はじめに
本記事では、大規模なWebサービスにおいて実際に発生したデータベースロックの問題と、その対策までを解説します。
私が担当していたRailsとMySQLで構成されたAPIサービスで、突如として発生したロックタイムアウトの嵐に遭遇しました。
その嵐は、テーブルの肥大化とユニーク制約違反が引き起こす「ロックコンボイ」という現象でした。
この事例を通じて、データベース設計における長期的な視点の重要性と、パフォーマンス問題のデバッグ手法について得た私なりの知見を共有します。
システム構成
問題が発生したシステムは以下の構成でした。
ここで紹介する事象はMySQL 8.0以上でも再現します。
問題の発生
ある日、特定のAPIエンドポイントで突如として大量の500エラーが発生しました。
症状
- Lock wait timeout exceededエラーが瞬間的に多発
- 約500rpsのリクエストのうち、大半がタイムアウトエラーで失敗
- エラー発生時には数秒間にわたって影響が継続
- 特定のActiveRecordモデルの
saveメソッド(INSERT文)実行時に集中して発生
アプリケーション実装例
class PostsController < ApplicationController
def create
@post = Post.new
ApplicationRecord.transaction do
# 実際はここに大きな処理があってロングトランザクションになっている
@post.save_code!
# ロックを保持し続ける要因となった重い処理をシミュレート
sleep 5
end
render json: @post, status: :created
end
end
class Post < ApplicationRecord
def save_code!
attempts = 0
begin
self.code = Code.generate
save!
rescue ActiveRecord::RecordNotUnique
attempts += 1
raise if attempts > 5
Rails.logger.info("Generated code was duplicated: #{code}")
retry
end
end
end
module Code
# 12桁の数字文字列を生成
def self.generate
SecureRandom.random_number(10**12).to_s.rjust(12, '0')
end
end
原因究明のアプローチ
問題の根本原因を特定するため、以下の手法を用いてチームでデバッグを進めました。
- ログ解析とインストゥルメンテーション
- データベース内部状態の調査
- 再現環境の構築
- 外部サポートの活用
ログ解析とインストゥルメンテーション
ActiveRecordのインストゥルメンテーション機能を活用し、問題が起きているテーブルに実行されるSQLクエリを詳細にロギングしました。
幸い、該当テーブルには個人情報は含まれなかったため、マスキングやログ保存場所などの特別なセキュリティ対策は不要でした。
データベース内部状態の調査
以下の2種類の情報を定期的に取得し、ロック待ちとなっているトランザクションの依存関係を把握できるようにしました。
-
INFORMATION_SCHEMAテーブルから、ロック状態とトランザクション情報をダンプ -
SHOW ENGINE INNODB STATUSコマンドでInnoDB内部の詳細情報を取得
なお、Aurora v3 (MySQL 8+)であれば、data_locksテーブルなどからも状態取得したいですね
再現環境の構築
本番環境でロギングしたクエリを用い、同等のトラフィックパターンの再現を試みました。
ローカルで複数シナリオでスクリプトを組んで実行し、問題を確実に再現できる最小限の手順を確立させました。
ここで再現できなければ、詰んでいたと思います。
外部サポートの活用
再現結果含めてAWSサポートに問い合わせ、Aurora固有の挙動などについて相談しました。データベースの設定やパフォーマンスメトリクスのレビューをしていただき、結果としてはAurora固有の仕様はなく、MySQL の仕様であるという回答を得ました。
このとき、MySQL Bugのサイトで参考となる報告もいただき、事象のメカニズムの理解に役立てました。
※当時ご提供いただいたバグ番号は失念したのですが、以下の報告と事象が似ているのでご参考までに。
原因の特定
調査の結果、以下のメカニズムで問題が発生していることが判明しました。
問題の構造
- ユニークID生成の衝突
- セカンダリインデックスでの重複検出
- プライマリキーへの波及
- ロングトランザクションによるロック保持
- 後続トランザクションのブロック
1. ユニークID生成の衝突
サービス要件により12桁の数字文字列IDをアプリケーションでランダム生成していました(アプリケーション実装例のCodeモジュールを参照)。
そして、既存レコード数が10億件に達し、衝突確率が無視できないレベル(約0.1%)に上昇していることが分かりました。
2. セカンダリインデックスでの重複検出
IDが衝突したことで、このカラムに対するセカンダリインデックスで、ユニーク制約違反が発生しました。
このとき、MySQLはセカンダリインデックス上で(共有)レコードロックを取得します。
しかし、今回の事象ではこのロックは原因ではありません。
3. プライマリキーへの波及
- INSERT対象のテーブルは、RailsのActiveRecord規約に従って設けられたオートインクリメントなサロゲートキーをプライマリキーとして利用していました
- つまり、INSERTしようとした行データのプライマリキーは最も大きな値となります(以下図のid=4を挿入)
- セカンダリインデックスの重複検出時の動作で、プライマリインデックスのsupremum pseudo-record(最大擬似レコード)に対してもネクストキーロックが発生します
その様子を図で示します。
インデックスの模式図はB+Tree index structures in InnoDBを参考に描いています。
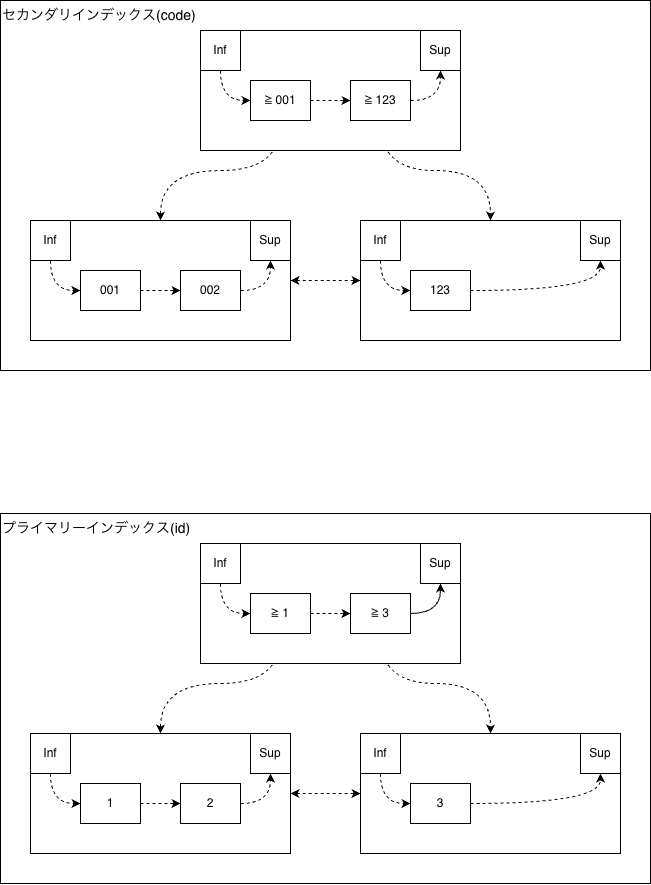
1つ目の図は、INSERT前の状態です。すでに(code)=(’123’)という行が存在しています。
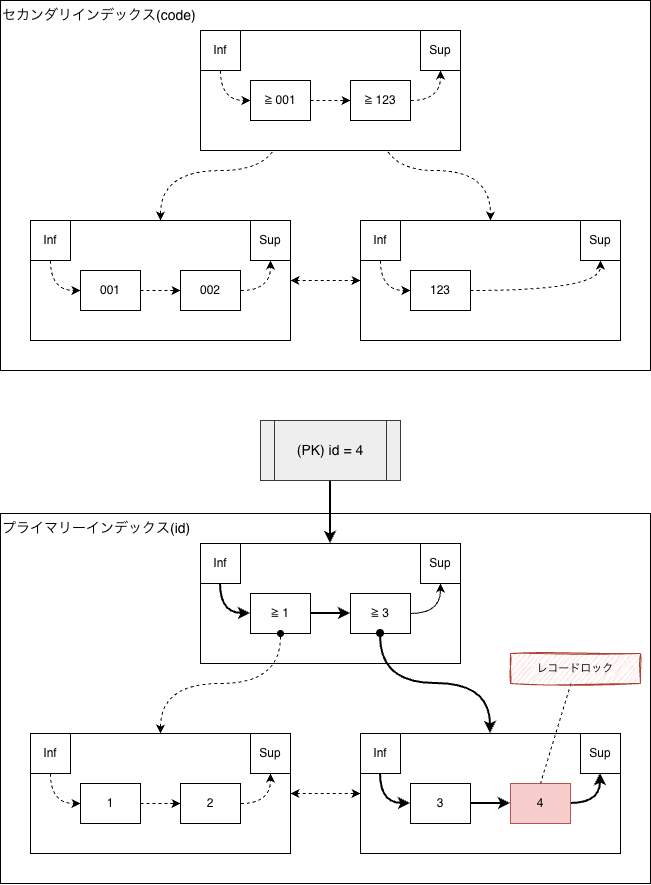
次の図は、セカンダリインデックスが重複する行(id, code)=(4, ’123’)をINSERTする様子です。
まずはプライマリーインデックスに(id)=(4)のレコードをINSERTします。
続いて、セカンダリインデックスに(code)=(’123’)をINSERTしようとしますが、セカンダリインデックスの123という値が重複します。
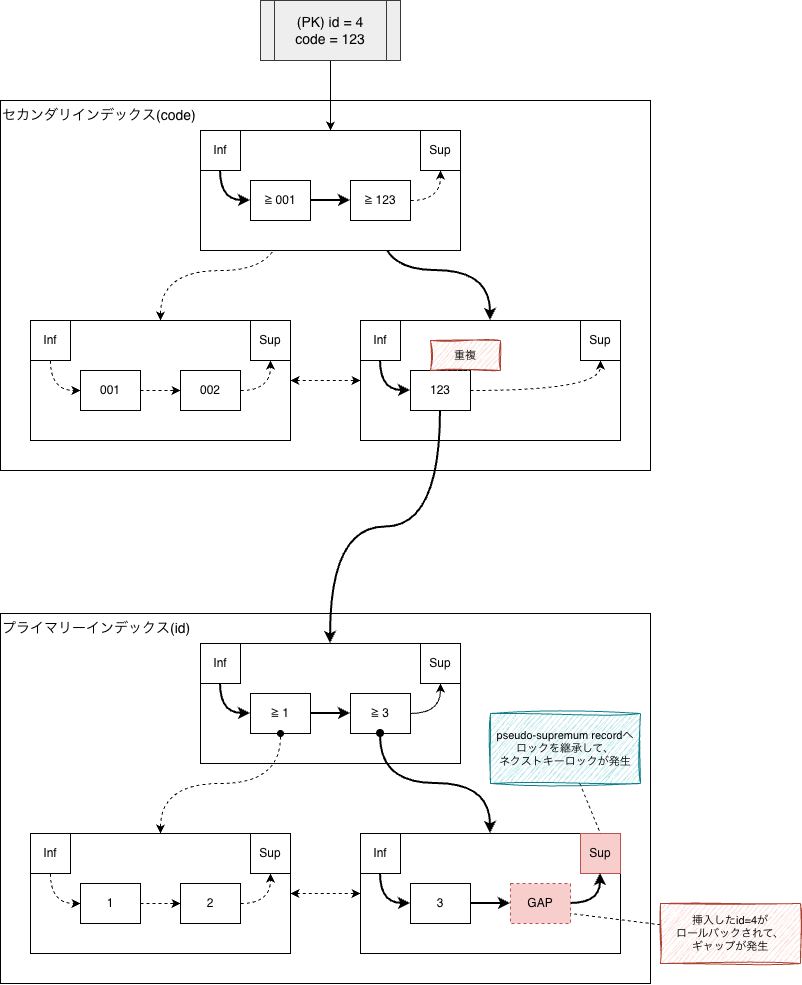
すると、MySQL InnoDBストレージエンジンでエラー処理用の関数row_mysql_handle_errorsによってロールバックが実行され、挿入済みのプライマリーインデックスからレコード(id)=(4)を削除します。
レコードが削除されたことでその部分にギャップが発生してしまいます。
そこで、続くlock_update_delete関数によって元のレコードロックをギャップロックとし、次のレコード(supremum pseudo-record)にロックを引き継ぎます。これによって、supremum pseudo-recordへのネクストキーロックが発生するという仕組みです。
4. ロングトランザクションによるロック保持
アプリケーション側でID生成のリトライ処理を実装していたため、ユニーク制約違反発生後もトランザクションが継続し、ロックを長時間保持しました。
5. 後続トランザクションのブロック
別のDBトランザクションによる新しいINSERT処理がすべて、supremum pseudo-recordのネクストキーロック解放待ちとなり、待ち行列が発生して後続トランザクションがすべて待機しました。
InnoDBのロック状態(実例)
以下は、問題発生時に取得したInnoDBの内部状態です。重複しているのは(code)=(’123456789012’)になります。
---TRANSACTION 403453, ACTIVE 20 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1128, 1 row lock(s)
MySQL thread id 60, OS thread handle 281472900120320, query id 602082 160.79.104.10 root update
insert into posts(code) values ('123456789012')
------- TRX HAS BEEN WAITING 20 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 8 page no 4 n bits 72 index PRIMARY of table `rails_development`.`posts`
trx id 403453 lock_mode X insert intention waiting
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
0: len 8; hex 73757072656d756d; asc supremum;;
------------------
---TRANSACTION 403452, ACTIVE 23 sec
4 lock struct(s), heap size 1128, 2 row lock(s)
MySQL thread id 57, OS thread handle 281473235336960, query id 602080 160.79.104.10 root
以下は同じ状況におけるロックテーブルの状況です。
SELECT
thread_id,
index_name,
lock_type,
lock_mode,
lock_status,
lock_data
FROM performance_schema.data_locks
where object_name = 'posts'
;
| thread_id | index_name | lock_type | lock_mode | lock_status | lock_data |
|---|---|---|---|---|---|
| 57 | TABLE | IX | GRANTED | ||
| 57 | index_posts_on_code | RECORD | S | GRANTED | '123456789012', 1 |
| 57 | PRIMARY | RECORD | X | GRANTED | supremum pseudo-record |
| 60 | TABLE | IX | GRANTED | ||
| 60 | PRIMARY | RECORD | X,INSERT_INTENTION | WAITING | supremum pseudo-record |
このログから、トランザクション403453が20秒間にわたってプライマリインデックスのsupremum疑似レコードに対する挿入意図ロックの取得が待機されていることがわかります。
ロックコンボイ現象の理解
今回の問題の核心は「ロックコンボイ(Lock Convoy)」と呼ばれる並行処理における性能劣化現象です。
ロックコンボイとは

Convoying is a phenomenon in concurrent systems that occurs when a thread holding a lock experiences a delay, causing other threads that require the same lock to queue up behind it.
ロックコンボイ(ロック渋滞)とは、ロックを保持しているスレッドが遅延すると、同じロックを必要とする他のスレッドが次々とキューイングされ、全体のスループットが大幅に低下する現象です。
今回のケースにおけるコンボイの発生メカニズム
- 引き金:ユニーク制約違反により、トランザクションAがギャップロックを取得し、エラーハンドリングのため処理が遅延
- 連鎖反応:トランザクションBが同じテーブルへのINSERTを試みるが、ロック待ちで停止
- 雪崩効果:トランザクションC、D、E...が次々とキューイングされ、待機状態に
- スループット崩壊:500rpsの処理能力が低下
衝突確率の検証
設計当初は問題なかったユニークID生成ですが、12桁(1兆通り)ある数字文字列が本当に衝突するものなんでしょうか?
設計時の前提
- ID形式:12桁の数字文字列(000000000000〜999999999999)
- 番号空間:$10^{12}$(1兆)通りの可能性
- 生成方法:ランダム生成
衝突確率の計算
新しいレコード1件が既存のレコードと衝突する確率は、単純に「既存レコード数 ÷ 名前空間」で求められます。
$$
P(衝突) = \frac{n}{N}
$$
本システムでは $n=10^9$(既存レコード数)、$N=10^{12}$(番号空間)のため、以下のとおり衝突確率=約0.1%(1,000回に1回)となります。
$$
P(衝突) = \frac{10^9}{10^{12}} = 10^{-3} = 0.1%
$$
500 rpsでの衝突頻度に換算すると、500 rps × 0.001 = 0.5回/秒(2秒に1回程度)も高頻度な衝突が起きる計算となります。
問題の本質
衝突確率0.1%は決して高くありません。しかし、低頻度の衝突でも、ロングトランザクション内で発生するとロックコンボイの引き金となる点が問題でした。
2秒に1回程度の衝突でも、トランザクションが5秒間ロックを保持すれば、その間に約2,500件のINSERTが待機状態になります。
まさに渋滞の連鎖です。
最悪のケースとして、各衝突で5秒のロック保持 × 10回 = 50秒衝突の連鎖が続くと仮定すると、innodb_lock_wait_timeoutのデフォルト値50秒を超え、待機中のトランザクションが次々とタイムアウトしてしまいます。
実装された解決策
原因を特定した後、以下のようなアプローチで問題を解決しました。
- メイントランザクションからID生成処理をスレッド分岐
- 別のDBコネクションを用いる
- 生成したIDのユニーク性を
READ COMMITTEDトランザクション分離レベルを使って確認
これにより、メイントランザクション内でのユニーク制約違反の確率を下げ、supremum pseudo-recordのネクストキーロックの確率を下げました。
該当システムはWebアプリケーションサーバとして、プロセスモデルで稼働するPhusion Passengerを使用していたため、DBコネクションプールについての制約は緩いものでした。
メイントランザクション自体のトランザクション分離レベルは、影響範囲が大きくREPEATABLE READのまま据え置きました。
class PostsController < ApplicationController
def create
@post = Post.new
# 影響範囲が大きく暫定的に分離レベルは維持された
ApplicationRecord.transaction do
@post.async_save_code! # 別スレッドでID生成する処理に置き換え
# ロックを保持し続ける要因となった重い処理
sleep 5
end
render json: @post, status: :created
end
end
class Post < ApplicationRecord
def async_save_code!
self.code = Post.async_generate
save!
end
def self.async_generate
code_generator = Thread.new do
5.times do
code = Code.generate
unique = ApplicationRecord.transaction(isolation: :read_committed) {
!Post.exists?(code: code)
}
break code if unique
Rails.logger.info("Duplicated code was generated: #{code}")
end
end
code_generator.value
end
end
教訓
この経験から得られた重要な学びをまとめます。
1. ユニークID設計の原則
設計時は将来のレコード数を考慮し、十分な余裕を持った番号空間が設計されていたはずでした。
なので、ある種の順当な進化を経た成長痛ではあります。問題に備えて追加で検討できることは以下です。
衝突監視の実装
ユニーク制約違反の発生頻度を監視し、閾値を超えたらアラートを発報させるようにします。特に見積条件となったデータ増加速度と実測に乖離がないかを確認する仕掛けがあるとより安全です。
このように、当時の設計前提に基づくアラート設定(技術的負債アラート)は、いわゆる緊急性のある運用対応とは別の、設計の陳腐化を未来に伝える良い手段になるかなと思います。
決定論的ID生成
可能であれば、ランダム生成ではなく決定論的なID生成(シーケンス、タイムスタンプベースなど)の仕組みを検討したいです。IDのビジネス要件の検討段階で、本当に全桁でランダムである必要があるのかを検討されたいです。
外部IDと内部IDの区別
今回のシステムで同期的に発行するのは、ビジネス要件の制約に囚われない技術的に自由度の高い内部IDを採用しつつ、非同期でビジネス要件に沿ったシビアな外部IDを発行するような仕組みも考えられます。遅延処理が致命的になり得るのか再検討する価値があります。
(そもそもIDが不要になるといいですね)
2. トランザクション設計の原則
トランザクションの最小化
トランザクション内での処理は必要最小限にとどめましょう。
リトライ処理の外出し
リトライが必要な処理はトランザクション外で実施し、ロック範囲と時間が広がらない工夫を入れましょう
適切な分離レベルの選択
用途に応じて分離レベルを使い分けましょう。今回の事象はMySQLデフォルトのREAD COMMITTED分離レベルでは起きない事象でした。
3. モニタリングとアラート
ロック待ち時間の監視
平均ロック待ち時間と最大ロック待ち時間、またはその代替としてHistory List Lengthを継続的に監視して、傾向変化を多角的な視点でモニタリングできる環境があるといいです。
トランザクション時間の可視化
長時間実行されているトランザクションを検出できるようにします。
まとめ
本記事では、大規模データベースにおけるロックコンボイ問題の発見から解決までを解説しました。
- テーブルの肥大化は、設計時には問題なかった部分にも影響を及ぼします
- 固有のランダムなユニークID生成は、要件見直しと耐用年数設計に合わせたモニタリングが重要になります
- ロックコンボイは、一見関係のない複数の要因が組み合わさって発生します
- トランザクション設計とロック戦略は、スケーラビリティに直結します
- 包括的なモニタリングにより、問題の早期検出・診断をサポートします
同様の問題に直面している方々の参考になれば幸いです。