はじめに
IQ Botで明細の取得をしてみると、行の抽出が意図した場所で止まらず、余計な行まで拾ってきてしまうケースがあります。

だめじゃん! と思うかもしれませんが、明細の構造を自動で取得する、準定型対応OCRの宿命ともいえる事象です。
(参考:非定型OCRを正しく知って、上手に付き合おう ~定型OCRにはない、非定型OCR固有の課題~)
そしてIQ Botの場合、このケースにはちゃんと対応方法があります。
この記事では、そんな場合の対処方法を説明します。
基本:ストッパーとなる文字列を指定する方法
基本となるのは、ストッパーとなる文字列を指定する方法です。
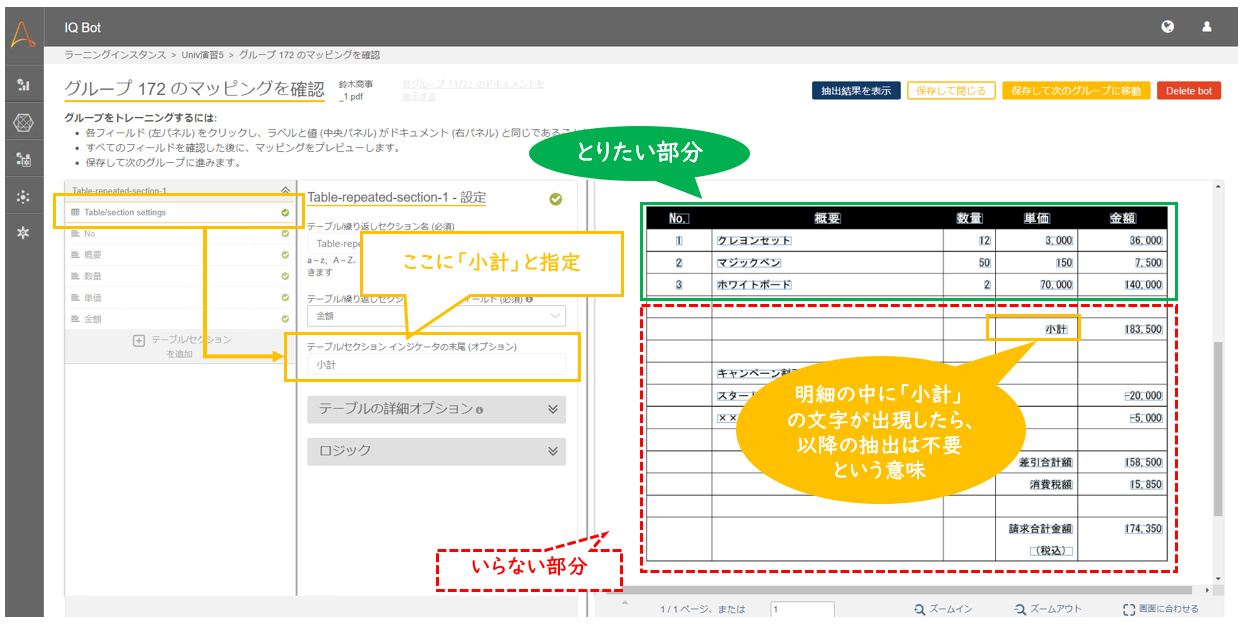
上記の帳票を見てみると、「小計」という文字が出現する前後で、明細の必要な部分と不要な部分が分かれています。
そこで、「Table/section settings」配下の「テーブル/セクション インジケータの末尾」に「小計」と指定します。
これは、明細の中に「小計」という文字列が現れたら、以降の抽出は不要ですよ、という指定になります。
文字列指定でテーブルを止める際の注意点
上記で説明した「テーブル/セクション インジケータの末尾」に指定できるのは、固定の文字列のみです。
正規表現などで複数のパターンを指定することはできません。
したがって、この方法でテーブルの抽出を止められるのは、以下の条件をすべて満たす場合に限られます。
文字列指定でテーブル抽出を止められる条件
a.テーブル(明細)の抽出したい部分が終わった直後に、いつも必ず決まった文字列が出現する
上記の例でいえば、抽出したいテーブルの直後にいつも必ず「小計」という文字列が出現する必要があります。
「小計」の他にも「消費税」や「送料」など、ストッパーとなる文字列に複数の可能性がある場合などは、次に説明するカスタムロジックで対応する必要があります。
b.上記a.の文字を、OCRが安定して読み取ることができる(誤読の可能性が低い)
例えば帳票上の「小計」をOCRが誤って「小言十」と読んでしまった場合、「小言十」はストッパーとして定義されていないのでテーブルの抽出を止めることができません。
したがって、OCRが安定して読み取れる項目をストッパーとして選ぶ必要があります。
「計」を「言十」として読むケースはOCRでは時々見られるのですが、このような可能性があらかじめ予測できる場合も、次に説明するカスタムロジックで対応する必要があります。
c.上記a.の文字が必要な明細の途中で出現しない
上記の例では「小計」をストッパーとして使っていますが、もしも抽出したい明細の途中に「小計」という文字列が現れてしまうと、IQ Botはそこで抽出をやめてしまいます。
文字列指定でテーブルを止める方法のまとめ
文字列指定でテーブルを止める方法は、最も簡単なやりかたです。
ですが、上に挙げた注意点などを鑑みると、文字列指定でテーブル抽出を止める方法が適用できるケースが限られているのも事実です。
文字列指定では対応できない条件でテーブル抽出を止めたい場合は、カスタムロジックを使って対応する必要があります。
応用:カスタムロジックを使う
カスタムロジックを使用して抽出行を止める方法は、明細の構造により千差万別です。
帳票自体のデータの構造に多種多様なパターンが想定されるため、「このロジックを使えば、あらゆるパターンに対応できます!」という万能なロジックは残念ながらありません。
ここではあくまでも参考として、最も基本的なパターンのロジックを載せておきます。
このロジックでは、以下のような明細を扱います。
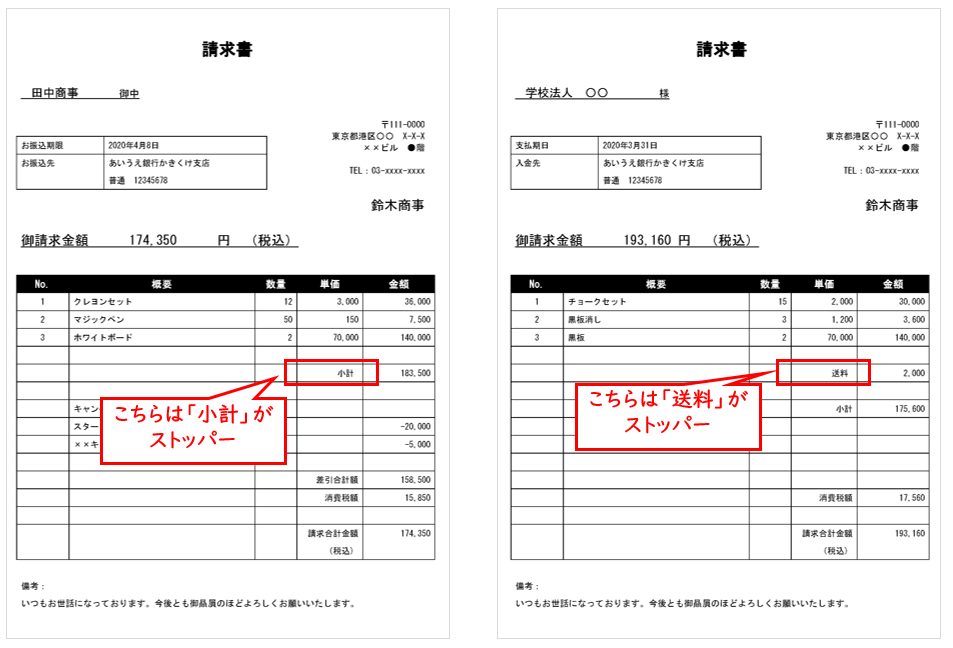
ストッパーの候補は「小計」と「送料」があって、いずれも単価欄に出現するというパターンです。
ロジック例
# 値を保存する変数: table_values
import pandas as pd
df = pd.DataFrame(table_values)
# 削除対象の文字列が出現する列名
# (IQ Botの列名に合わせる)
col = "単価"
# 「この文字列が出現したら、それ以降の行を削除」という文字列を定義
flagList = ("小計","送料")
# 抽出対象かどうかを設定するフラグ
isTaisho = True
# 明細行を上から順番にループする
for i in range(len(df)):
#フラグ判定(単価欄の内容(df.at[str(i),col])がflagListの要素(j)と一致したらフラグを立てる)
for j in flagList:
if df.at[str(i),col] == j:
isTaisho = False
#フラグがFalseなら、対象列に固有の文字列を代入
if isTaisho == False:
df.at[str(i),col] = "この行は削除対象です"
# 固有の文字列を代入した列を削除する
df = df[df[col] != "この行は削除対象です"]
# 表の操作をするときに必ず入れるコード(最後)
table_values = df.to_dict()
簡単に補足
解説はほぼコードの中のコメントに書いていますが、少しだけ補足しておきます。
(初心者向けです。コードの意味がわかった人は読み飛ばして大丈夫です。)
フラグ判定と全体の構造
このロジックの最大のポイントは、フラグ判定の部分です。
ループの手前でフラグにTrueを立てておき、条件に該当したらFalseにします。
この条件を定義するロジックを対象の帳票に合わせて書き換えることで、それなりに色々な帳票に対応できるようになります。
ループの中でFalse→Trueに戻す箇所はないため、一度Falseになったらそれ以降はずっとFalseです。
この構造により、「ひとたび条件を満たす行が見つかったら、以降の明細は不要ですよ」という処理ができあがります。
不要な行の削除
また、不要な行の削除の削除のしかたもちょっと特徴的です。
これは IQ Bot というより、pandasに特有の実装方法のようですが、「フラグが立っていたら、それ以降の行を1行1行消していく」という処理構造にはなっていません。
かわりに、
- フラグが立っていたら、削除対象だとわかる固有の値を特定の列に入れる
- 特定の列に固有の値が入っている行を最後にまとめて削除する
という2段階の構造をとります。
今回のケースでは、単価欄に「"この行は削除対象です"」という固有の値を入れて、最後にそれを条件に削除しています。
固有の値は、その値を根拠に削除対象の判別がつけば何でも良いです。
なお、不要な行の削除については以下の記事に若干詳しく書きましたので、あわせて参照してみてください。
https://qiita.com/IQ_Bocchi/items/e714b15225f425a582c5
このケースは、先ほどから何度も言っている「固有の値」を特定の列に入れることで「不要な行」を意図的に作り出し、最後に除外しているという仕組みです。
以上!
今回の記事は以上です。
ご不明な点や今後の記事のリクエストなどあれば、お気軽にコメントください。
TwitterでからんでいただいてもOKです。
それでは!