Railsログ基盤をCloudWatch LogsからS3 + Athenaへ移行した話
Railsアプリケーションのログ基盤を、CloudWatch LogsからS3 + Athenaに移行しました。本構成は現在ステージングと本番環境の両方に適用済みです。弊社ではAmazonのマネージドサービスを活用しつつ、Terraformでインフラを構築・管理しています。
背景と目的
本ログ基盤の刷新は、以下の目的に基づいています:
- プロダクト改善施策の立案に必要な傾向分析
- システム構成やワーカー数の最適化に向けた実測データの把握
- 利用状況の可視化に基づくコスト見積もりやリソース配分
- AI活用を見据えたログデータセットの整備と統一フォーマット化
これらをコスト効率よく実現するため、CloudWatch Log Insightsベースの構成からS3 + Athenaを活用した構成へ移行しました。
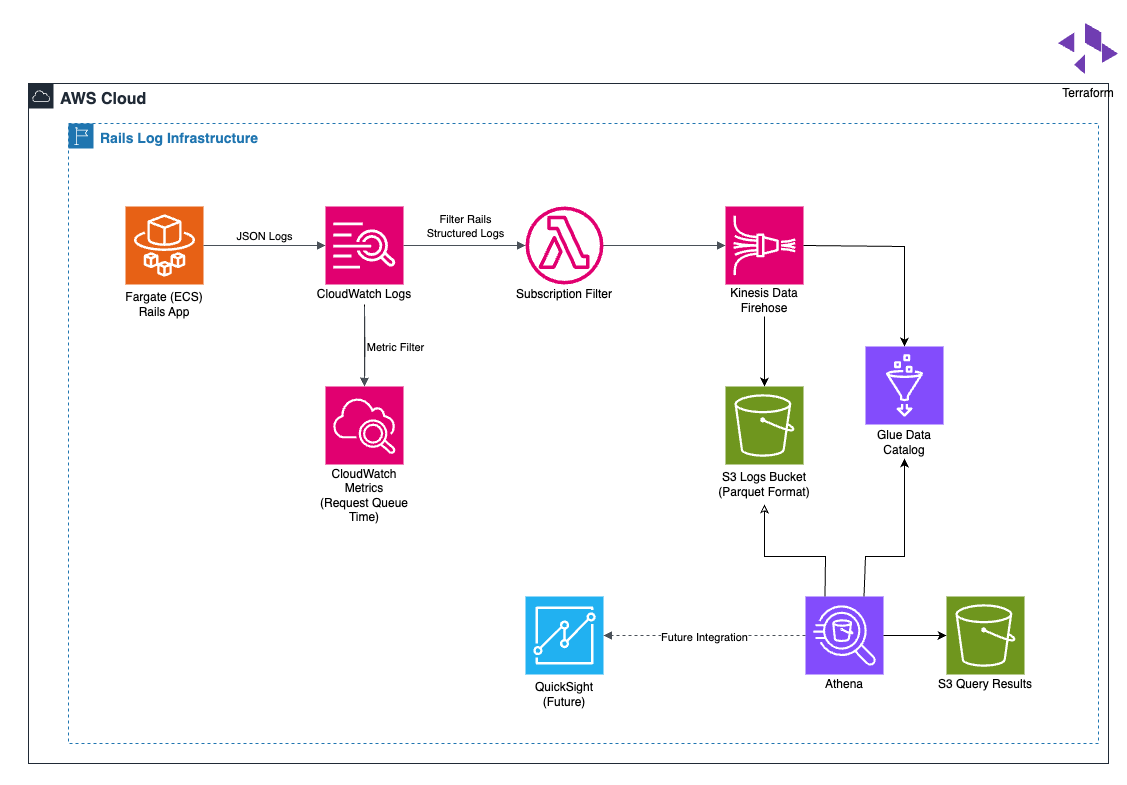
全体構成
ログの流れは以下の通りです:
CloudWatch Logs
→ Subscription Filter
→ Kinesis Data Firehose (+ Glue Data Catalog)
→ S3 (Parquet形式)
→ Athena
CloudWatch Logsに集約されたアプリケーションの標準出力から、Railsの構造化ログのみをSubscription Filterで抽出し、Firehose経由でS3に転送・保存しています。
検討したが導入しなかったもの
FireLens
FireLens(Fluent Bit)を使ってログを直接Firehoseへ転送する構成も検討しましたが、以下の理由から見送りました:
- Fluent Bitのconf記述に関する学習コストが高く、運用負荷を避けたかった
- WAFをすり抜けるPOST Flood攻撃などに即時対応するのに、CloudWatch Logsによる即時可視化が必要だった
- 冗長性の観点から、Firehose障害時にもCloudWatchにログが残る構成の方が望ましい
参考:
- FireLens って結局なんだっけ?どう使えばいいの?
- AWS ECS on Fargate + FireLens で大きなログが扱いやすくなった話 | BLOG - DeNA Engineering
Embedded Metrics Format
カスタムメトリクスを取る際、アプリ側のAPI呼び出しに付随するレイテンシや非同期処理の実装を避ける目的でEmbedded Metrics Formatの導入も検討しました。
しかし最終的にすべてのログをCloudWatch Logs経由にしたため、CloudWatch Logsのメトリクスフィルター機能を活用する方が構成としてシンプルで明快と判断しました。
参考:
Railsログの整備と活用
ログの構造化と秘匿情報のフィルタリング
RailsのログをLogrageでJSON形式に変換し、Athenaで扱いやすい形に整備しています。特にPOSTパラメータに含まれる長文や秘匿情報に対しては、トランケート処理とフィルタリングを行っています。
config.lograge.custom_options = ->(event) do
exceptions = %i[controller action format authenticity_token]
{
datetime: Time.current.strftime('%F %T'),
params: ActiveSupport::ParameterFilter.new(
config.filter_parameters +
[->(_k, v) { v.replace(v.truncate(256, omission: '...')) if v.is_a?(String) }]
).filter(event.payload[:params].except(*exceptions)),
request_queue_time_ms: event.payload[:request_queue_time_ms],
bot: !!event.payload[:bot]
}
end
参考:
Pumaのキュー時間(request_queue_time_ms)の記録と可視化
RailsのコントローラでX-Request-Startヘッダーを元にPumaのキュー時間を計算し、ログに含めています。これはCloudWatch Logs上でメトリクスフィルターを使い、可視化・監視可能としています。
Railsパフォーマンスアポクリファでpumaのワーカー数を決定するための指標として紹介されていたため取得するようにしました。
def set_request_queue_time
x_request_start = request.headers['X-Request-Start']
if x_request_start
start_time = Time.at(x_request_start.sub('t=', '').to_f / 1000)
request.env['request_queue_time_ms'] = ((Time.current - start_time) * 1000).round(2)
end
end
resource "aws_cloudwatch_log_metric_filter" "request_queue_time" {
name = "RequestQueueTimeMs"
log_group_name = aws_cloudwatch_log_group.web_app.name
pattern = "{ $.request_queue_time_ms = * }"
metric_transformation {
name = "RequestQueueTimeMs"
namespace = "ServiceName/Staging"
value = "$.request_queue_time_ms"
unit = "Milliseconds"
}
}
参考:
- メトリクスフィルター、サブスクリプションフィルター、フィルターログイベント、およびライブテールのフィルターパターン構文 - Amazon CloudWatch Logs
- Ruby on Rails パフォーマンス アポクリファを読んで育休明けにやりたくなったこと #パフォーマンスチューニング - Qiita
AWS側での設計ポイント
Firehose受信時刻でのパーティション化
CloudWatch LogsからのSubscription Filter経由で届くログは圧縮されたDataMessage形式のため、FirehoseのMetadata Extractionを使ってログ内のtimestampでパーティションを切ることができません。そのため、Firehose受信時のUTCを使ってパーティションを作成しました。
参考:
resource "aws_glue_catalog_table" "rails_log" {
name = "rails_log"
database_name = aws_glue_catalog_database.log.name
table_type = "EXTERNAL_TABLE"
parameters = {
"projection.enabled" = "true"
"projection.year.type" = "integer"
"projection.year.range" = "2023,2030"
"projection.month.type" = "integer"
"projection.month.range" = "1,12"
"projection.month.digits" = "2"
"projection.day.type" = "integer"
"projection.day.range" = "1,31"
"projection.day.digits" = "2"
"storage.location.template" = "s3://${aws_s3_bucket.logs.bucket}/rails/year=$${year}/month=$${month}/day=$${day}/"
}
storage_descriptor {
location = "s3://${aws_s3_bucket.logs.bucket}/rails/"
input_format = "org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat"
output_format = "org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat"
serde_info {
serialization_library = "org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe"
}
}
}
Firehoseのバッファ設定とParquet化
Athenaの推奨に従い、Firehoseのバッファサイズは128MB、間隔は15分に設定。Parquet形式で保存することで、クエリ時の読み取り効率と圧縮効率を高め、クエリコストも抑制しています。
参考:
S3バケットの分離とIAM設計
RailsログとAthenaクエリ結果を格納するS3バケットを分離することで、サービス本体からのアクセス権限(読み取り専用)を明確に制御できるようになり、IAMポリシーの設計が簡素化されました。
詰めきれなかったところ
- Firehoseの変換エラーはCloudWatch Logsにしか出力されないため、CloudWatch Alarmを組んで通知する運用が必要
- ログ内のdatetimeはJSTである一方、パーティションはUTC基準のため、Athenaで絞り込みを行う場合はパーティションを1日広めに取る必要がある
今後やりたいこと
- QuickSightを使用したビジネス側のダッシュボード整備
- サービス利用者へのアナリティクス機能提供
- Firehoseやその他AWSリソース側のエラー通知
おわりに
CloudWatch LogsからAthenaへ移行するにあたって、構成はシンプルながらも、細かい仕様や制約に向き合う必要がありました。
運用開始後は、Athenaを用いたアクセス傾向分析や、API利用実態の調査・コスト見積もりに既に活用されており、移行の価値は十分にあったと実感しています。