はじめに
プログラミングにおいて無駄な処理をしないようなコードを書くのは基本ではあるが、緻密で無駄のないコードを書くことは、ソフトウェアを実装する上での生産性や変更容易性に関して不利になる恐れがある。
- 実装スキルがそんなに高くない人やそのプログラミング言語に熟練していない人は、余計なことを考えずに愚直にコードを書きたいだろう
- 緻密で無駄のないコードは、作成時点での要求仕様を前提に無駄をそぎ落としているので、仕様変更時に変更量が多くなるリスクが考えられる
また、今時のプログラミングにおいては、言語仕様を活かした安全な書き方や便利な書き方は当然したい。
例えば、C言語であれば配列を用いていたデータでも、C++を用いるならstd::vectorなどのシーケンスコンテナを活用したい。
C言語であれば構造体のメンバを外部から直接いじっていたデータでも、C++を用いるならクラスのAPI経由でいじりたい。
とはいえ、C++の言語仕様を活かした書き方は、C言語の仕様の範囲での実装と比べて処理が重くなる心配はある。単純に考えれば、安全で抽象度の高い書き方は、処理のオーバーヘッドとのトレードオフがあるだろう。
もちろん、プログラミングにおける生産性、変更容易性、安全性と、処理のオーバーヘッドが少ないことを両立できれば、望ましいことである。結論を言えば、コンパイラの最適化のおかげで、これらはある程度両立できる。
以下、コンパイラの最適化によって両立できるかどうかを実験した。
実験方法
コンパイラの最適化をあてにせずに動作効率を意識して書いたコードと、同じ動作内容で無駄やオーバーヘッドのあるコードを、コンパイラの最適化オプションを変えてコンパイルし、実行時の処理時間を以下のようにして比較した。
- timeコマンドで得られるユーザCPU時間とシステムCPU時間の合計を処理時間とみなした
- 一つの測定パターンにつき100回測定し、それぞれのパターンについて、結果の上位10個と下位10個を除いた80回の平均を求めた(結果の上位と下位10個ずつを除く理由は、偶発的に良い結果や悪い結果が出た場合の影響を避けるためである)
- Ubuntu24.04(x86_64版)のGCC(バージョン13.3.0)を用いた
- GCCの最適化オプション指定として、-O0, -O1, -O2, -O3, -Osを比較した
実験 : 無駄があるが素直なコードの場合
無駄があるが素直なコードとは、悪く言えば「深く考えずに書いたコード」ではあるが、簡単に書ける(スキルを求めずに書くので生産性が良い)ことや、仕様変更があった場合の変更量や変更漏れを起こすリスクが少ないことを鑑みている。
ループ内で毎回しなくても良い処理をループ外に出す/出さない
本来はループの外で行って構わない以下の処理を、あえてループ内で毎回やるようにした。
- メモリの確保/解放 … メモリを使う直前に確保して、使い終わったらすぐに解放するのは、メモリの解放忘れ(メモリリーク)をしてしまうリスクが小さい
- ループ内で不変な計算 … 仕様変更によってループ内で不変でなくなっても、修正ミスをしにくい
static const int LOOP = 250000000;
static double check_data = 0;
static int last_count = -1;
// 計算処理(ループ内で不変)
double Calculate(double A, double B) {
return A * B;
}
// コンパイラの最適化によって処理結果がおかしくなっていないかの確認用関数
void PrepareCheck(double A, double B) {
check_data = Calculate(A, B);
}
inline void Check(double result, int i) {
if (result != check_data || i == last_count) {
printf("Error\n");
exit(-1);
}
last_count = i;
}
// メモリ確保/解放やループ内で不変な処理もループ内で行う場合
void Idiot(double A, double B) {
// Memory allocation can be moved to outside of the loop.
for (int i = 0; i < LOOP; ++i) {
double* pDummy = new double;
*pDummy = Calculate(A, B);
Check(*pDummy, i);
delete pDummy;
}
}
// メモリ確保/解放やループ内で不変な処理はループの外に出す場合
void NoIdiot(double A, double B) {
double* pDummy = new double;
*pDummy = Calculate(A, B);
for (int i = 0; i < LOOP; ++i) {
Check(*pDummy, i);
}
delete pDummy;
}
上記Func関数を呼ぶmain関数(上記Func関数とは別のコンパイル単位、コンパイル時にマクロ「IDIOT」が定義されているかどうかで動作を切り替える)
int main() {
const double A = 1.1;
const double B = 2.2;
PrepareCheck(A, B);
#ifdef IDIOT
Idiot(A, B);
#else
NoIdiot(A, B);
#endif
return 0;
}
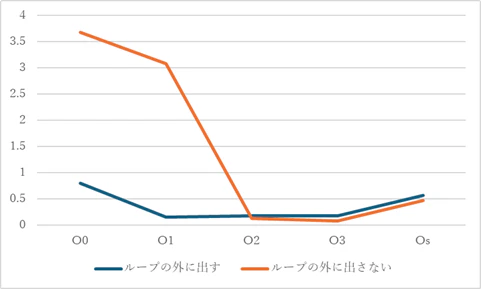
コンパイル時の最適化オプションを変えての両コード(ループ内で不変な処理をループの外に出す/出さない)の処理時間の比較は以下のような結果だった。結果の数値の単位は秒である。
-O2以上の最適をすれば、メモリ確保/解放や計算処理をループ内で毎回行っているプログラムでも、ループ外で1回だけ行うプログラムと同様の処理に最適化されるのだろう。
| -O0 | -O1 | -O2 | -O3 | -Os | |
|---|---|---|---|---|---|
| ループの外に出す | 0.796 | 0.155 | 0.172 | 0.172 | 0.562 |
| ループの外に出さない | 3.676 | 3.083 | 0.134 | 0.076 | 0.471 |
関数の途中でreturnする/しない
関数化された処理内部での条件分岐の結果によって、関数の途中の時点で処理を打ち切って構わない場合はそこでreturnするのが望ましい書き方ではあるが、それをせずに関数の最後まで到達してしまう書き方をした場合の影響を比較した。基本的には下手なプログラミングではあるが、強いて言えば、仕様変更によって必須の処理が途中のreturn以降に追加された場合に、修正(途中のreturnを削除)を見落とすリスクを回避できる。
関数化された処理のコード(マクロ「ENABLE_RETURN」を定義すると途中でreturnする)
#ifdef ENABLE_RETURN
#define RETURN return
#else
#define RETURN
#endif
#define CONVERT(i) ((i) * 10)
// 条件次第で途中でreturnできる処理
void func(int in, int* pOut) {
if (in == 0) {
*pOut = CONVERT(0);
RETURN;
}
if (in == 1) {
*pOut = CONVERT(1);
RETURN;
}
if (in == 2) {
*pOut = CONVERT(2);
RETURN;
}
if (in == 3) {
*pOut = CONVERT(3);
RETURN;
}
if (in == 4) {
*pOut = CONVERT(4);
RETURN;
}
if (in == 5) {
*pOut = CONVERT(5);
RETURN;
}
if (in == 6) {
*pOut = CONVERT(6);
RETURN;
}
if (in == 7) {
*pOut = CONVERT(7);
RETURN;
}
}
// コンパイラの最適化によって処理結果がおかしくなっていないかの確認用関数
void check(int in, int out) {
if (out != CONVERT(in)) {
printf("Error\n");
exit(-1);
}
}
上記func関数を呼ぶmain関数(上記func関数とは別のコンパイル単位)
#define LOOP 100000000
int main() {
int out;
int i, j;
for (i = 0; i < LOOP; ++i) {
for (j = 0; j < 7; ++j) {
func(j, &out);
check(j, out);
}
}
}
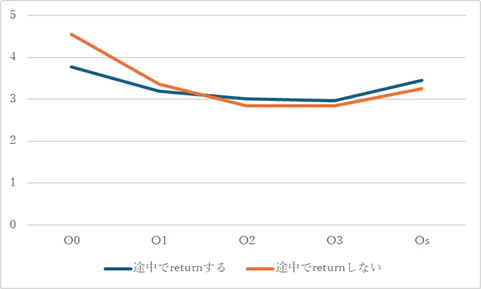
コンパイル時の最適化オプションを変えての、両コード(関数の途中でreturnできる場合はreturnする/しない)の処理時間の比較は以下のような結果だった。結果の数値の単位は秒である。
コンパイル時に最適化をすれば、-O1であっても両者の差はかなり小さくなり、-O2以上なら遜色ない。
| -O0 | -O1 | -O2 | -O3 | -Os | |
|---|---|---|---|---|---|
| 途中でreturnする | 3.770 | 3.197 | 3.005 | 2.963 | 3.459 |
| 途中でreturnしない | 4.551 | 3.357 | 2.844 | 2.844 | 3.248 |
実験 : C++らしいコード
C++はオブジェクト指向や、C言語に比べればモダンな仕様が利用できる。C言語に比べて便利で抽象度の高いプログラミングができる反面、単純に考えれば実行時のオーバーヘッドが大きくなる心配があるだろう。
データの集合として配列/std::vectorを用いる
データの集合を配列ではなくstd::vectorなどコンテナを用いて扱えるのはC++の利点ではあるが、配列のアクセスよりは若干オーバーヘッドは大きくなる。
そこで、同じ処理を配列を用いて行った場合と、std::vectorを用いて行った場合を比較した。
配列あるいはstd::vectorを用いたプログラム(マクロ「USE_VECTOR」が定義されていると配列ではなくstd::vectorを用いる、func関数およびcheck関数については後述)
#define LOOP 60000000
#define INIT_VALUES {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
int main() {
#ifdef USE_VECTOR
std::vector<int> a = INIT_VALUES;
std::size_t size = a.size();
#else
int a[] = INIT_VALUES;
std::size_t size = sizeof(a) / sizeof(int);
#endif
for (int i = 0; i < LOOP; ++i) {
for(std::size_t j = 0; j < size; ++j) {
func(i, &a[j]);
check(i, a[j]);
}
}
return 0;
}
上記プログラムから呼ばれるfunc関数およびcheck関数(上記プログラムとコンパイル単位は分けている)
// ダミーの処理用関数
void func(int i, int* a) {
*a = i;
}
// コンパイラの最適化によって処理結果がおかしくなっていないかの確認用関数
void check(int i, int a) {
if (a != i) {
printf("Error\n");
exit(-1);
}
}
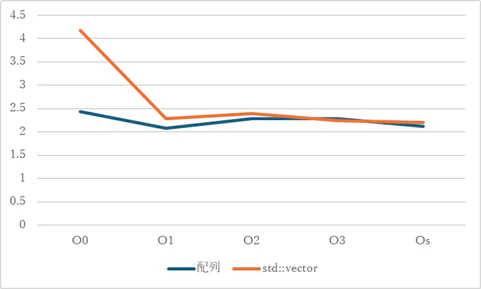
コンパイル時の最適化オプションを変えての、配列を用いた場合とstd::vectorを用いた場合の処理時間の比較は以下のようになった。
-O2や-O3で処理時間がかえってかかるようになっている理由は調査していないが、std::vectorを用いても-O2以上の最適化を行えば処理時間は配列を用いた場合と遜色ないだろう。
| -O0 | -O1 | -O2 | -O3 | -Os | |
|---|---|---|---|---|---|
| 配列 | 2.428 | 2.080 | 2.279 | 2.278 | 2.117 |
| std::vector | 4.171 | 2.284 | 2.399 | 2.247 | 2.198 |
構造体やクラスのメンバ変数をAPI経由でアクセスする/しない
C++のようなオブジェクト指向に対応した言語であれば、構造体のデータメンバを構造体の外から直接触らせるのではなく、クラスの体裁にしてAPI経由で外からアクセスさせたい。
とはいえ、データメンバを直接触る処理は変数アクセスであるのに対し、API経由だと関数呼び出しになってしまう。アクセスAPIをインライン化すれば、関数呼び出しのオーバーヘッドは避けられることを期待できるだろう。
データメンバへのアクセスを、構造体、クラス(API経由)、クラス(インラインAPI)の三者の場合について処理時間を比較した。
構造体やクラスの宣言
struct StructData {
int a;
int b;
};
class ClassData {
public:
void SetA(int x);
void SetB(int x);
int GetA() const;
int GetB() const;
private:
int a;
int b;
};
class ClassDataInline {
public:
void SetA(int x) { a = x; };
void SetB(int x) { b = x; };
int GetA() const { return a; };
int GetB() const { return b; };
private:
int a;
int b;
};
const int AB_INIT_VALUE = 0;
クラスのAPIの定義+ダミーの処理を行う関数(後述のmain関数とはコンパイル単位を分けている)
void ClassData::SetA(int x) {
a = x;
}
void ClassData::SetB(int x) {
b = x;
}
int ClassData::GetA() const {
return a;
}
int ClassData::GetB() const {
return b;
}
// コンパイラの最適化によって処理結果がおかしくなっていないかの確認用関数
static int last_b = AB_INIT_VALUE;
void check(int a, int b) {
if (a != last_b) {
printf("Error\n");
exit(-1);
}
last_b = b;
}
main関数(構造体を用いる場合はマクロ「USE_STRUCT」を、インラインAPIのクラスを用いる場合はマクロ「USE_CLASS_INLINE」を有効化する)
static const int LOOP = 500000000;
int main() {
#ifdef USE_STRUCT
StructData s;
s.a = AB_INIT_VALUE;
s.b = AB_INIT_VALUE;
#else
#ifdef USE_CLASS_INLINE
ClassDataInline c;
#else
ClassData c;
#endif // USE_CLASS_INLINE
c.SetA(AB_INIT_VALUE);
c.SetB(AB_INIT_VALUE);
#endif // USE_STRUCT
int loop = LOOP;
while (loop--) {
#ifdef USE_STRUCT
s.a = s.b;
s.b = loop;
check(s.a, s.b);
#else
c.SetA(c.GetB());
c.SetB(loop);
check(c.GetA(), c.GetB());
#endif
}
return 0;
}
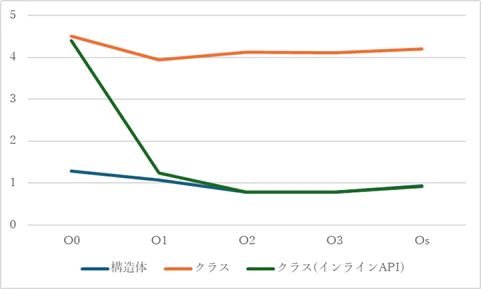
コンパイル時の最適化オプションを変えての、構造体のメンバに直接アクセスした場合と、クラスを用いてAPI経由でアクセスした場合、クラスのAPIをインライン化した場合についての処理時間の比較は以下のようになった。
最適化なし(-O0)では、inline指定をしてもクラスのAPIのインライン展開はされていなさそうである。-O1以上の最適化をすれば、APIをインライン化すればクラスのAPI経由のアクセスでも、構造体のメンバを直接アクセスした場合と同等の処理時間である。
APIをインライン化しない限りは、最適化をしても関数呼び出しのオーバーヘッドからは逃れられない。
| -O0 | -O1 | -O2 | -O3 | -Os | |
|---|---|---|---|---|---|
| 構造体 | 1.289 | 1.077 | 0.790 | 0.781 | 0.939 |
| クラス | 4.498 | 3.939 | 4.115 | 4.107 | 4.198 |
| クラス(インラインAPI) | 4.399 | 1.242 | 0.778 | 0.778 | 0.919 |
まとめ
無駄のなさでは甘い部分があるコーディングや、オーバーヘッドと引き換えに言語仕様を活かしたコーディングなどでも、コンパイラの最適化を頼れば性能への影響は抑えられると考えられる。
緻密で無駄のないコーディングをするに越したことはないのかもしれないが、コードレビューでは細かい無駄の指摘よりも、以下のような観点に注力しても良いのではないだろうか。
- 安全性や、誤りなく動作すること
- 原理的な計算量の違いを左右するようなアルゴリズムの選択
例えば画像処理などでは、計算量を節約できるアルゴリズムや、CPUキャッシュなどの挙動を考慮したメモリアクセスパターンを用いると効率良く実行できる。
コーディングでは、そのようなコンパイラではカバーできない大きな効率化に注力し、コンパイラの最適化でカバーできるような効率化は割り切って構わないだろう。
また、単に効率面で甘さが見られるだけの実装なら、内容次第や実装者の力量次第ではでは目をつぶっても良いかもしれない。
コーディングの担当者として実力者ばかりをそろえられるとは限らないので、力量の落ちる実装者に対するコードレビューでは、主に動作として誤りがないかに注力し、効率面の甘さには目をつぶることで、実装者とレビュー者の双方が疲弊することを避けられる。
コンパイラの最適化でカバーできそうなこととそうでないことのさじ加減は、本稿をここまで読まれたような方であれば肌感覚で分かるだろう。