Ruby on Rails パフォーマンス アポクリファを読みました。
https://nateberk.gumroad.com/l/apocrypha_ja
Railsのパフォーマンス改善をライフワークにしている方が、自身のワークショップの外伝として著したものです。
パフォーマンス問題には常に頭を悩ませており、ネットの記事を拾い読みするだけでは限界を感じたため購入しました。
いつもは読書メモ載せて終わりにするところなんですが、育休復帰後すぐ実践移すために、取り入れようと思ったことを残しておきます。
弊社ではECS上でRailsアプリケーションを運用し、Sentryを用いたエラー監視・パフォーマンス分析を行っています。表示箇所も併せて記載します。
計測について
12のベンチマークを計測する
標準的なRailsアプリケーションの目指すべき指標が記載されていました。これだけでもかなりありがたい。
調べてみた感じ、インフラコスト、テストの実行速度、ページのダウンロードサイズ、DBのクエリ速度、Rails/Rubyのバージョンあたりが厳しそうだなと思いました。
- レスポンスタイム
平均で300m秒以下、95%では1秒以下であるべき
Sentryでは平均レスポンスタイムの項目が見当たりませんでした。
ヘルプにAverage Transaction Durationの記載はあるので、見落としているだけかもしれませんが…
95%では1秒以下であるべき、というのはInsights -> Backend PerformanceからP95という指標で見ることができます。

P50: すべてのトランザクションのうち50%が超える時間
P95: すべてのトランザクションのうち5%が超える時間
例えばP50が200ms, P95が500msのとき
ユーザーの半数は200m以上の待機時間がある
ユーザーの5%は500ms以上の待機時間がある
ということです。
- ホスティングにかかる総コスト
たとえば、1 分間に 1000 リクエストを処理する場合、1 か月にかかる費用は 1000 ドル未満であるべきです
これは大幅に超過していたのでしっかり見直す必要があります。
コスト順でいくとRDB >> ECS > CloudFront ≒ OpenSearchという感じでした。
特にRDBは増えすぎたレコードを捌くために2ランクぐらい上のサイズのインスタンスを使ってしまっているので早急に対応したいです。
ECSはEC2で動かしていたバッチをほぼそのまま持ってきてしまっているので、実行時間と頻度を抑えればコスト削減できそう。
OpenSearchの方はリザーブドインスタンスに変えることでわずかですが抑えられそうです。
- メモリ
ほとんどの Rails プロセスは約 512MB のメモリを使用します。したがって、1GB 以上使用しているプロセスは通常、メモリ消費に何らかの問題があります
タスクはnginx+Railsコンテナで構成されていて、1vCPU,2GBのリソースで動いています。
Pumaはシングルプロセス、5ワーカーで走らせています。
サービスのメトリクスにはなってしまいますが、平均だと40%以下だったので概ね問題はないはずです。
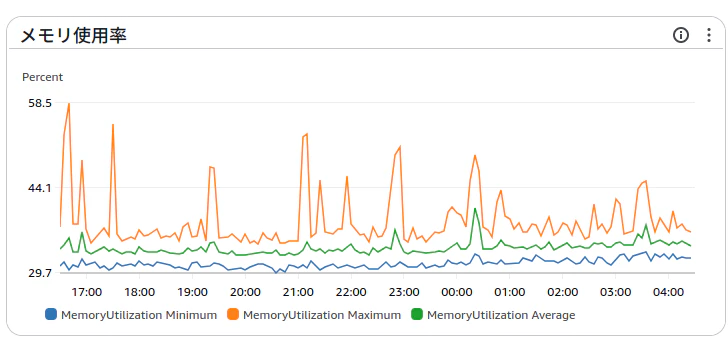
デプロイ直後はピークが50%を超えることがありメモリを1GBには下げられていません。
bootstrapがとにかく遅いのでちゃんと分析したいところです。
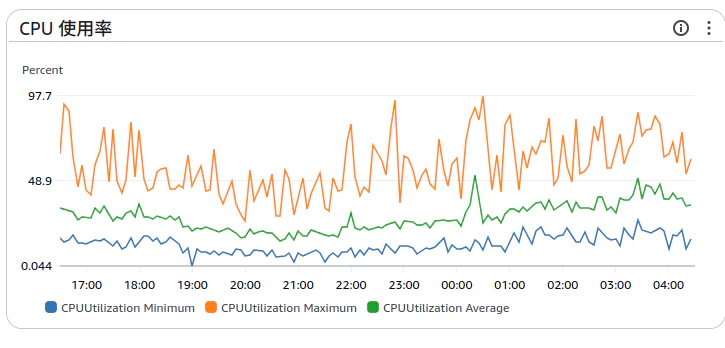
- CPU
使用率 80% 未満、負荷指標はマシンのコア数の約 80% 以下に等しいです
- Webサーバーごとのホスト数
各 Web サーバー(または dyno、VPS)には、少なくとも 4 つのプロセス(Puma ワーカー、Unicorn ワーカーなど)が稼働している必要があります。
Pumaをシングルプロセス5ワーカーで動かしているので大丈夫かなとも思いましたが、きちんと計算してみました。
New RelicだとNetwork, Ruby, I/Oがそれぞれどれくらいの比率か分かるようですが、Sentryでは分からず…
パフォーマンスから個別のリクエストでどういう比率になっているかは確認できましたが、全体の比率は見つけられませんでした。
大まかな計算方法も記載されており、1プロセスあたりのワーカー数はI/O比率から求めるのが良いようです。
代わりに、次の経験則をお伝えします。最大リクエスト負荷(すなわち、無限のリクエスト/秒)の元では、CPU 負荷は、アプリケーションスレッド数* CPU 律速な作業に費やされるリクエスト時間の割合に向かう傾向を示します。
CPU 負荷が 1.5 でスレッドが 2 つある場合、平均レスポンスタイムの約 25% が I/O になります
例えば5スレッド * CPU負荷 = 0.4なので、CPU負荷は8%、92%がI/Oになりますね。
都市伝説バスターズ「WebアプリのボトルネックはDBだから言語の性能は関係ない」
およそチューニングされていないRailsアプリでもI/O比率が80%もあることはそうない。
とのことなので、だいぶ良くないですね…10ワーカーぐらいあってもいいような状態になってしまっています。
ピークでは100%に達しているところも多くあるので、様子を見ながら一旦ワーカー数を増やしてI/O比率を改善していくのが良さそうです。
- キャッシュヒット率
データベースや Memcache など、全てのキャッシュはヒット率が95% 以上であるべきです。
キャッシュミスをした場合はredisなどへの問い合わせ時間+本来の処理でキャッシュ導入前よりも時間がかかる、ということになってしまうためヒット率が大事だということですね。
これもElastiCacheを確認したところ60%程度だったため駄目そうでした。
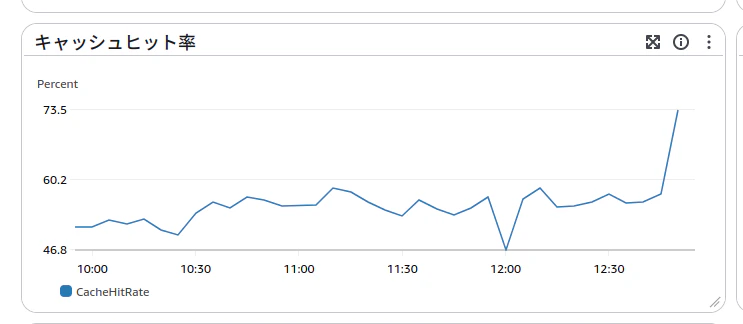
確認したところ、user_idをキーにしたフラグメントキャッシュが多い, キャッシュのexpires_inが短いためこのような状況になっていそうでした。
ECS導入の際、キャッシュストアにRedisを採用をしましたが、コストもかかるし代替手段を見つけたいところです。
ActiveSupport::Cache::FileStoreDockerのVolumeマウントとかでなんとかならないかなと思ったんですが、非推奨のようですね…
トラフィックが中規模程度のサイトを1、2個程度ホストする場合に向いています。異なるホストで実行するサーバープロセス間のキャッシュを共有ファイルシステムで共有することも一応可能ですが、おすすめできません。
https://railsguides.jp/caching_with_rails.html#activesupport-cache-filestore
- ページのダウンロードサイズ
ページのダウンロードサイズは 2MB 以下が望ましいです。
これはChromeのDeveloper Consoleのネットワークタブ下側に表示されており、フルリロードした際の値で良いようです。
計測したところ、4.0MBだったので改善の余地がありそうです。

Cookpadはどのページも1MB以下に抑えられていたのでさすがという感じですね
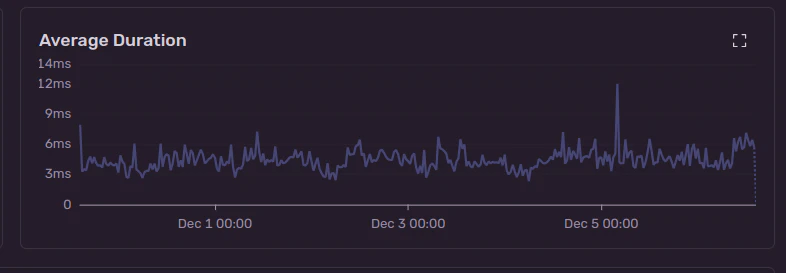
- DBのクエリ速度
アプリケーションから見た場合、ほとんどのクエリーは 10ms 以下であるべきです
SentryだとInsights -> Backend Performance -> クエリー内のAverage Durationから確認できました。
一応10msには抑えられているようです。にも関わらずI/O比率が高いということは、一部のクエリが著しく遅くなっている、HTTPリクエストなどSQL以外の外部アクセスに時間がかかっている、などの原因が考えられそうです。
- RailsとRubyのバージョン
許容できるのは、現在の Rails のバージョンから最大で 1 メジャーバージョン、Ruby のバージョンから 2 マイナーバージョンの遅れまでです
現在Rails8がリリースされ、Rubyは最新バージョンが3.3.6でした。
(Rails7まで、Ruby3.1までであるべき)
これも意識して改善する必要がありそうです。
- 開発者1人あたりのコード行数
裏付けとなるデータが多くあるわけではありませんが、ほとんどのコードベースでは、アプリケーションコード 2 万行につき 1 人の開発者が必要だと感じています
これも計算したところ足りていませんでした。
現状の稼働比率で考えたところ肌感として納得できる数値だと思いました。
- テスト速度
テストは 100 アサーション/秒(RSpec であれば example /秒)かそれ以上の速度で実行する必要があります
2500exampleで実行時間が13分程度でした。
2500 / 100 = 250秒ぐらいで終わらないようなのでだいぶ厳しい…
続いて本書には下記のような記載がありました。
多くのテストスイートでは、FactoryBot が 50% 以上の時間を費やしています
「create() を build() や build_stubbed() で置き換えればいい」とアドバイスされることがよくあります。確かに、そうできますし、性能上の利点もあります。
また、setupやbeforeで重い処理が毎テストケース実行される、ということも指摘されていました。
流石に1つのexample済むassertionを分割しているということは無さそうなのですが、ElasticSearchのテストが多く含まれているため、インデックスの生成、削除に時間がかかっていそうだなとは思いました。
buildやbuild_stubbedで置き換え、は工数的に難しそうですが、Rails6からparallel testingが標準でサポートされているため、なんとかそちらでカバーしたいところです。
またElasticsearchを使った並列テストも下記のような記事があり対応できそうです。
Rails RSpec Elasticsearch 並列テストスイート | Rubynor
テスト用のElasticsearchが提供されているときもあったようですが(Elasticsearch::Extensions::Test::Cluster),deprecatedになっていました…
Elasticsearch-extensions (Test::Cluster) replacement? · Issue #1354 · elastic/elasticsearch-ruby
ほか、テスト中はリフレッシュ間隔(refresh_interval)を止めたりすることも効果がありそうです。
ElasticSearch(OpenSearch)が重いときはrefresh_intervalを長くしてパフォーマンスチューニングする
- メモリ内部
1トランザクションに割り当てられるオブジェクト数は75000以下であるべき
ガベージコレクションは100トランザクションあたり20回以下、メジャーGCは100トランザクションあたり3以下
ヒープサイズは150万オブジェクト以下であるべき
これはちょっと今確認できないので、いつかbenchmarkをとってみたいですね。
Sentryのドキュメントを読む
何よりもまず計測、というところでAPMに習熟する必要があると感じました。
弊社では最初はNewRelicを導入していたのですが、コスト面と多機能すぎて利用のハードルが高いこと、エラー監視をまず優先して取り組みたいということからSentryを利用しています。
あまり日本語での情報がないのでSentryではどのページにアクセスすればその指標が見られるのか、ということは意識してメンバーに伝えていきたいところです。
フレームグラフを読めるようにする
Sentryではパフォーマンス->Profiles->Flamegraphから見ることができました。
まだあまり深く読み込めてはいないのですが、要するに
- コールスタックの中からアプリケーションコードで時間がかかっているものを見つける
- 深堀していって、実際に何の処理で時間がかかっているのかを見る
ということだと理解しました。
また、下記のスライドも参考になりました。
フレームグラフこわくない - Singedで始めるパフォーマンス改善
APMへ送るデータ量を見直す
たとえ全ホストの5%でも十分なデータが得られます
最低プランで運用しており、現在のレートは1%なのでSentry習熟後には引き上げたいところです。
/benchmarksディレクトリにmy_benchmark.rbを用意する
計測したい指標に合わせて/benchmarksディレクトリ内にファイルを用意し、簡単に計測できるようにするべきということでした。
例えばオブジェクトがどれぐらい生成されているかを調べる際には下記のようなコードを用いることになります。
GC.disable
before = ObjectSpace.count_objects
# ベンチマークを取るコードをここに記述
after = ObjectSpace.count_objects
puts(before - after)
# どのような種類のオブジェクトが作成されたかをおそらくここに記録
本番と開発がほぼ同じになるような設定をワンタッチで切り替えられるようにする
本番と同様の環境で計測することが大事なので、環境変数を用いて環境の差異を減らせる仕組みを用意したいです。
例えば本書では下記のような掲載がありました。
if ENV['PROFILE']
config.cache_classes = true
config.eager_load = true
config.logger = ActiveSupport::Logger.new(STDOUT)
config.log_level = :info
config.public_file_server.enabled = true
config.public_file_server.headers = {
'Cache-Control' => 'max-age=315360000, public',
'Expires' => 'Thu, 31 Dec 2037 23:55:55 GMT'
}
config.assets.js_compressor = :uglifier
config.assets.css_compressor = :sass
config.assets.compile = false
config.assets.digest = true
config.assets.debug = false
config.active_record.migration_error = false
config.active_record.verbose_query_logs = false
config.action_view.cache_template_loading = true
end
弊社だとjs_compressorがterserになっていたりするので調整して設定する予定です。
rack_miniprofilerを本番でもONにできるようにする
本番と同様の環境で、ということであればもう本番でプロファイラを動かしてしまえばいいということですね。
下記のような記載がありましたが、管理ユーザーのすべてのリクエストが遅くなる可能性があるので、リクエストヘッダーやクエリパラメータを見るような形式で取り入れたいと思います。
before_action do
if current_user && current_user.is_admin?
Rack::MiniProfiler.authorize_request
end
end
warn_on_records_fetched_greater_thanを設定する
クエリから返されたレコード数が非常に多い場合の警告を有効にします。
active_record.warn_on_records_fetched_greater_than
development モードでは常にオンにしつつ、バックグラウンドジョブを実行するときだけ production モードでもオンにするのが便利でしょう。
find_eachやペジネーションを適切に設定できていない箇所を見つけるのに使えそうです。
stagingでは常にONで良さそうかなと思っています。
フロントエンドのロード時間を計測する
パフォーマンスチューニングというとRubyコードやSQLのクエリを調整することをイメージしがちです。しかし、ユーザーにとってはアセットのダウンロードなどフロントの影響が大きいので、まずはそちらから取り掛かるとよいということでした。
実際LightHouseのレポートを確認したところ、JSの評価、コンパイルにかなり時間がかかっているようでした…
本書には具体的な計測方法や指標は記載がなかったのですが、ちょうど最近下記のような素晴らしい動画が公開されていたので、視聴して理解を深めようと思います。
[社内勉強会] mizchiさんのパフォーマンスチューニングイベントについていくための準備をしました
mizchiさんによる「LAPRAS 公開パフォーマンスチューニング」~調査編~
インフラでできること
単一ドメインを使用するように変更する
アセットに別のドメインを使うのは止めましょう。その代わりに、1 つのドメインへは 1 つの接続だけ
で済むようにし、2 回目のドメイン検索を無くしましょう
いまjs, cssなどのアセットとリサイズした画像を別々のCDN(ドメイン)から配布しているので、統合する方法がないか調べたいです。
wwwを含めてすべての前にCDNを置く
CDNといえば静的コンテンツの配信、というイメージでしたが最早そうではないらしく…
TLS接続がCDNまででよくなるのと、CDN以降オリジンまでのネットワークは高速化されているようなので、キャッシュしない場合でもCDNは置いたほうがいいらしいです。
下記のようなポストもありました。
CloudFrontでHTTP/3を有効にする
CloudFrontはHTTP/2の優先度付きリソースをサポートしていない、という記載があったので色々検索したところ、HTTP/3は使えるようなので設定すれば多少早くなる人も出てくるのではと思っています。
NginxでリクエストヘッダーにX-Request-Startを追加する
ですから、Web サーバーをレスポンスタイムに基づいてスケーリングしてはいけません。代わりに、リクエストのキュー時間に基づいてスケーリングする必要があります
EC2 インスタンス上でリバースプロキシ(NGINX または Apache)を使用し、自分でヘッダーを追加する必要があります。
タスクごとの最適なワーカー数がわかったところで、じゃあ何タスク動かすのが最適かという話です。
キュー時間がほとんどないのにタスクを増やしても意味がないので、まずはリクエストキュー時間を計測できるようにしたいです。
ALBでは付与できないそうなのでNginxでX-Request-Startを設定し、さらにSentryのカスタムスパンを設定する必要があります。
(下記はAI生成のコード)
class ApplicationController < ActionController::Base
before_action :start_request_queue_timer
private
def start_request_queue_timer
request_start = request.headers['X-Request-Start']&.to_f
if request_start
queue_time = (Time.current.to_f - request_start / 1000)
Sentry.configure_scope do |scope|
scope.set_span(Sentry.get_current_scope.get_transaction.start_child(
op: 'request.queue',
description: 'Time spent in queue before request processing',
start_timestamp: request_start / 1000,
end_timestamp: Time.current.to_f
))
end
end
end
end
Custom Instrumentation | Sentry for Ruby
Backendでできること
ページの中で何に時間がかかっているかを可視化し、必要ないものを削減する
単純に表示するものを減らせばその分だけ処理は早くなる、ということでページ内のクリック頻度、処理にかかる時間を求め、ビジネス側と相談の上表示量を調整できると良さそうだなと思いました。
キャッシュを使用している箇所を見直し、クエリで解決できないか確認する
キャッシュヒット率の項目にも繋がるところですが、そもそもキャッシュすべき箇所かというところを見直す必要がありそうです。
特にクエリでの解決を諦めて一旦キャッシュで対応、ということになっているところが多いので、キャッシュはタダではなくヒット率によっては通常のリクエストが悪化することもあるということを周知したいです。
Turboを復活させる
もし、あなたが毎日作業している Ruby アプリケーションがまだ Turbolinks を使っていないなら、こう考えてみてくださいShopify、GitHub、Basecamp という「ビッグ 3」の Rails サイトはすべて、何らかの形での「view-over-the-wire」技術を使用しています。
以前は古いTurbo-link(2系)が使用されており悪さをしているようだったので消したのですが、本来悪いものではないはずなので復活させたいです。
一応非同期読み込みにはrender_asyncを使用しているのですが、これもTurboに置き換えたいです。
例外を使うコードを減らす
rack-mini-profiler を使い、リクエストごとに 10 数個の例外が発生していることが確認されたなら、改善の余地があるということです。
あまり影響が大きくなさそうなので意識的な部分ですが、パフォーマンスの観点からも通常の処理の中でif-elseの代わりにrescueを使うのはやめようということを周知していきたいです。
クエリキャッシュすら呼ばれないようにする
User Load (0.5ms) と表示される代わりに、CACHE User Load (0.0ms) と表示されました。0 ミリ秒です。これは素晴らしいことです。つまり、Active Record の「ホット」なクエリーキャッシュからの取得はタダということでしょうか?そういうわけではありません。
クエリキャッシュが使用されているといっても、そのクエリを組み立てるまでのコスト、そこからインスタンスを生成するコストはタダじゃないという話です。
例えば下記のようなコードはsession[:user_id]がnilだったりUserが見つからなかったとき、オーバーヘッドが生じます。
@current_user ||= User.find_by(id: session[:user_id])
これを避けるためには下記のような形でそもそも呼び出し自体を抑える必要があるということです。
@current_user ||= User.find_by(id: session[:user_id]) if session[:user_id]
その他大事だと思ったこと
技術的負債を計測する
負債とは、極めて定量的なものです。レスポンスタイムの平均と 95 パーセンタイルを監視することで、パフォーマンス負債を測定できます。先月より良くなっているのか、それとも悪くなっているのか? フィーチャーベロシティは、1 日か 2 日かけてプロセスを作り上げれば、簡単に測定できます。
技術的負債もコードの変更にかかる負債なのか、パフォーマンス上の負債なのかを分けて分析するべきだと思いました。
弊社では一時期CodeClimateを使用しており、ある程度改善が見られたので解約したのですがもう一度確認してみるのも良さそうです。
リードレプリカの使用を遅らせる
Amazon は実際に、SQL データベースをスケールする際に監視すべき非常に有用なメトリクスのリストを提供しています。これらのメトリクスのいずれかが許容値を超えたら(通常は CPU かIOPs)、プランをスケールアップします。
リードレプリカは設定を複雑にし、コストも高く有効に使うのは難しいので、なるべくスケールアップで対応したほうが良いとのことでした。
分析目的で重いクエリを発行する可能性があるときはリードレプリカを検討するとのことでしたが、そういう用途だとBigQueryでカバーするのもアリかと思います。
おわりに
今まではパフォーマンスチューニングといえば主にバックエンドを調整することだと思っていたため、学びがありました。
本書では他にもGVLの仕組みやI/O比率でワーカー数を設定するのはなぜなのか、というところが詳しく説明されています。
値段も¥1,000程度とお求めやすく150ページ程度でさくっと読めて次のアクションを考えるきっかけになるので、目次を読んで興味を持たれ方はぜひ読んでみてください。
『Ruby on Railsパフォーマンスアポクリファ』 - snoozer05's blog