2026-07-05 全面改稿: 初出(7/2)から追記を2回重ねた時系列構成を、実測が出そろった時点で体系構成に整理し直しました。数値はすべて全日確定値に更新しています。速報時の経緯や生データは、リポジトリの
docs/verification-2026-07-04.md/docs/verification-2026-07-05.mdに残してあります。
概要
Claude Code を回した実測で、消費トークン量の
約95%がcache read(キャッシュ済みコンテキストの再読) でした。
最初は「output が重いのでは」と思っていました。
が、実際 output は全体の約0.4%。大半を占めたのは、肥大化したセッションを毎ターン再読する cache read、コヤツが犯人でした。
ただ、これは「料金の95%が cache read だった」という意味ではないです。cache read は通常の入力より単価が安い。問題は単価ではなく、量。長いセッションでは、毎ターンの再読量が雪だるま式に増えていく。
この記事で扱うのは、私の Claude Code 利用ログ(2026-07-02〜07-05 の4日間)から見えた実測です。
Claude Code 全体の一般統計ではありません。
ですが、長時間セッションを多用する人にはかなり再現性のある問題になると思われます。
この記事の全体像は5つ。
- トークン最適化でまず見るべきは output ではなく cache read
- 集計には3つの罠がある:
requestIdの重複、subagents/の別ファイル、そして測定日当日の部分日バケット - 可視化だけでは行動は変わらない。効いたのは、フックでモデル自身に切り時を提案させる closed-loop
-
/compactはセッション内の live context を中央値66%縮める(実測29件)。ただし200k トークン超で切らないとほぼ無意味 - 4日間のワークロード正規化系列で、セッション中央値の cacheRead/output 比が 233x → 83x へ単調改善。一方 cacheRd% と hot率は動かず、「どの指標を成功指標にすべきか」自体が実測の成果だった
この仕組みは Claude Code プラグイン session-health として公開しています。
きっかけ
Fable 5復活に歓喜して、朝4時から Claude Code をブン回す。
サブスクとはいえ1週間のRate Limitがある。
「どの処理が一番トークンを食っているのか」気がかりですよね。
Claude Code は ~/.claude/projects/ 配下にセッションのトランスクリプトを JSONL として残す。つまり、API側の請求画面を待たなくても、ローカルだけで input / output / cacheRead / cacheCreation の内訳をかなり正確に出せる。
最初は「生成が重いのでは」と思っていた。
実測すると、主役はまったく違った。
測り方 — transcript 集計と3つの罠
JSONL の assistant レコードには message.usage が入っている。
主な内訳は次の4つ。
input_tokensoutput_tokenscache_read_input_tokenscache_creation_input_tokens
さらに requestId や sessionId も入っている。
この情報を集計すれば、セッションごとのトークン内訳を出せる。
ただし、素朴に合計すると罠にはまる。私は3つ踏んだ。
罠1: ストリーミングの重複
1リクエストが複数の JSONL 行に分かれて書かれるため、行単位で合計すると2〜3倍に水増し。。。
requestId で重複排除する必要があった。
初日の実測では、重複排除によって 513.9M tokens 分の水増しを除外した。
ここを間違えると結論が大きくズレる。
罠2: サブエージェントは別ファイル
もう1つの罠は、サブエージェントのトランスクリプト。
サブエージェントのログは、本体と同じ JSONL ではなく、次のような別ディレクトリに保存される。
<プロジェクト>/<セッションID>/subagents/agent-*.jsonl
ここを見落とした私は、「なんで、委譲ゼロやねん!!!」と疑問符が頭にわいた。
実は、main 以外の agent でも 875リクエスト が記録されていた。
集計を疑い、ファイル構造を確認してから結論を出すべきだった。
罠3: 測定日当日のバケットを確定値にしない
これは数日運用してから踏んだ罠。
7/4 の日中に集計した「7/4 の行」は、総tok 133M・委譲27%だった。ところがその後も作業は続いていたので、全日で締め直すと 総tok 220M・委譲19% に変わった。「7/4 に委譲が増えた」という観察は、日中時点の偏りにすぎなかった。
日次比較は全日確定バケットだけで行い、測定日当日の分は「部分日」と明記する。 集計ツールを作った本人がこの罠を踏んだので、自戒として残しておく。
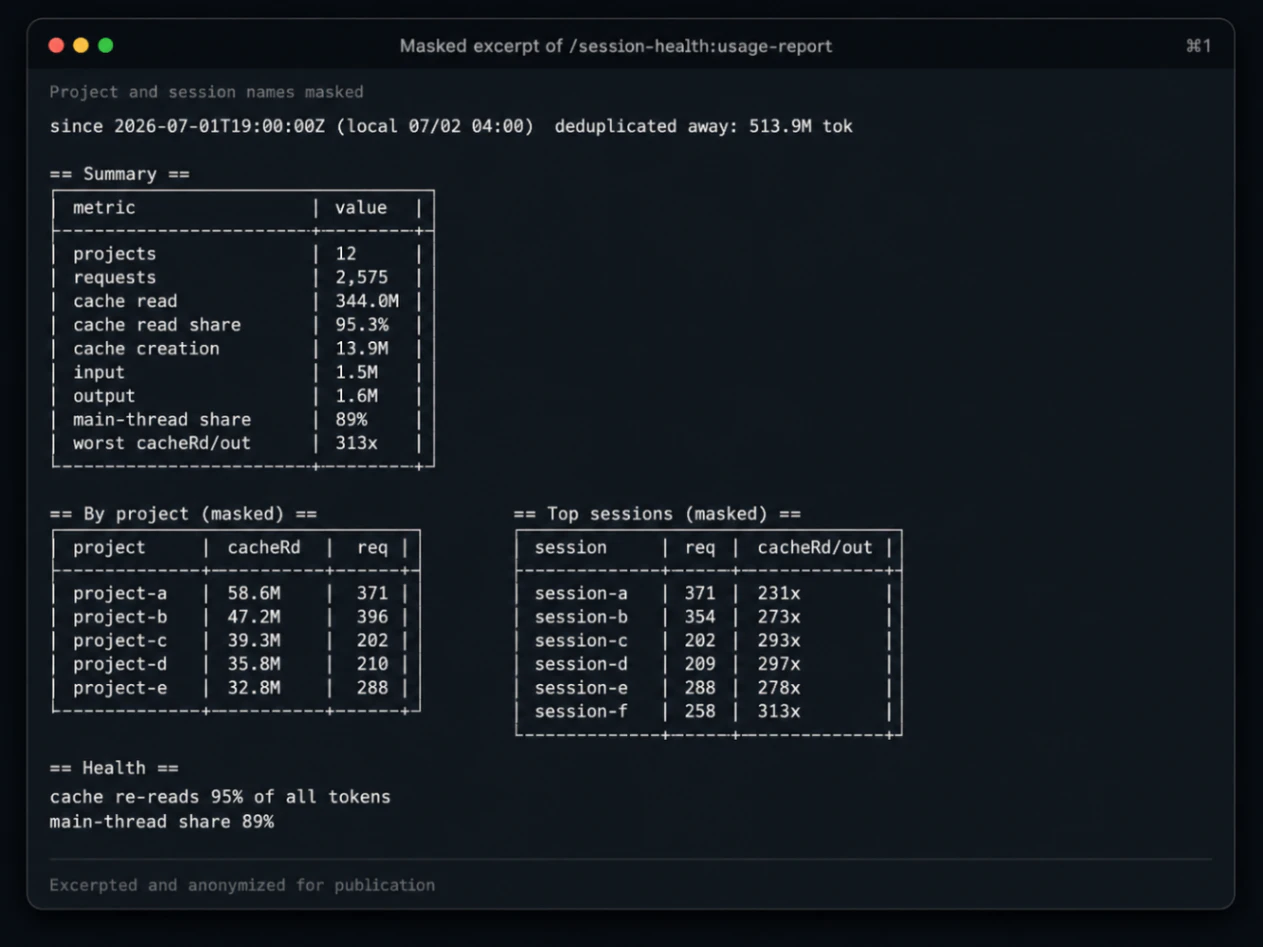
実測1: トークンの95%は cache read
初日(2026-07-02)の1日分を /session-health:usage-report で集計。
条件は次の通り。
- 12プロジェクト
- 2,575リクエスト
-
requestIdベースで重複排除済み - top-level session と
subagents/配下の transcript を両方集計 - 重複排除で除外した水増し分: 513.9M tokens
結果。
| 種別 | トークン | 割合 |
|---|---|---|
| cache read | 344.0M | 95.3% |
| cache creation | 13.9M | 3.9% |
| input | 1.5M | 0.4% |
| output | 1.6M | 0.4% |
output は約0.4%。
一方で、cache read は約95%。
Claude Code のトークン消費で支配的だったのは、生成そのものではなく、長く太ったセッションの再読だった。
セッション別に見ると、ワースト帯では cacheRead/output 比が 200〜300倍超 まで膨らんでいた。最大では 313倍。
cacheRd/out=313x
cacheRd/out=297x
cacheRd/out=293x
cacheRd/out=278x
cacheRd/out=273x
数字を見ると、output を少し削るよりも、
まずセッションの切り時を早める方が効く構造だとわかる。
マスク済み抜粋
なぜこうなるのか
プロンプトキャッシュ自体が犯人ではない。
Claude Code のような長文コンテキスト前提のワークフローでは、キャッシュはむしろ必須に近い。毎回すべてを通常入力として送るより、キャッシュを使った方が安く済む。
問題は、usage 上、長く太ったセッションほど各リクエストで大量の cache_read_input_tokens が計上される構造です。
セッションが長くなる。
コンテキストが太る。
1ターンごとの再読量が増える。
さらに会話を続ける。
そのたびに、太ったコンテキストを読み直す。
この繰り返しで、cache read の総量が雪だるま式に増える。
つまり、トークン最適化の主戦場は「返答を短くすること」だけではない。
むしろ、長くなったセッションをどこで畳むかが重要になる。
委譲しているつもりでも、メインスレッドに偏る
agent 別の内訳も出した。
結果、初日の main-thread share は 89% だった。
これは、全トークン消費の大半がまだ main thread に集中していたという意味である。サブエージェントは動いているが、「メインはオーケストレーター、実装や調査はサブエージェント」という理想形にはまだ寄っていない。
サブエージェントは、メイン会話のコンテキストを汚さずに探索や実装を逃がせる。だから、Claude Code を長時間使うなら有効な設計だと思う。
ただし、「サブエージェントを使っている」だけでは足りない。
実際には次のような観点まで見る必要がある。
- どの agent が動いているか
- どの model で動いているか
- main thread にどれだけ残っているか
- 探索や定型作業が本当に委譲されているか
- 重いモデルで軽い作業を回していないか
「探索は軽いモデルに逃がしているつもり」でも、実際にどの model が動いたかはログを見ないとわからない。
CLAUDE.md や運用ルールに書くだけでは不十分で、実測で確認する必要がある。
対策: 可視化では行動が変わらなかった
実は、statusline にはすでに「セッションが大きくなったら警告」を仕込んでいた。
しかし、結果はこうだった。
3.4MBまで膨張。
人間は警告を見ない。
少なくとも私は見なかった。
見たとしても、作業の区切りが悪いと無視する。
「あと少しだけ」と思って続ける。
その「あと少し」が積み上がって、セッションが太っていく。
そこで発想を変えた。
人間に警告するのではなく、モデル側に自覚させる。
Claude Code の UserPromptSubmit フックは、ユーザーがプロンプトを送信した直後、Claude が処理する前にスクリプトを挟める。ここで additionalContext を返すと、次のモデルリクエストにコンテキストとして注入できる。
session-health は、セッションの状態を見て、閾値を超えたらモデルに短い是正指示を注入する。
閾値検知
- リクエスト80回超
- または cacheRead/output 比 150倍超
→ additionalContext を注入
「次の自然な区切りで /compact か新セッションを提案せよ」
「探索や定型作業はサブエージェントへ委譲せよ」
→ モデルが自分から畳み時を提案してくる
注入は20リクエストに1回、約60トークン程度。
したがって、是正コスト自体はかなり小さい。
同じ判定エンジンを、次の3つに接続した。
| 出口 | 役割 |
|---|---|
UserPromptSubmit hook |
モデルに切り時と委譲方針を注入する |
| statusline | 人間向けに現在の session health を表示する |
| Stop hook 通知 | 応答完了時に「切り時」を通知する |
ポイントは、単なるダッシュボードではないこと。
検知して終わりではなく、モデルの次の行動に介入する。
閉ループは「自分の効果」を観測できるように作る
運用初期に、ツール自身のバグも踏んだので共有しておく。
当初は req 数と cacheRead/output 比を transcript 全体で累積していた。すると /compact してもカウンタが下がらない。statusline は 🔥 のまま、フックは「また compact しろ」と鳴き続ける。つまり、閉ループが自分の介入効果を観測できない構造だった。
v0.3.1 で計測を「最後の compact 以降の生きたセグメント」に変更した。実セッションでは 🔥req671·480x が compact 後に req47·115x へ即リセットされる。
あわせて、疑っていた「サブエージェント分の二重計上」は実データで非問題と確認できた。
「作動する」と「効いたと観測できる」の間にはもう1段ある。介入するツールを作るなら、介入の効果が自分の計測に反映されるところまで含めて設計する必要がある。
実測2: /compact はセッション内で中央値66%縮む
closed-loop が「作動する」ことと「効く」ことは別問題なので、効果を実測した。
測り方 — 日次集計ではなく、イベント前後の直接比較
日次の集計値どうしを比べると、「その日どれだけ働いたか」に交絡される。仕事量が3倍の日はトークンも増えるので、生の日次比較では /compact の効果を主張できない。
そこで transcript に記録される compact 境界レコードを使った。/compact すると、type: system / subtype: compact_boundary のレコードが transcript に書かれる(compactMetadata に圧縮前サイズ preTokens と、手動/自動を区別する trigger を持つ)。
この境界の前後 K=4 リクエストずつの live context(リクエストあたり input + cache_read + cache_creation)を同一セッション内で直接比較する。ワークロード量に依存しない、compact そのものの効果測定になる。
計測スクリプトはプラグインに同梱した(scripts/compaction_effect.py。ローカル読み取りのみ、外部送信なし)。
結果: 中央値66%縮む。ただし「早すぎる /compact」は無意味
手元の実 transcript にあった compact イベント 29件(manual 27 / auto 2)で:
- live context 削減: 中央値 66%(auto はほぼ上限で発火するため 77%)
- 圧縮後のフロアはほぼ一定で約50〜64kトークン(中央値 59,382)。システムプロンプト・ツール定義・保持セグメントが残るため、ここより下には縮まない
- 削減率は圧縮前サイズにきれいに単調依存する(Spearman ρ=0.977)
| 圧縮前サイズ | n | 削減率(中央値) |
|---|---|---|
| <100k | 9 | 14% |
| 100–200k | 7 | 62% |
| 200–400k | 11 | 79% |
| >=400k | 2 | 89% |
実務的な含意は明快で、フロアの2倍(約100〜130k)未満で /compact を打ってもほとんど得しない。200k超で切れば8割前後縮む。閾値ベースで「熱くなってから切る」という session-health の設計は、結果的に正しかった。
実測3: 4日間の正規化系列 — 233x → 83x
セッション内で縮むことは分かった。では、日をまたいだ利用全体では効いているのか。
観測窓は 7/2〜7/5(閉ループ稼働開始は 7/2 の夜、7/5 は 15:30 頃までの部分日)。窓全体が同一モデル世代なので、日間比較にモデル移行の交絡はない。
生の日次系列(全日確定ベース)
| 日 | 総tok | cacheRd% | main share | 委譲 | hot(≥80req) | セッション数 |
|---|---|---|---|---|---|---|
| 7/2(稼働前中心) | 381M | 95% | 87% | 13% | 13 | 43 |
| 7/3 | 119M | 93% | 91% | 9% | 6 | 16 |
| 7/4 | 220M | 94% | 81% | 19% | 11 | 25 |
| 7/5(部分日) | 58M | 95% | 90% | 10% | 3 | 8 |
総トークンは日次で7倍動く(57M〜381M)ので、総量の増減そのものからは何も主張しない。そして cacheRd% は動かない。cache read が9割を占めるのはこのワークロードの構造であって、閉ループの成功指標にはならないことが、系列を延ばしてはっきりした。
本命: ワークロードに依存しない正規化指標
そこで、セッション単位に正規化した指標で見る。
| 日 | セッション中央値 cacheRd/out | セッション中央値 req数 | worst比(絶対量併記) | hot率 |
|---|---|---|---|---|
| 7/2 | 233x | 2 | 313x (cacheRd 32.8M) | 30% |
| 7/3 | 130x | 59 | 249x (2.5M) | 38% |
| 7/4 | 110x | 59 | 891x (5.8M) | 44% |
| 7/5(部分日) | 83x | 20 | 165x (23.5M) | 38% |
(cacheRd/out 比は req≥10 のセッションのみで算出。hot率 = hot セッション / その日のアクティブセッション)
いちばん重要なのは左の列で、セッション中央値の cacheRead/output 比が 233x → 130x → 110x → 83x と単調に下がっている。
これが効いている根拠になるのは、同じ期間にセッションの使い方が「多数の短いセッション(中央値2リクエスト)」から「少数の長いセッション(中央値59リクエスト)」へ変わっているからだ。cache read は文脈長に比例して毎リクエスト積み上がるので、セッションが長くなればこの比は普通は悪化する。長時間化と比率低下が同時に起きているのは、閾値で /compact を打って live context を切り下げている効果と整合する。
悪化した指標も正直に書いておく。hot率(≥80req セッションの割合)は 30% → 44% と上がった。セッションを集約した副作用で、閉ループは「hot になったら切らせる」仕組みであって「hot にさせない」仕組みではない。ここは設計どおりだが、期待とのずれとして明記しておく。
もう1つ。「ワーストの cacheRead/output 比」は 7/4 に 891倍と過去最悪を更新したが、実体は出力が6.5kトークンしかないドキュメント閲覧セッションだった(cache read の絶対量は5.8Mと小さい)。比率だけを見ると低出力セッションが上位を独占するので、この指標は絶対量と併読しないと読み間違う。
/compact の打ち方が変わった
compact 境界レコードの日次カウントはこうなった: 1回 → 21回 → 7回 → 1回。
稼働翌日の 7/3 はフックに言われるがままに21回も切っている。帯域別の実測(<100k で切ってもほぼ無意味、200k超で8割縮む)を知ってからは回数が減った。回数が減ったあとも中央値比は下がり続けている(110x → 83x)ので、回数より切るタイミングが効いている可能性が高い。
因果についての留保
因果の断定はしない。n=4日(うち部分日1)・1ユーザー・ワークロード非統制である。
ただし「セッション内の直接測定(中央値66%削減)」と「正規化系列の単調改善(233x→83x)」という独立な2系統が同方向を指しており、閉ループが cache read の積み上がりを削っているという説明が現時点で最も整合的だと考えている。
生データと再現手順はリポジトリの docs/verification-2026-07-04.md / docs/verification-2026-07-05.md に置いた。
実務ガイド — 明日から使うなら
4日分の実測から言える運用の要点をまとめる。
1. /compact は「200k超えてから」
圧縮後のフロアは約50〜64kトークンで、それより下には縮まない。フロアの2倍(約100〜130k)未満で切っても中央値14%しか縮まない。200k超で切れば8割前後縮む。
「こまめに /compact」は無意味だった。閾値を超えて熱くなってから、タスクの区切りで切る。
2. 見る指標と、単独では見ない指標
見る指標:
- セッション中央値の cacheRead/output 比(絶対量と併読)— 閉ループの効果が最も素直に出た
- main-thread share と agent × model 内訳 — 委譲が実際に起きているかはログでしか分からない
単独では見ない指標:
- cacheRd% — 構造的に9割前後で張り付き、ほぼ動かない。成功指標にならない
- worst 比 — 低出力セッションが上位を独占する(891x の実体は出力6.5kの閲覧セッション)。絶対量との併読が必須
- hot率 — セッションを集約すると悪化する。閉ループの設計上は想定内の動き
3. 集計するなら3つの罠を踏まない
-
requestIdで重複排除する(しないと2〜3倍に水増し) -
subagents/配下の別ファイルを読む(読まないと委譲ゼロに見える) - 測定日当日のバケットを確定値にしない(全日で締めると数字が変わる)
既存ツールとの違い
ccusage はコスト・使用量レポートとして強力だし、Claude HUD は context usage や active tools、running agents、todo progress などを常時表示できる。
どちらも便利で、競合というより補完関係に近い。
ただ、今回作りたかったのは「見える化」ではなかった。
作りたかったのは、閾値を超えた瞬間にモデルの挙動を変える closed-loop だった。
見える化は、人間が見ることを前提にしている。
しかし、人間は見なくなる。
だから、見える化だけでなく、モデル自身に「今は切り時だ」と知らせる。
そして、モデルがタスクの区切りで /compact や新セッションを提案する。
調査した範囲では、UserPromptSubmit フックで session health を見て、additionalContext によってモデル自身の行動を変えるツールは見つからなかった。反例があれば教えてほしい。
このプラグインの賭けどころは、「最も安い介入点はダッシュボードではなく、モデル自身の行動ではないか」という点にある。
インストール前に確認してほしいこと
Claude Code のプラグインは強力である。commands / hooks / agents / MCP servers などを追加できるため、よくわからないプラグインを入れるのは普通に怖いと思う。私もそう思う。
なので、このプラグインが何を追加するかを明示しておく。
session-health が追加するものは主に2つ。
-
/session-health:usage-report- ローカルの
~/.claude/projects/配下にある Claude Code transcript を読み、token usage を集計する slash command - 集計軸は
project × session × subagent × model - 外部送信はしない
- ローカルの
-
UserPromptSubmithook- プロンプト送信時に、現在のセッション状態をローカル transcript から読む
- 閾値を超えている場合だけ、短い
additionalContextをモデルに注入する - 目的は「次の区切りで /compact か新セッションを提案せよ」とモデルに知らせること
このプラグインは、次のものを追加しない。
- MCP server
- 外部API連携
- 常駐 daemon
- ネットワーク送信
- Python 標準ライブラリ以外の依存
不安な場合は、インストール前にリポジトリ内の以下を確認してほしい。
.claude-plugin/plugin.json.claude-plugin/marketplace.jsonhooks/hooks.jsoncommands/usage-report.mdscripts/session_health.pyscripts/usage_report.py
特に見るべきなのは hooks/hooks.json である。
ここに、Claude Code がどのタイミングで何を実行するかが書かれている。
「個人リポジトリのプラグインを警戒する」のは正しい感覚だと思う。
そのうえで、中身を見て判断してほしい。
使い方
導入は2行。
/plugin marketplace add House-lovers7/claude-code-session-health
/plugin install session-health@house-lovers7
フックと /session-health:usage-report はすぐ使える。
/session-health:usage-report では、次の4軸でトークン内訳を確認できる。
project × session × subagent × model
statusline と Stop 通知の接続は README に書きました。
すべてローカル完結。
外部送信はしない。
閾値は環境変数で調整できる。
限界と今後
- 因果の証明ではない。 n=4日・1ユーザー・ワークロード非統制の観測であり、独立2系統の整合性までが現時点の主張である。7日以上の系列が溜まったら第3報を出す
- hot率の扱いは未解決。 セッション集約の副作用として許容するのか、指標を再定義するのか(例: hot になってから切るまでの滞留リクエスト数)は今後の課題
-
transcript の内部仕様に依存する。 JSONL のレコード形状や
subagents/の配置は非公開仕様であり、Claude Code の将来の更新で集計側の修正が必要になる可能性がある - 閾値は私のワークロードに合わせた既定値で、環境変数で調整できる
まとめ
- トークン最適化の主戦場は output ではなく cache read、つまり肥大化したセッションの再読だった
- 集計は
requestId重複排除・subagents/ディレクトリ・部分日バケットの3つの罠を踏むと誤診する - サブエージェントは使うだけでなく、どの agent がどの model で動いたかまで確認する
- 可視化だけでは行動は変わりにくい。閾値を超えたら、モデル自身に切り時を提案させる方が今回いちばん効いた
- /compact はセッション内の live context を中央値66%縮める。ただし切るのは 200k 超えてから
- 日をまたいだ傾向も、正規化した4日系列でセッション中央値の cacheRead/output 比が 233x → 83x へ単調改善。一方 cacheRd% と hot率は動かず、どの指標が成功指標になり得るか自体が実測の成果だった
同じ構造(検知 → モデルへの注入 → 行動変更)は、委譲の徹底、セキュリティ規約の再確認、巨大ログの持ち込み抑制など、他の「守られないルール」にも応用できるはず。