SaaSをはじめとするサブスクリプション型のビジネスは、ビジネスモデルが売り切り型のビジネスとは異なるため、ビジネスの成長のために注目すべきポイントや、分析手法も異なっています。
そこで、こちらの記事ではサブスクリプション型のビジネスで注目すべきポイントと、重要な5つの分析手法を紹介します。
サブスクリプション型ビジネスのポイント
5つの分析手法を紹介する前に、簡単にサブスクリプション型ビジネスのポイントをおさらいします。
サブスクリプション型のビジネスと比較されることが多い売り切り型のビジネスでは、1人の顧客が商品やサービスを購入した場合、翌月もその顧客からの収益を見込めるとは限りません。

一方で、サブスクリプション型のビジネスでは、1回に得られる収益は売り切り型のモデルより少ないことが多いものの、毎月や毎年といった頻度で繰り返し顧客から収益を得られるため、長い目で見ると、売り切り型のビジネスより多くの収益を一人の顧客から得ることも可能です。
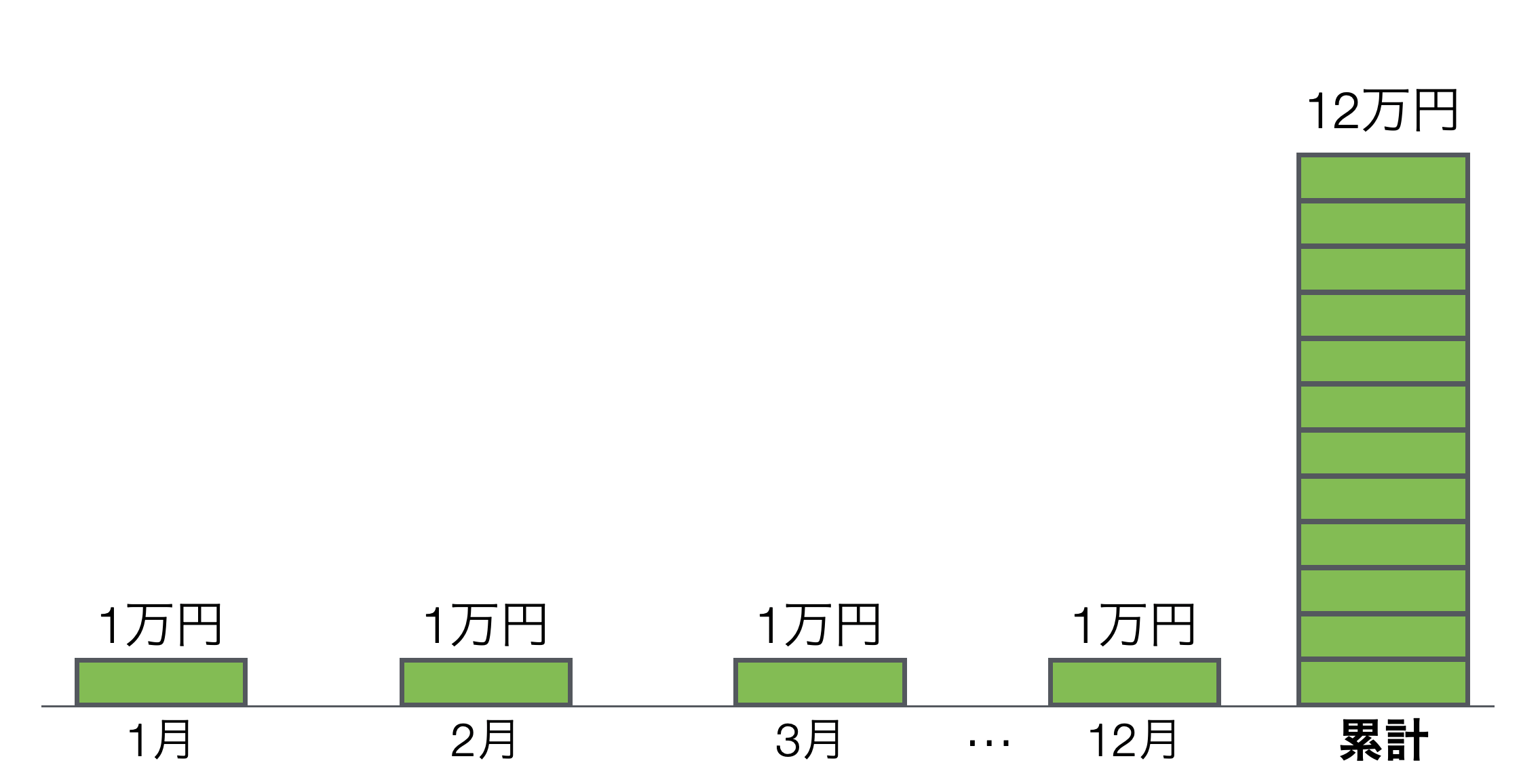
上記は顧客1人に注目した例ですが、次は「利用開始時期」で顧客をグループに分けて、それぞれのグループから得た収益の推移を可視化したチャートを使って、サブスクリプション型のビジネスの全体像を見てみます。
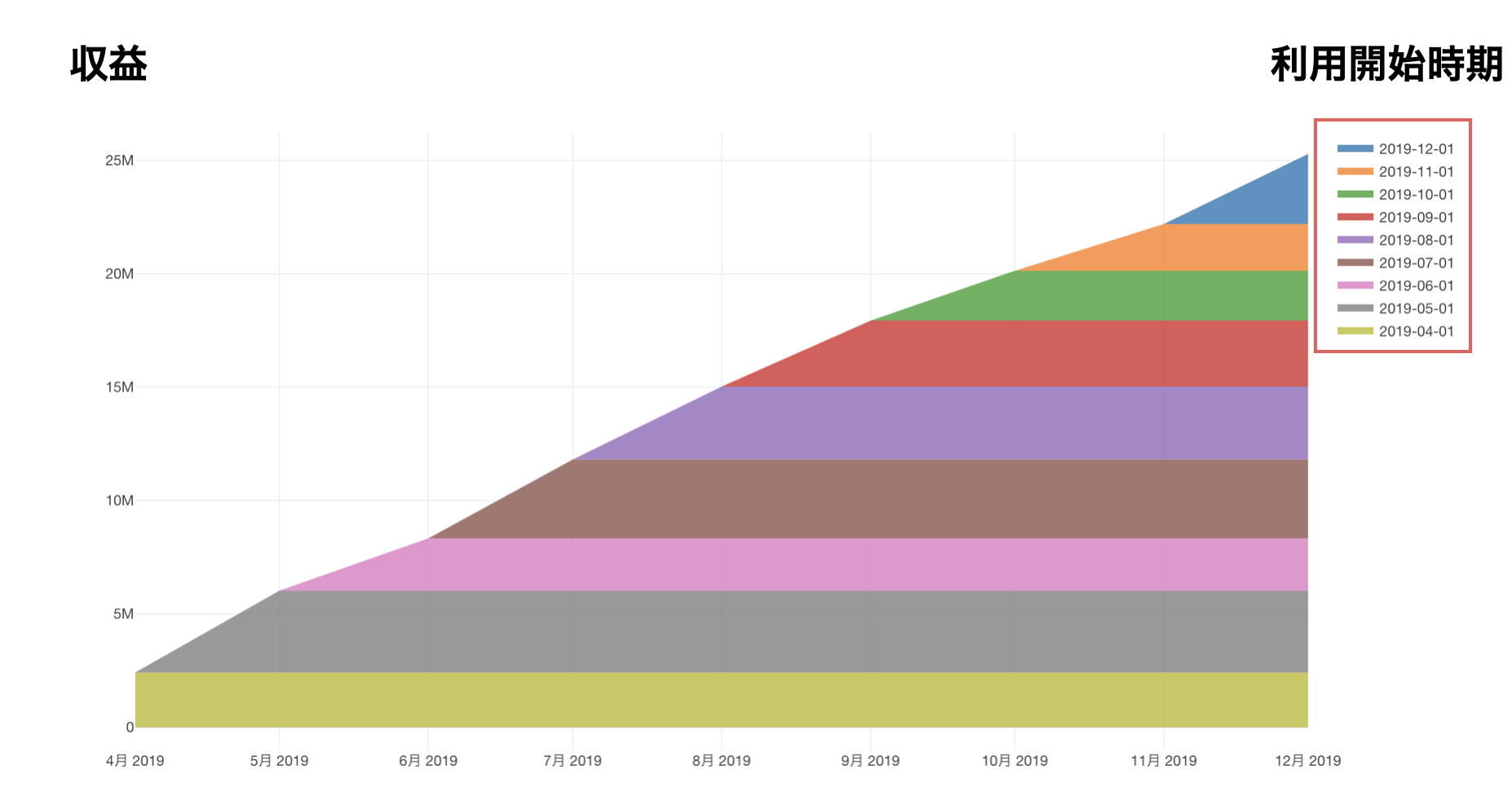
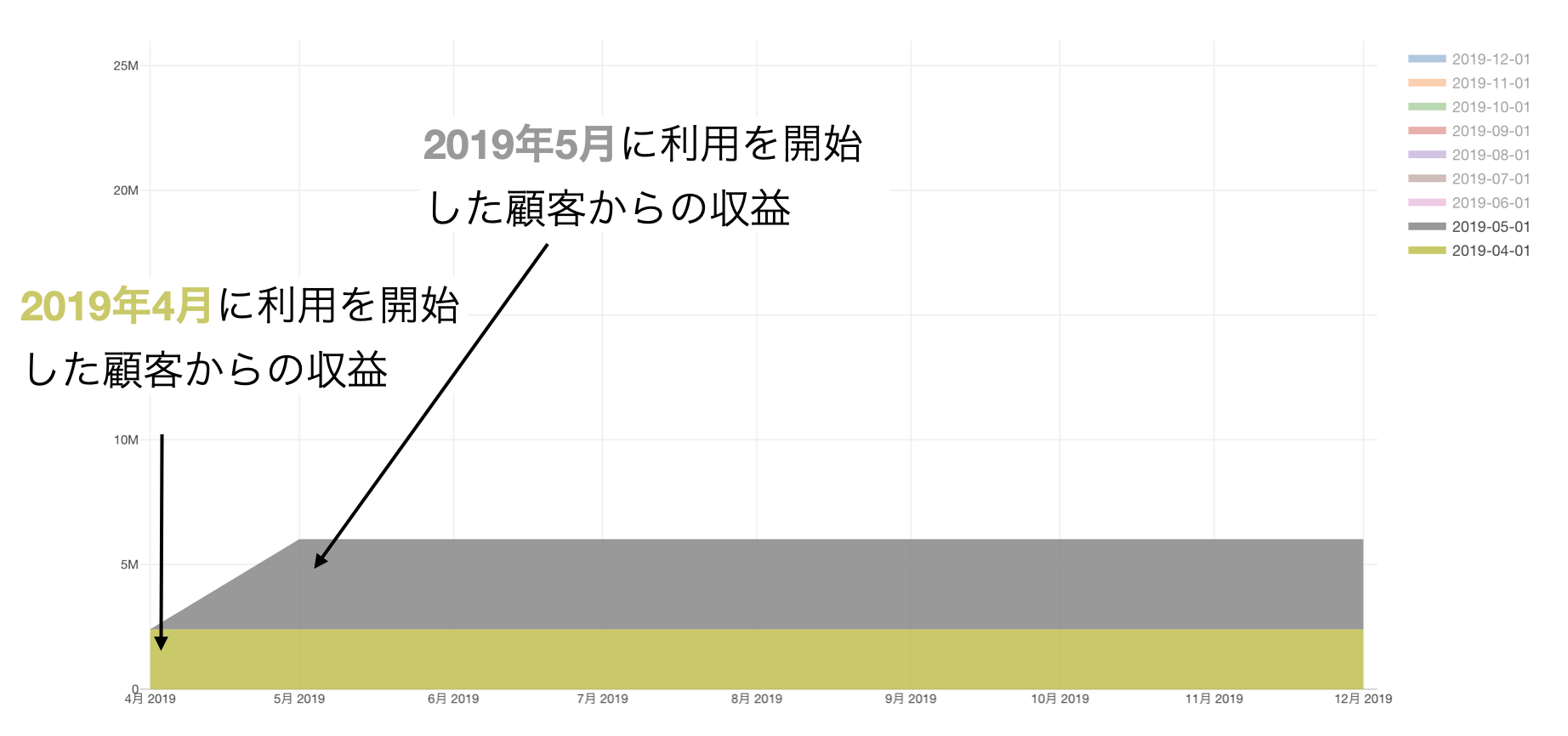
こういったチャートのことをサブスクリプション型のビジネスの世界では「レイヤーケーキ・チャート」と呼びますが、サブスクリプション型のビジネスでは下記のように過去に利用を開始した顧客の収益に、新しくサービスの利用を開始した顧客の収益が積み重なっていきます。
そのため、新しい顧客が利用を開始する度に、言い換えればコンバージョンが発生する度に、収益は積み上がり、ビジネスは成長します。
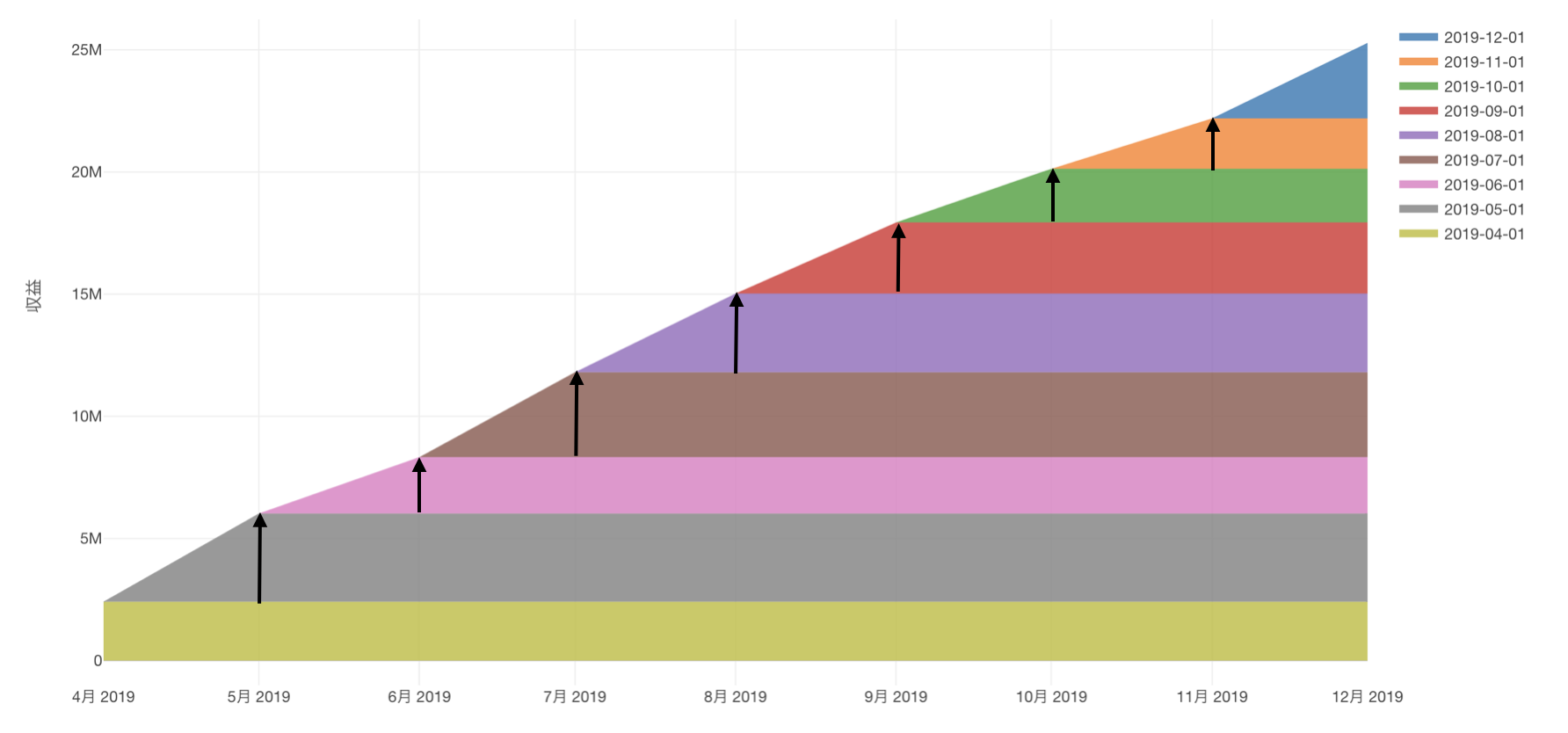
しかし実際のビジネスでは、時間の経過とともに顧客はサービスをキャンセルするので、得られる収益は減っていきます。
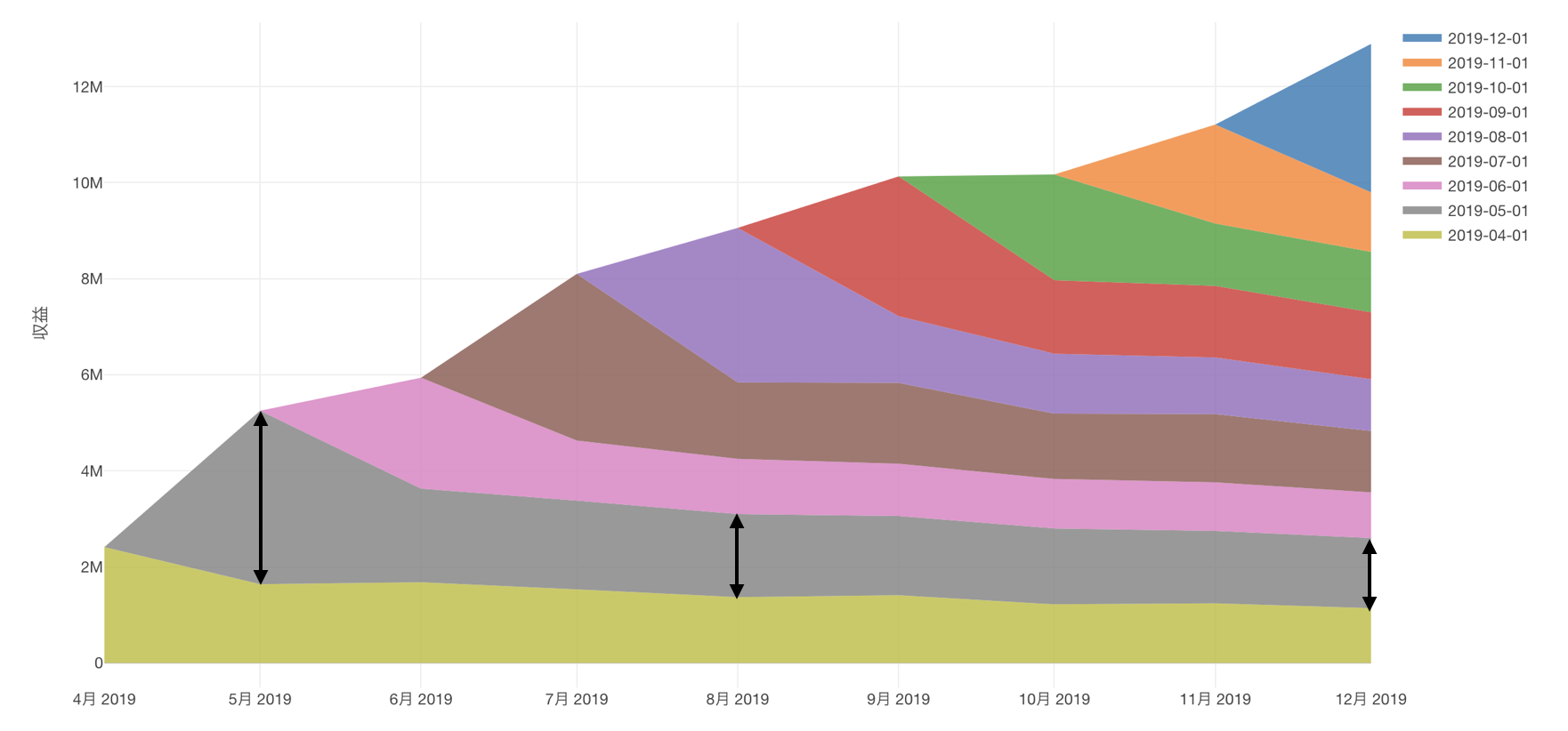
そのため、サブスクリプション型のビジネスではビジネスの成長を左右するコンバージョンとキャンセルの分析、具体的にはどういった顧客がコンバートあるいはキャンセルしやすいのかを理解することが重要です。
そしてコンバートしたりキャンセルしやすい顧客の特徴は、コンバージョンやキャンセルと相関する指標を見つけることで理解できます。
そのため、今回はコンバージョンやキャンセルを分析するときに役立つ5つの分析手法を紹介します。
1. 相関分析
そもそも「相関」とは、2つの変数のうち、1つの変数の値が変わると、もう1つの変数の値も一定の規則をもって一緒に変わる関係を表しています。
例えば、「Webサイトの滞在時間」が伸びるとコンバージョン率が上がるような関係を相関関係と呼びますが、相関関係が分かれば、コンバージョン率を改善する打ち手のヒントになります。
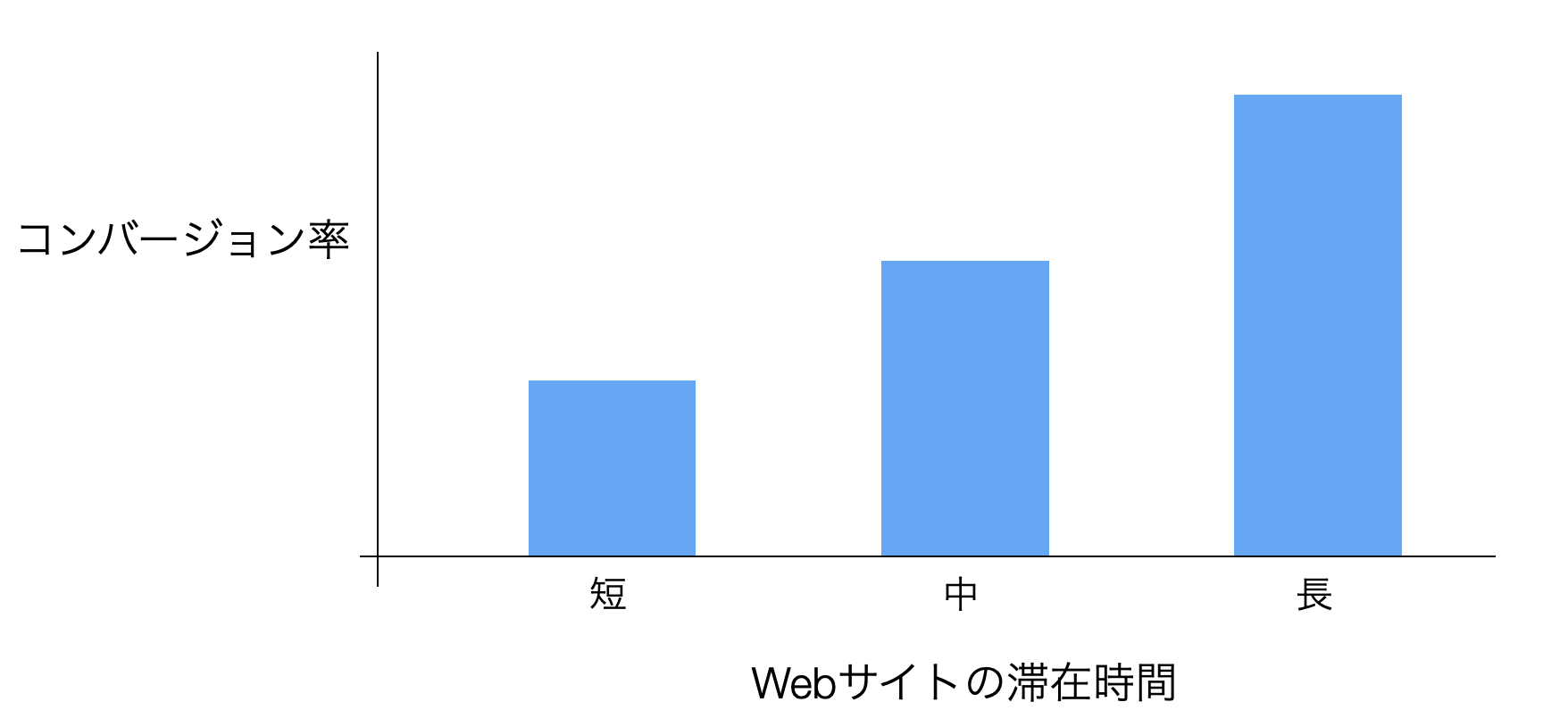
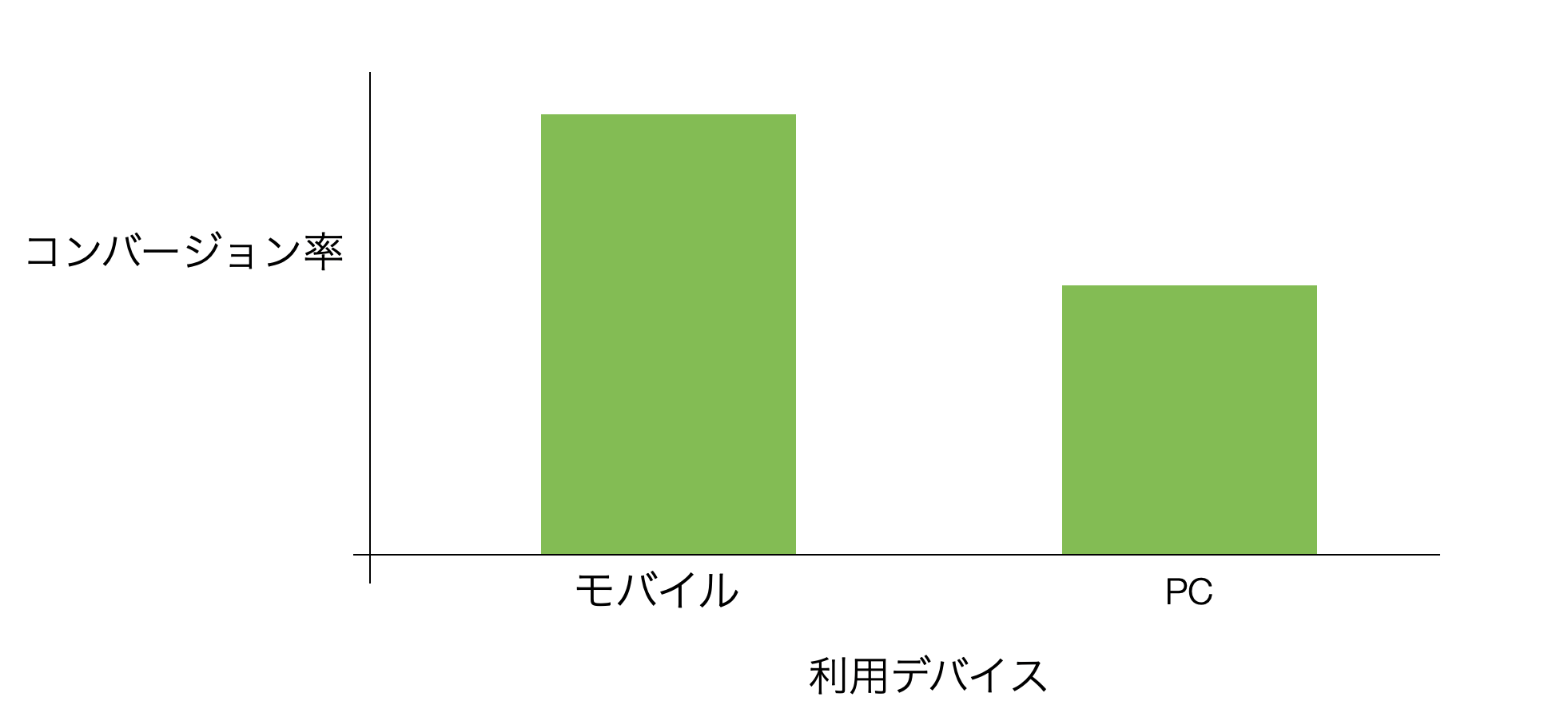
なお、カテゴリーが変わることによってコンバージョン率が変わるような関係も、相関関係となり、同じようにコンバージョン率を改善する打ち手のヒントになります。
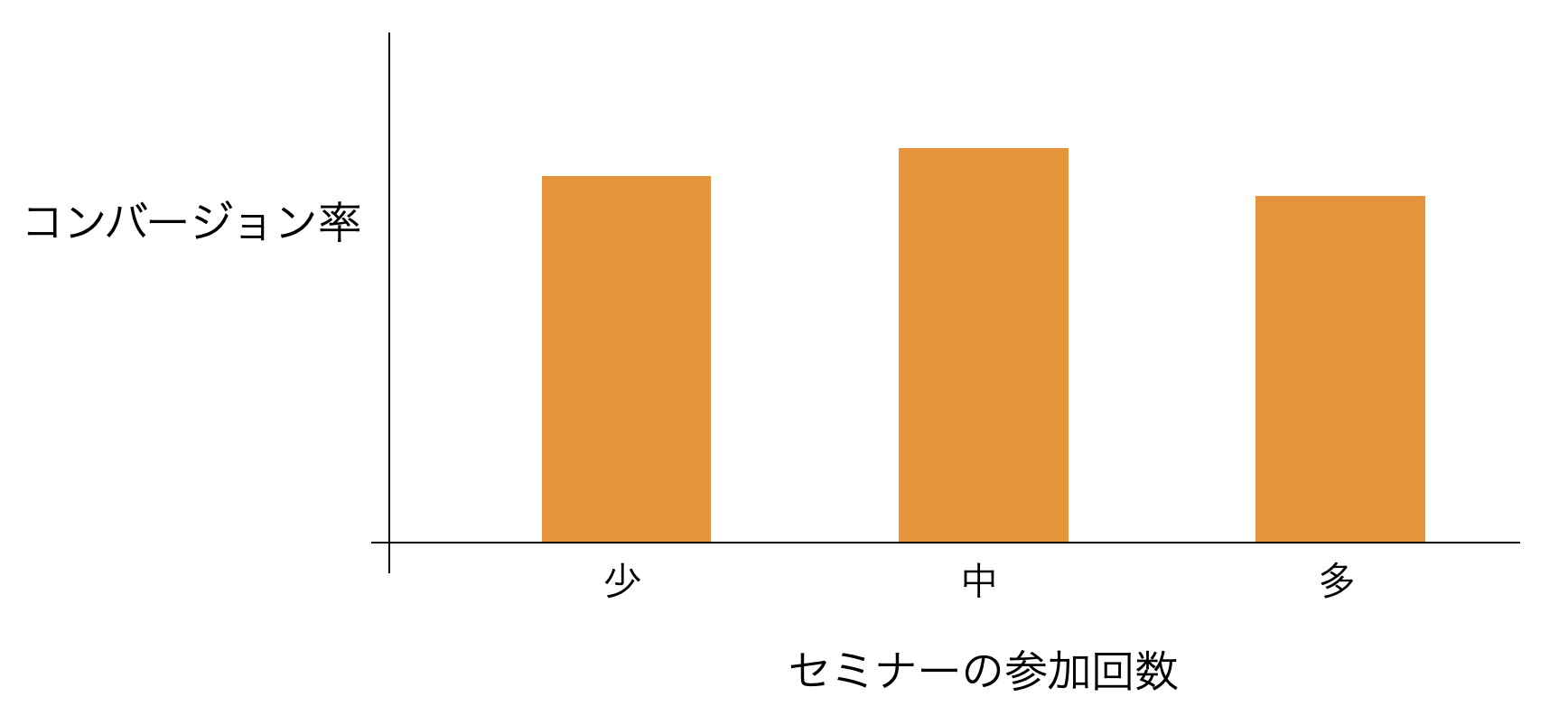
対して、「セミナーの参加回数」が増えてもコンバージョン率は変わらない、言い換えれば「セミナーの参加回数」とコンバージョンの間に相関がないようであれば、打ち手のヒントにはなりません。
一般的に、こういった相関関係を調べるときは、バーチャートなどを使って変数ごとにコンバージョン率を比べます。
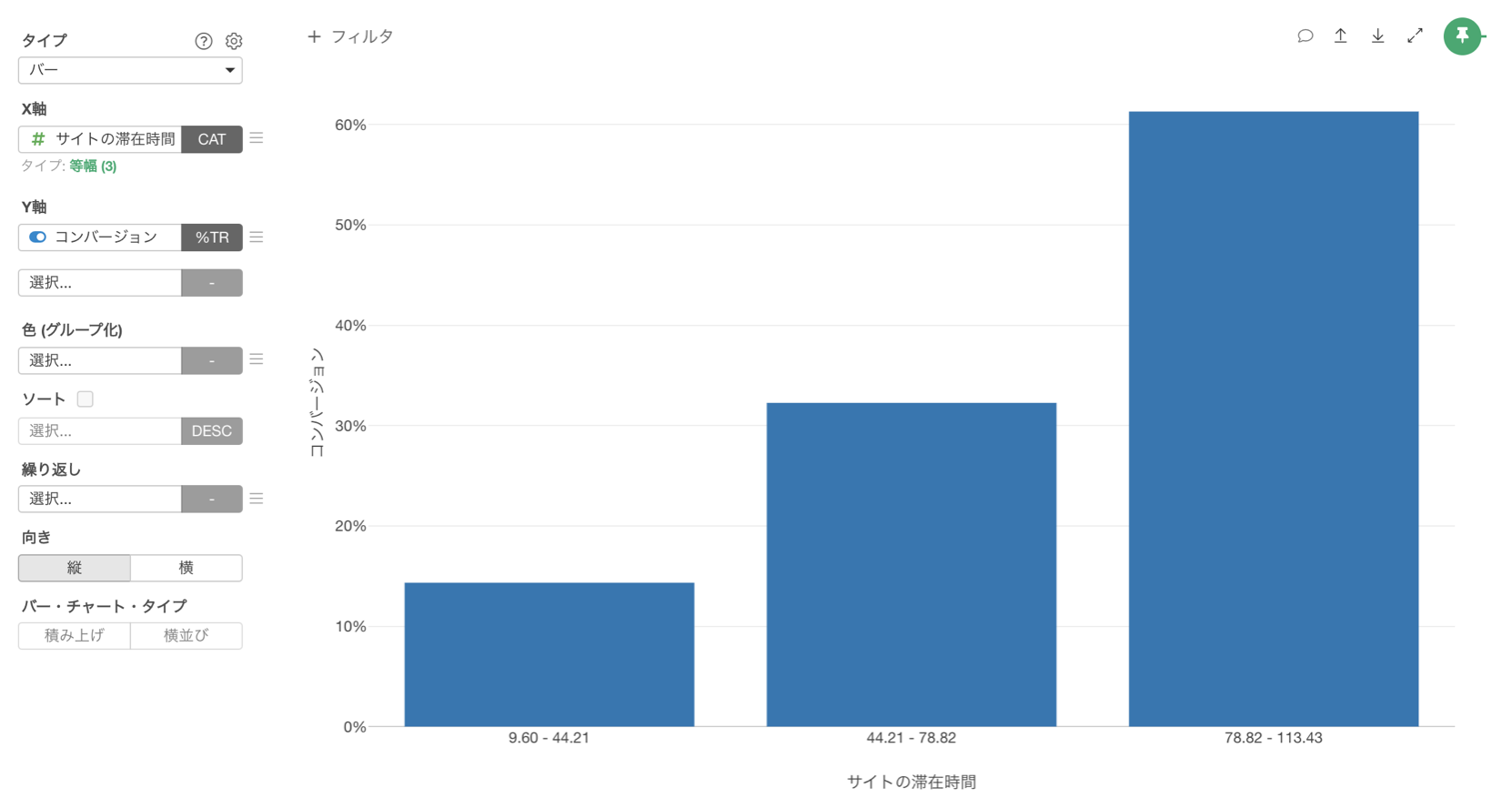
ただし、顧客から取得可能なデータは多く、全てのデータを使って沢山のバーチャートを作って、コンバージョン率を比べるのは手間がかかります。
そこで、例えば、データの加工、可視化、分析、レポーティングのためのUIツールのExploratoryでは、「相関モード」を利用して、注目している変数(コンバージョン)と、他の変数の相関関係を一度に調べることができます。
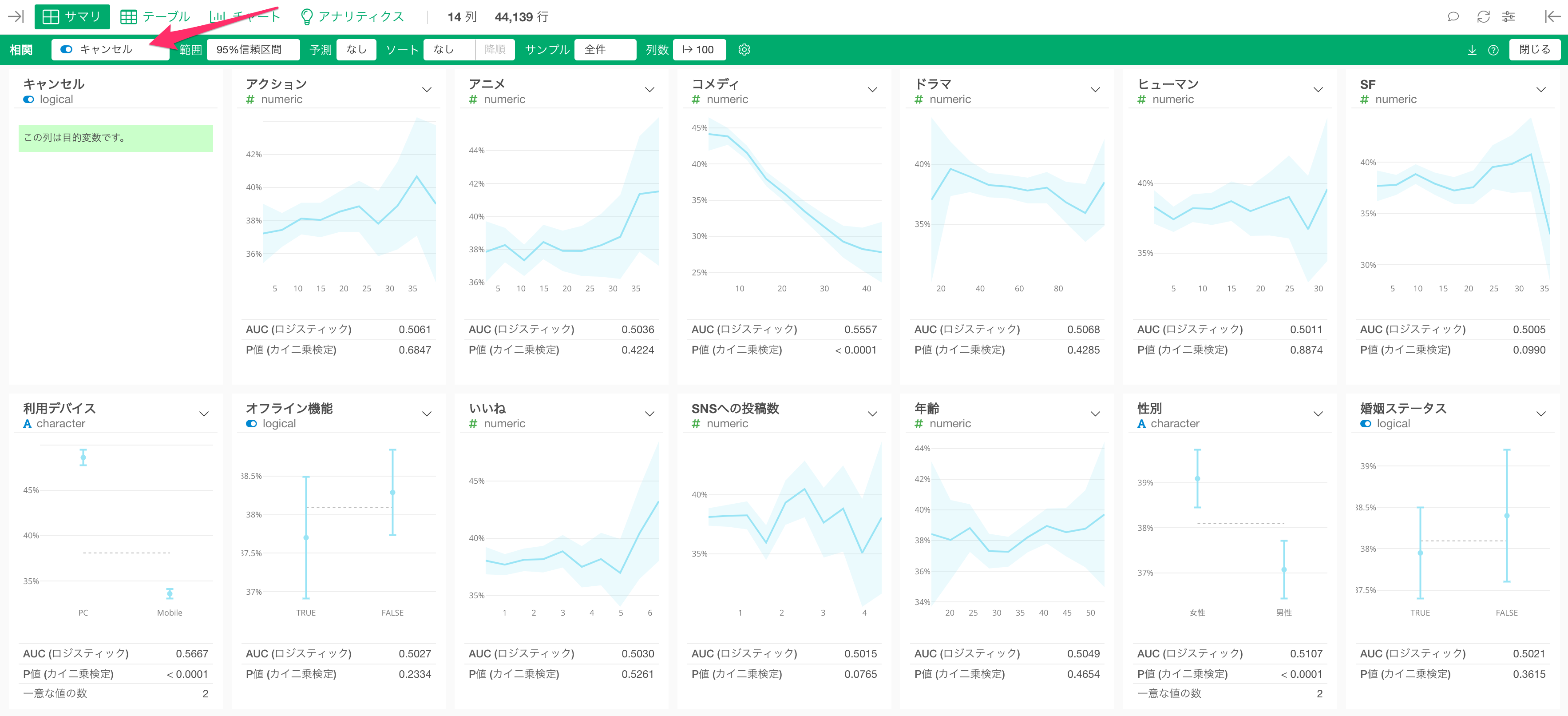
さらに「相関モード」では、コンバートしたかどうかのように、Yes/Noで答えられるロジカル型の変数との相関の強さを表す指標の「AUC」も計算するため、「AUC」が大きい順、つまり、相関が強い順に各変数をソートして、コンバージョンと相関が強い変数を一瞬で確認できます。
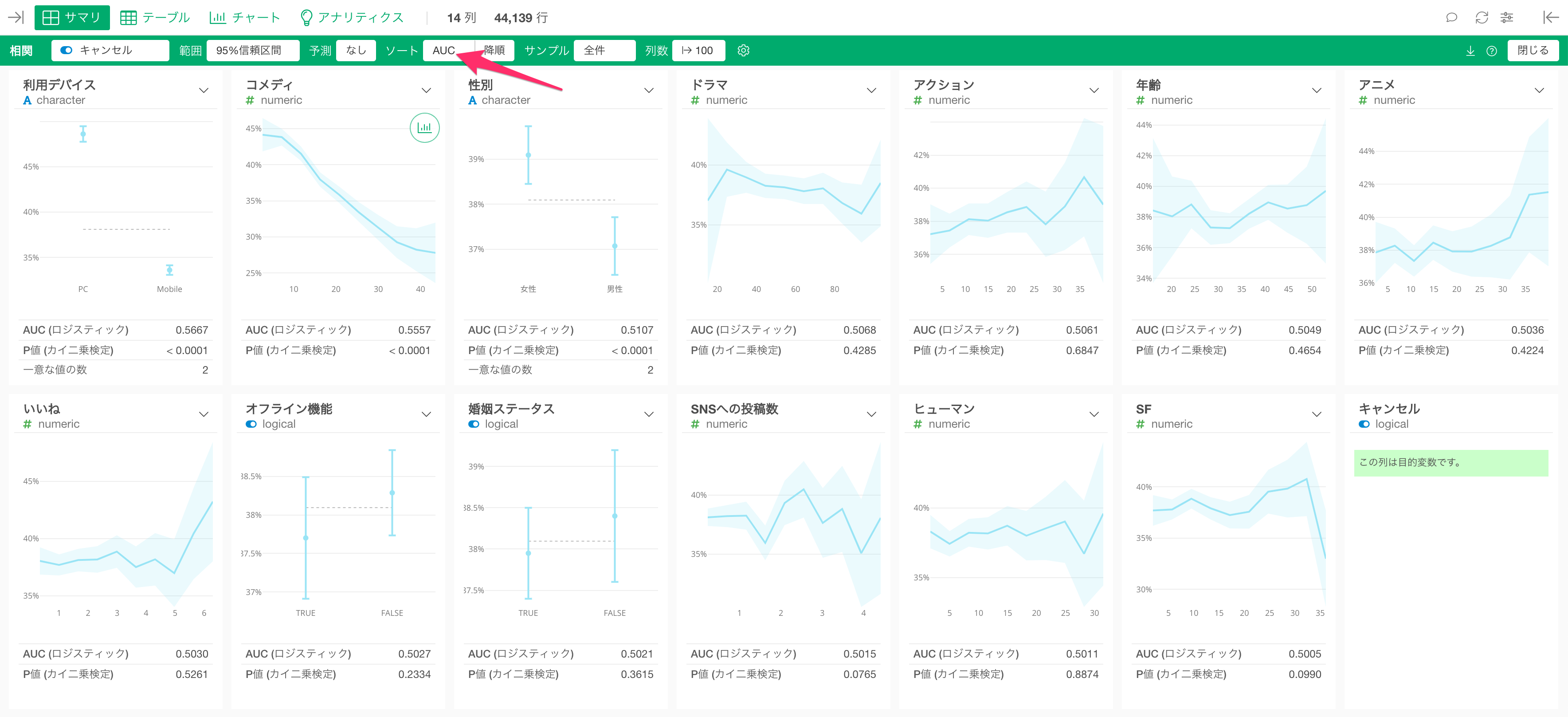
2. 多変量解析
変数ごとにコンバージョン率を比較し、コンバージョンとの相関を調べるとことは可能ですが、注意が必要なことがあります。
それは、相関関係と因果関係は違うということです。
このことを、サメの襲撃件数とアイスクリームの売上を可視化したビジュアルを使って、簡単に説明していきます。
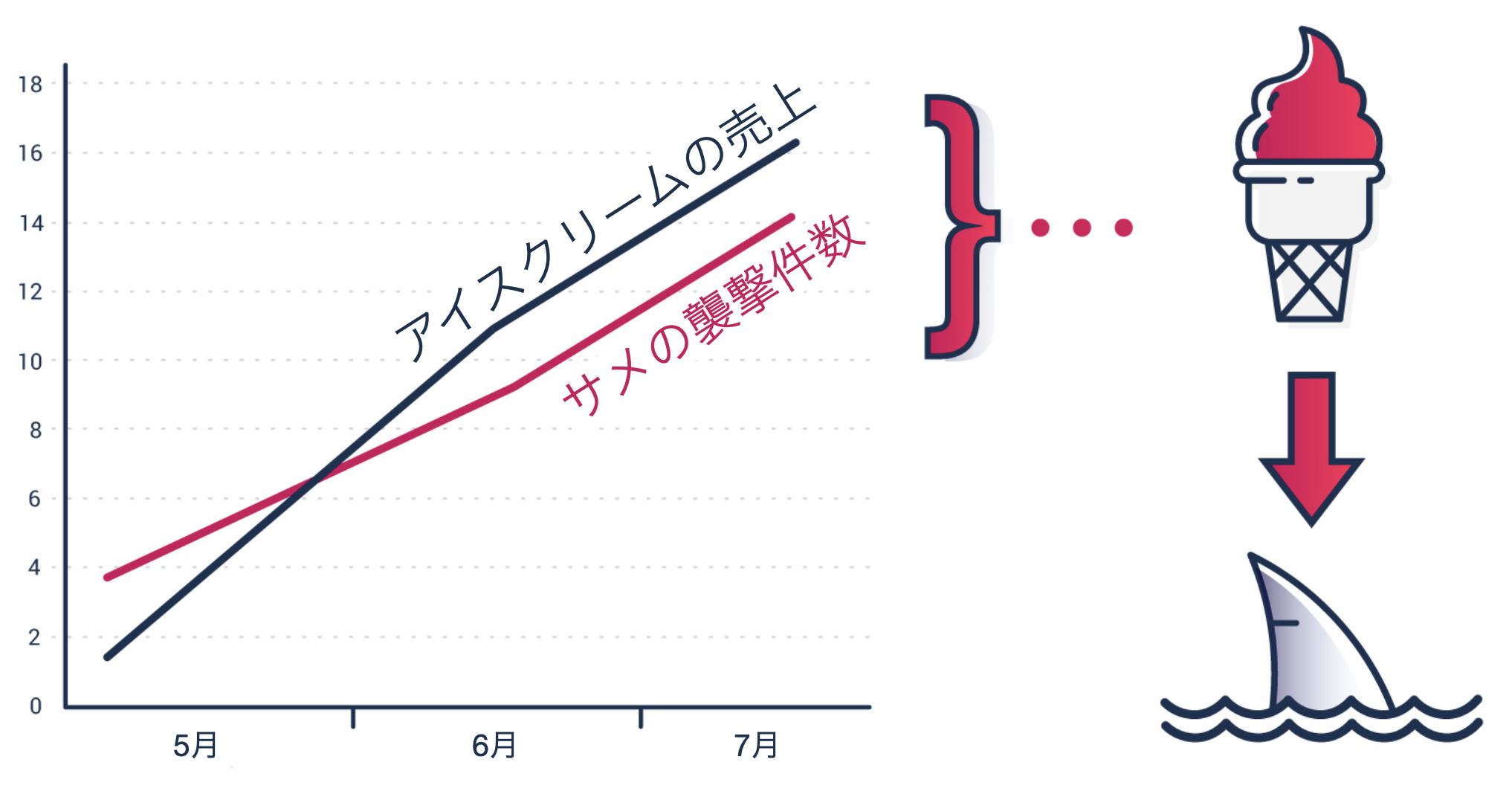
上記のチャートからは、例えばアイスクリームの売上が増えると、サメの襲撃件数が増えるような関係を読み取れます。
しかし実際のところ、そのような関係や、その逆の関係があるとは考えづらく、夏が近づくにつれて気温が上がるためアイスクリームを食べる人が増えたり、海に入る人が増えるためサメの襲撃件数が増えていることが想定されます。
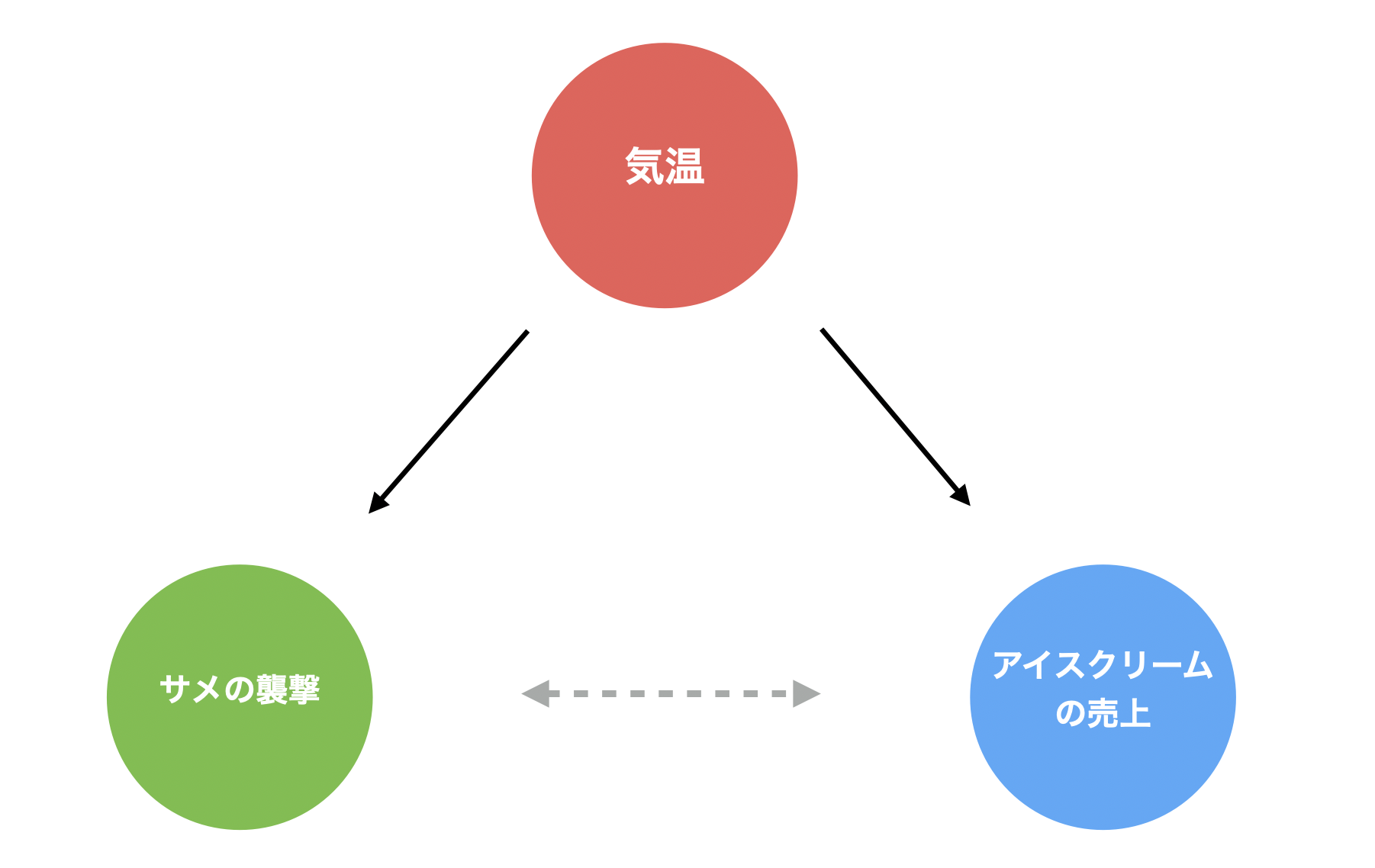
ただし、先程のチャートだけを見ていると、気温が上がるとサメによる襲撃回数とアイスクリームの売上が増えるような関係があるにも関わらず、気温が上がるとアイスクリームの売上が上がるような関係があるため、その結果として、あたかもアイスクリームの売上が増えるとサメによる襲撃回数が増えるような関係を見出してしまうことがあります。
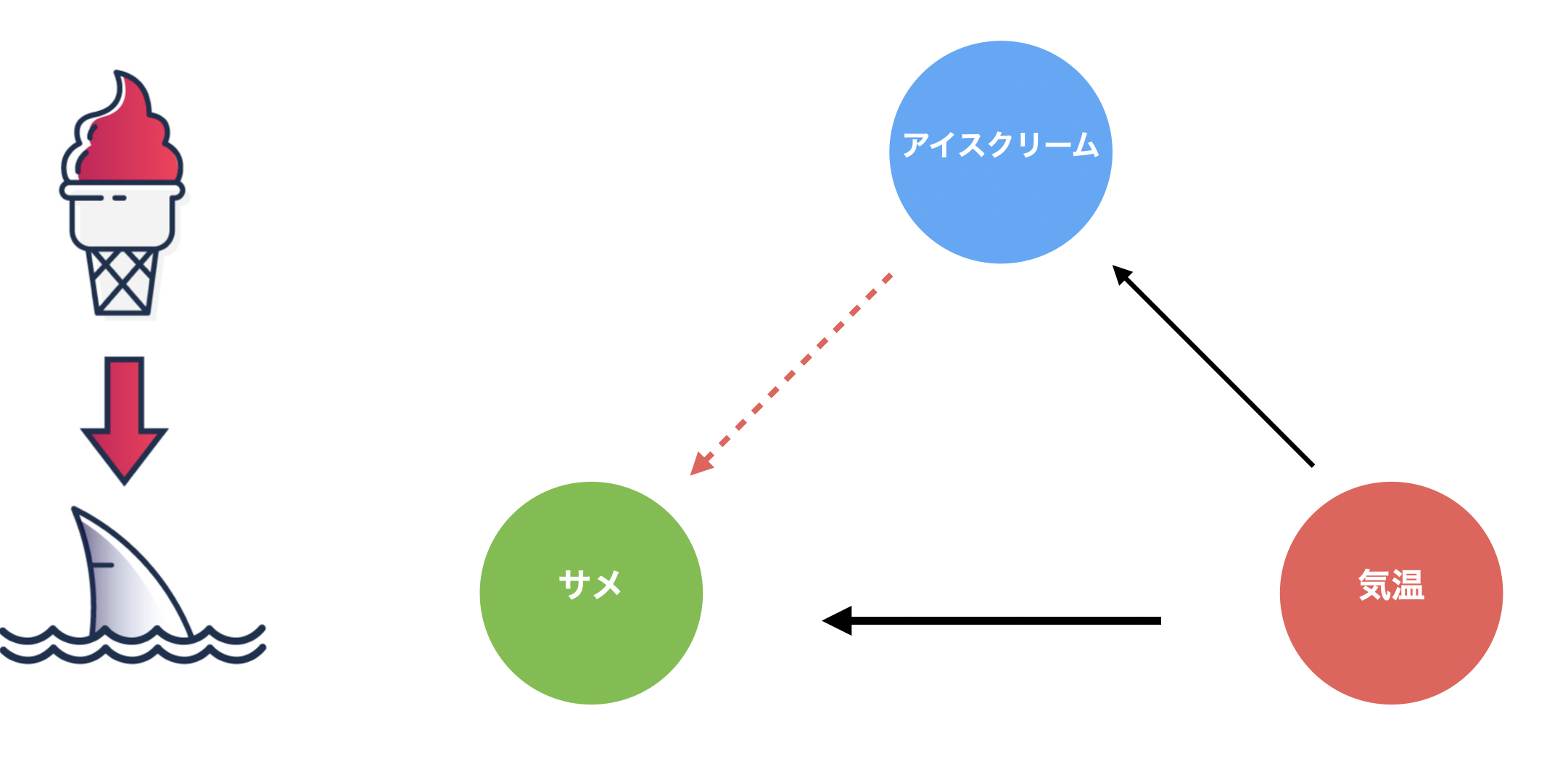
今回の例は極端なため、常識的に考えて、アイスクリームの売上が増えることでサメの襲撃件数が増えるような関係はないことがわかりますが、変数がビジネスの変数に置き換わったり、扱う変数が増えていくと、こういった関係に気付かず、誤った因果関係を自分の頭の中に描いて、不適切な行動を起こしてしまう(例: サメの襲撃件数を減らすために、アイスクリームの販売をやめてしまう)こともあります。
例えば、無料のトライアル期間を提供するNetflixのような動画視聴サービスを例に考えてみます。
このサービスでは、ドラマの視聴時間が伸びるとコンバージョン率が高くなることや、女性の方が男性と比べるとコンバージョン率が高いことが分かっていました。
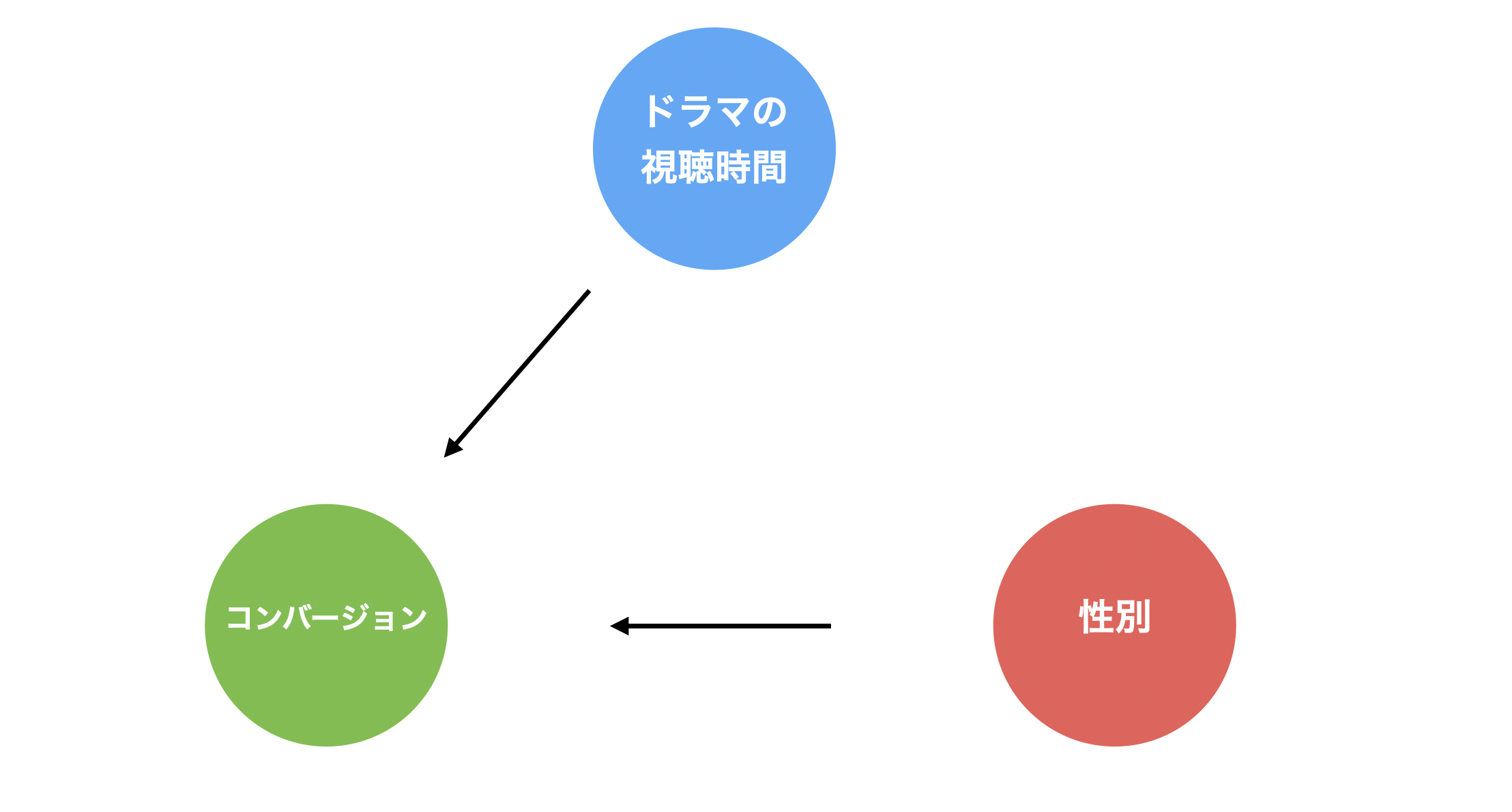
しかし、「サメ」と「アイスクリーム」の例のように、実は「ドラマの視聴時間」と「性別」の間には、「女性はドラマの視聴時間が長い」という相関関係があるかもしれません。
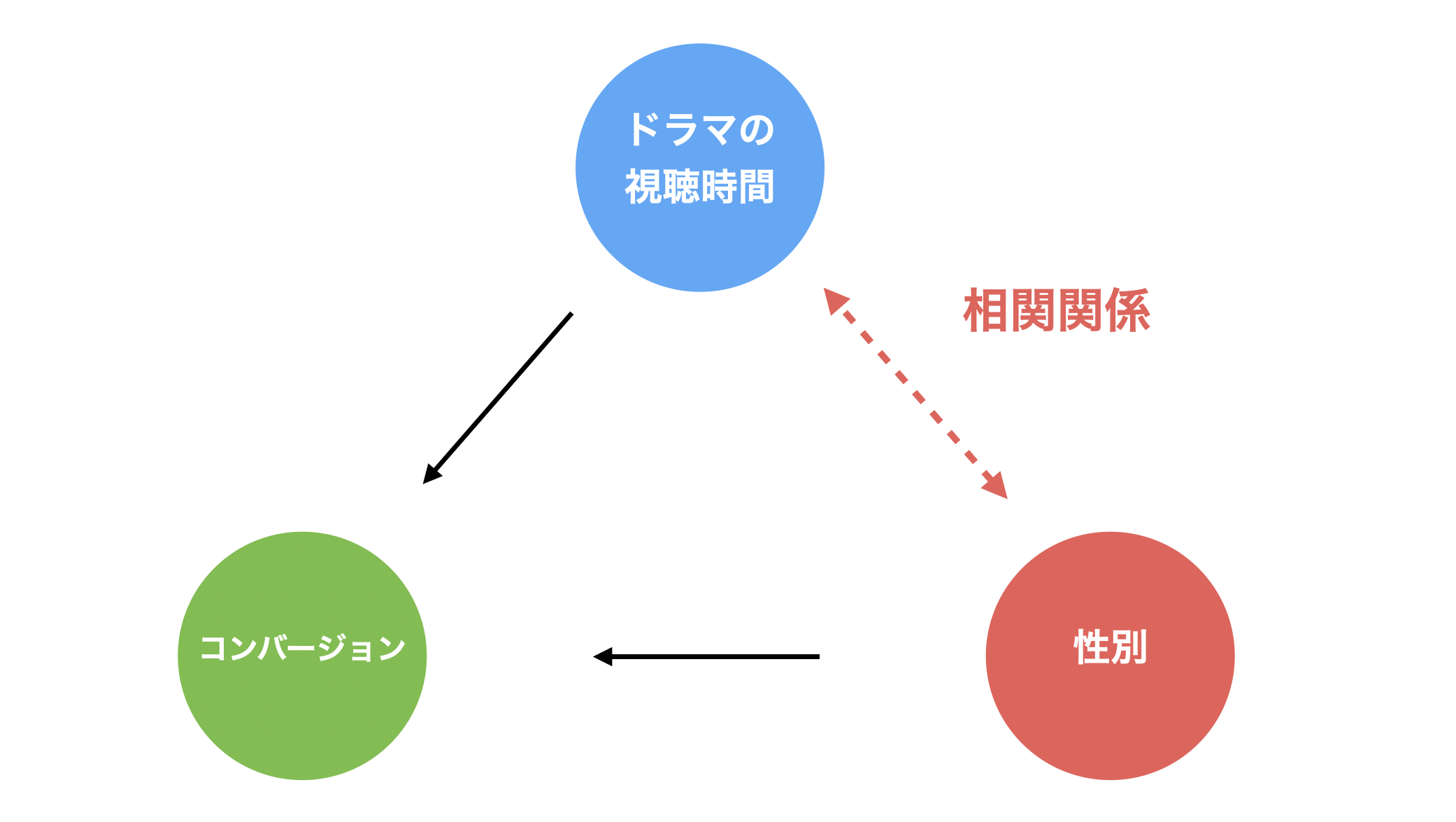
すると、コンバージョン率のチャートからだけでは「どちらがコンバージョンに影響を与えていそうなのか」、あるいは「両方の変数がコンバージョンに影響を与えていそうなのか」を理解できません。
では、どうすれば、コンバージョンとの関係を適切に捉えられるかと言うと、ドラマの視聴時間を一定にして性別のみを変化させたとき、コンバージョンが変化するのであれば、性別とコンバージョンの間は関係があることがわかります。
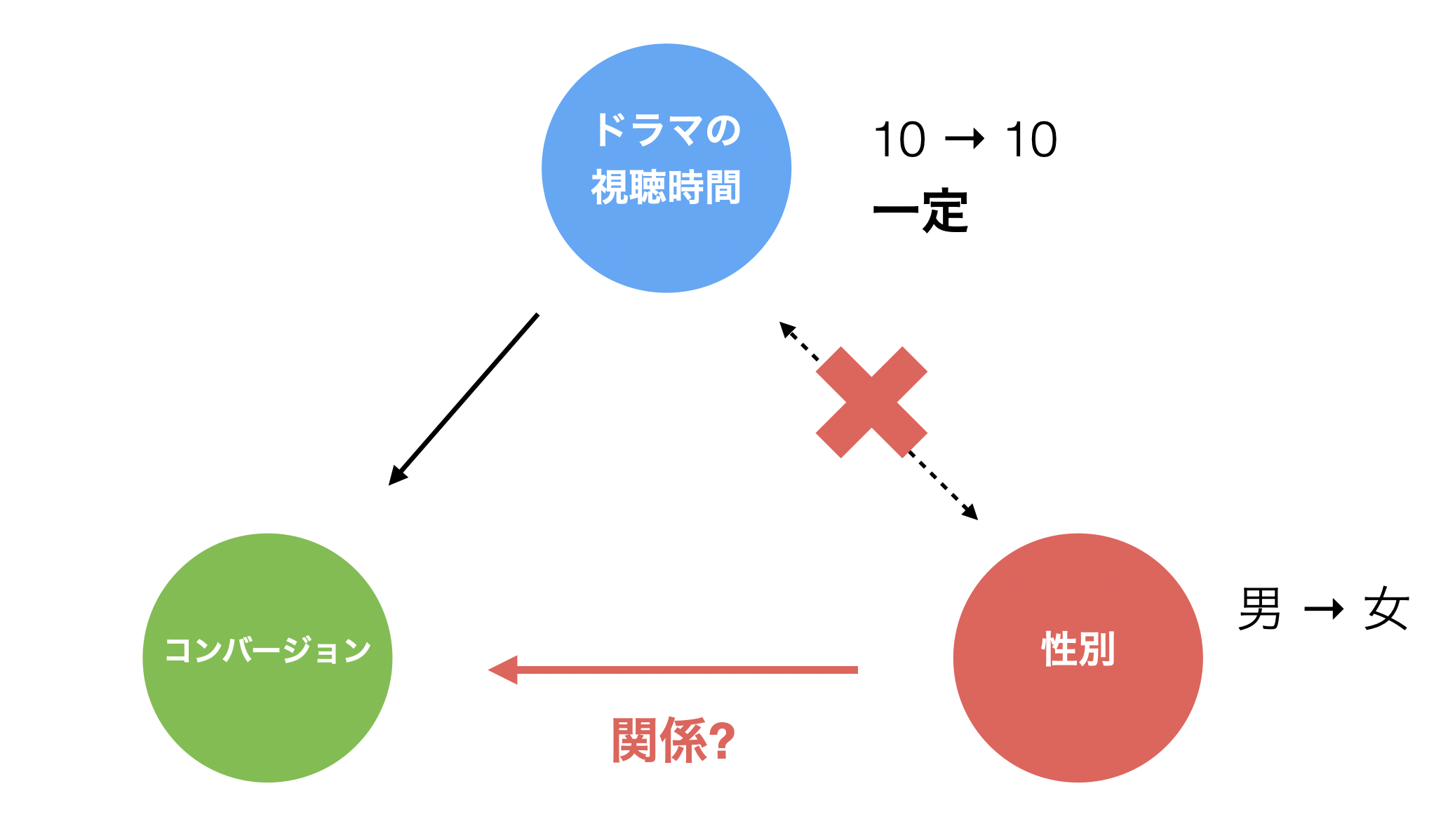
逆に性別を一定にしてドラマの視聴時間のみを変化させたとき、コンバージョンが変化するのであれば、ドラマの視聴時間とコンバージョンの間は関係があることがわかります。
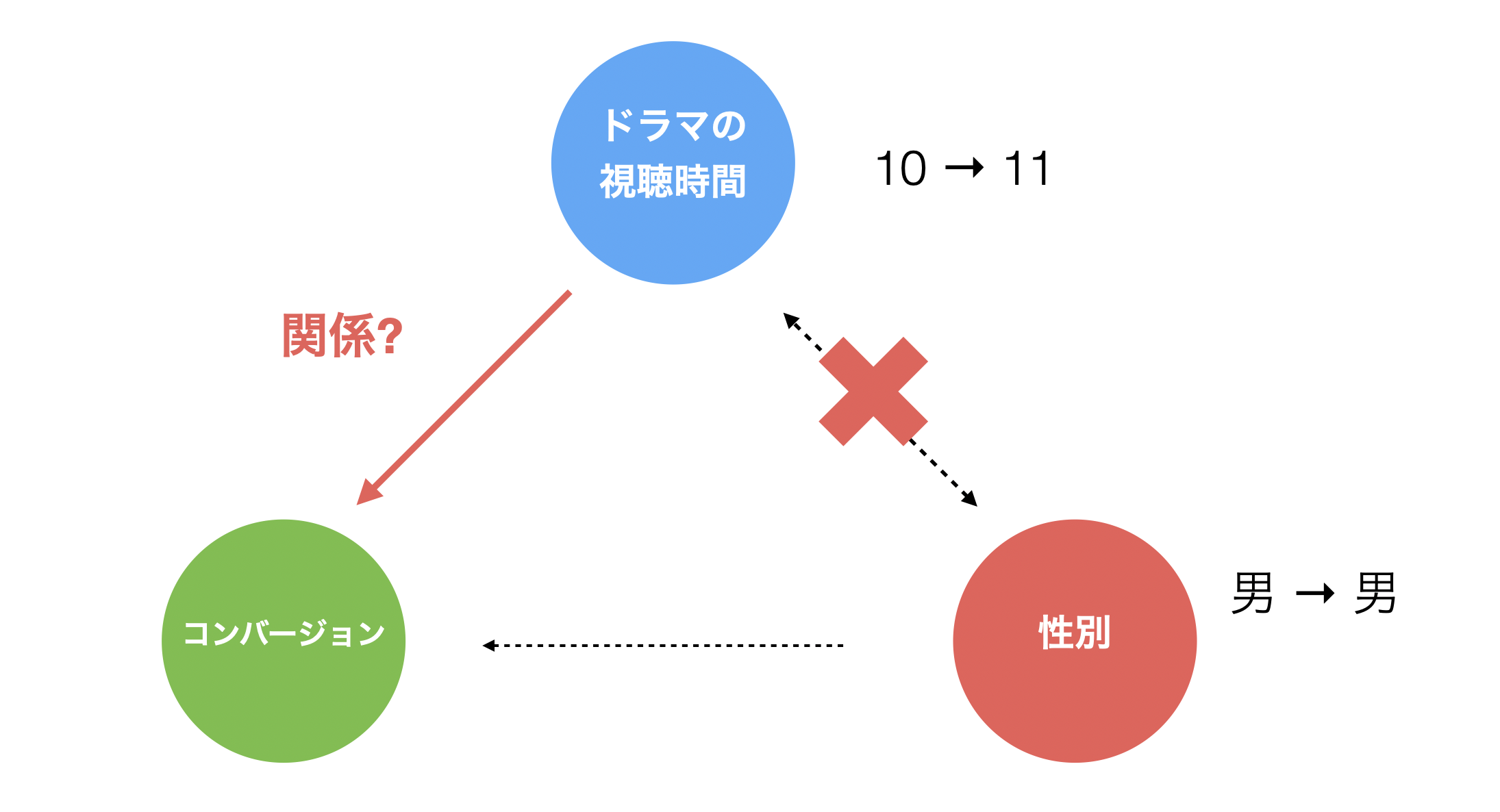
こういったことは統計学習の予測モデルを作ると調べることができ、一般的にこうした分析手法を多変量解析と呼びます。
また、顧客のコンバージョンに対する「多変量解析」を実施したいときは、統計学習のアルゴリズムの、「ロジスティック回帰」を利用します。
なお、Exploratoryでは先程紹介した相関モードから数クリックで、ロジスティック回帰の予測モデルを簡単に作れます。
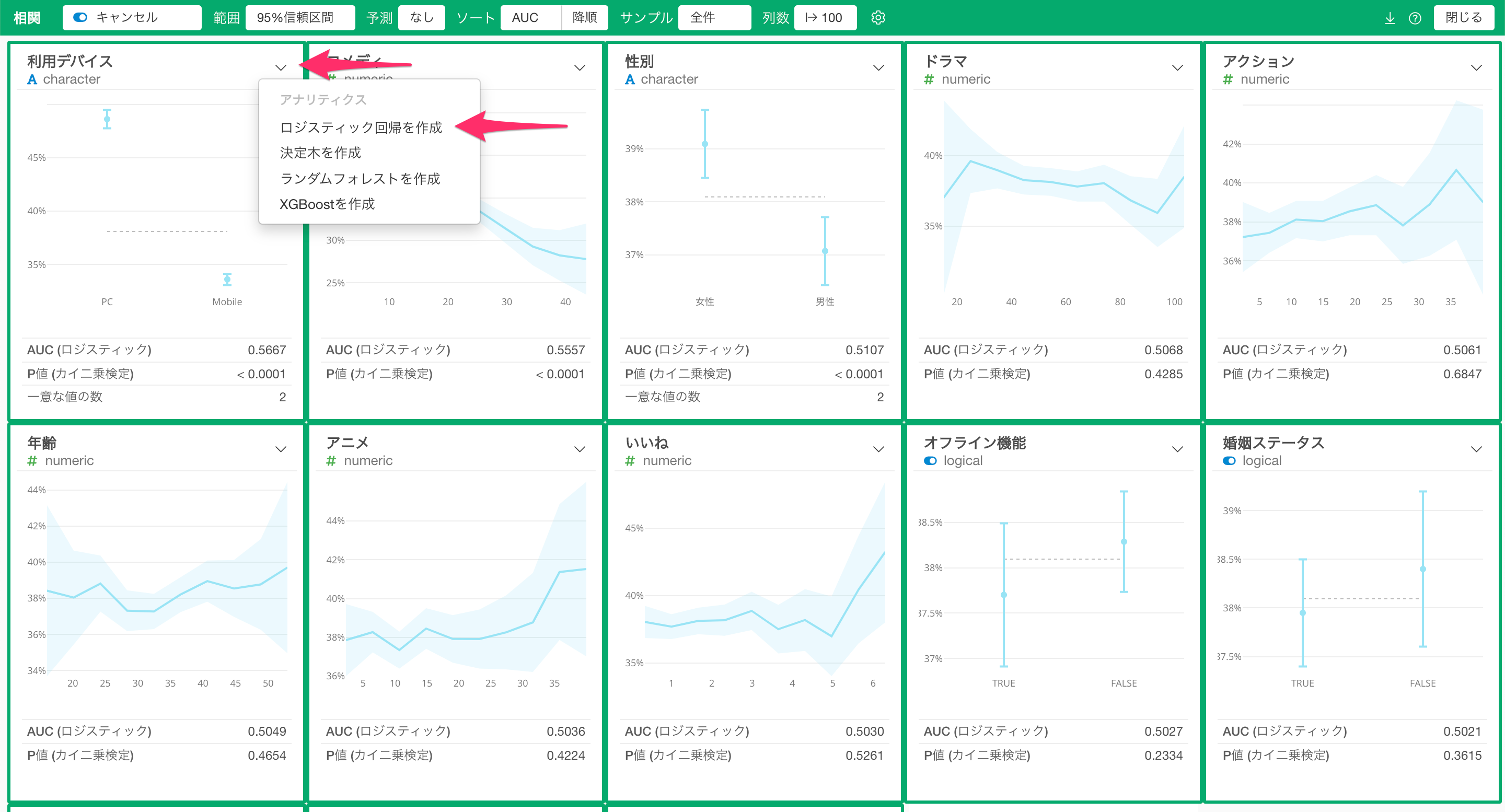
ロジスティック回帰の予測モデルを作成すると複数のタブが表示されます。各タブの情報は「アナリティクスの文法」という仕組みを使って直感的に解釈でき、「他の変数の値が一定だったときの各変数のコンバージョンへの効果」を調べたうえで、例えば、どの変数が「コンバージョンとの相関がより強いのか」や、「コンバージョンと関係があると言えそうか」を理解できます。
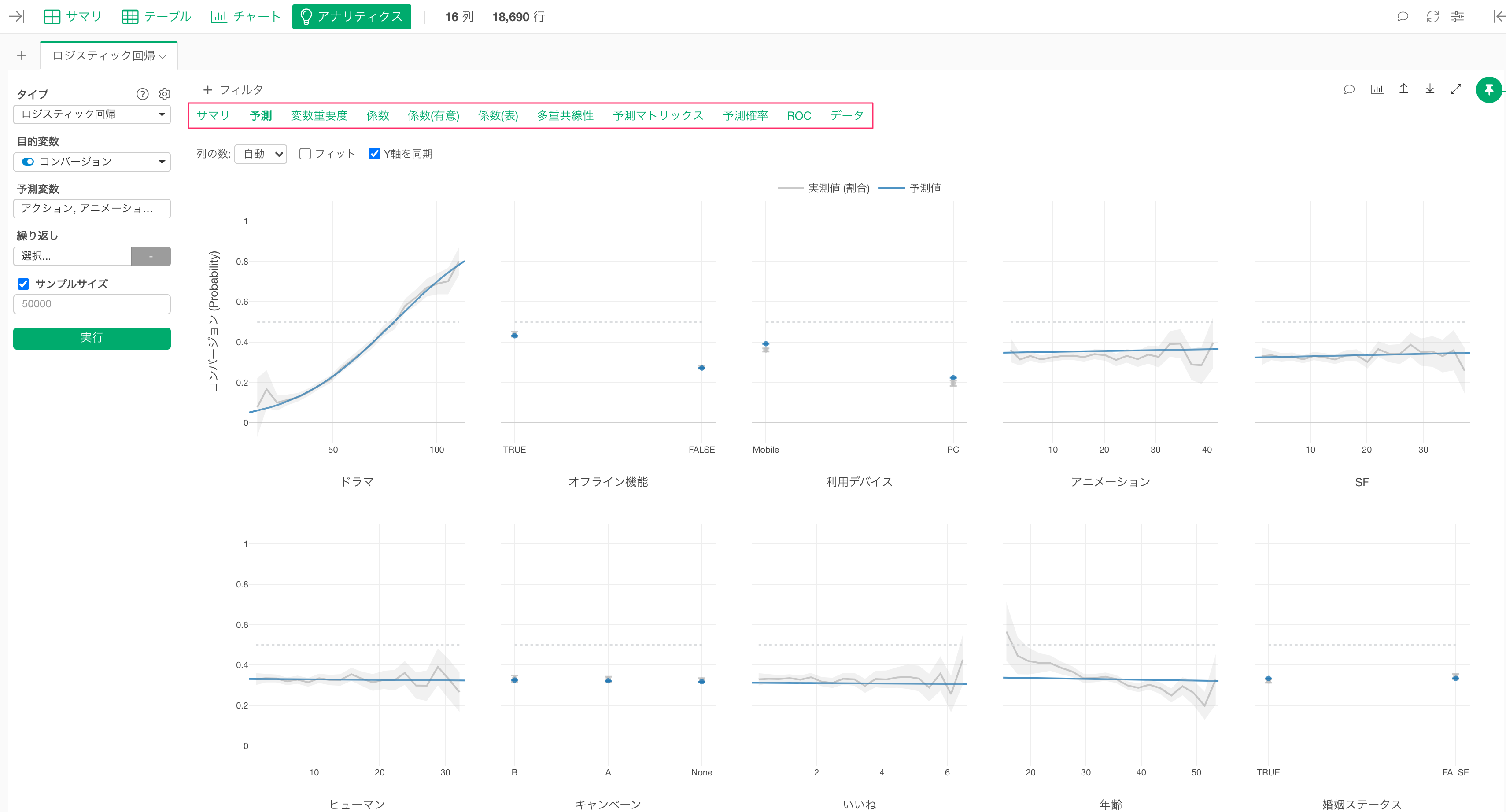
予測と機械学習のモデル
さらに、こういった予測モデルを使うと、まだコンバージョンが発生していない見込み顧客がコンバートする確率を予測できます。
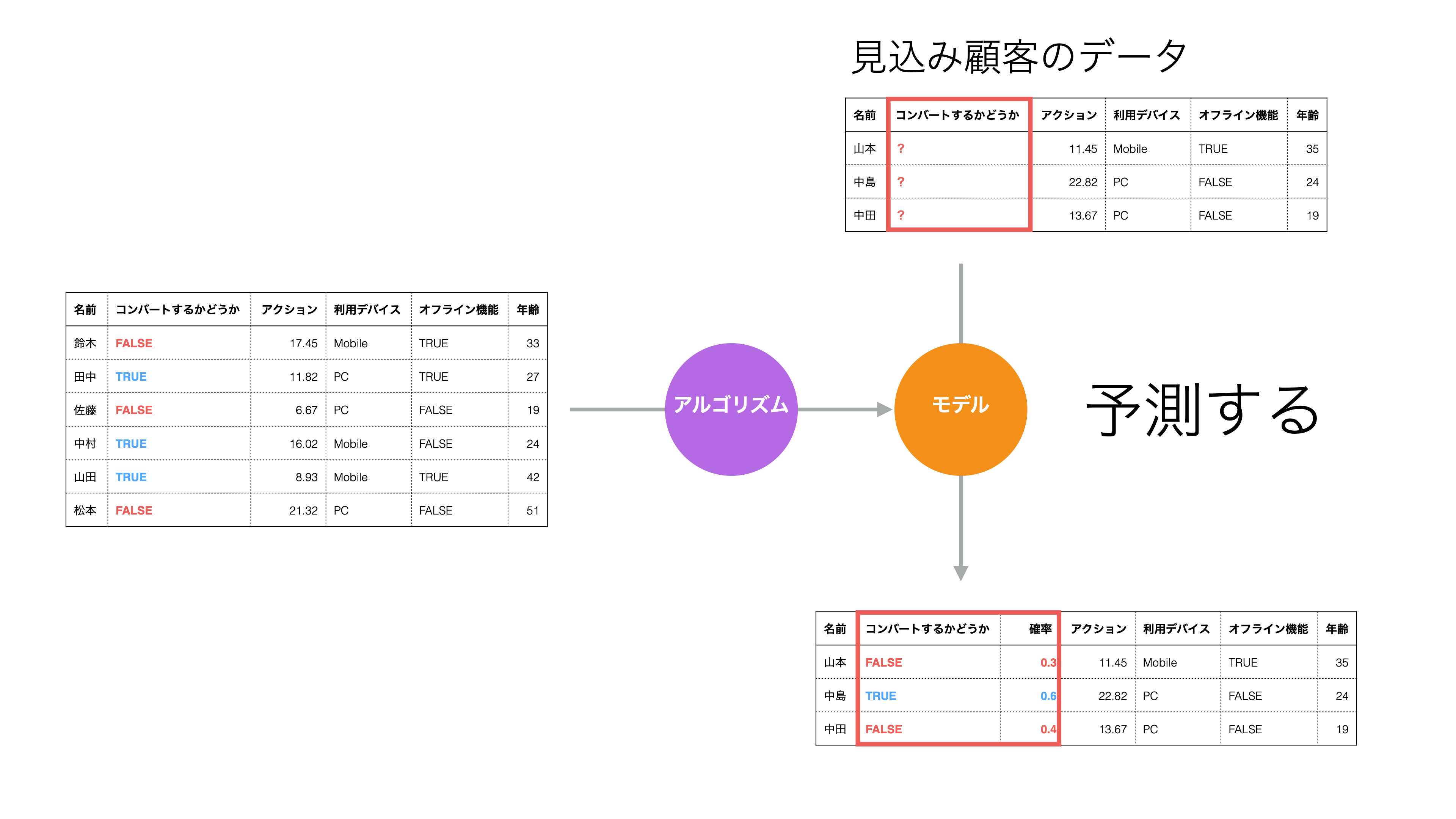
コンバージョンが発生する確率がわかれば、例えば、その確率が高い顧客を重点的にサポートして、コンバージョンを増やすためのアクションが打てるわけです。
ただし、全く当たらない予測を元にアクションをしていては意味がないので、予測結果を元に何らかのアクションをするときには「予測精度」が重要になります。
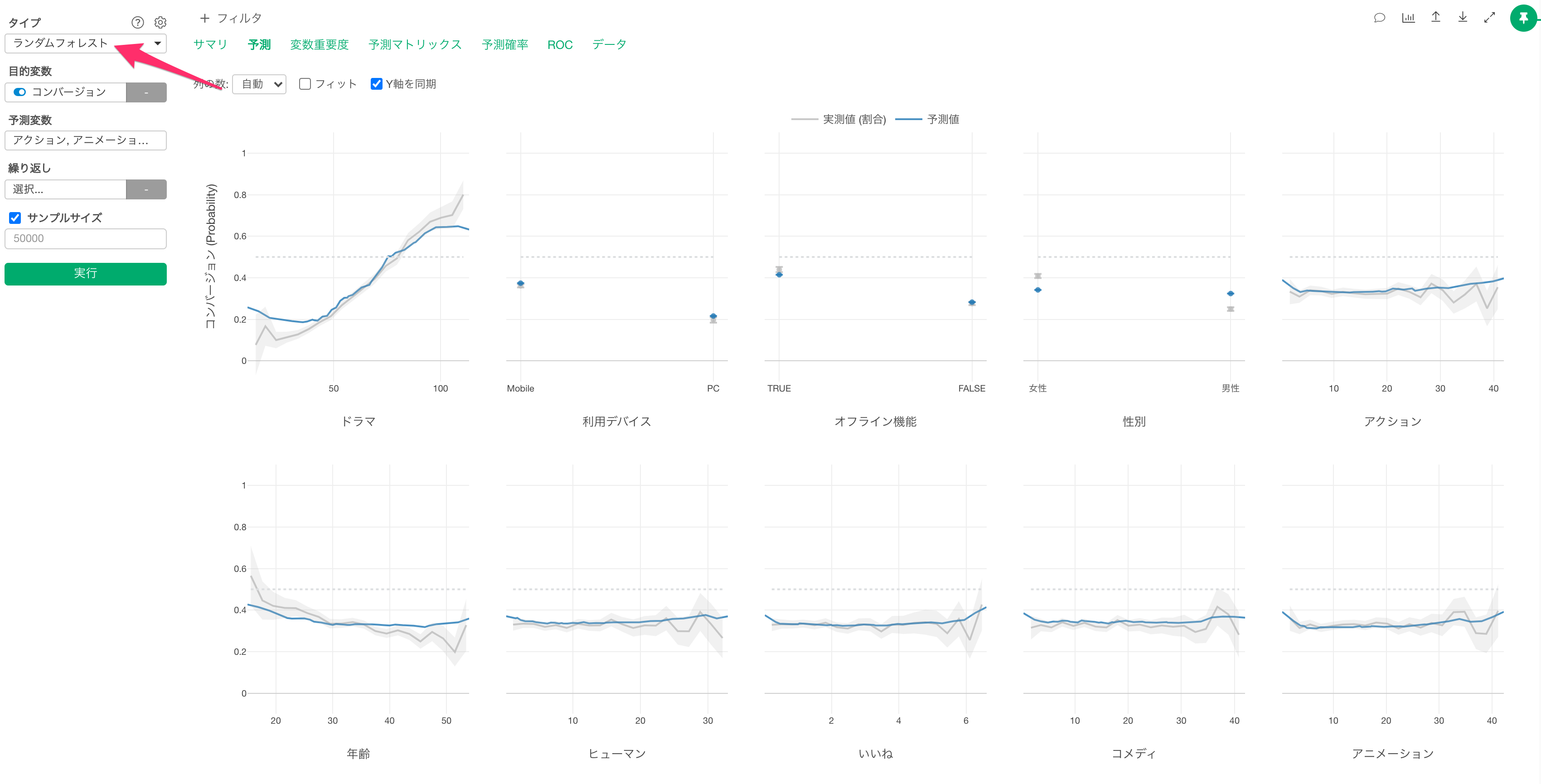
そこで、高い予測精度を得やすい「ランダムフォレスト」や「XGBoost」といった機械学習の予測モデルが、予測の際には、よく使われます。
Exploratoryでも作成した予測モデルを使って、新しいデータに対して、数クリックでコンバージョンが発生する確率を予測をしたり、
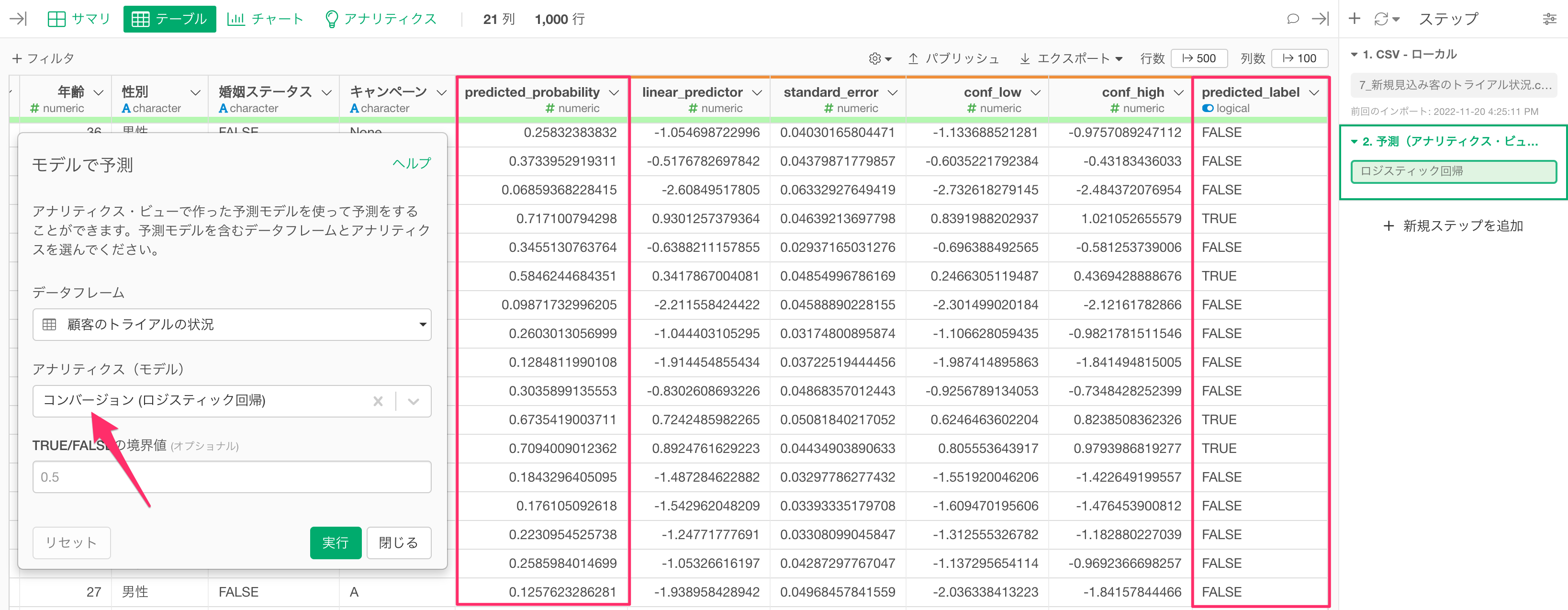
予測に使うモデルのタイプを変更して、「ランダムフォレスト」や「XGBoost」を使った予測モデルの構築が可能です。
3. コホート分析(生存分析)
続いてキャンセルの分析の話に入っていきます。
キャンセルの分析をするときも、コンバージョン率との相関を分析したときと同じように、キャンセル率の差を比べがちですが、1つ気をつけるべきことがあります。
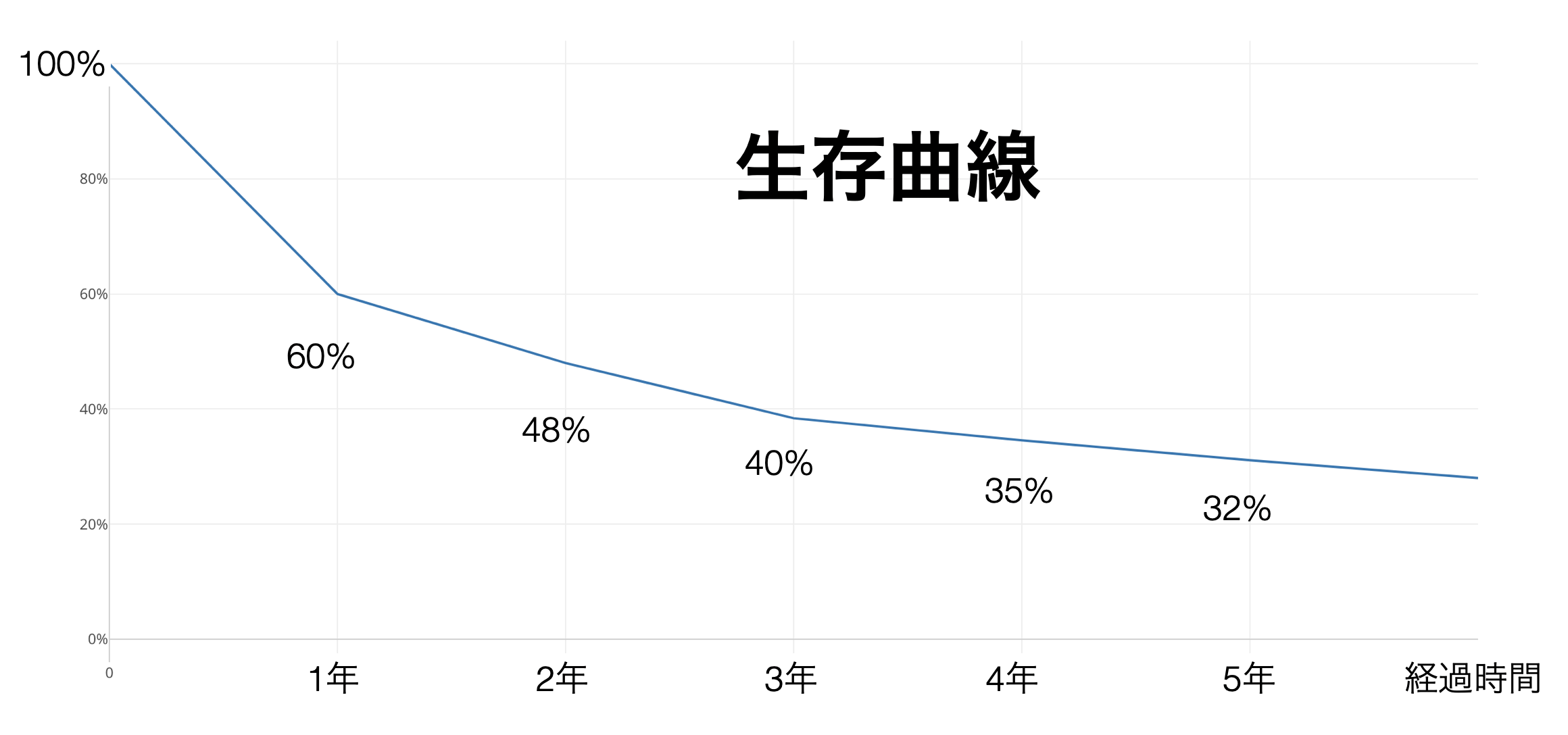
このことを、利用開始から時間が経つとともに、どれだけの割合の顧客が残っているかを表したチャートを使って簡単に説明していきます。
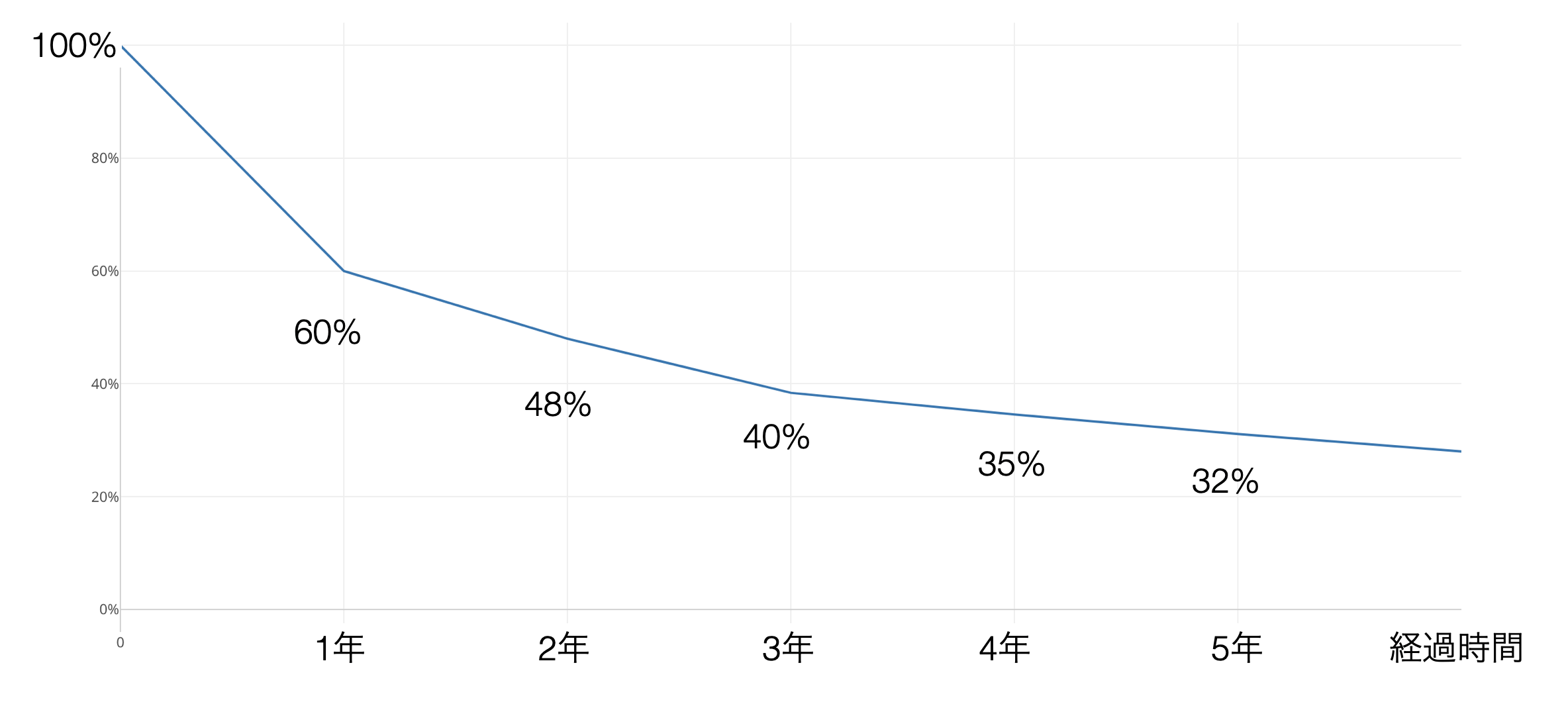
サブスクリプション型のビジネスでは、サービスやプロダクトを使ってみたものの、あまり価値を感じられなかったなどの理由で、一般的に使用開始から間もない時期にはキャンセルが発生しやすく、年間のキャンセル率は高くなりがちです。
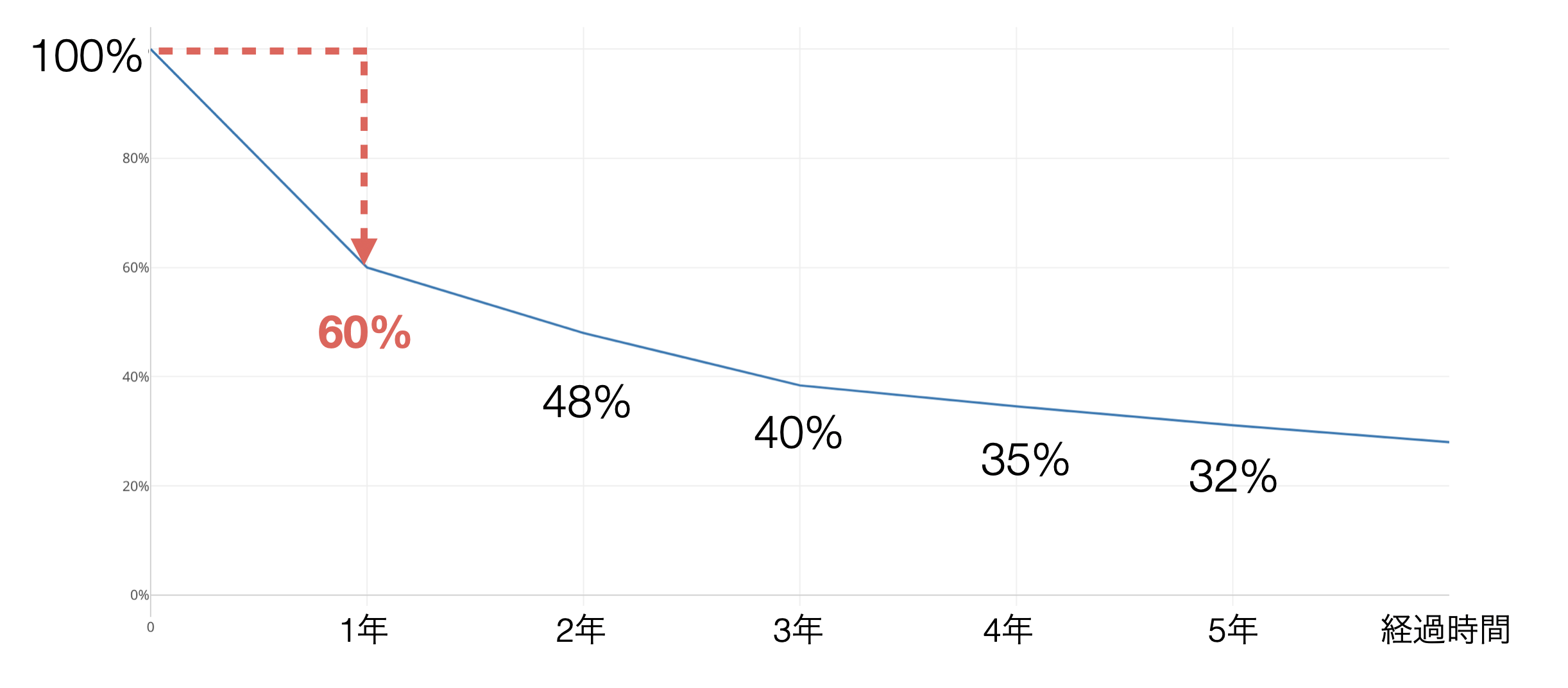
逆に、キャンセル率は使用開始から時間が経つに連れ徐々に低くなります。
なぜかというと、例えば、5年目にキャンセルする確率は、4年間キャンセルしなかった人達がキャンセルする確率となり、価値がないと判断した顧客はすでにキャンセルしているため、キャンセルする理由がない顧客が残っているため、キャンセルが発生しづらいからです。
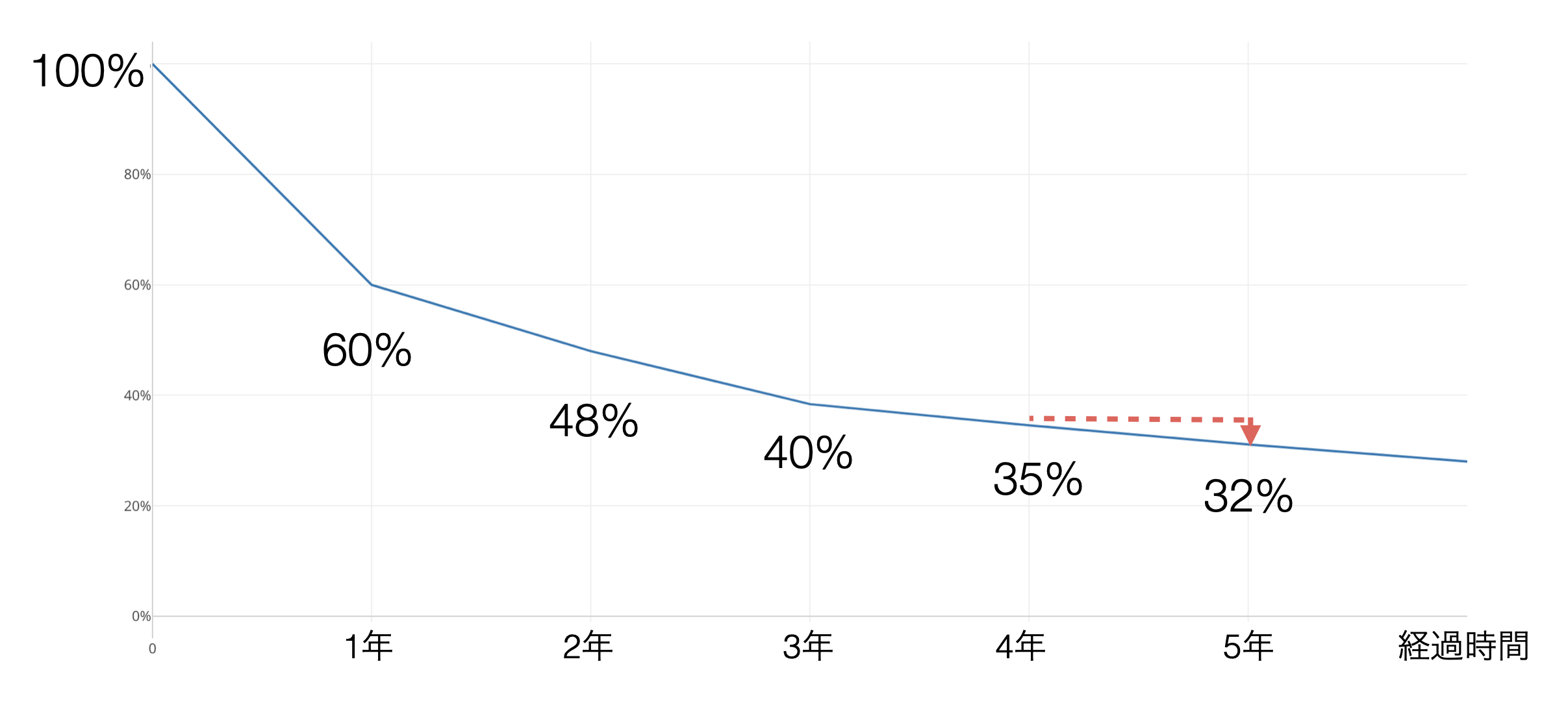
このようにサブスクリプション型のビジネスで顧客がキャンセルする確率は、サービスの利用を始めてからどれくらいの期間が経っているかによって変わってくる特徴があります。
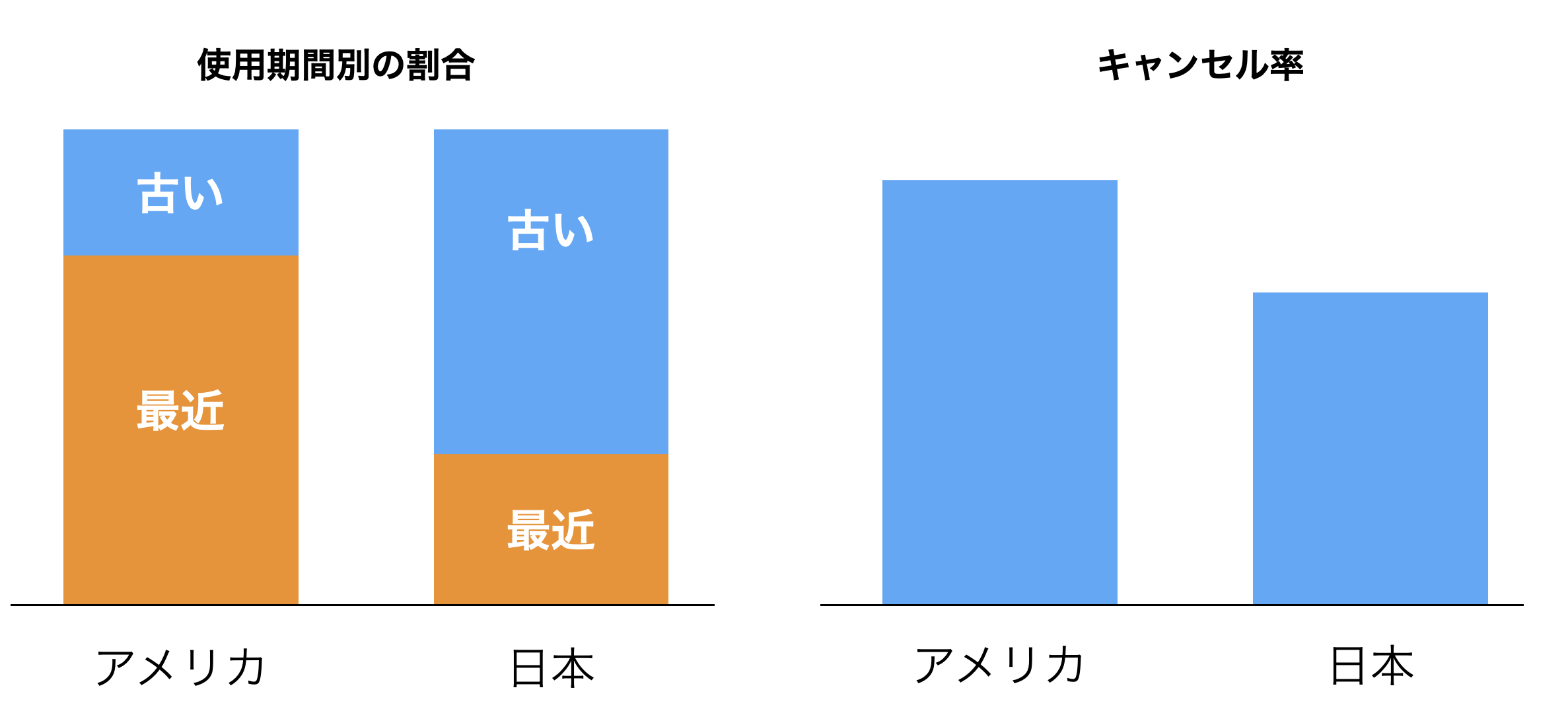
この特徴を踏まえたうえで、とあるサービスのアメリカと日本のキャンセル率を比べたチャートを見ていきます。
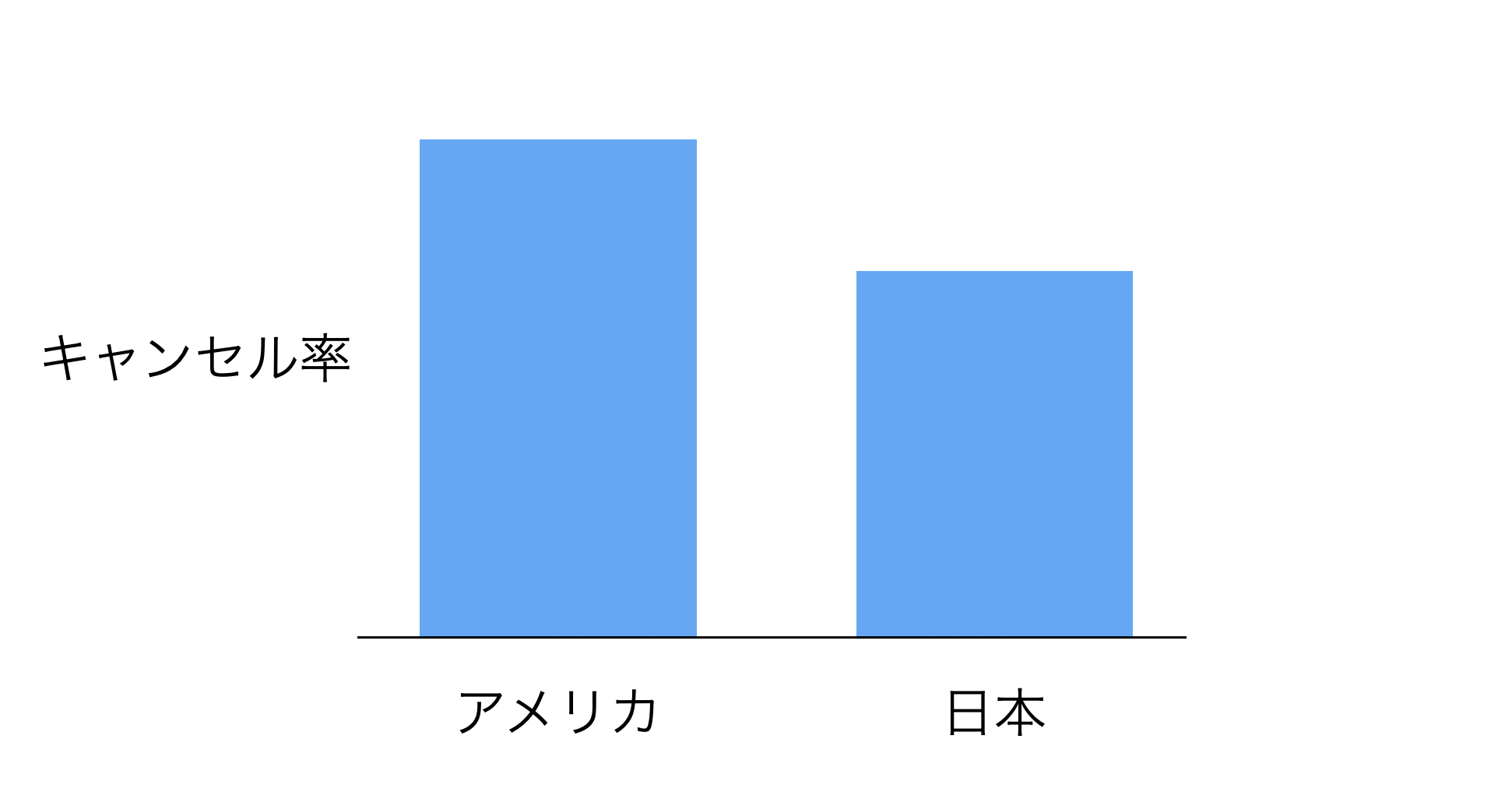
一見、アメリカの方がキャンセル率が高く、日本と比べるとアメリカのサービスに問題があるように感じるかもしれません。
しかし、ユーザーの使用期間別の割合を比べたところ、アメリカの方が最近、利用を始めた顧客、つまりは、キャンセル率が高くなりやすい、顧客の割合が高いことがわかりました。
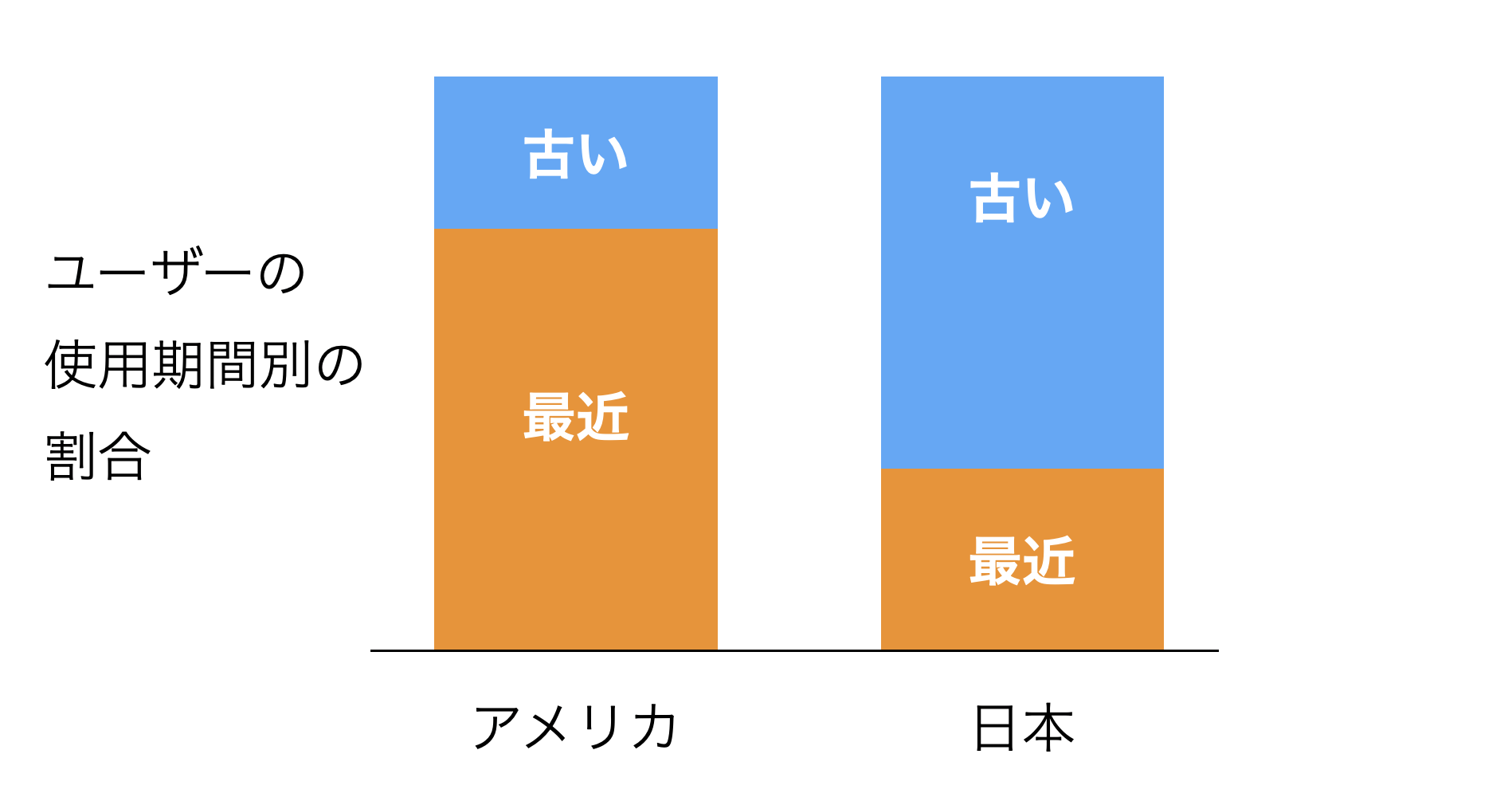
すると、アメリカの方が日本よりキャンセルしやすいユーザーの割合が高いため、アメリカのキャンセル率が日本に比べて高いのは、ある意味当たり前と言えます。
このように「期間」を考慮してキャンセル率を見た方が、全体のキャンセル率を見るより、適切に顧客のキャンセルを捉えられます。
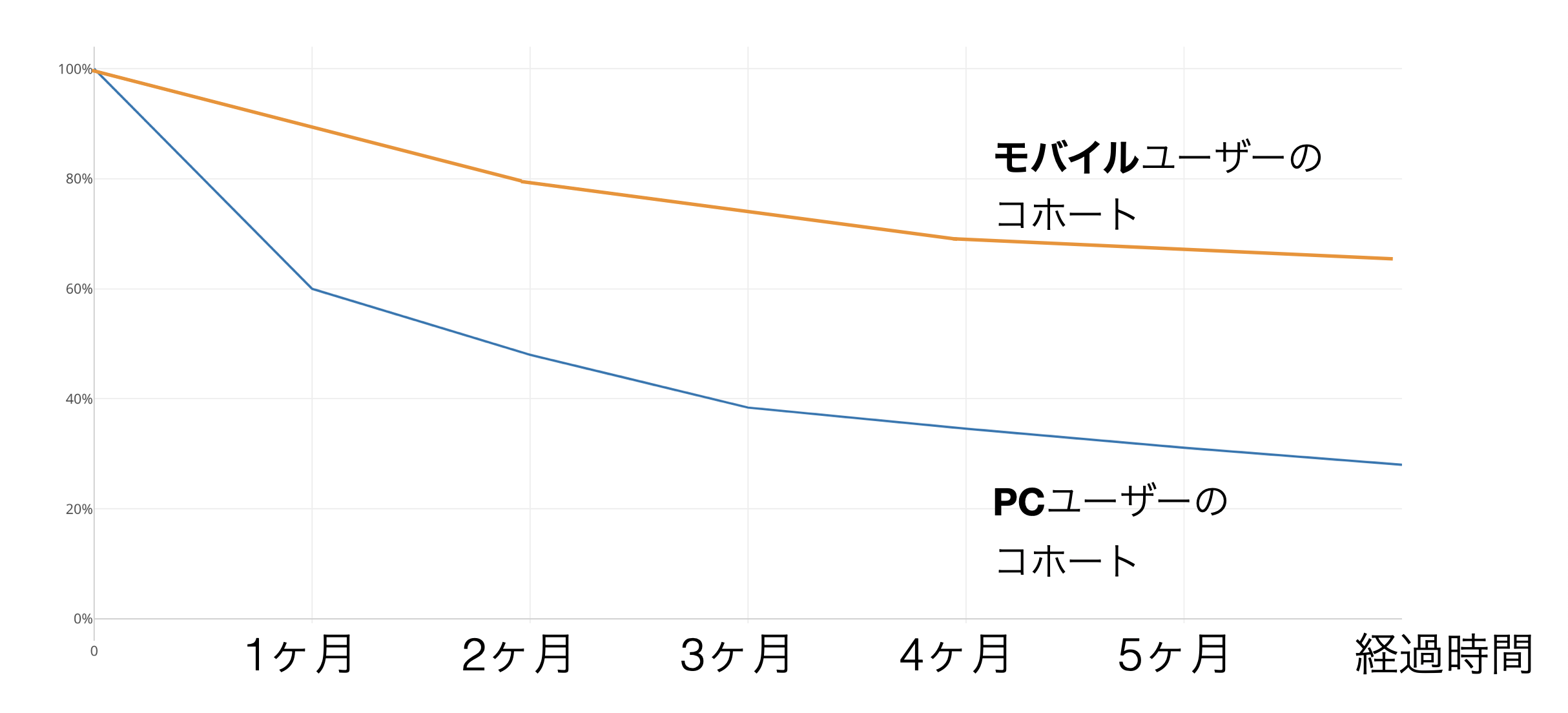
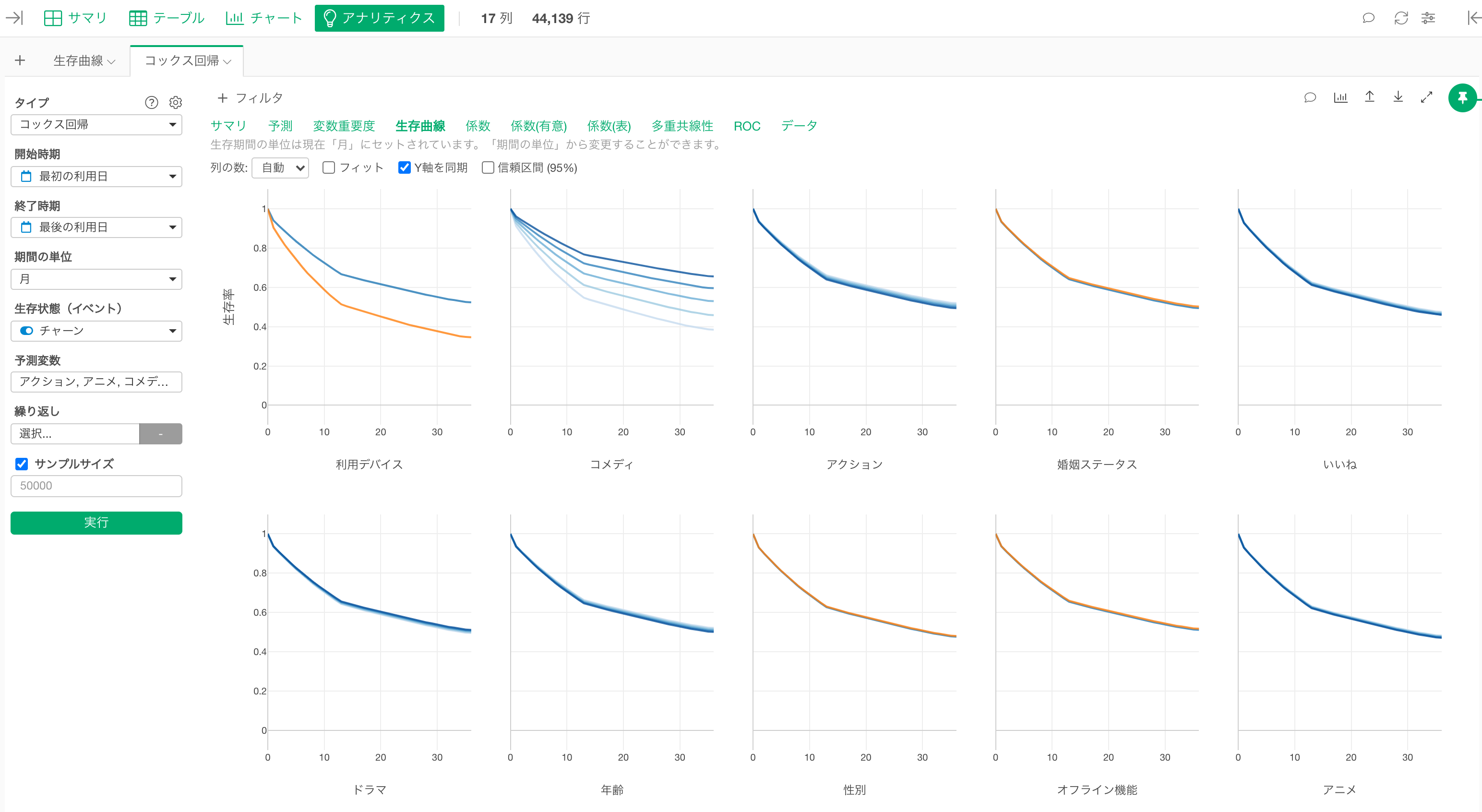
そして、こういった、サービスの利用期間ごとにキャンセルしなかった顧客の割合(生存率)を可視化したチャートを生存曲線と呼ぶのですが、生存曲線を使うと「期間」を考慮したうえで、複数のグループ間のキャンセルの状況を比べられます。
例えば、モバイルユーザーとPCユーザーの生存曲線を比べると、モバイルユーザーの生存曲線の方が、PCユーザーの生存曲線より緩やか、つまりは生存率が高く推移しているので、モバイルユーザーの方が、キャンセルしにくいことが分かるわけです。
疫学用語で「グループ」のことを「コホート」と呼ぶことから、このようなグループごとに生存曲線を比べる分析を「コホート分析」と呼びます。
顧客の属性・セグメント・特定機能の利用状況などを使ってコホート分析をすることで、キャンセルと相関する指標を分析できるわけです。
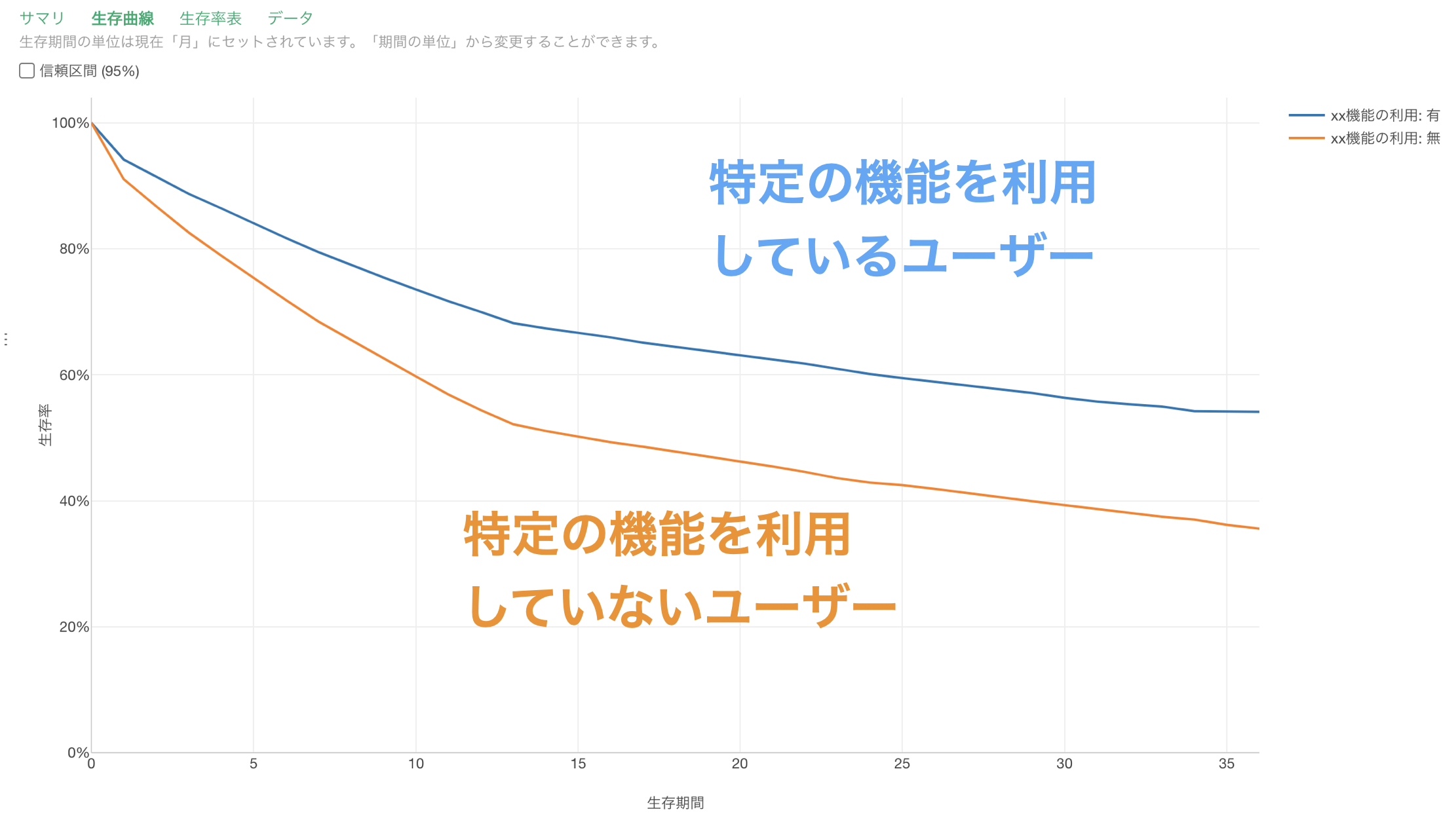
なお、サブスクリプション型のビジネスの世界でコホート分析と言うときには、一般的に「利用開始時期」でコホート(グループ)を分けることを指します。
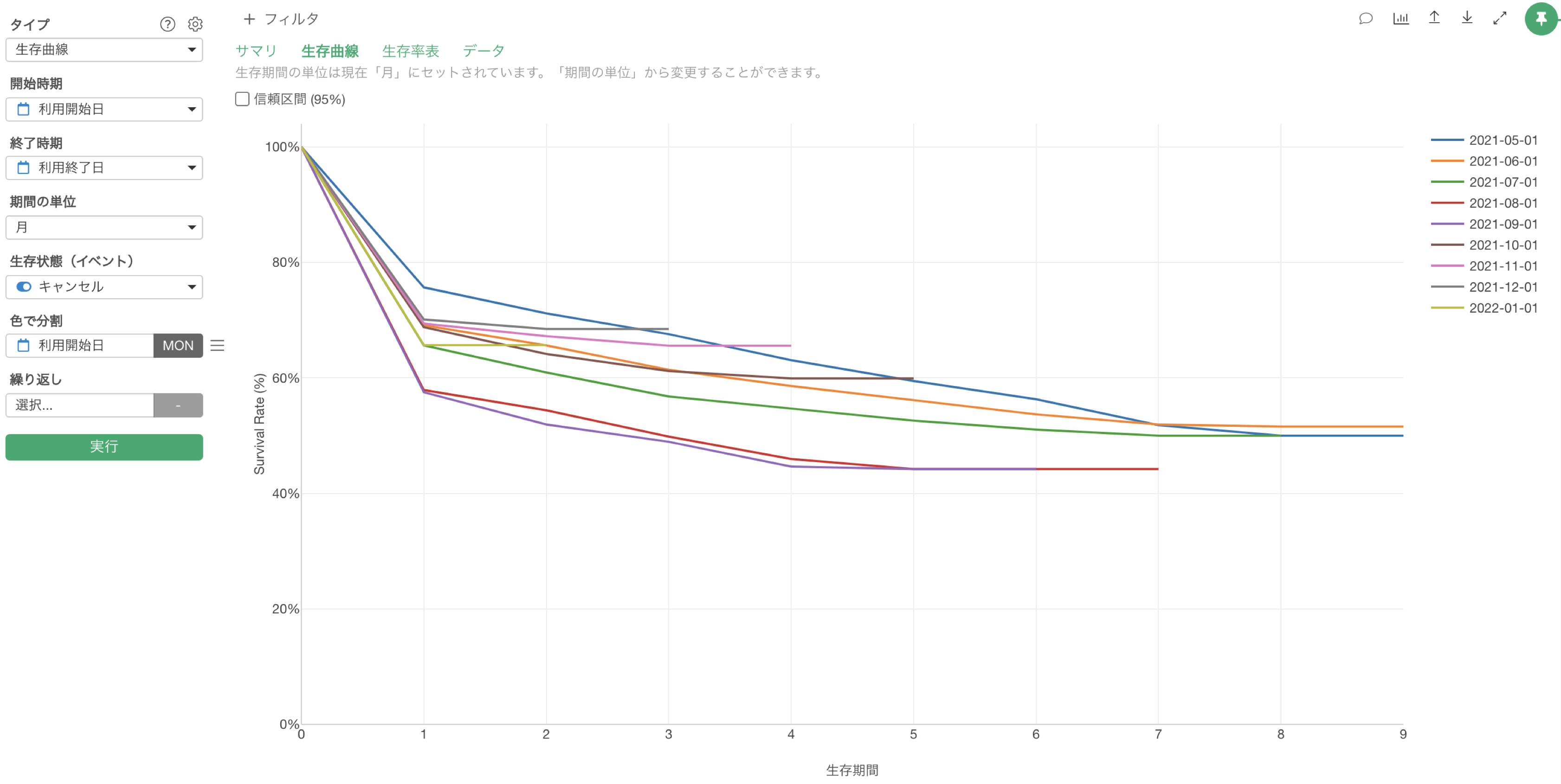
「利用開始時期」で顧客をコホートに分けると、時間の経過とともに生存曲線が急/緩やかになっているかどうかで、顧客のリテンションを改善できているかがわかります。
詳細につきましては、こちらで紹介をしていますので、ぜひ、ご覧ください。
4. 多変量解析(生存分析)
ただし、コホート分析においてもコンバージョンと同じように「アイスクリームとサメ」の問題が生じます。
例えば、コホート分析をした結果、「コメディの視聴時間が長くなるほどキャンセルしにくい(生存曲線が緩やかになる)」、あるいは「男性の方が女性よりキャンセルしにくい(生存曲線が緩やかになる)」ことが分かったとします。
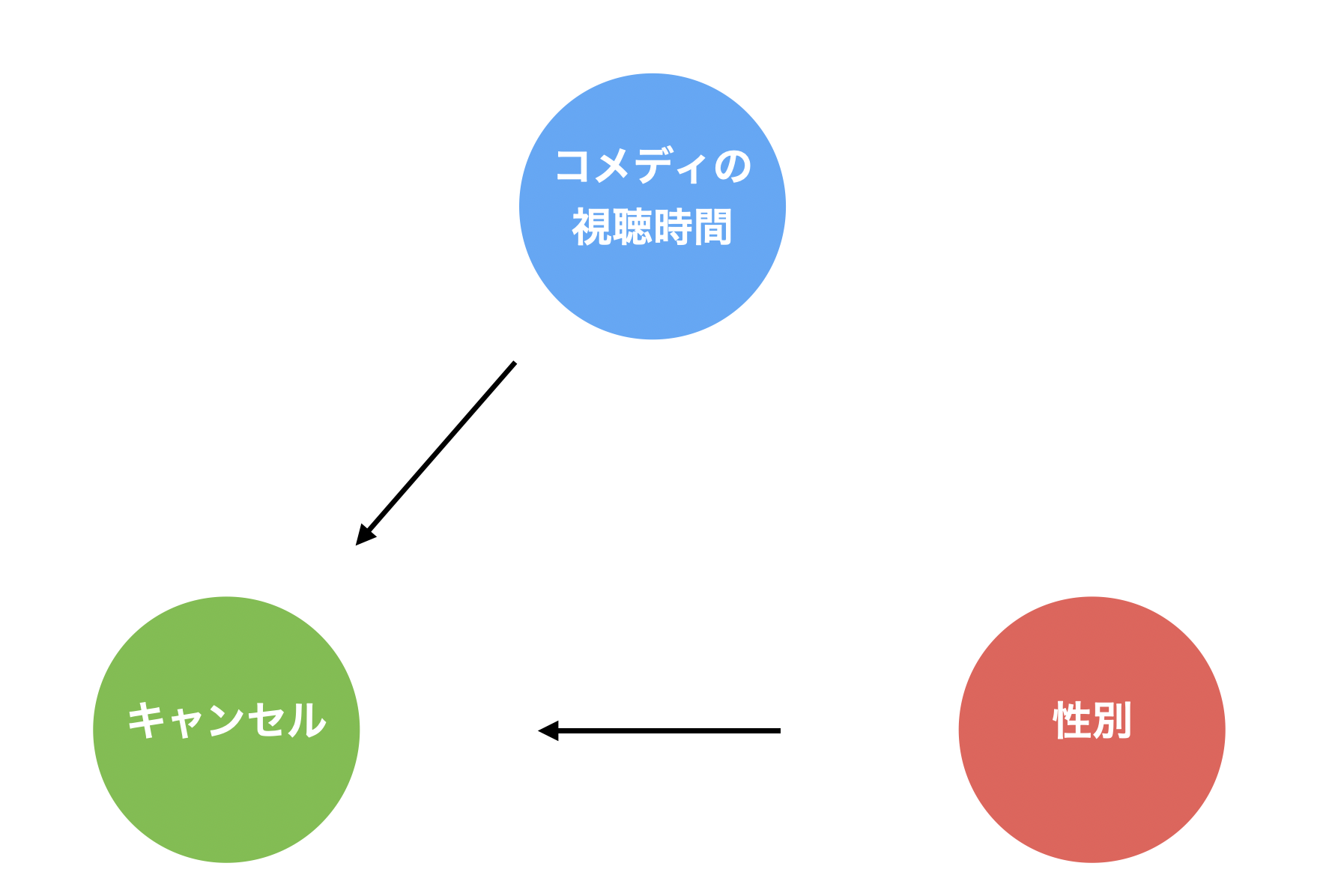
このとき、「性別」と「コメディの視聴時間」の間には、「男性はコメディの視聴時間が長い」といった、相関関係があるかもしれません。
その場合、コホート分析を実施しただけでは「どちらがキャンセルに影響を与えているのか」あるいは「両方の変数がコンバージョンに影響を与えているのか」を理解できません。
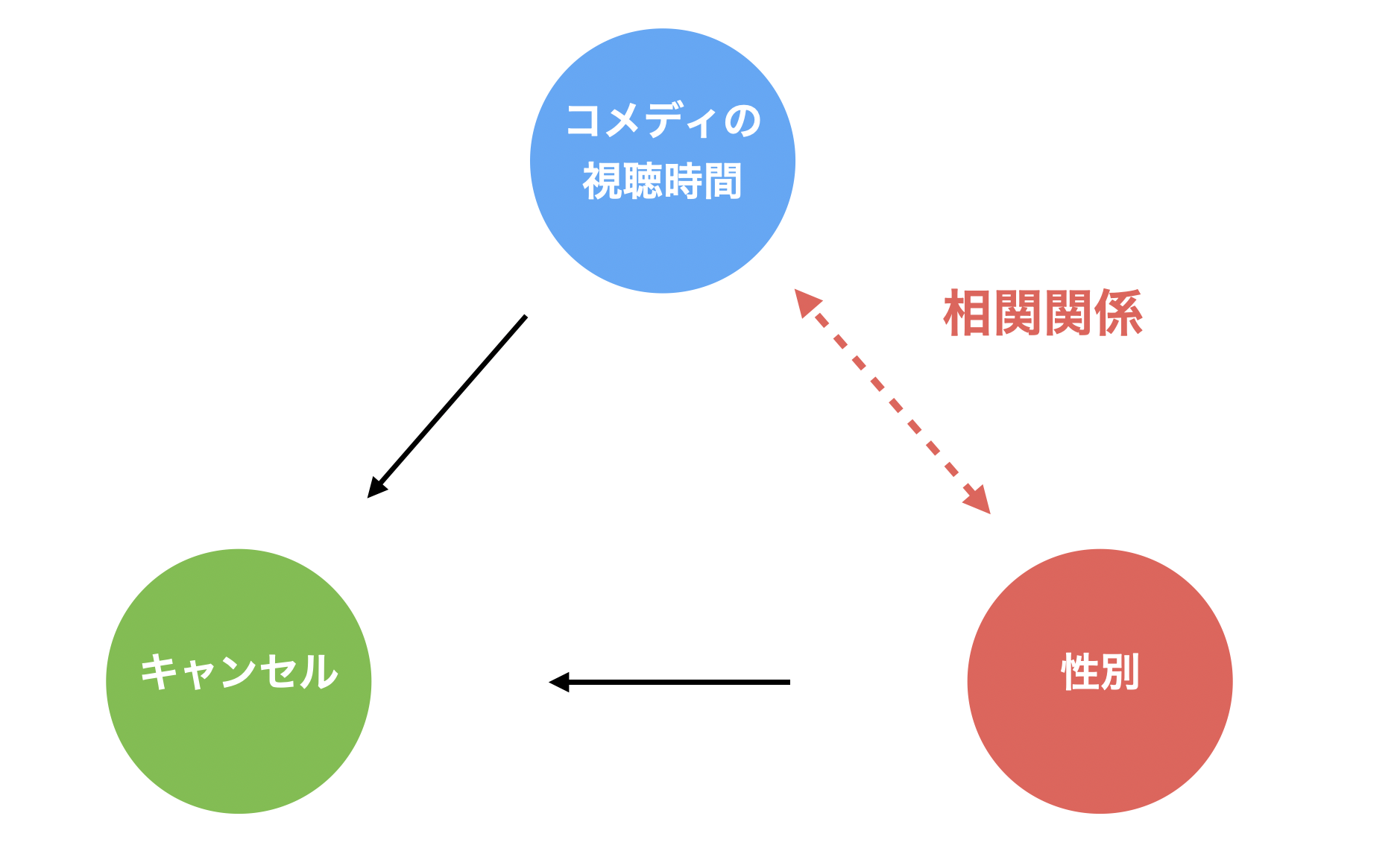
そこで、コホート分析においてもコンバージョンと同じように「多変量解析」を行います。
多変量解析を行い、例えば性別を一定にしてコメディの視聴時間のみを変化させたときに、キャンセルが変化するのかを調べることで、コメディの視聴時間とキャンセルの間に関係があるのかがわかります。
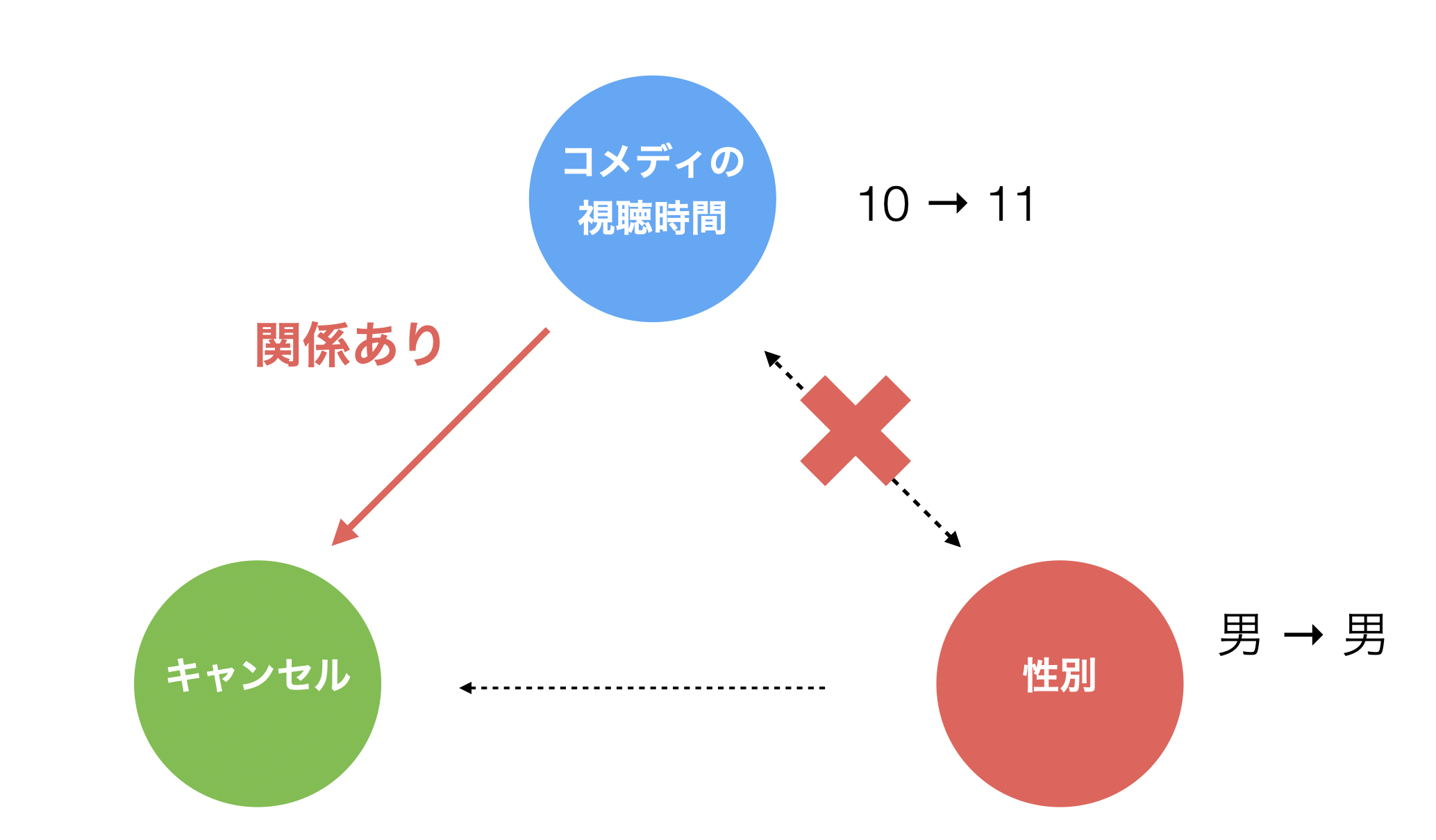
なお、多変量でコホート分析を行いたいときは「コックス回帰」という予測モデルを利用します。
Exploratoryでは、ロジスティック回帰と同じように、UIを通して、コックス回帰の予測モデルを作成して、他の変数の値が一定だったときのキャンセルへの効果を調べられます。
また、Exploratoryでは、どのタイプの予測モデルを作っても、「アナリティクスの文法」という仕組みをもとにモデルが変わってもモデルを解釈できるので、どの変数が「キャンセルとの相関がより強いのか」や、「キャンセルと関係があると言えそうか」を同じように理解できます。
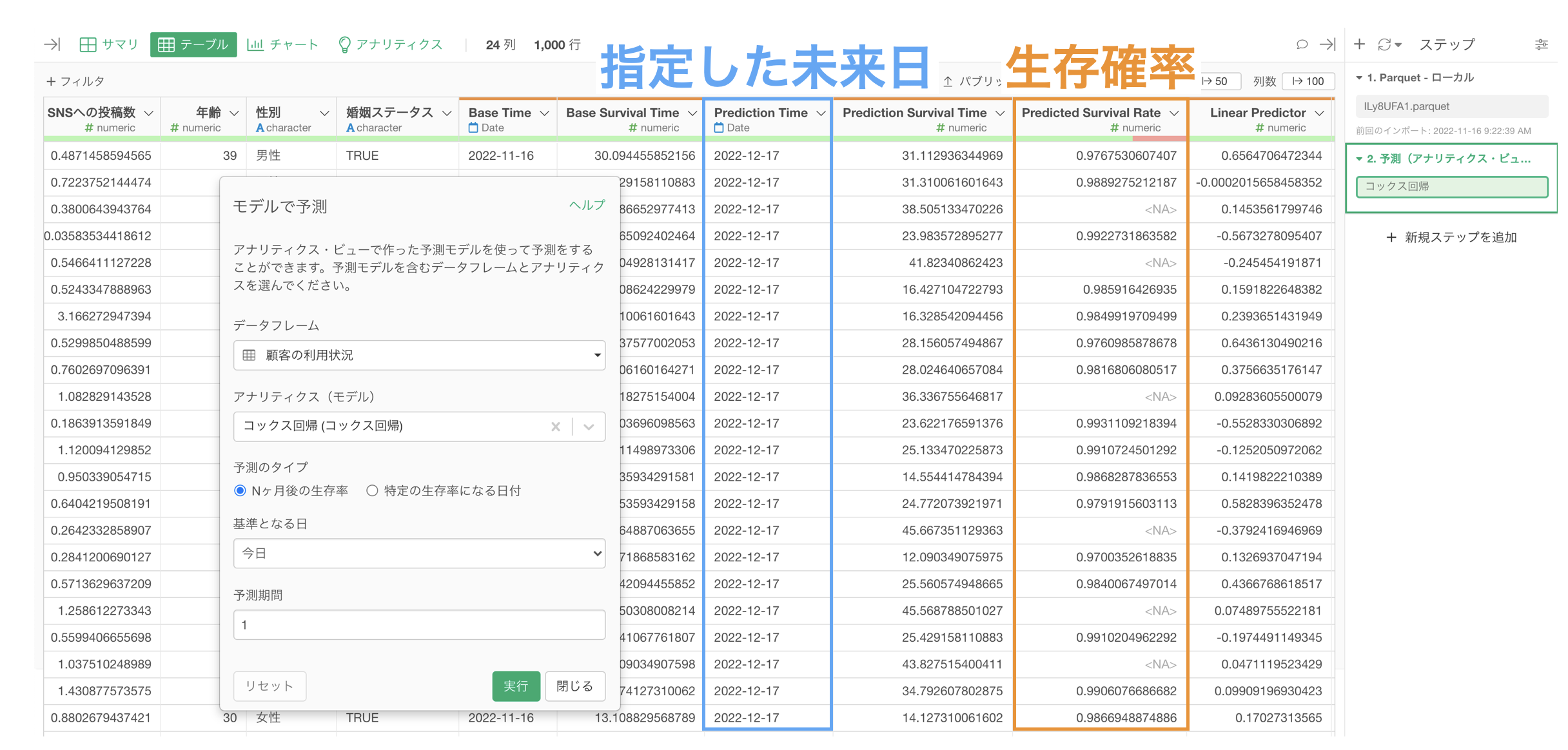
予測と機械学習のモデル
さらにコックス回帰のモデルを使うと、顧客ごとに指定した未来日の生存確率を予測したり、
顧客ごとに指定した生存確率になる日付を予測し、キャンセルしそうな顧客のサポートに注力するアクションの実行が可能です。
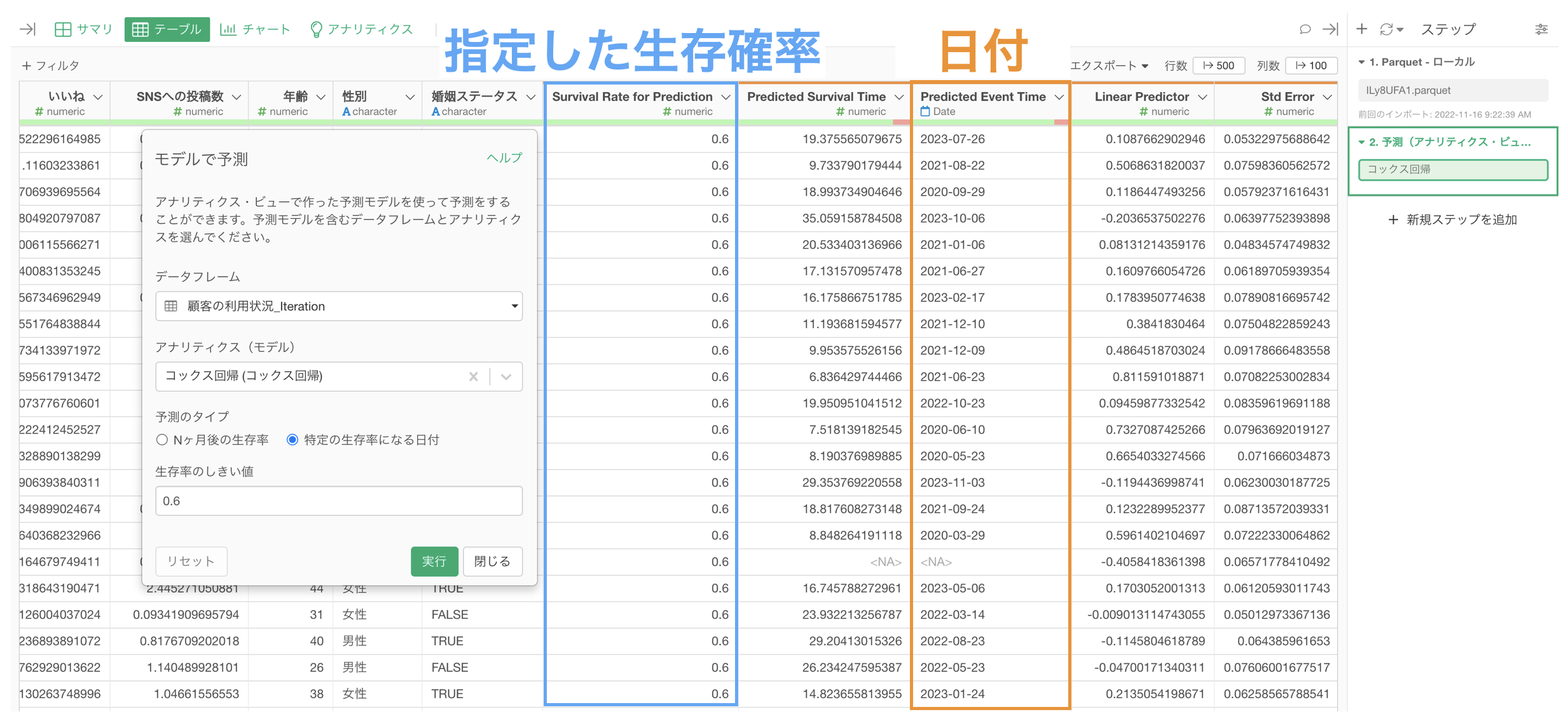
なお、コンバージョンを予測するときと同じように、当てにならない予測を元にアクションをしても意味はないので、予測結果を元に何らかのアクションをするときには「予測精度」が重要です。
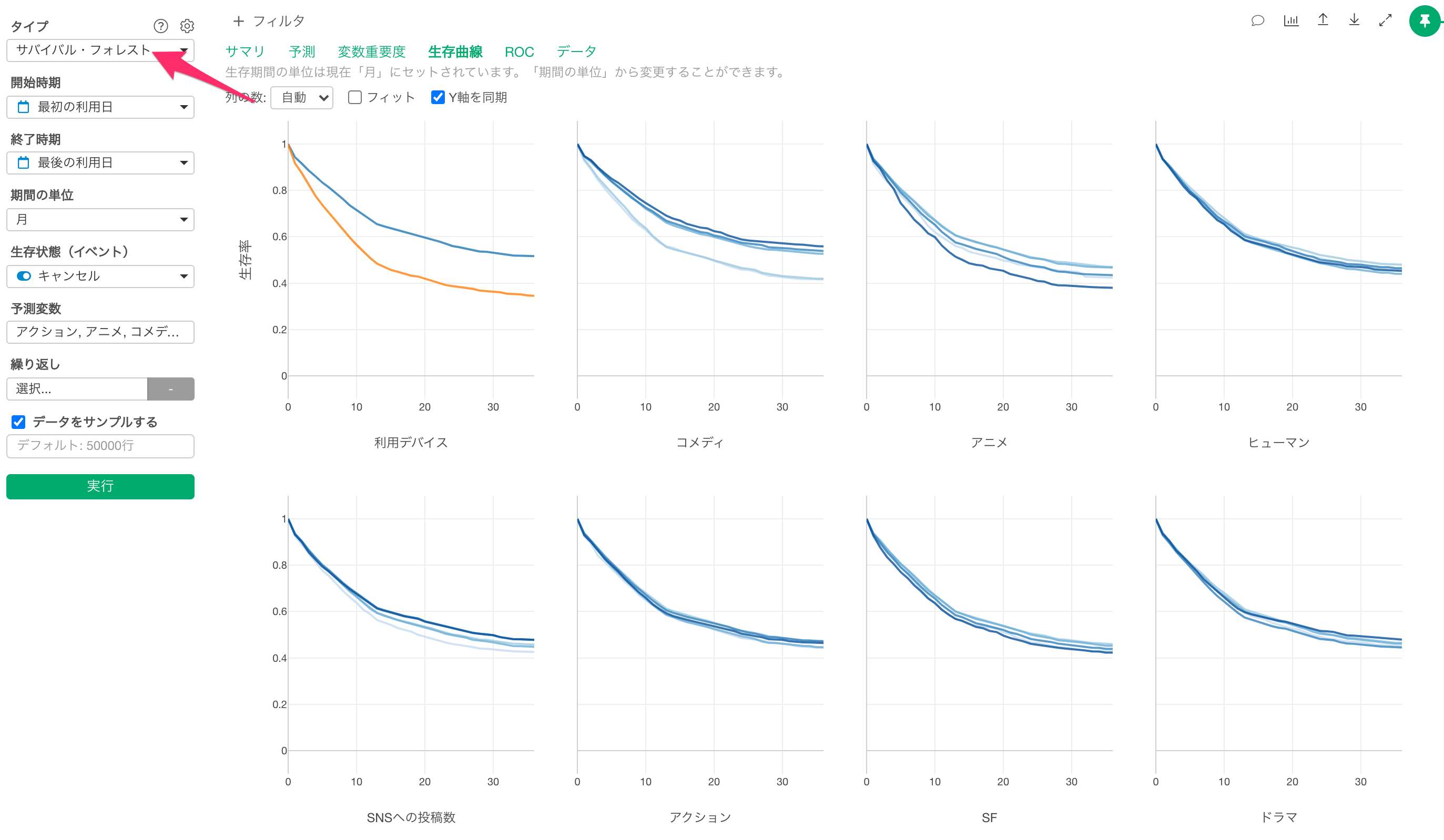
そこで、高い予測精度が出やすい機械学習のモデルである「サバイバルフォレスト(ランダムサバイバルフォレスト)」を利用することも可能です。
5. テキスト分析
コンバージョンを増やし、キャンセルを減らすには、サービスやプロダクトの改善が欠かせません。そこで、サービスやプロダクトの改善のヒントを得るために、見込み顧客や既存顧客にアンケートを実施し、自由記述のフィードバックを集めることはよくやることの1つです。
ただし、回答数が多くなると全ての回答に目を通すことは難しいため、全体像が掴みにくくなります。
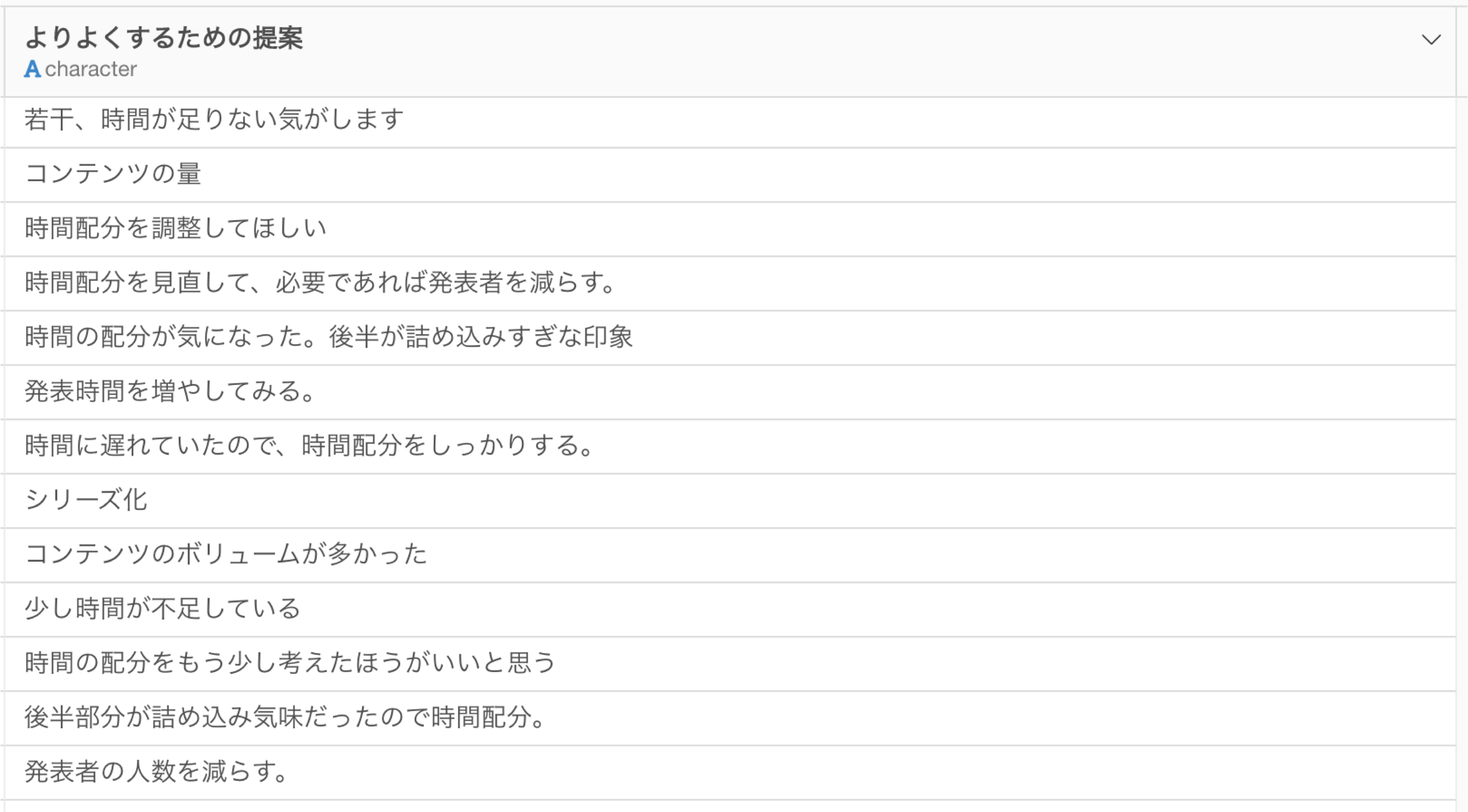
そこで、**文章を単語に分け、それぞれの単語の頻出回数を集計(定量化)**することで、データの中にあるパターンや特徴をつかみ、サービスやプロダクトを改善するためのヒントを得ることが可能です。
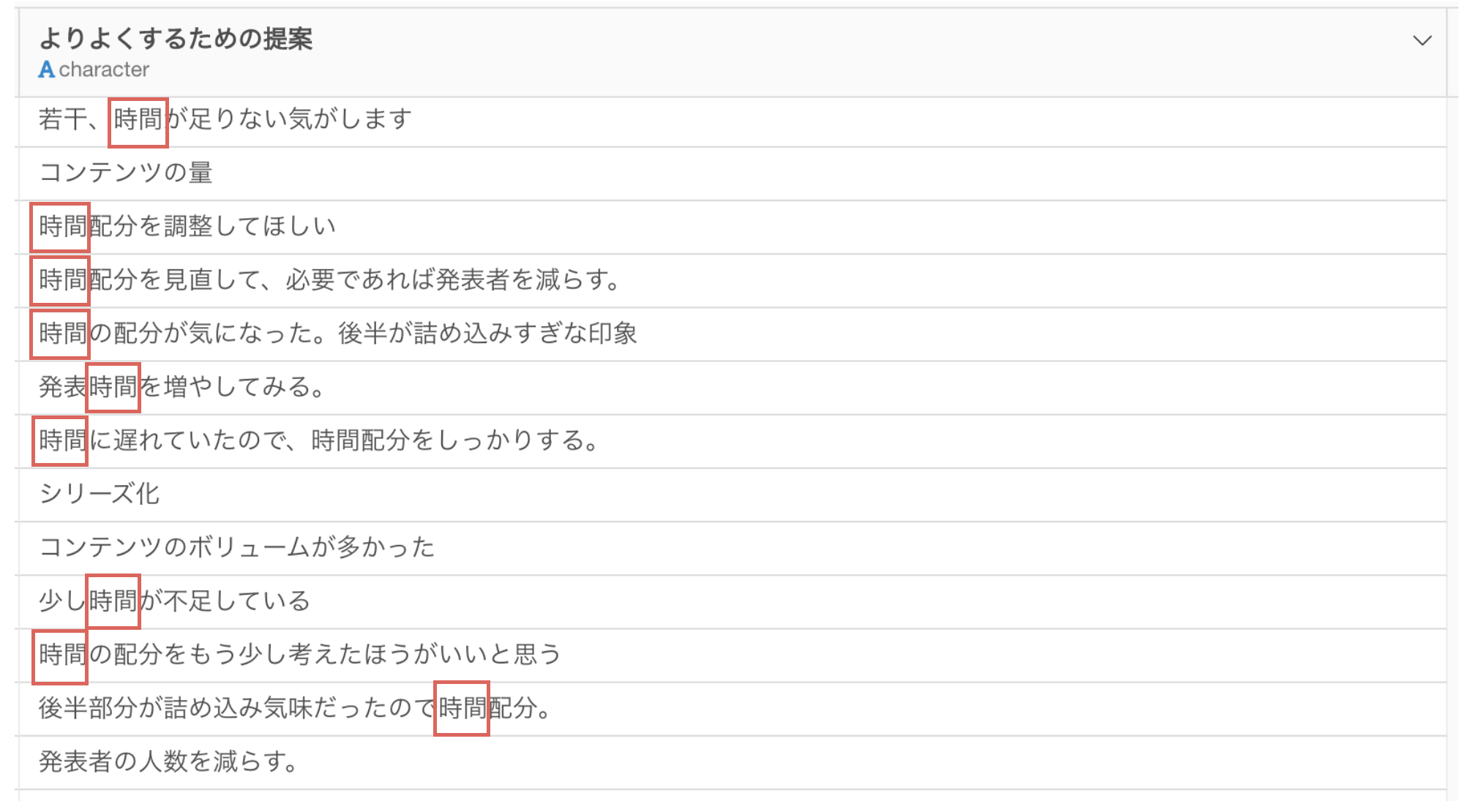
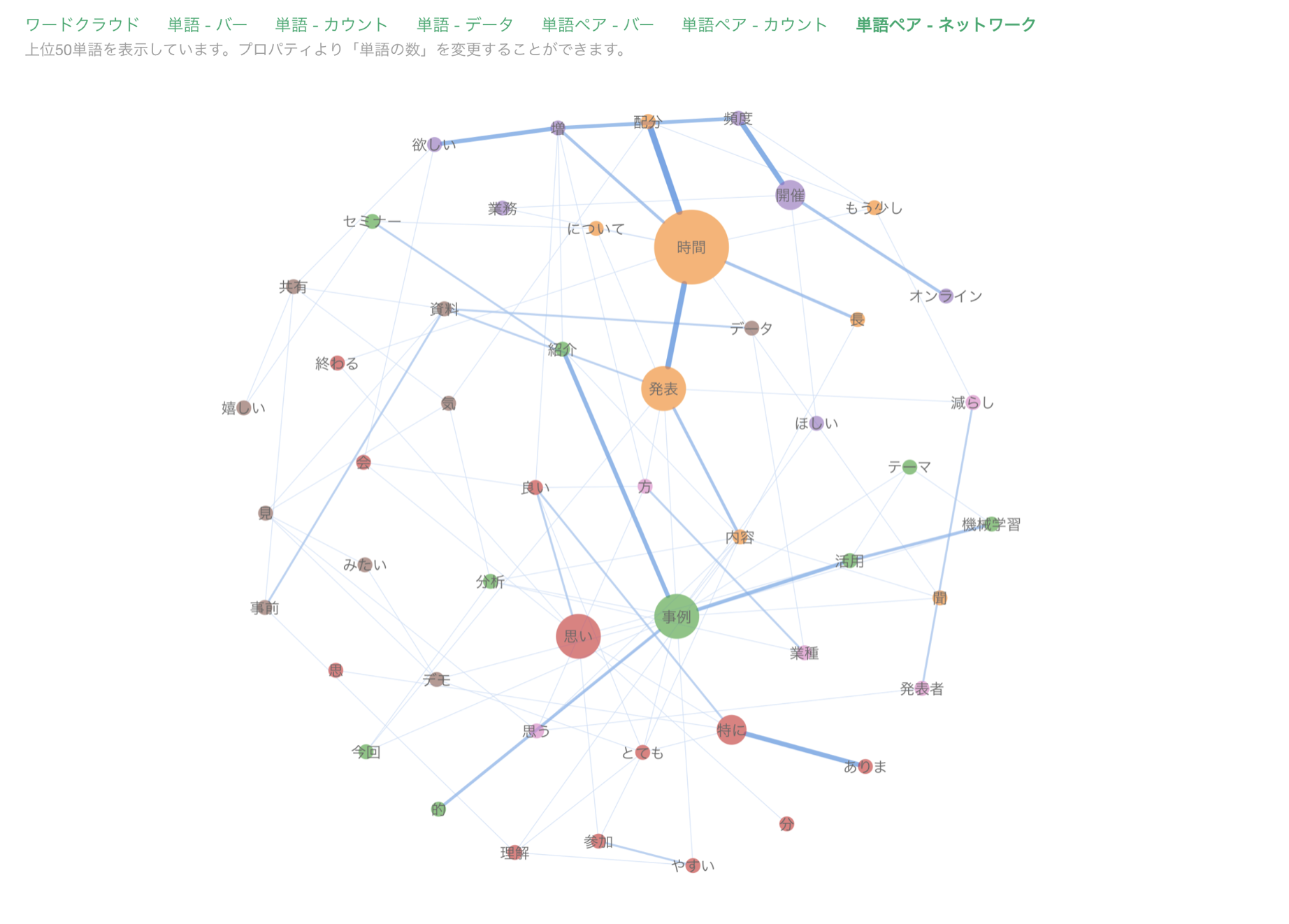
そして、文章を単語に分けたときによく利用されるのが、単語の登場頻度を色とサイズで表す「ワーククラウド」です。

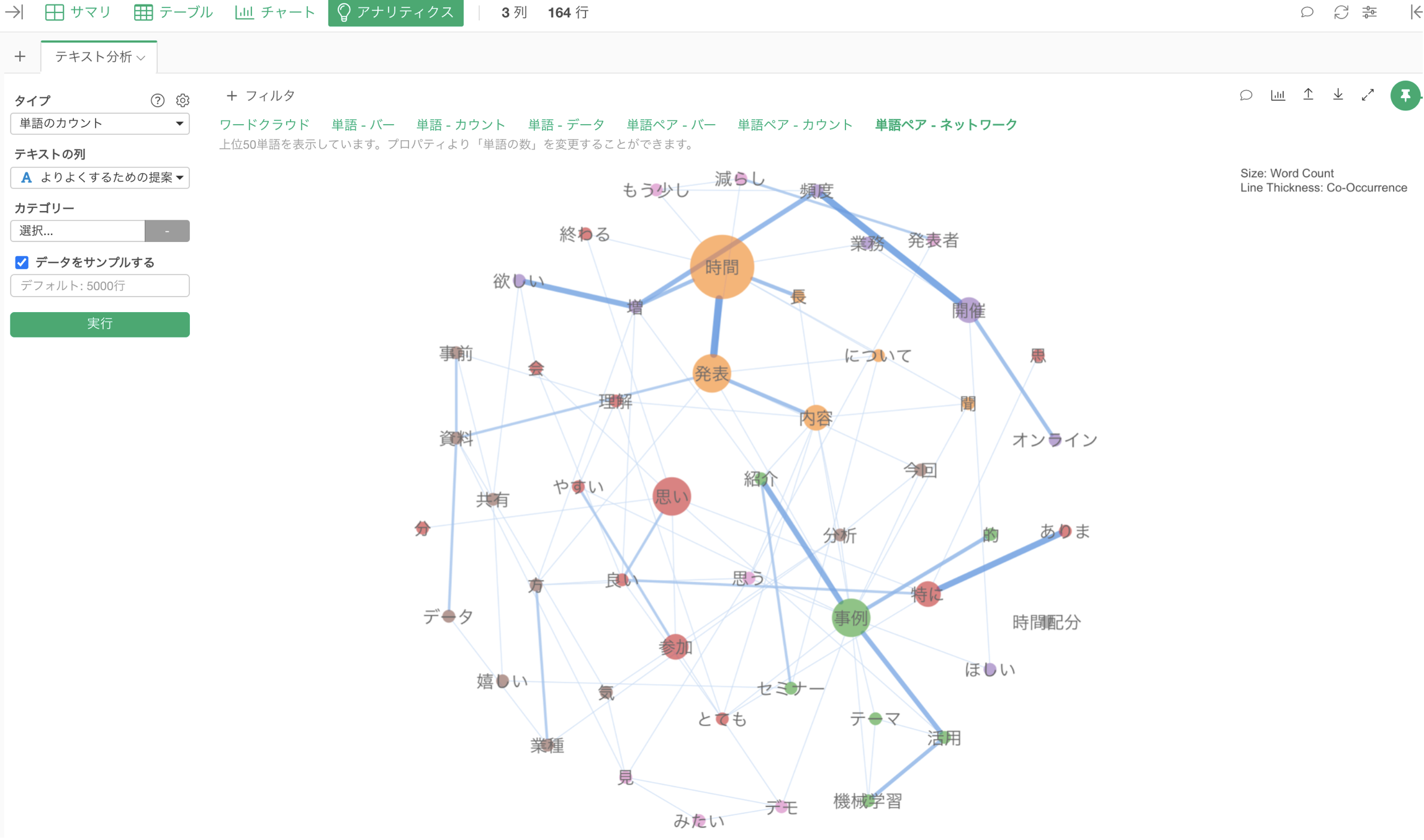
また、各単語がどのような単語と一緒に使われているのかを知りたいときには「共起ネットワーク」を利用します。
なお、Exploratoryではテキストの列に単語化したい列を割り当て、「テキスト分析」を実行をクリックするだけです。
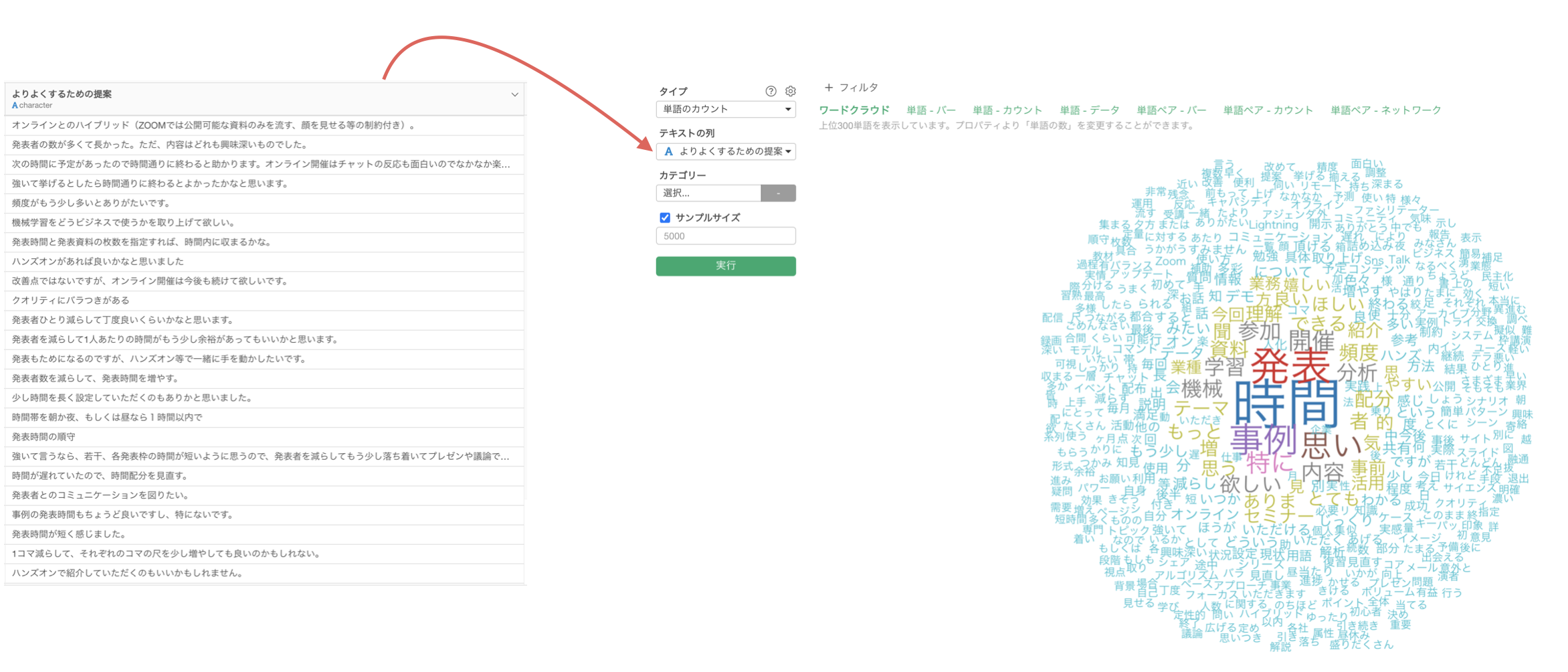
テキスト分析を実行すると、前述のワードクラウドや共起ネットワークが自動で生成されます。
以上が、5つの分析手法です。
もっと知りたい!
今回は、サブスクリプション型のビジネスの分析に欠かせない5つの分析手法を紹介しました。
こちらの記事で紹介した分析手法を、実際にどのように使うのかを知りたい方は、Exploratoryのデモを交えた紹介動画がありますので、ぜひご覧ください!
やり方を学びたい!
今回紹介した分析手法を使って、自分でもサブスクリプション型ビジネスのデータ分析をできるようになりたい方は、この12月にサブスクリプション型ビジネスに特化したトレーニングを開催予定ですので、そちらへの参加をご検討いただければと思います。
トレーニングでは、こちらの記事で紹介した全ての分析手法に加えて、サブスクリプション型のビジネスに特有のビジネス指標(KPI)の定義、コンバージョンやキャンセル(解約)の先行指標となるエンゲージメントの計算方法や分析手法を効率的に学んでいただくための2日間のトレーニングとなっています。
SaaSやサブスクリプション型のビジネスの分析または可視化の手法を効果的に学びたい方は、ぜひ参加をご検討ください。
自分のデータで試してみたい!
記事内の全てのチャートは、データの加工、可視化、分析、レポーティングのためのUIツールのExploratoryを利用して作成しています。
ご自身のデータを使って、これらのチャートを作成したり、データの分析をしたい方は、下記のリンクより無料トライアルが可能ですので、ぜひ、お試しください!