本記事では、llama.cppの主要部分がどこかや全体像を説明します。
前回記事を踏まえて本記事を読めば、llama.cppのソースを読んでいける状態になると思います。
まずはggmlのサンプルプログラムから見る
llama.cppのソースをいきなり見ようとすると厳しいので、まずは前回も参考にしたggmlのサンプルプログラムを見ていきます。
main
├gpt2_model_load
├read
├gpt_tokenize //プロンプトを単語id配列に変換
[文章を一単語ずつ生成していくループ]
├gpt2_eval
├ggml_get_rows //グラフを作る種々の関数
├ggml_mul_mat //グラフを作る種々の関数
…
├ggml_graph_compute_with_ctx //本番の数値計算。確率一覧を作成
├gpt_sample_top_k_top_p //確率一覧をみて単語を選択(単語idを取得)
├id_to_token //単語idを単語に変換
[ループ終わり]
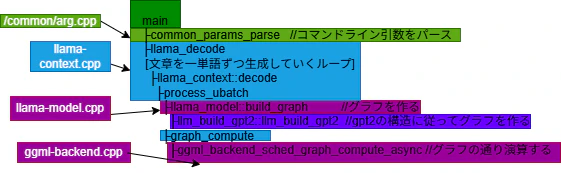
llama.cppの構造
llama-cliから推論すると以下のようなプログラム構造で動きます。
main
├common_params_parse //コマンドライン引数をパース
├llama_decode
[文章を一単語ずつ生成していくループ]
├llama_context::decode
├process_ubatch
├llama_model::build_graph //グラフを作る
├llm_build_gpt2::llm_build_gpt2 //gpt2の構造に従ってグラフを作る
├graph_compute
├ggml_backend_sched_graph_compute_async //グラフの通り演算する
モジュール構造を把握するためにソースファイルを色分けしたのが下図です。
llama.cppの方が少し粒度が粗くなってしまいましたが、一応読んでいける状態にはなったのではないかと思います。
今後加筆していきたいです。
最後までお読みいただきありがとうございました。