概要
気象庁の地震データについてEDAもどきを行う。
今回の結果を踏まえ、最大震度予測や時系列方向の予測なども次回行いたい。
- 実施時期: 2021年11月
- OS: Ubuntu20.04 LTS
- Python: Python3.8.10
改版履歴:現状の震源分布をplotlyで描画しstreamlitで公開
モチベーション
データ整形後の震源分布はこちら(日時範囲スライダ付き)
プロットの大きさはマグニチュードを、色は震源の深さを示す。

最近アップされた下記投稿の地震データをplotlyに入れて日本列島を眺めながら、
「緯度経度を指定したら地震発生確率とか、その時の震度が予測できるんじゃね?」
と思ったので、やってみる。
内容
前述の方が気象庁の全生データをcsvファイルにマージされていたので、それを使用させていただく。
ただ、経度、緯度、時刻、深さ、最大震度など、精査するとそのまま使用できなかったので自前で加工する。
別の機会に確率予測や時系列傾向分析(できれば予測まで)やってみる意気込み。
データ加工
全マージデータのindex列には元の気象庁データが置かれているので、基本的にはこれを加工する。
indexという用語はpandasのindexとかぶって嫌なので、originにエディタで変更している。
加工方法は下記に記載ありこれに則る。
加工ルール
- 震央地名に 「詳細不明」 が含まれる行は削除した
- 「最大震度」 はレコードフォーマットを参照し下表の通り置き換えた。つまり震度は0~9でorder encoredする
- 「マグニチュード」 と 「最大震度」 がブランクの行はそれぞれでゼロとした
- 計算コスト削減のため 「震央地名」 対象地域にはコード中のtarget_areaに指定した文字が入っている行に絞る(後述)
| origin | 意味 | replace |
|---|---|---|
| ブランク | 説明なし | 0 |
| 1~4 | 震度1~4 | 1~4 (そのまま) |
| A | 震度5弱 | 5 |
| B | 震度5強 | 6 |
| C | 震度6弱 | 7 |
| D | 震度6強 | 8 |
| 7 | 震度7 | 9 |
EDA
簡単にPandasのProfileReportでEDAした。
数値データ
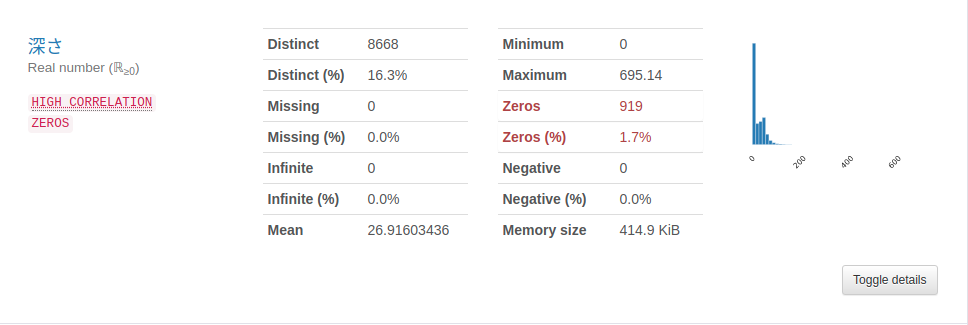
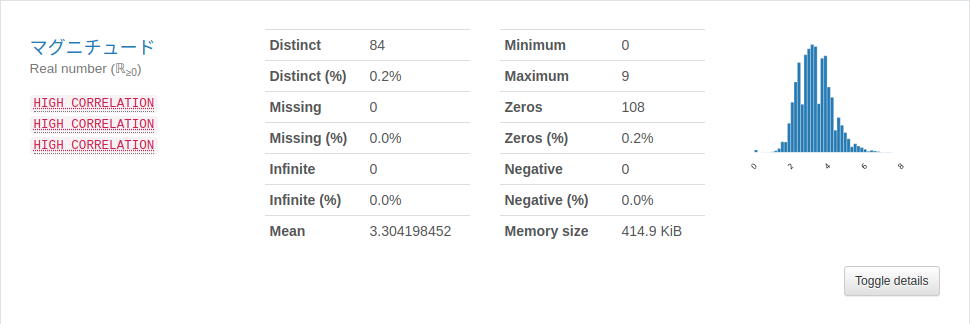
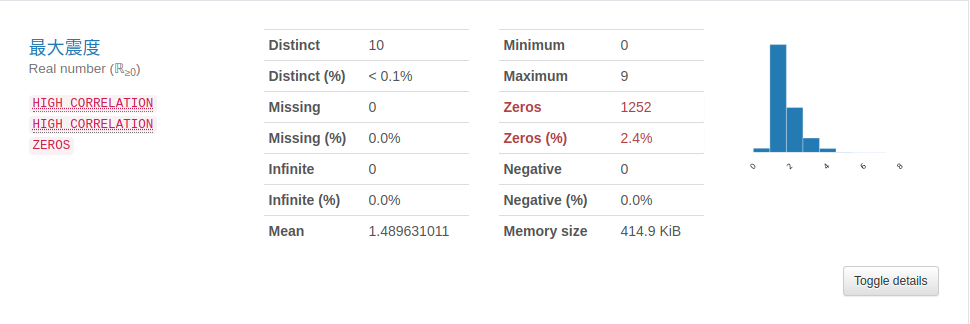
ゼロ(もともとブランク含む)があるのでその扱いは各分布から深さは中央値に、マグニチュードは平均値に、最大震度は中央値に置き換える。

日本列島は東西に長いので経度は西日本の山と、北海道から関東までの大きな山がわかる。
最近も地震が頻発している後者について解析することにする。特に震央地名に下記の文字が含まれる行を対象とする。
三陸沖|岩手|宮城|福島|茨城|千葉|東京|神奈川|栃木|群馬|埼玉|房総半島|関東|相模湾|伊豆|新島|三宅島|八丈島
カテゴリデータ
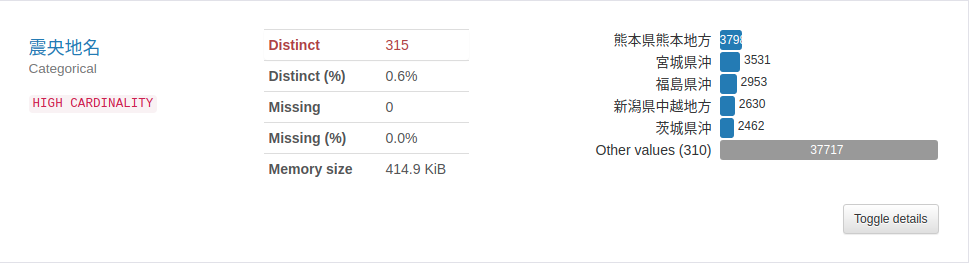
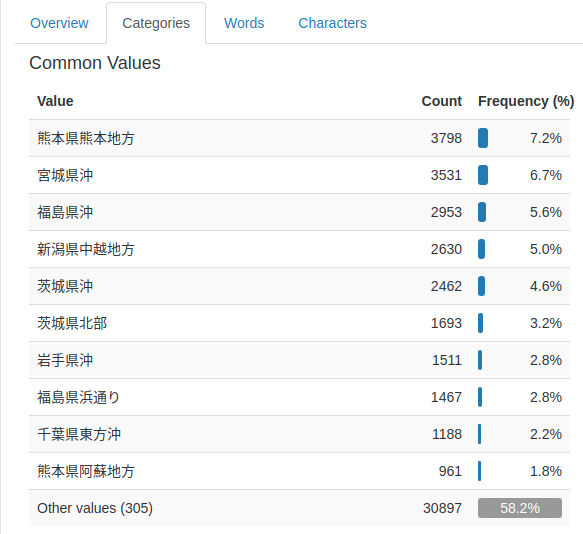
東日本大震災関連が目立つことがわかる。
その他、「被害規模」や「津波規模」などのデータはほとんど値が入っていないので、利用しない。
Scatter plot
PlotlyのScatterplotで分布を確認する。plot sizeはマグニチュード、colorは深さを示す。
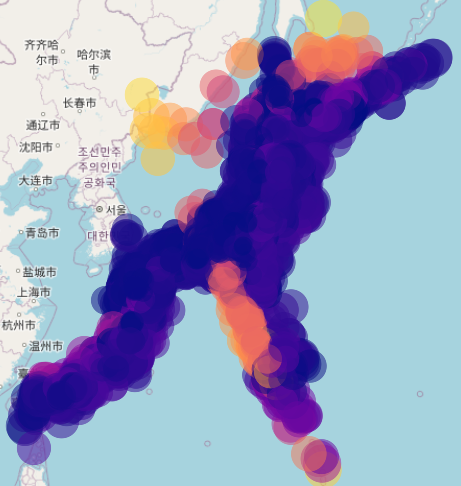
下図のように小笠原諸島沖や鳥島近海は震源が400km~600kmと非常に深いため、ヒートマップにするとそれらに引っ張られてしまい、東北から関東にかけた地震分布を色では区別できなくなっている。

上述の結果を反映させたデータ加工部は下記となる。
def preprocess():
df_ethq = pd.read_csv("dataset/earthquake_20year_full.csv", index_col=0)
df_ethq = df_ethq.drop(['時刻', '深さ', 'マグニチュード', 'dt'], axis=1) # 使えない列を削除
df_omit = df_ethq.loc[df_ethq['震央地名'].str.contains('詳細不明')]
omit_list = list(df_omit.index)
df_ethq = df_ethq.drop(index = omit_list)
target_area = '三陸沖|岩手|宮城|福島|茨城|千葉|東京|神奈川|栃木|群馬|埼玉|房総半島|関東|相模湾|伊豆|新島|三宅島|八丈島'
df_ethq = df_ethq.loc[df_ethq['震央地名'].str.contains(target_area, regex=True)]
df_ethq = df_ethq.reset_index(drop=True)
wkstr = df_ethq['origin']
wklen = len(wkstr)
wkstryy = [wkstr[i][1:5] for i in range(wklen)]
wkstrmm = [wkstr[i][5:7] for i in range(wklen)]
wkstrdd = [wkstr[i][7:9] for i in range(wklen)]
wkstrHH = [wkstr[i][9:11] for i in range(wklen)]
wkstrMM = [wkstr[i][11:13] for i in range(wklen)]
wkstrSS = [wkstr[i][13:15] for i in range(wklen)]
wkdatetime = ['{}/{}/{} {}:{}:{}'.format(wkstryy[i], wkstrmm[i], wkstrdd[i], wkstrHH[i], wkstrMM[i], wkstrSS[i]) for i in range(wklen)]
wkdatetime = [datetime.datetime.strptime(wkdatetime[i], '%Y/%m/%d %H:%M:%S') for i in range(wklen)]
df_ethq['日時'] = wkdatetime
# print(df_ethq[(df_ethq['日時']<'2002/01/01') & (df_ethq['日時']>'2001/06/01')])
wkmgn= []
for i in range(wklen):
if wkstr[i][47:49] == ' ': # I3,2X
wkmgn.append(float(wkstr[i][44:47]))
else: # F5.2
wkmgn.append(int(wkstr[i][44:49])/100)
df_ethq['深さ'] = wkmgn
df_ethq['深さ'] = df_ethq['深さ'].replace(0.0, df_ethq['深さ'].median())
wkmgn = [wkstr[i][52:54] for i in range(wklen)]
df_ethq['マグニチュード'] = wkmgn
df_ethq['マグニチュード'] = df_ethq['マグニチュード'].replace(' ', '0')
df_ethq['マグニチュード'] = df_ethq['マグニチュード'].astype(float) / 10
df_ethq['マグニチュード'] = df_ethq['マグニチュード'].replace(0.0, df_ethq['マグニチュード'].mean())
df_ethq = df_ethq.replace({'最大震度': {'A': '5', 'B': '6', 'C': '7', 'D': '8', '7': '9', ' ': '0'}})
jp_cities_omit = df_ethq.loc[df_ethq['最大震度']=='0']
jp_cities_omit_list = list(jp_cities_omit.index)
df_ethq = df_ethq.drop(index=jp_cities_omit_list)
df_ethq = df_ethq.reset_index(drop=True)
df_ethq['最大震度'] = df_ethq['最大震度'].astype(float)
lstans = []
wkint = df_ethq['緯度']/10000
for i in range(len(wkint)):
wkflt1, wkint1 = math.modf(wkint[i]) # wkflt1: 元は4桁の分(6000=60.00分)
wkflt1 = wkflt1 * 100 /60
lstans.append(wkint1 + wkflt1)
df_ethq['緯度'] = lstans
lstans = []
wkint = df_ethq['経度']/10000
for i in range(len(wkint)):
wkflt1, wkint1 = math.modf(wkint[i]) # wkflt1: 元は4桁の分(6000=60.00分)
wkflt1 = wkflt1 * 100 /60
lstans.append(wkint1 + wkflt1)
df_ethq['経度'] = lstans
df_ethq.to_csv('dataset/converted_target.csv')
return df_ethq
def draw_map(df_ethq):
fig = px.scatter_mapbox(df_ethq, lat="緯度", lon="経度", color="深さ", size="マグニチュード", \
hover_name="震央地名", hover_data=["日時", "マグニチュード", "最大震度"],
color_discrete_sequence=["fuchsia"], height=500, size_max=30, opacity=0.5)
# color_discrete_sequence=["fuchsia"], zoom=3, height=500, size_max=30, opacity=0.5)
fig.update_traces(uirevision='constant', selector=dict(type='scatter'))
fig.update_layout(mapbox_style="open-street-map")
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
fig.show()
df_ethq = pd.read_csv('dataset/converted_target.csv', index_col=0)
draw_map(df_ethq)
加工後をプロットすると、例えば福島近辺は下図のようになる。経度・緯度・深さでクラスタリングできるように見えてならない。
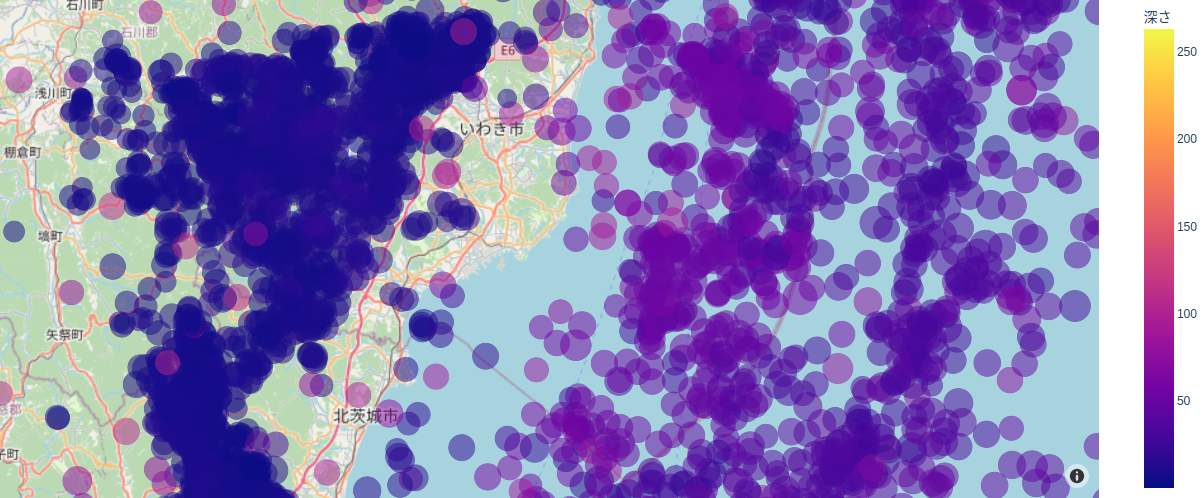
GMMでクラスタリング
以前投稿したGMMを使ってクラスタリングを行ってみる。初めに最適クラス多数を探す。使用するデータは'緯度', '経度', '深さ', 'マグニチュード'とする。最終予測対象である最大震度は使用しない。
import pandas as pd
import pandas_profiling as pdp
import matplotlib.pyplot as plt
import numpy as np
from sklearn.mixture import GaussianMixture
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def_find_cluster():
df_jp = pd.read_csv('dataset/converted_target.csv', index_col=0)
Y = df_jp['最大震度']
df_jp = df_jp.drop(columns='最大震度')
X = df_jp
test_size = 0.1
seed = 27
X_train_org, X_test_org, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
X_train = X_train_org.loc[:, ['緯度', '経度', '深さ', 'マグニチュード']]
X_test = X_test_org.loc[:, ['緯度', '経度', '深さ', 'マグニチュード']]
# 最適クラス多数を探す
n_components = np.arange(5, 30)
models = [GaussianMixture(n, n_init=10).fit(X_train)
for n in n_components]
fig, ax = plt.subplots(figsize=(9,7))
ax.plot(n_components, [m.bic(X_train) for m in models], label='BIC')
ax.plot(n_components, [m.aic(X_train) for m in models], label='AIC')
plt.legend(loc='best')
plt.xlabel('n_components')
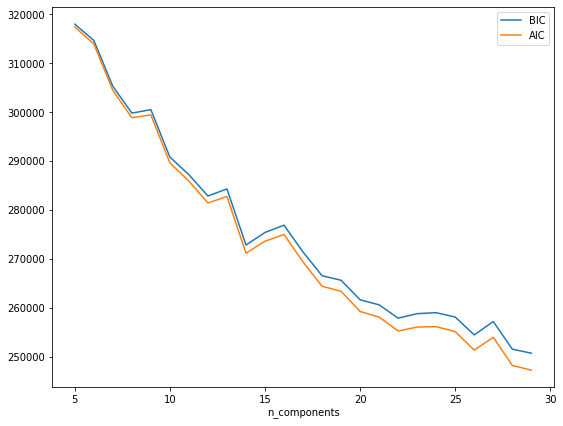
プロットを見ただけでもクラスタは多くなりそうとわかるが、14にくぼみがあるのでここでfitさせる。
gm = GaussianMixture(n_components=14, random_state=27, n_init=10)
gm.fit(X_train)
# fit()で収束したか確認
print(f'Convergence: {gm.converged_}')
y_pred = gm.predict(X_train)
X_train_org.loc[:, '最大震度'] = y_train
X_train_org.loc[:, 'cls'] = y_pred
# print(X_train_org)
X_train_org.to_csv('dataset/converted_target_pred.csv')
colorを深さからclsに変更して、Scatter plotすると下図のように何気にうまくクラスタリングできているように見える。
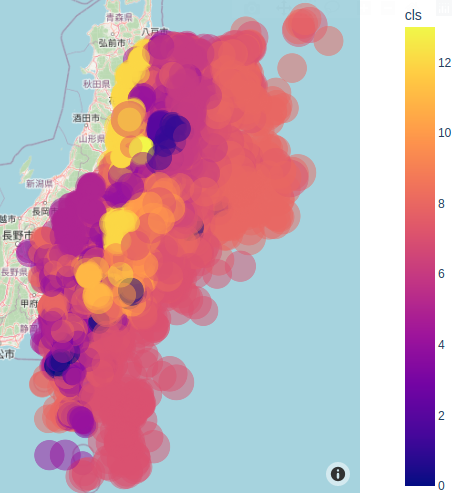

次回は、各クラスタで最大震度が予測可能か、回帰問題として挑戦してみる。
流れとしてはユーザが任意の緯度経度を入力し、確率分布的に一番近しいクラス(0~13)に振り分け、そのクラスで最大震度を予測する的な感じかな?
前段で最大震度を1~9に変換した。このまま線型回帰にするか、3レベルくらいに分けて識別問題にするか、精度を見ながら検討しなければならない。
余談
GaussianMixture()を実行中は、全CPU(スレッド)使用率が100%に張り付きぱなしになっていた。

でも、このときのCPU温度は78℃~79℃で安定している。このPCを組んだときケチってCPUクーラはRyzen付属のリテールクーラにしたことを後悔していたけど、案外冷えていて安心した。
ryzen@ryzen:~$ sensors
nvme-pci-0400
Adapter: PCI adapter
Composite: +27.9°C (low = -20.1°C, high = +74.8°C)
(crit = +79.8°C)
k10temp-pci-00c3
Adapter: PCI adapter
Tctl: +78.2°C
Tdie: +78.2°C