この記事について
NiFi における分散処理の考え方について、図解や設定方法を交えながら解説します。
NiFi 用語集の「分散処理の考慮ポイント」もあわせて参照してください。
NiFi における分散処理の考え方
NiFi における分散処理では、以下の2点を考えて設計する必要があります。
① プロセッサーの設計
→ プロセッサーを単一ノードで処理するべきか、分散して処理するべきか
② コネクタの設計
→ 前後のプロセッサーの負荷分散状況を踏まえ、それらのプロセッサーをコネクタでどのように設計するか
以下に、それぞれの考え方についてもう少し詳しく書きます。
① プロセッサーの設計
NiFi のプロセッサーには、その処理を単一ノード(=プライマリノード)で実施するのか、全ノードで実施するのかを選択する設定項目があります。
(下図はNiFi 用語集の「分散処理の考慮ポイント
」より引用)
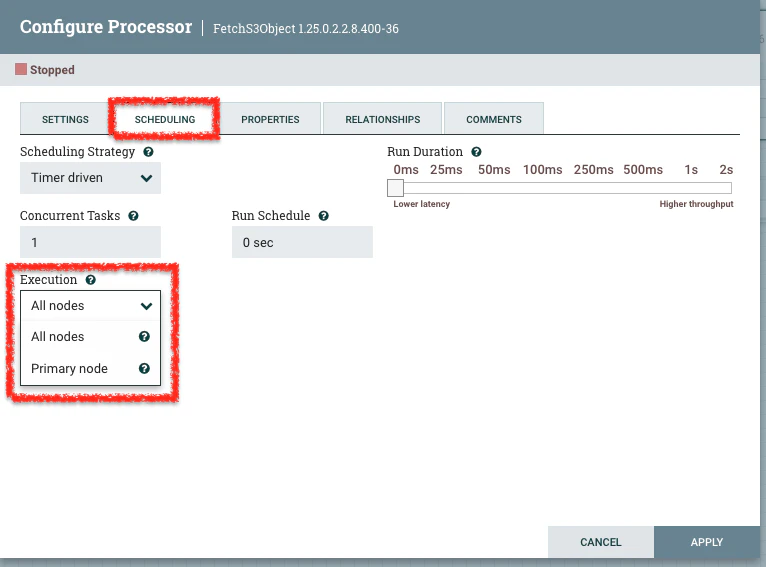
処理に利用できるサーバーが複数あったとしても、プロセッサーの処理の性質によっては、あえて単一ノードでの実行を選んだ方がいい場合もあります。
以下に、それぞれのパターンに適するパターンを記載します。
単一ノード実行(Primary node)に適するパターン
たとえば1分ごと、1時間ごとなどにスケジューリングした処理を「正確に1回」実行したいというニーズがある場合、その処理を行うプロセッサーは単一ノードで実行する必要があります。
「正確に1回」のニーズが出てきやすいパターンには、例えば以下があります。
フローの最初の処理
フローの最初には、Listen系のプロセッサーや、データベースへのクエリ発行などのプロセッサーが来ることがよくあります。
こうしたプロセッサーをAll nodes で動かしてしまうと、スケジューリングした処理がすべてのノードで動くことになり想定外の挙動につながる場合があります。
特に、フローの先頭に List 系が来る場合は、単一ノードで実施することが必須になります。
List は、たとえば ListFile なら、特定ディレクトリに入っているファイルの一覧を取得する処理になりますが、「どこまで読み込んだか」の情報をノードごとに持ちます。
そのため、ListFileを複数のノードで行ってしまうと、ノードごとに自分がまだ読み込んでいないファイルを一覧にしてしまい、結果として、ノードの数だけ重複してファイルを取得することになってしまいます。
こうした状況を避け、「先頭の処理はひとつのノードに集約したい」というニーズがある場合には、処理の先頭のプロセッサーは単一ノードで実行するのが適切です。
フローの最後のWrite処理
同様に、フローの最後の Write 処理も、無駄なI/Oを避けるなどの目的でひとつのプロセッサーに集約したい場合があります。
こうしたケースでも、単一ノードでの実行が役に立ちます。
分散実行(All nodes)
上記のように「正確に1回」という要件がなく、複数ノードに負荷を分散したい場合は、All nodes に設定し分散実行するのが適切です。

先ほど、フローの先頭の List 系の処理は単一ノードで実行する必要があると書きましたが、 List のあとには Fetch(一覧にしたファイル等を実際に取得する処理)が来ることがほとんどです。
この Fetch の処理は、複数のノードに分散することで並列性を高め、処理を高速化することができます。
② コネクタの設計
各プロセッサーをどのように負荷分散するかが決まったら、次はコネクタで、先行のプロセッサーの処理結果を後続のプロセッサーにどのように受け渡すかを考えます。
コネクタによる負荷分散には、以下の4つの選択肢があります。
- Do not load balance(ロードバランスしない)[デフォルト]
- Partition by attribute(属性によるパーティション)
- Round robin(ラウンドロビン)
- Single node(シングルノード)
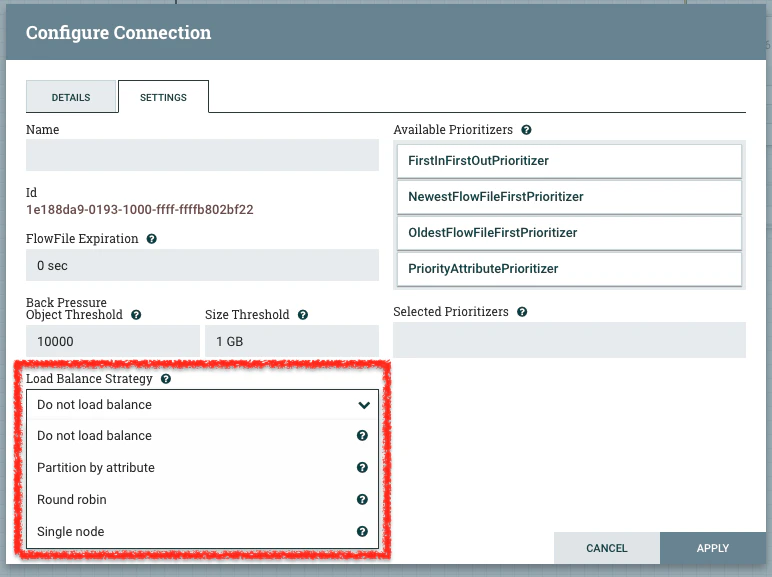
これらがどのような負荷分散を行うのかと、実際にどのような場合に利用するのかを以下に記載します。
Do not load balance(ロードバランスしない)
NiFi ユーザーガイド の定義
クラスター内のノード間で FlowFile のロードバランスを行いません。これがデフォルト設定です。
実際いつ使う?
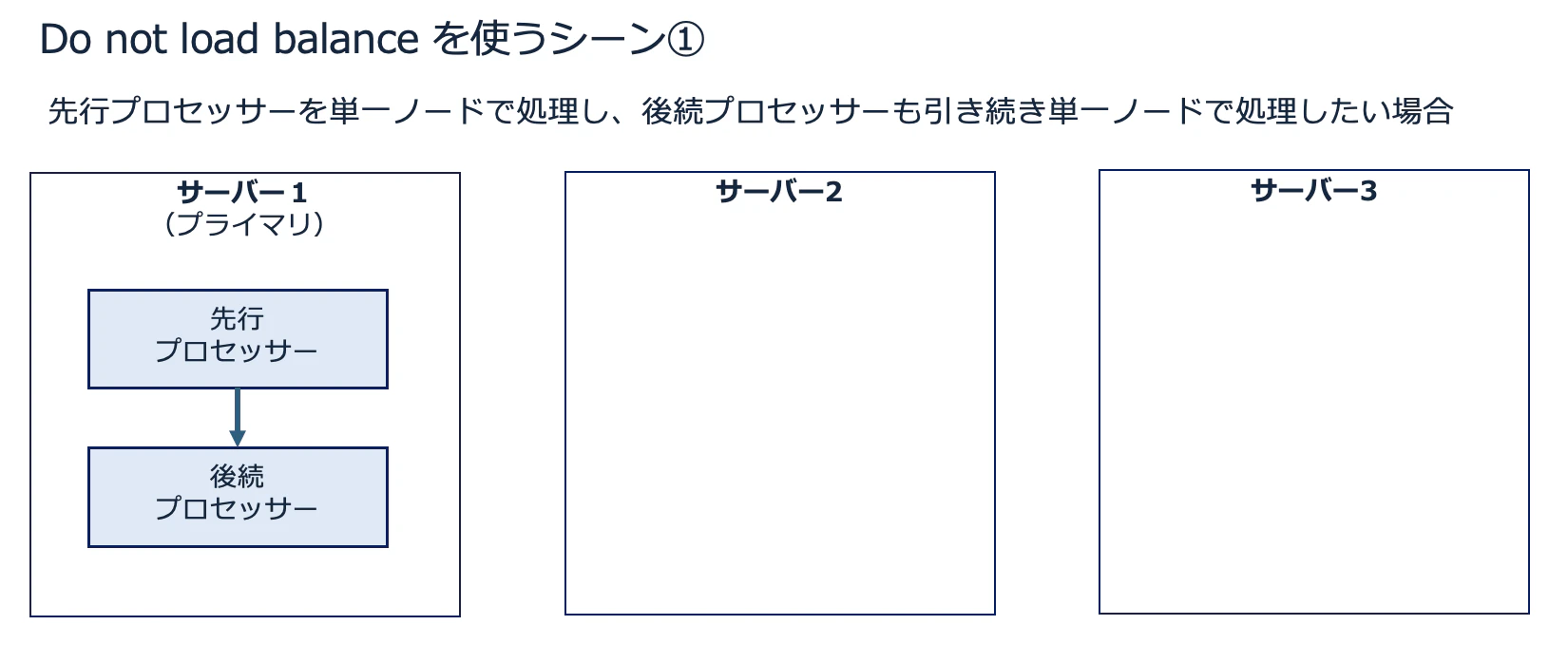
Do not load balance を利用するシーンは、主に以下の2つです。
ひとつは先行プロセッサーを単一ノードで処理し、後続プロセッサーも引き続き単一ノードで処理したい場合です。
もうひとつは、先行プロセッサーを全ノードで処理しており、後続プロセッサーも全ノードで処理する際に、後続を引き続き同じサーバーで処理したい場合です。
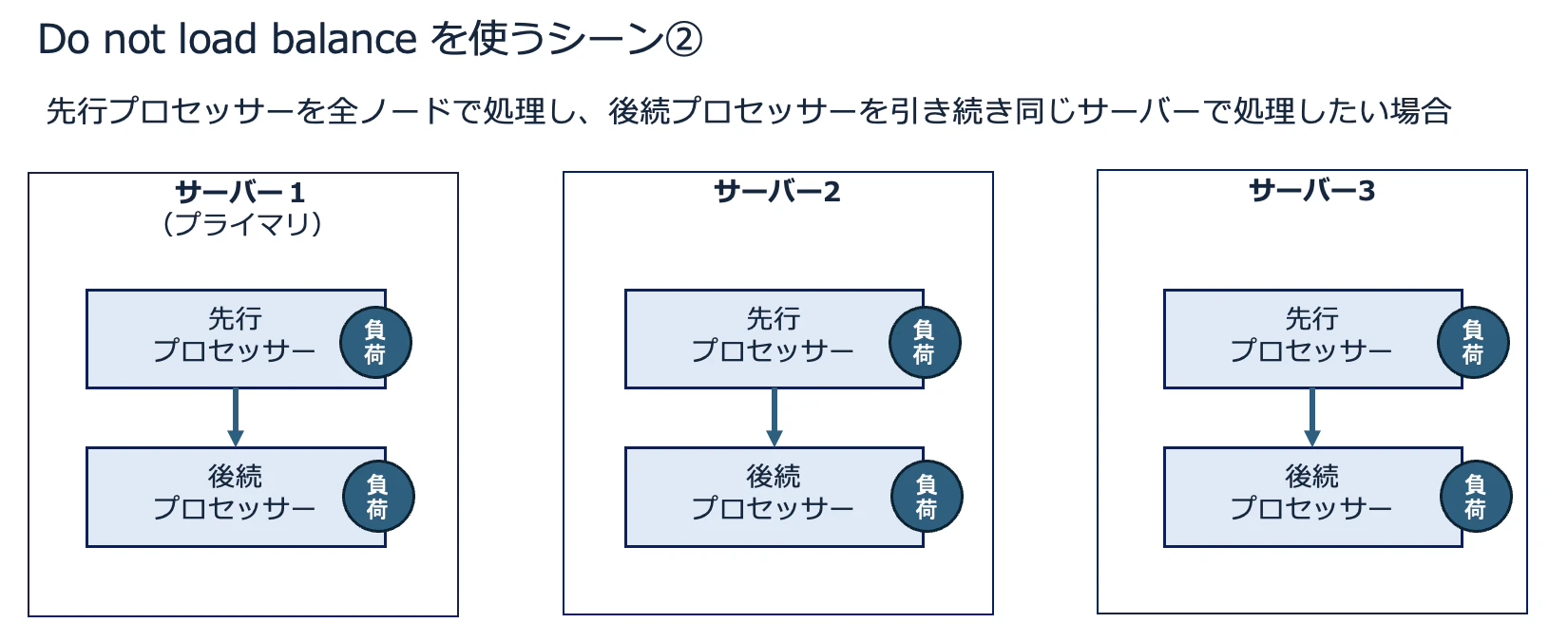
先行のプロセッサーが同程度の負荷で動いている状況であれば、無駄なネットワーク帯域の消費を防ぐために、この方法をとるのがベストプラクティスです。
Round robin(ラウンドロビン)
NiFi ユーザーガイド の定義
FlowFile をクラスター内の各ノードに順番に振り分けます。ノードが切断または通信不能になった場合、そのノード用にキューイングされていたデータは自動的に他のノードへ再配布されます。また、特定のノードが他のノードほど速くデータを受信できない場合、クラスター全体のデータ配信スループットを最大化するために、そのノードへの配信が一時的にスキップされることがあります。
実際いつ使う?
ラウンドロビンによる負荷分散を利用するシーンとしては、以下が考えられます。
ひとつは先行のプロセッサーを単一ノードで実行しており、後続のプロセッサーを全ノードに分散したい場合です。
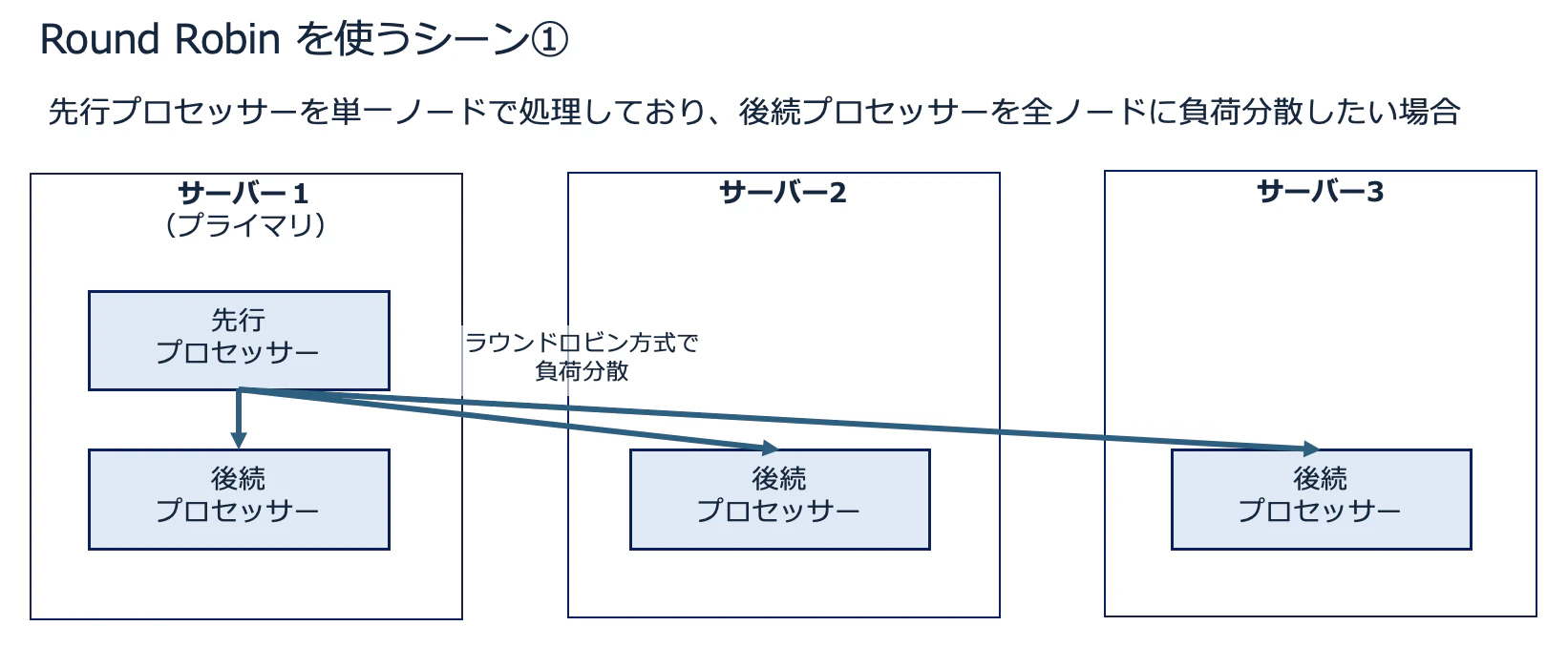
たとえばフローの最初の List を単一ノードで処理し、その結果を全ノードに分散して後続の Fetch を処理する、といった場合に、このパターンは非常によく使われます。
もうひとつは、先行プロセッサーを全ノードで処理しており、後続プロセッサーも全ノードで処理する必要があるが、特定のノードに偏った負荷を改めて分散したい場合です。
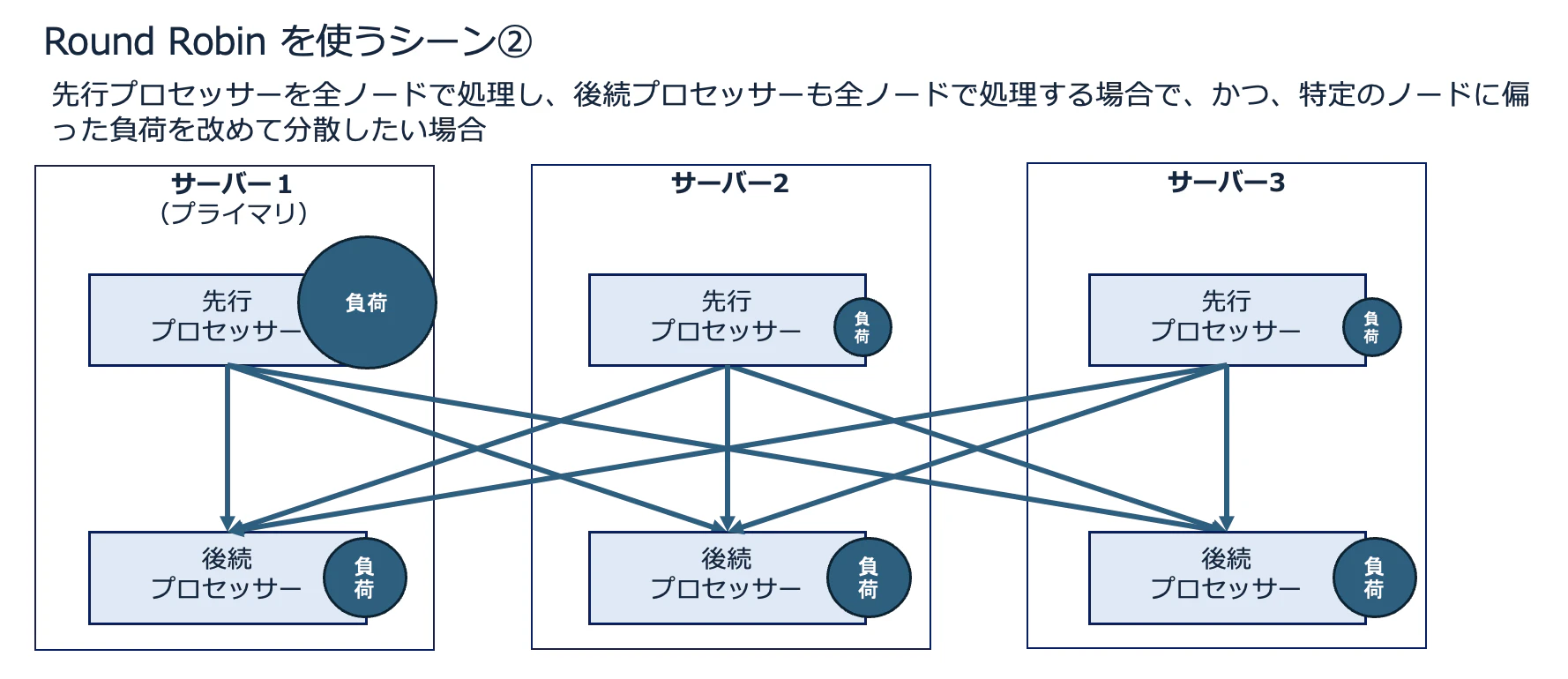
このパターンの使いどころは、よく考えるべきです。
上記の図のように、処理の途中で特定のプロセッサーに負荷が偏ってしまう可能性がある場合(例:引き当てたデータの内容によって、処理の負荷が大きく変わる場合など)はよいですが、逆に、負荷の調整の必要がないのにやたらと Round Robin による分散をかけてしまうと、無駄なネットワークまたぎが頻発し、帯域を消耗してしまいます。
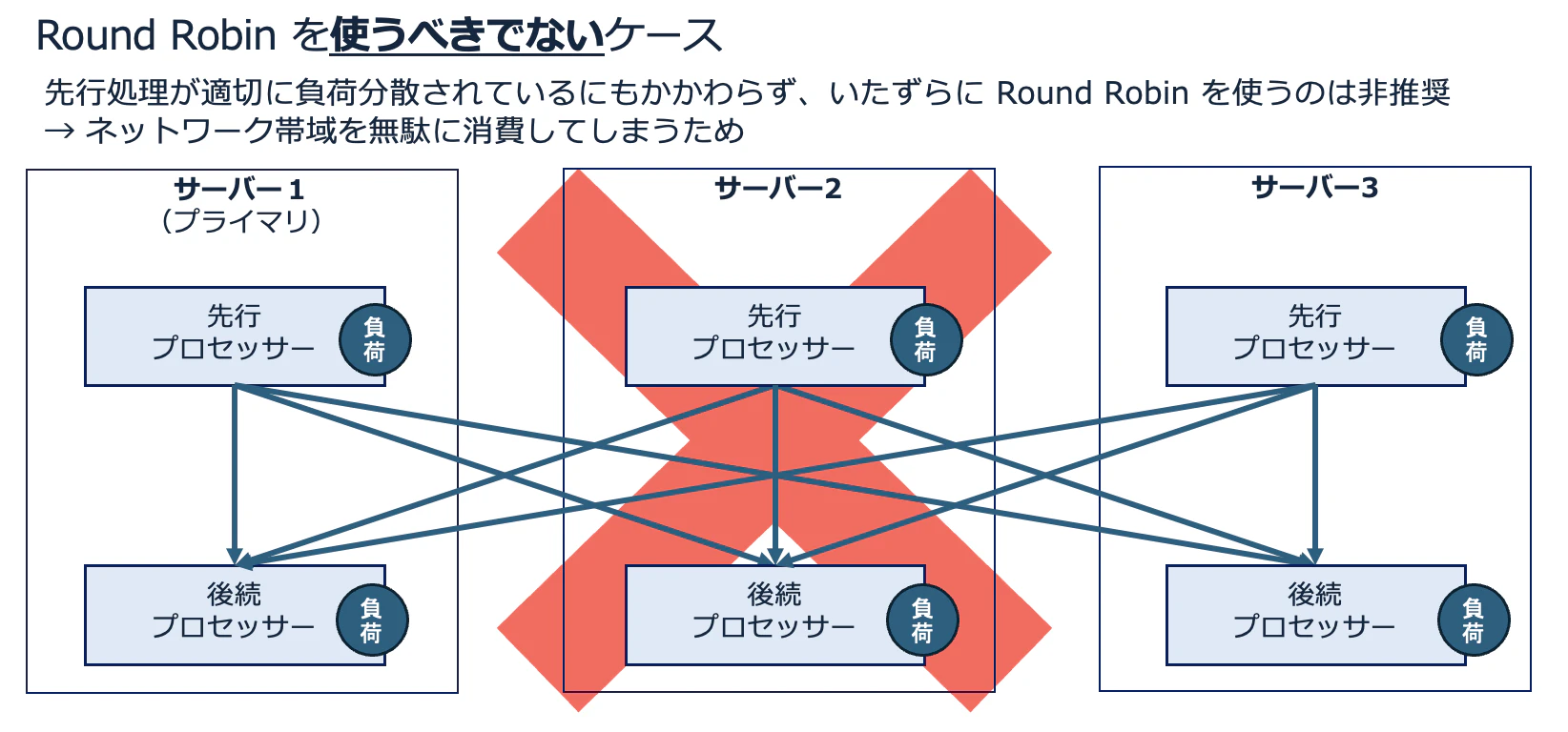
「全ノード→全ノード」の負荷分散は、本番処理を想定した性能テストなどをきちんと実施した上で、ここぞというところで使うようにしましょう。
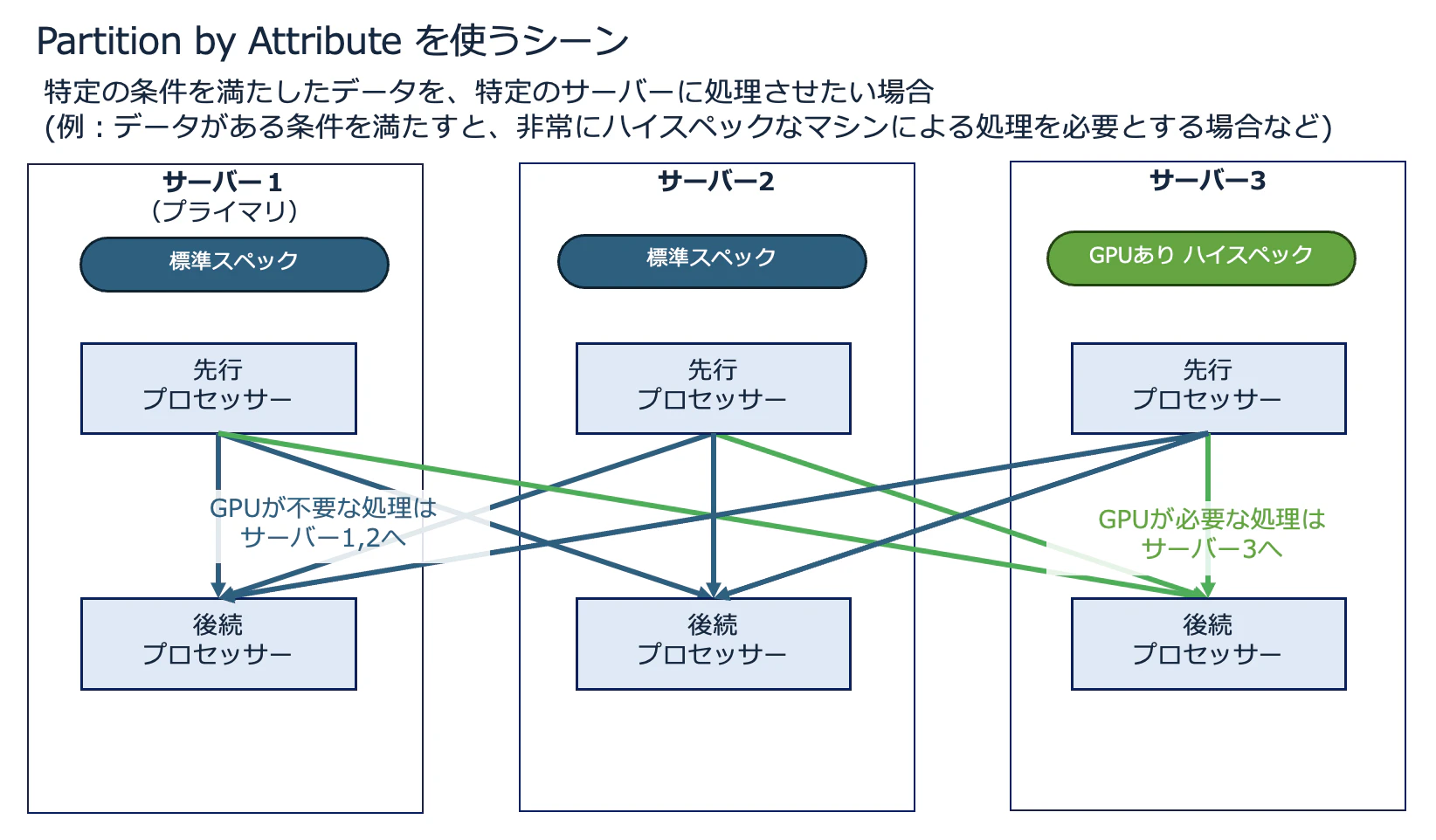
Partition by attribute(属性によるパーティション)
NiFi ユーザーガイド の定義
ユーザーが指定した FlowFile 属性の値に基づいて、どのノードに送信するかを決定します。同じ属性値を持つすべての FlowFile は、クラスター内の同じノードに送信されます。 送信先ノードが切断されたり通信不能になった場合、データは他のノードへフェイルオーバーされず、そのノードが復旧するまでキューに蓄積されます。また、ノードの増減により再配置が必要な場合は、全データを再配布せずに済むよう「コンシステント・ハッシュ法」が適用されます。
実際いつ使う?
単純なラウンドロビンによる負荷分散ではなく、データの内容などによってあらかじめ振り分けを行いたい場合には、振り分けの条件となる情報を Attribute に持たせた上で、この Partition by attribute を利用することになります。
例えば、データの条件によって負荷が高くなるとわかっているデータについては、あらかじめ Attribute にフラグを持たせておき、ハイスペックな特定のサーバーに送って処理をする、といった場合にこの方法が役に立ちます。
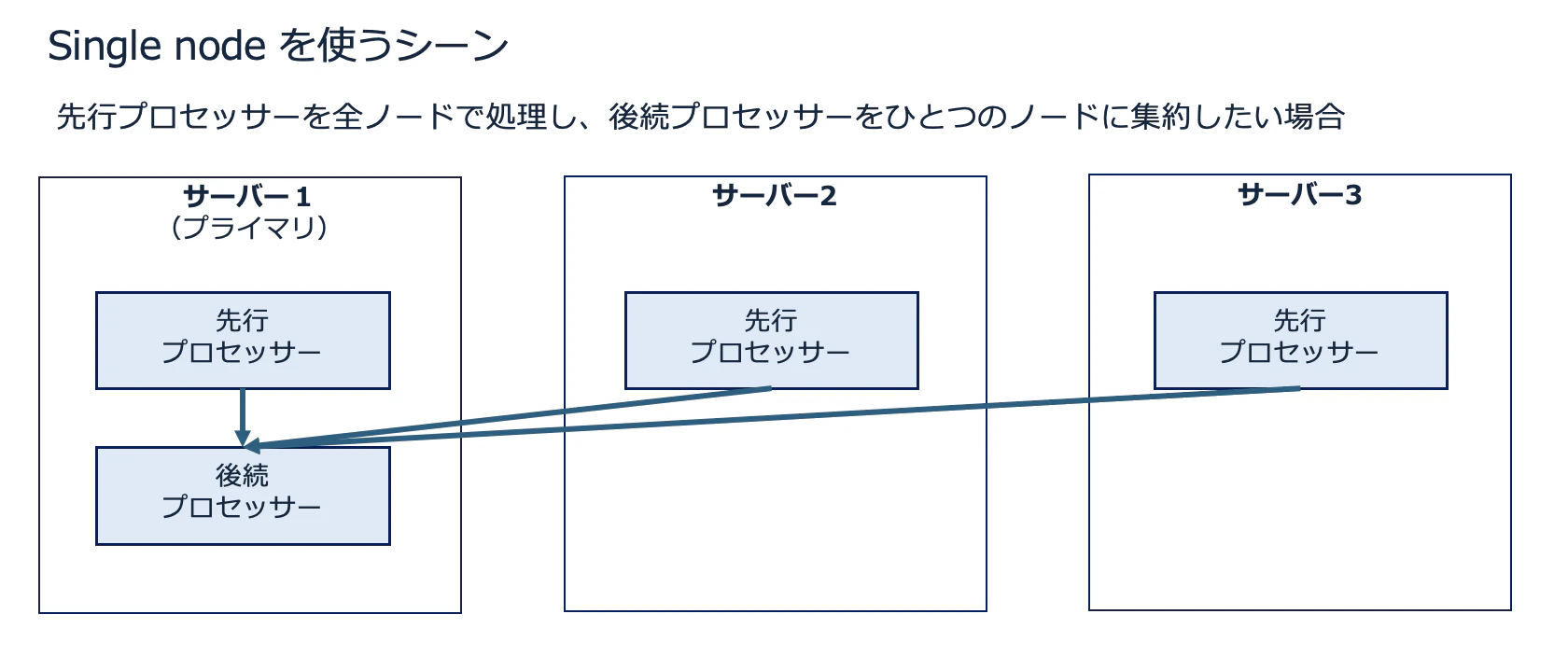
Single node(シングルノード)
NiFi ユーザーガイド の定義
すべての FlowFile をクラスター内の特定の1つのノードに送信します。送信先となるノードを任意に設定することはできません。そのノードが切断または通信不能になった場合、キューにあるデータはノードが復旧するまで保持(待機)されます。
実際いつ使う?
以下のように、先行プロセッサーを全ノードで処理しており、後続のプロセッサーをひとつのサーバーに集約したい場合に利用します。
まとめ
以上、NiFi におけるロードバランシングの考え方と設定について、図解を交えながらまとめました。
みなさまの NiFi 活用の参考になれば幸いです。