はじめに
こんにちは。
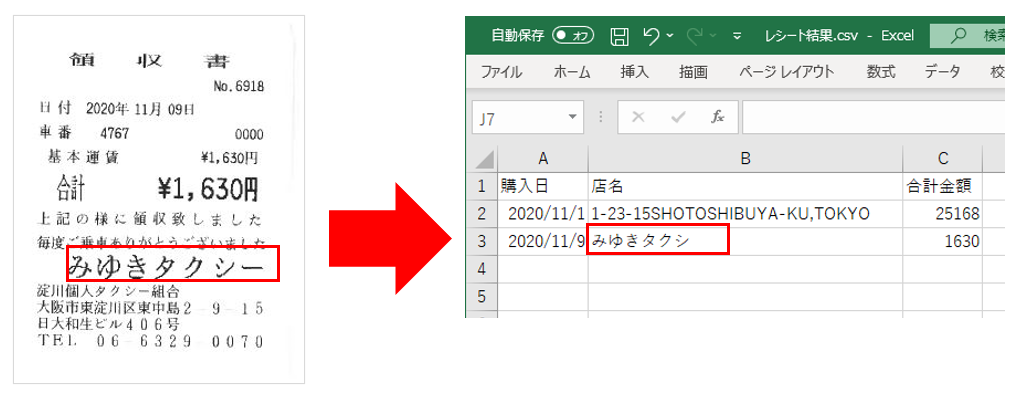
昨日(2021年2月26日)実施したRPA Community 主催イベント「【初心者歓迎】女子部♡RPAツール「Automation Anywhere」からLINE OCRを使ってみるハンズオン!」では、以下のようなことができるBotを作りました。

レシートの画像がCSVに書き出せた瞬間は、「すごい!」「便利!!」という声が上がります。
が、すごく細かいことを言うと、上記の読み取り結果には2か所の「誤読」があるのにお気づきでしょうか。
一般的に「誤読」といえば、「OCRが文字の認識をまちがえた」というふうにとらえられがちですが、非定型を扱うOCRの場合、事情はもう少し複雑です。
この記事では、これらの誤読を細かく見ていきながら、定型OCRにはない、非定型OCR固有の課題 について説明していきます。
非定型OCRを上手に活用するためにも、まずは正しく理解を深めていきましょう。
誤読① 「みゆきタクシー」が「みゆきタクシ」に
誤読の一つ目は、「みゆきタクシー」が「みゆきタクシ」となり、伸ばし棒が読めていない点です。
単純な誤読……じゃなかったorz
一件、これは単純な誤読(伸ばし棒の読み漏れ)……のようにも見えますが、よくよく見るとそうではないことがわかります。
これがなぜ単純な誤読ではないのかについて、ちょっと丁寧に説明してみます。
Generalモードでの読み取り結果
Clova OCRのページで、この画像を「General」のモードで読むと、ちゃんと「みゆきタクシー」と読めています。
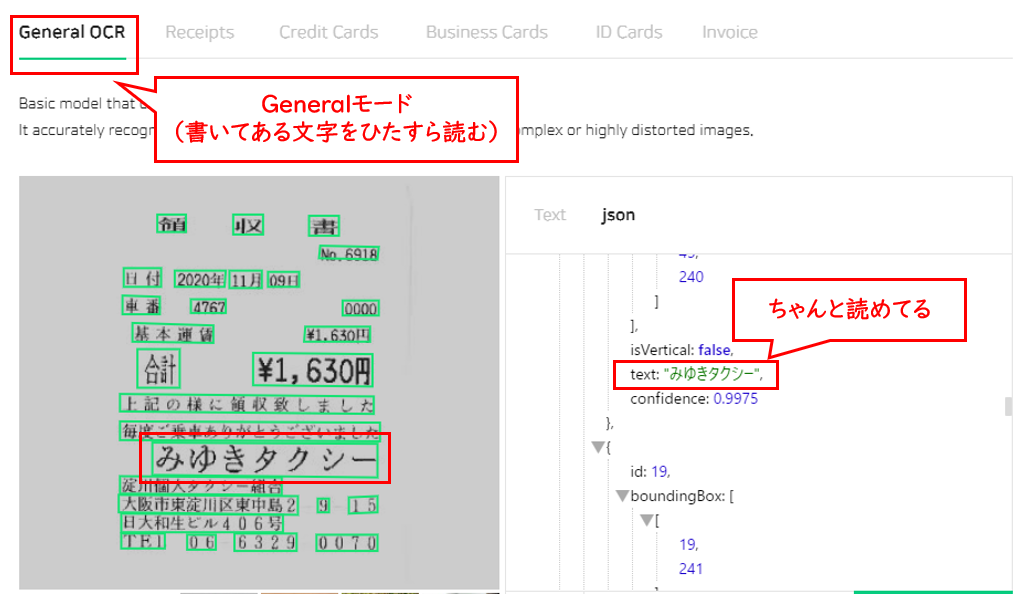
上記の図で、緑の枠で囲まれた場所は、OCRが文字として認識できた場所です。
(IQ Bot でいうSIRですね。SIRがわからない方はこちら(https://qiita.com/IQ_Bocchi/items/1e0a36fb69393106d025 )参照)
GeneralモードとReceiptモードの違い
次に、上記の画像をReceiptモードで読んだときの話をしたいのですが……
読み取り結果の話に直接入る前に、GeneralモードとReceiptモードの大きな違いをまず押さえておきましょう。
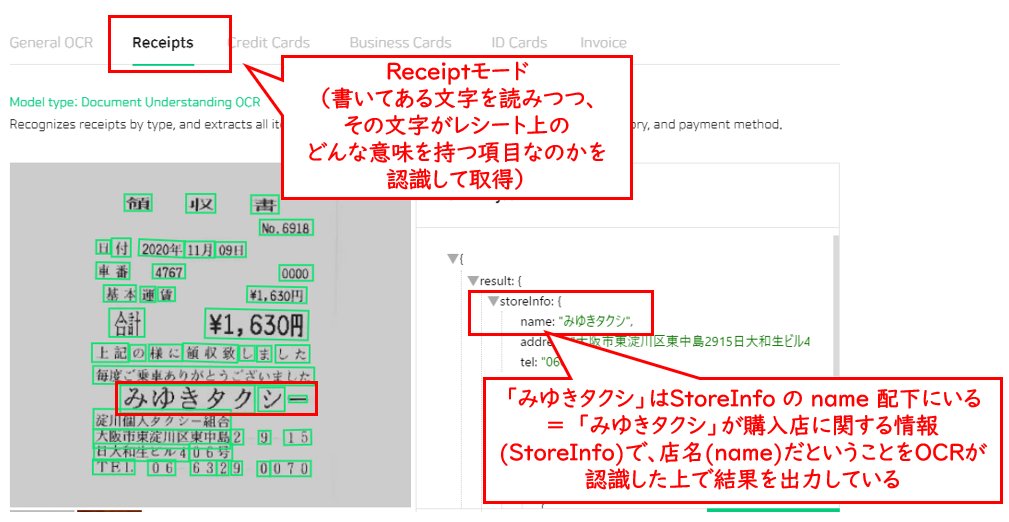
Generalモードが「書いてある文字をとにかく読む」というモードなのに対し、Receiptモードでは書いてある文字を読みつつ、その文字がレシート上のどんな意味を持つ項目なのかを認識して取得します。
Receiptモードにおける「みゆきタクシー」の伸ばし棒
この点を押さえた上で、「みゆきタクシー」の読み取り結果をより注意深く見ていくと、伸ばし棒は緑の枠で囲まれている=文字としてはちゃんと認識されている形跡があるのです。
「文字として認識できている」というのがどういうことかというと、その少し下にある住所や店名のハイフンと比べてみるとよくわかります。

住所や店名のハイフンは、緑の枠で囲まれていませんね。
つまり、これらのハイフンは「OCRが文字として認識しなかった」ということです。
文字として認識しなかったということは、当然文字のデータとして出力されることはありません。
ですが、「みゆきタクシー」の伸ばし棒はちょっと事情が違います。
繰り返しになりますが、「みゆきタクシー」の伸ばし棒は緑の枠で囲まれている=文字としてはちゃんと認識できているのです。
ただ、読んだ文字を「店名」「住所」「アドレス」といったカテゴリ別に拾っていく過程で、店名として拾われなかったという事情のようです。
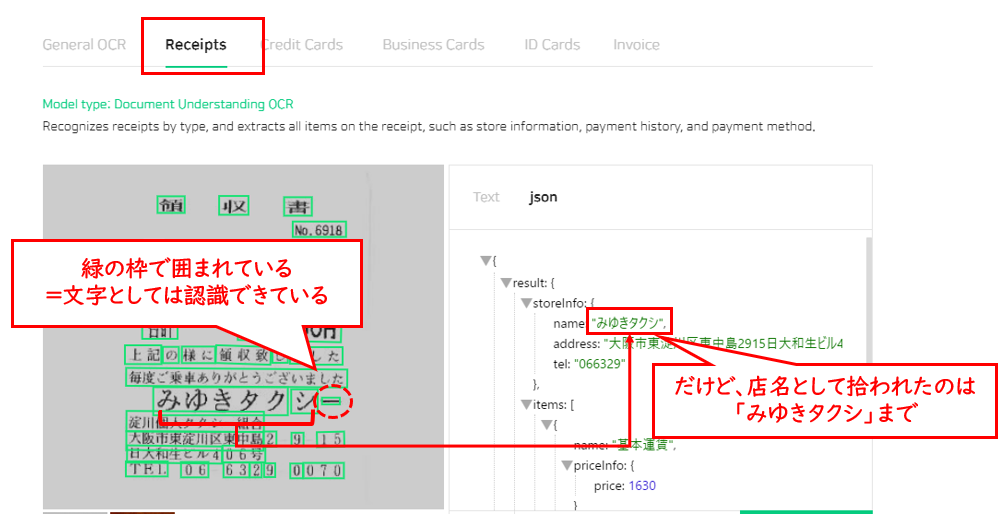
伸ばし棒はなぜ捨てられたのか?
伸ばし棒はなぜ捨てられてしまったのか? という疑問をきっとみなさん持つと思いますが、これはすみません、私にもわかりません。
というのも、これに明確に回答できるのは、LINEの内部でOCRのアルゴリズムを開発しているエンジニアだけだからです。
ただ、「なぜ」がわかったところで、伸ばし棒が必ず拾われるように調整することは、私たちユーザーの力ではできません。
また、アルゴリズムを開発しているエンジニアが頑張れば、こうした誤読や拾い漏れをより少なくすることはできるかもしれませんが、それらがゼロになることは理論上ありえません。
ユーザーとしては、「こういう誤読があり得る」という点を認識した上で、「それらとどう付き合うか」を考えていく必要があります。
誤読との付き合い方については、また別途記事を書く予定です。
付き合い方の前にもう少し、誤読についての理解を深めておきましょう。
誤読② レストランの店名は店名じゃなかった!
誤読の2つ目ですが、こちらも店名に関する誤読です。
CSVの1行目に出力された「店名」は、実は店名じゃなかったことにお気づきでしょうか?
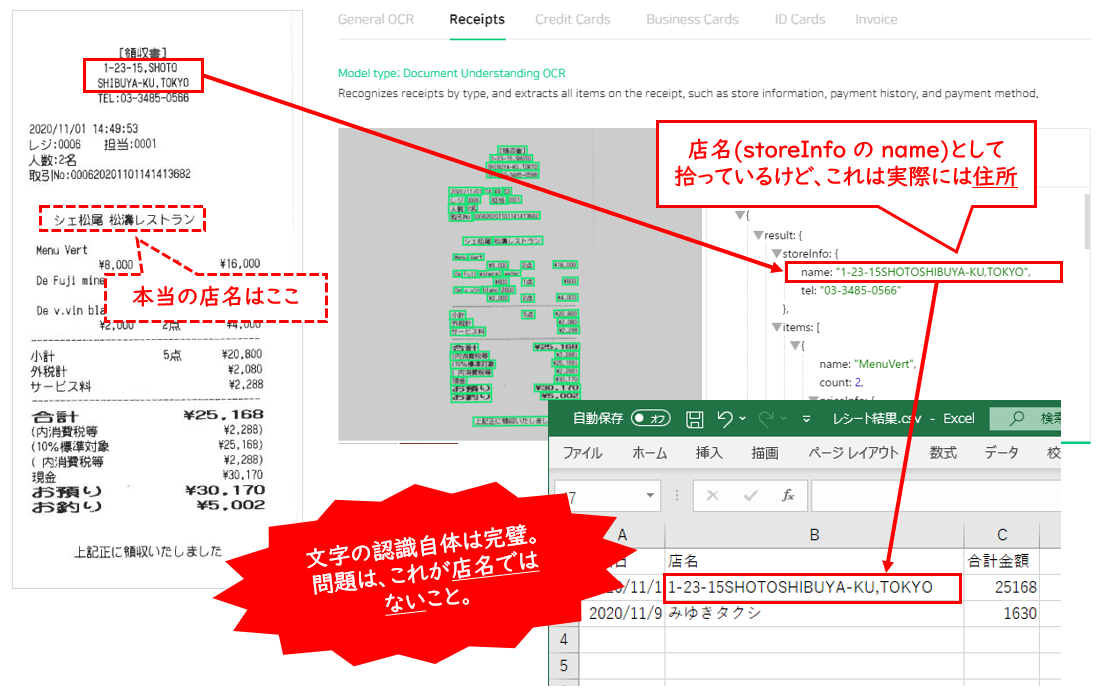
これ、文字としては完璧に拾っているので、いわゆる「文字の認識精度」の観点で言えば100%なんですが、データとして正しいか誤りかでいえば誤り、つまり誤読です。
以下の記事に「場所の特定精度」という話が出ていますが、これがまさにそれです。
【外部リンク】失敗から学ぶAI-OCR導入の注意点~導入成功のためのポイント~
今回の誤読は①②とも、非定型OCRに固有の誤読
誤読を詳しく見ていった結果、今回の誤読はいずれも非定型OCRに固有の誤読であることがわかりました。
勘がいい人はもうおわかりかもしれませんが、定型帳票ではなぜ、こうした問題が起こらないのでしょうか?
場所特定の問題が定型OCRでは起こらない理由
これは実は「めんどりはなぜメスなのか」という問いに似ているのですが、定型OCRで扱えるのは固定帳票=項目の場所が決まっている帳票だからです。
固定のフォーマットに対して、どの項目がどこにあるかを「場所」で定義したテンプレートを利用者が作り、その「場所」から項目を拾ってくるというやりかたなので、「場所の特定」などということがそもそも問題になりえないのです。

非定型OCRの場合
それに対して、非定型OCRが扱うのはフォーマットがバラバラの帳票=項目の場所が決まっていない帳票たちです。
そうなると、固定帳票のように「あらかじめ定められたテンプレートで特定した場所から文字を読んでくる」という方法では対応できません。
なので非定型に対応しているOCRは、まず画像全体の文字をすべて読み取った上で、「どの項目がどこに書かれているかを探す」という部分まで自動で行います。
その「探し方」をどうするかで各OCRの特色が出てくるのですが、いずれにしても、定型OCRにはない「探す」という仕事が非定型OCRではマストになるため、場所の特定精度が問題になってくるというわけです。

まとめ ~正しく知って、上手に付き合おう~
以上、Clova OCRによるレシートの読み取りを例に、定型OCRでは起こり得ない、非定型OCRに固有の「誤読」について説明してきました。
非定型OCRとの正しい付き合い方を知るためにも、まずは非定型OCRの特性を正しく理解することが重要です。
こうした特性をふまえて「どう付き合うか」というTipsは、また別の機会に記事を書きますので、楽しみに待っていてください。
それでは!