概要
B+木はDBやファイルシステムなどで使われるデータ構造です。
これがどのような課題を、どう解決するものなのかをDBの例で説明します。
なお本記事で説明したものすべてを実装したのが以下のリポジトリになります。
結論
- ソート/挿入時にメモリコピーが走る問題の回避
- レコード挿入とキーでの索引が速くなる
この記事で考えるDB
DBといえば一般的に、複数のデータ属性(カラム)をひとまとめにしたもの(レコード)が何件もある、というような状況を想定します。
名簿でいえば、1人ひとりのデータがレコード、「年齢」「性別」のようなラベルをカラムと言います。1エクセルのようなイメージです。
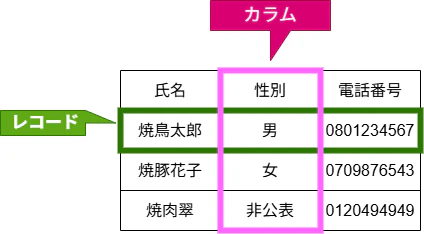
B木を使わない、素朴な実装①:テーブル
以下、書籍DBを例に考えます。「ISBN」「タイトル」「著者」「出版年」カラムを持つとします。
依頼されたデータを高速に取り出すためのカラムをキーといいます。このカラムは重複があってはいけません。ですので今回だと著者や出版年はキーにできません。
キーのないDBも普通に考えられるのですが、とりあえずISBNをキーにすることにします。(実装は簡単のため、ISBNの上6桁をキーにしました。だいぶ危ないですが…。)
まず思いつくのが、普通に配列で実装することです。
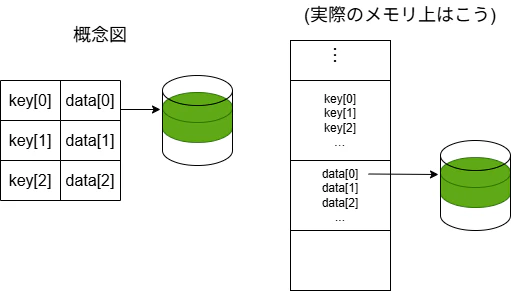
実装
リポジトリのindex_table.cから引用します。void table_insert(
Table *t,
const char *title,
const char *author,
int isbn_topsix,
int isbn_bottomseven,
int year)
{
if (t->key_count >= 1024)
return;
int i = t->key_count;
Record *record = pool_alloc(&t->pool);
if (!record)
return;
t->keys[i] = isbn_topsix;
strncpy(record->Title, title, TITLE_MAX);
strncpy(record->Author, author, AUTHOR_MAX);
record->ISBN_bottomseven = isbn_bottomseven;
record->Year = year;
t->data[i] = record;
t->key_count++;
}
char *table_search(Table *t, int key)
{
for (int i = 0; i < t->key_count; i++)
if (t->keys[i] == key)
return t->data[i]->Title;
return NULL;
}
しかしこれにはデメリットがあります。
キーで探すのが遅い
キーで探そうとすると、レコードの並びは無秩序(insertした順)なので全なめすることになります。
最初の方に作ったレコードにばかりアクセスするのならいいのですが、最近挿入したレコードにアクセスする際遅くなります。
素直な実装②ソート+二分探索
キーで探すのが遅いという課題を解決しようと考えて、自然に思いつくのはソートです。
ISBNは13桁の整数なので、ソートできます。ソートされていれば、挿入と検索のときに二分探索ができます。
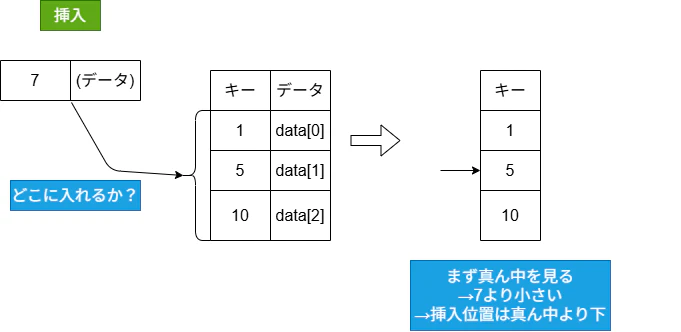
実装
#include "headers/table_index.h"
#include "headers/Pool.h"
#include <stdio.h>
#include <string.h>
#include <memory.h>
// found : flag=1, return index
// not found : *flag=0, return index to insert
int binary_search(Table *t, int key, int *flag)
{
int left = 0;
int right = t->key_count;
while (left < right)
{
size_t mid = (left + right) / 2;
if (t->keys[mid] == key)
{
*flag = 1;
return (int)mid;
}
else if (t->keys[mid] < key)
{
left = mid + 1;
}
else
{
right = mid;
}
}
*flag = 0;
return left;
}
void table_init(Table *t)
{
t->key_count = 0;
pool_init(&t->pool);
}
void table_insert(
Table *t,
const char *title,
const char *author,
int isbn_topsix,
int isbn_bottomseven,
int year)
{
if (t->key_count >= 1024)
return;
int i, flag;
i = binary_search(t, isbn_topsix, &flag);
if (flag == 1)
return;
memcpy(&(t->keys[i + 1]), &(t->keys[i]), (t->key_count - i) * sizeof(int));
memcpy(&(t->data[i + 1]), &(t->data[i]), (t->key_count - i) * sizeof(Record *));
t->keys[i] = isbn_topsix;
Record *record = pool_alloc(&t->pool);
if (!record)
return;
strncpy(record->Title, title, TITLE_MAX);
strncpy(record->Author, author, AUTHOR_MAX);
record->ISBN_bottomseven = isbn_bottomseven;
record->Year = year;
t->data[i] = record;
t->key_count++;
}
char *table_search(Table *t, int key)
{
int flag;
int i = binary_search(t, key, &flag);
if (flag)
return t->data[i]->Title;
else
return NULL;
}
しかしこれはこれでデメリットがあります。
追加が遅い
①の実装では、レコードを追加するには末尾に追加すればいいだけでした。
しかし②ではメモリコピーが走ります。先頭に挿入する際が最悪ケースで、レコード数*sizeof(int)バイトのコピーが走ります。これは遅いです。
ただこれも、ユーザーが暇している間にソートを走らせる、など工夫すれば勝機はありそうです。
(本当はB木の前に二分探索木を紹介するべきなのですが、できませんでした)
B木による実装
実装
一部を抜粋します。
void btree_init(BTree *t)
{
pool_init(&t->pool);
t->root = btree_create_node(1);
}
static Record *btree_search_node(BTreeNode *node, int key)
{
int i = 0;
while (i < node->key_count && key > node->keys[i])
i++;
if (i < node->key_count && key == node->keys[i])
return node->records[i];
if (node->is_leaf)
return NULL;
return btree_search_node(node->children[i], key);
}
Record *btree_search(BTree *t, int key)
{
if (!t->root)
return NULL;
return btree_search_node(t->root, key);
}
static void btree_split_child(BTreeNode *parent, int index)
{
BTreeNode *full = parent->children[index];
BTreeNode *new_node = btree_create_node(full->is_leaf);
int mid = BTREE_MAX_KEYS / 2; // =1
/* new_node に後半を移す */
new_node->key_count = BTREE_MAX_KEYS - mid - 1;
for (int i = 0; i < new_node->key_count; i++)
{
new_node->keys[i] = full->keys[mid + 1 + i];
new_node->records[i] = full->records[mid + 1 + i];
}
// 略
}
このようにすると、キー取得も追加も比較的速いです。
メモリコピーもそんなに走りません。
テーブルでいい場合も多い
ではB木は常にテーブルに勝るのかというと、そういうわけでもありません。
キーを外部入力しない場合、つまりレコードのidをDB側が発行する場合は追加も検索も計算量ほぼ0で行えます。
実装
void table_init(Table *t)
{
t->key_count = 0;
pool_init(&t->pool);
}
int table_insert(
Table *t,
const char *title,
const char *author,
int isbn_topsix,
int isbn_bottomseven,
int year)
{
if (t->key_count >= 1024)
return;
int i = t->key_count;
Record *record = pool_alloc(&t->pool);
if (!record)
return;
t->keys[i] = i; // verbose
strncpy(record->Title, title, TITLE_MAX);
strncpy(record->Author, author, AUTHOR_MAX);
record->ISBN_topsix;
record->ISBN_bottomseven = isbn_bottomseven;
record->Year = year;
t->data[i] = record;
t->key_count++;
return t->key_count;
}
char *table_search(Table *t, int key)
{
return t->data[key]->Title;
}
わかっていないこと/できていないこと
- ランダムアクセスに適している理由
- 二分探索木の紹介
- 実行速度の測定、データ規模に応じてどのくらい差が出るか
最後までお読みいただきありがとうございました。
-
ところどころ「無効値」みたいなものも許します。「年齢非公表」とかです。 ↩