不動産新着物件情報のサーバレス巡回通知システム
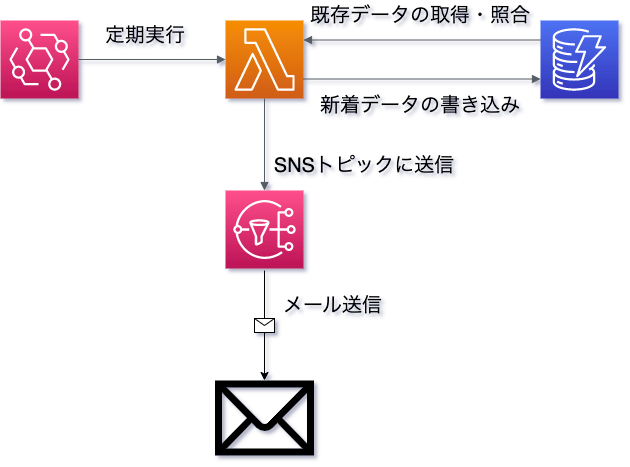
AWS各サービスを連携させ、SUUMOの検索結果を巡回して新着物件情報を通知します。
https://suumo.jp/
※requestsを用いたクローリングは直接的に利用規約違反にはなりませんが、負荷をかけることは禁止されています。どうやら新着物件情報は(SUUMOの場合は)1日に何度も頻繁には更新されないので、1時間以上に1回か、朝昼晩くらいの感じにしましょう。AWS無料枠の範囲に抑える観点からもそのほうが適しています。
本システムを利用するメリット
- 不動産サイト各社にはメール通知サービスはあるが、同一物件が通知されない保証はないのと、何社もメールを登録する個人情報的なリスクを回避できる
- 当然、自前のシステムなので検索条件は実質無制限に設定できる
- BSのパーサーは変更が必要になるが、SUUMO以外の不動産サイトにも対応可能(AWSのIPからのアクセスをブロックしていなければ&RequestsでHTMLを取得できる形式なら)
- 引っ越しを検討しているときだけ作動させればいいので無駄がない
使ったAWSサービス
- EventBridge Scheduler
- Lambda
- SNS
- DynamoDB(SUUMOのみならRDSでOK)
EventBridge Scheduler
2022年末にリリースされた新しいSchedulerの機能を用いています。cron記述が不要で、シンプルに「2分ごと」など指定できます。
設定の変更時に威力を発揮すると思います。cronだと普段から書いてないと書き方から調べ直しになりますが(間違いを防止するためにも)、SchedulerでしたらGUIで簡単に間違えようがなく設定できますし、「1回限りの実行」とテストにおあつらえ向きの機能も備わっています。
Lambda
コードはlambda.pyを参照。BeautifulSoupなど外部ライブラリはpipインストールのような文明は使えないので、Dockerを使わないでベタ書き実装する場合はレイヤーを追加する必要があります。
しかし、検索で山程出てきた情報ではなぜかうまく行かなかったので、arnを提供してくださっている方のarnをレイヤーに追加すれば問題なくいけました。
巡回するURLと、DynamoDBのパーティションキーとなる「PK」は、環境変数で指定する必要があります。
SNS
メール送信を用いています。
DynamoDB
SUUMOのように単一サイトの場合はBeautifulSoupで整えた形が均一なのでRDBで問題ありませんが、学習のためにもNoSQLを採用しました。サイトごとにDBを変更すれば尚更RDBで問題ないと思います。
設計として、パーティションキーには検索条件のタイトルをLambdaの環境変数に入れています。例えば、渋谷区10万円なら['shibuya10']といった具合です。
ほか、パーサーした各種データを放り込んでいます。
ソートキーには家賃を採用しています。
パーティションキーおよびソートキーを考えればあとは何も考えなくていいというのは、NoSQLのメリットかもしれません。たとえば、駅徒歩何分の情報は3駅まで掲載されるので、それがリストになることでリスト型を格納する必要がありますが、NoSQLでしたら考える必要はありません。
ビジョン
- 複数のLambdaで分散設計にしつつ、SUUMO以外の不動産サイトもクローリングできるようにしたい
- DynamoDBに格納されたデータは当然まとめて閲覧できるが、それらを分析できるようにしたい(分析する意味は除いて、学習のためにも)