjpegに関する事前知識が必要です。
あまりこの辺りは詳しくないので間違えている可能性があります。詳しくは参考書等を参照ください。
JPEG (Joint Photographic Expert Group)法は、画像圧縮技術のうちの非可逆圧縮方法の一つです。今知ったんですが、JPEGという策定委員会の名前をそのまま使ったそうです。
JPEG法の特色
JPEG法では、人間の目が
- 輝度の変化及び階調の変化には敏感であるが、色の変化には鈍感
- 緩やかに変化する(=逆空間における低周波数領域)の輝度の変化及び階調の変化には敏感であるが、細かく変化する(=高周波数領域)の輝度の変化及び階調の変化には鈍感
であることを利用して情報を間引いていきます。
具体的な圧縮方法
以下のような300 pxのLenna画像について考えます。

このLennaの画像は300 pxなので、8bitの3階テンソルとして3 color × 300 px × 300 px × 8 bit=2,160,000 bitの情報量を持っています。
色情報についての圧縮
色の成分を加色することで色空間を表現するRGBでは、明るさと色を区別して考えるJPEGにおける取り扱いが面倒なので、JPEG法ではYCbCrという色空間を利用します。
YCrCb色空間は、「色」と「明るさ」に分けて色空間を表現する方法で、下の画像のように輝度としてのグレースケールYに対して独立なCb(青の補色)とCr(赤の補色)でグレースケールからの差分を管理することで色空間を表現できます。

ここで、「人間は輝度の変化には敏感であるが、色の変化には敏感でない」ことを利用し、CrとCbについてデータ量が1/4になるようにbinningします。ここでデータ量はグレースケール分が720,000 bit、CrとCbはbinningにより1/4になったので各180.000 bitになり、合計で半分まで圧縮されることになります。

この処理は正直かなり軽い&通常の画像処理のため、実際は特にどっちでもいいです。
周波数成分についての圧縮
上記の圧縮に加え、今度は空間周波数によって情報量を圧縮します。考え方としてはローパスフィルタに近いものがあります。
JPEGでは、計算量の少ない離散コサイン変換(DCT)を用いて空間周波数に変換します。
実際には、対象画像を8 px × 8 pxの小さい画像ブロックに分け、その画像に対してDCTを行います。
この処理、言われてみれば確かにかなりのVision Transformerみがあります。
ここで、DCTを用い、対象画像を以下のような各種の空間周波数を持つ画像の重ね合わせに変換します。
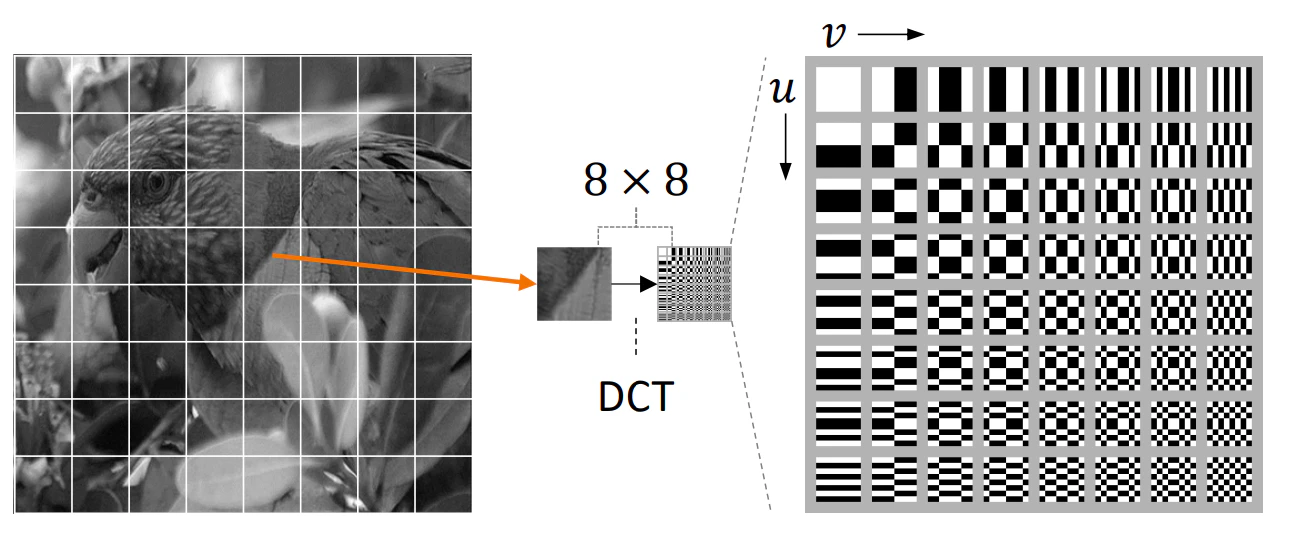
この変換した画像について、低周波数の部分(左上に近い成分)と高周波数の成分(右下に近い部分)が存在することがわかります。
ここで、JPEGでは「緩やかに変化する(=逆空間における低周波数領域)の輝度の変化及び階調の変化には敏感であるが、細かく変化する(=高周波数領域)の輝度の変化及び階調の変化には鈍感」という人間の目の特徴を使い、高周波数の部分を取り去って圧縮を行っています。
このDCT処理がかなり重く、JPEGのencoding/decodingの大部分を占めています。
Run Length Encoding&Huffman encoding
ここは特に本質ではないので省略しますが、JPEGはこの後Run length encodingにより圧縮を行い、Huffman encodingによってencodeされます。
本研究の着眼点・メリット
この研究では、このようなJPEGのDCTを挟む実装に対し、DCTによって処理された画像を処理することができるVision Transformerを提案しています。
- 計算コストのかかるJPEGにおけるDCTの逆変換を必要とせず、CPUで行われるデータロード処理を削減できる
この点に関してはかなり直観的にわかります。確かに処理速度が向上しそうです。
また、学習に用いる情報量の観点からも、jpeg encodeしたデータをdecodeした画像を最も効率的に次元圧縮する手段はjpegのencodeなので、確かに効率的に次元圧縮を行っているといえそうです。
- JPEGにおいてRBG画像をパッチに分割し、DCTによって周波数成分のベクトルに変換する操作は、ViTにおいてpatch embedding layerによって画像パッチをベクトルにエンコードすることに似ている
確かにそうです。
というわけで、これらの点から、著者らはCNNとは違い、ViTでは入力のpatch embedding layerのみを変更すれば簡単にDCT encodedな画像を入力として学習できると考えました。
patch embedding layer
本論文では3つのpatch embeddingの方法が提案されています。
いずれの方法でも、embeddingを行う前に、jpegエンコード時のCrCbのダウンサンプリングによって起こるチャンネルごとのサイズの不一致に対処しています。
具体的には、Yにおけるパッチサイズ8$\times$8に合うようにbinningされたCb・Crを4$\times$4で収集し、blockとするることで対応しています。
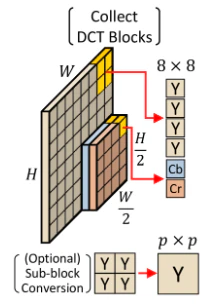
CNNにおける既存研究ではここが困難なポイントになっており、以下の3種類の方法はどれをとっても効果的かつ簡便に既存のモデルに適用させることが困難でした。
- CbCrをYのサイズに合わせる(アップサンプリング)
→ 計算量が増える - YをCbCrのサイズに合わせる(ダウンサンプリング)
→ 情報損失が発生する - 別々に計算し、ネットワークの後半で統合する(レイトコンカテネーション)
→ CNNアーキテクチャの大幅な変更が必要
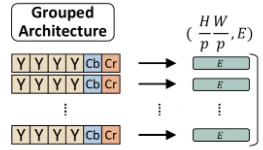
Group Architecture
前処理で生成したembedding用のblockをblockごとembeddingする手法です。
Separate Architecture
前処理で生成したblockの要素ごとに分割してembeddingを行い、それそれの結果を線形に統合する手法です。
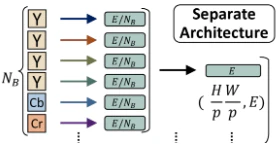
Group Architectureと比べると、各ブロックに対してそれぞれ特化した線形層を学習させることで、各ブロックが保持する情報を持つことができるため、良い結果が得られる可能性があります。
Concatenation Architecture
Separateほどは分割せず、YとCbCrの成分に対して別々にembenddingを行い、それを連結する手法です。
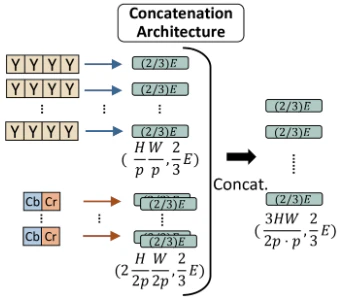
これはYとCrCbは異なる情報を持つことからくる手法で、それぞれの情報を扱う層は分けて学習させることが重要である可能性を考慮しています。
data augmentaion
DCTを直接学習するためには、data augmentationは避けて通れません。
一般にdata augmentationはResize、Cropping、flippingなど、RGB画像に対して直観的に行われる変換として表現されるため、DCTに対して直接同様の操作を行うことは困難です。
よって、先行研究では、ネットワークに画像を渡す前に
- DCTからRGBに変換
- RGBでData Augmentaiton
- DCTに変換
という操作を行っていましたが、この手法では学習時にDCTを利用するメリットを活用しきれていないため、本研究ではDCTのデータを直接Augmentationし、既存(RandAugment)のAugmentationが利用できないorDCTで行うには計算量が大きくなるもの(回転など)には新しい実装を提案しています。
個人的にはこの手法は軽いネットワークに対して推論を高速化したい場合に特に有効だと思うので、著者らの主張はちょっと微妙なのではないかと思うんですが、まあ学習が速くなるのはいいことです。(というか推論速度の加速自身はCNNと変わらないからここを主張しないとあんまり新規性ないですね)
Photometric augmentation
jpegでは2次元のDCTデータのうち、左上の$Y_{0,0}$や$Cr_{0,0}$、$Cb_{0, 0}$のことをDC成分、周波数部分のことをAC成分と呼び、それぞれに対して違った方針でAugmentationを行います。

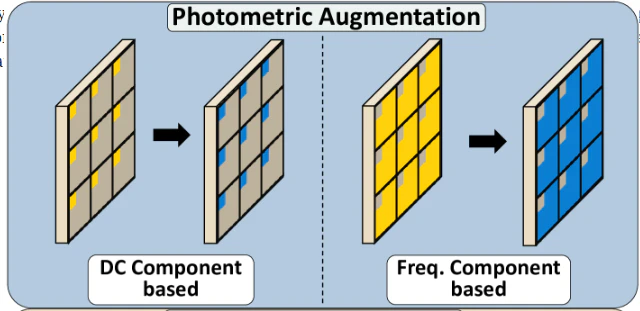
DC成分
まず、明るさと色相についてDCTのデータを用いてaugmentationします。
考え方はかなりシンプルで、YCbCr空間においてはYがコントラスト、CbとCrが色を決定するため、$Y_{0, 0}$に$t∈[0,∞)$および$Cr_{0,0}$、$Cb_{0, 0}$に係数$t$を用いて以下のように加算するだけでAugmentationが成立します。
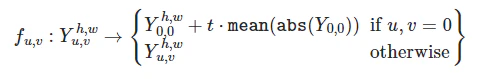
この考え方を拡張し、著者らはBrightness、Contrast、Color、AutoContrast、AutoColorについて実装しています。
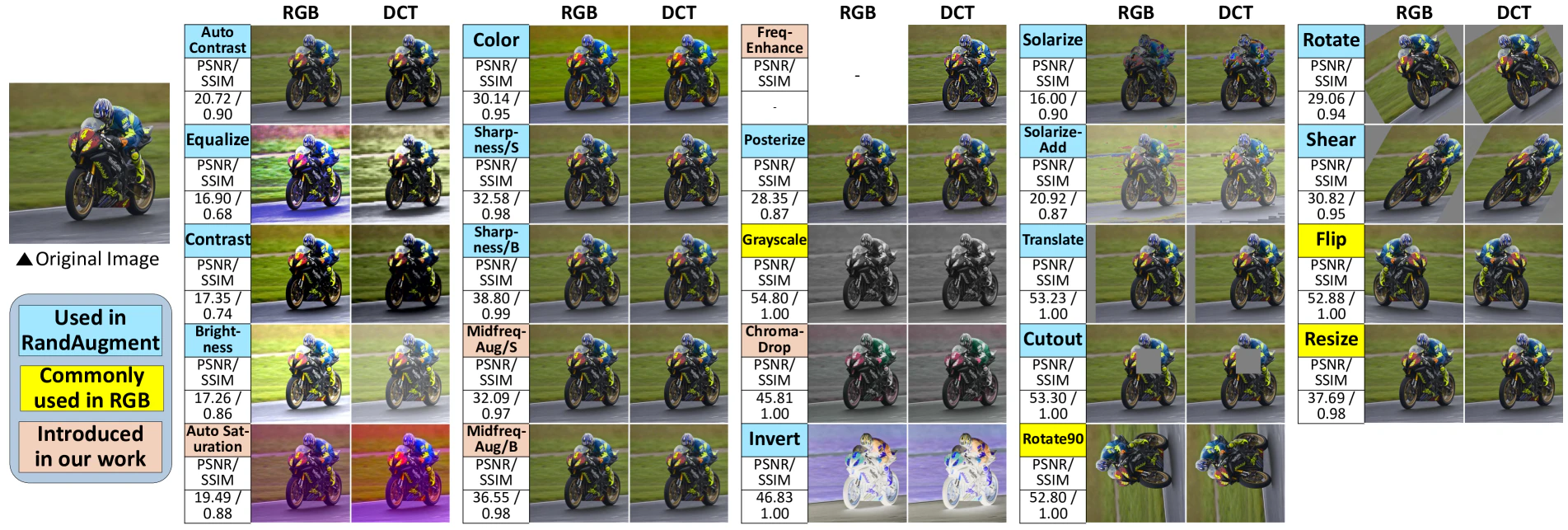
AC成分
周波数については、従来の周波数による画像処理と同等の操作が行えます。
これにより、Sharpnessの処理を実装し、独自の実装としてMidfreqAugmentation、FreqEnhanceを実装していますす。それぞれ名前のまんまの処理です。
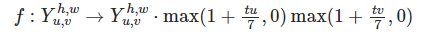
それ以外
それ以外にもphotometricなAugmentationを実装しています。
- Invert: すべてのDCT係数の符号を反転させます
- Posterize: DC成分を量子化します
- Solarize(Add): DC成分の値によってDCT block全体をinvert(Add)するかを決定します
- Grayscale: CbCr成分をゼロにします
- ChromeDrop: Cb or Cr成分をゼロにします
Geometric augmentation
幾何学的なAugmentationでは、block-wizeとsub-block conversionに分けて考えられます。
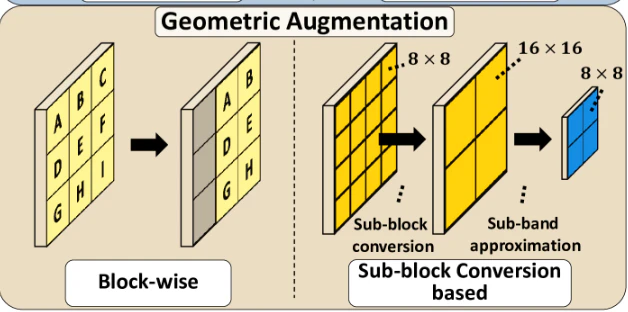
block-wize augmentation
DCTのブロックを一般の画像のように扱うことでAugmentationを行います。
- Translate
- Cutout
は通常の方法で実装できます。
- Flipping
- Rotate90
は詳細は省きますが、若干の工夫によって実装されています。
Sub-block conversion
ResizeとRotateについては周波数領域特有の事情で、近似およびフーリエ変換の回転特性をを用いることで行っています。それなりに複雑な割に、後述するようにあまり効果的でなかったため、詳細は省きます。(面倒)
結果
精度
結果的に、DCRで学習を行ったモデルは、RGBで学習を行ったモデルよりも高速に動作し、同程度の精度を達成できたようです。
AMPが用いられた★のモデルにおいて、JPEG-S(提案モデル)はViT-S(普通のViT)に比べ36.2%の高速化を達成し、より小さいモデルでは最大39.2%高速化されています。
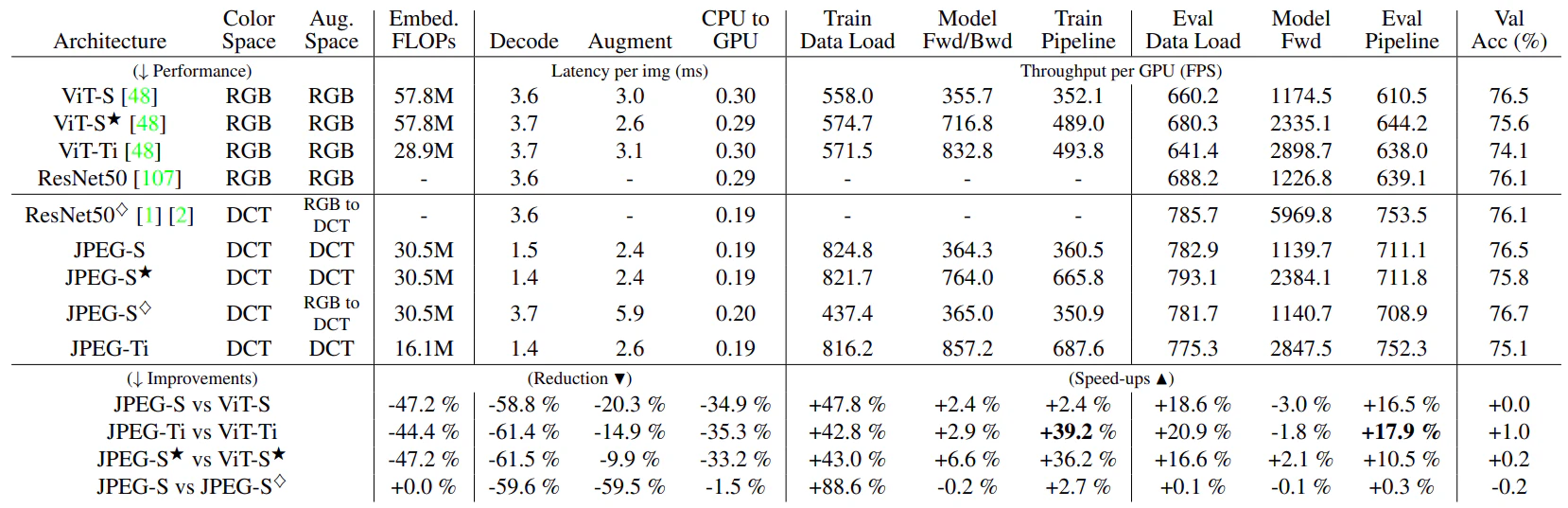
patch embedding
もっとも単純なGroup Architectureが精度が良かったそうです。

Augmentation
Sub-block basedな手法は使わないほうが精度が良かったそうです。計算コストかかりますし、やらないほうがいいですね。
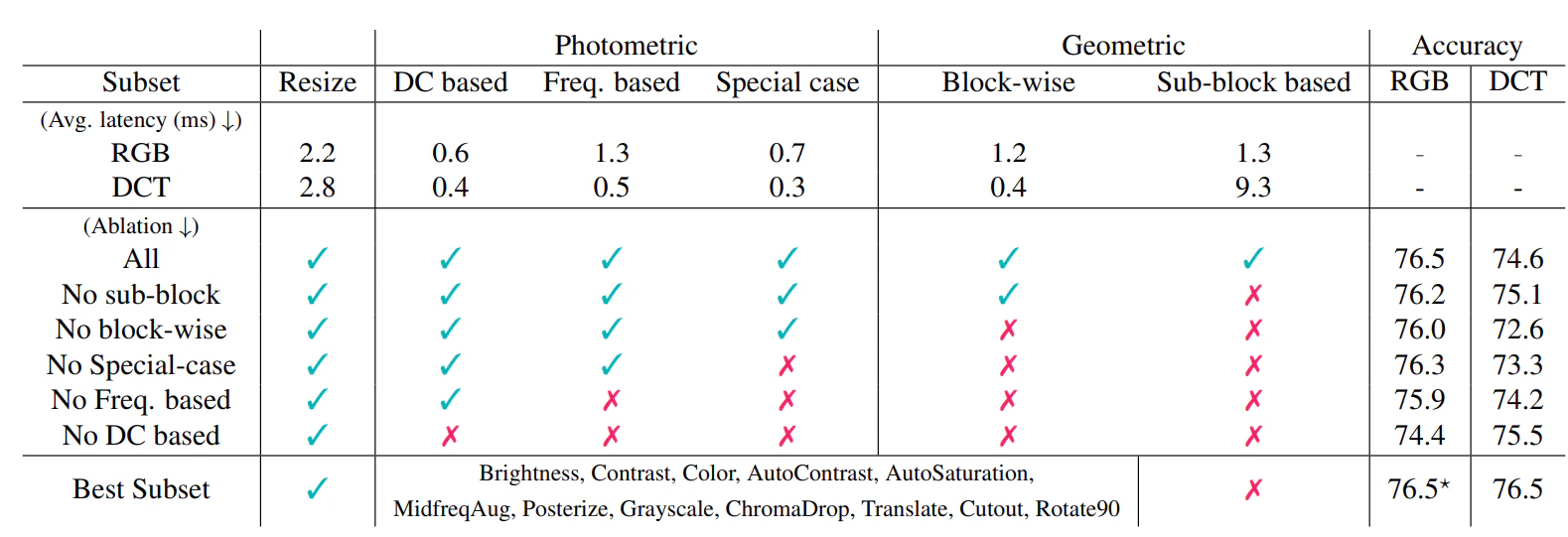
結論
結局、著者らの主張通りViTにおいては構造をほぼ変えることなく推論時間の短縮を行うことができることがわかりました。
ViTはその登場以来、多岐にわたるモデルが提案されていますが、(ほぼすべての)モデルに対して適用可能な本手法はかなり有効な提案と言えそうです。