DjangoでLINE botを動かす手順はこちらの記事を参考にさせていただきました。詳しい解説はリンクをご覧ください。
Djangoとハギングフェイスライブラリを用いてローカルで動くLINE_botを作る
目次
・LINE developers側の設定
・Django側の実装
・公開設定
・ローカルLLMの設定
・実際に動作させる
LINE developers側の設定
ラインデベロッパーズにログインしてください。
その後、プロバイダーを作成して

LINE Messageing API を選択し、チャンネルを設定します。(後で変更が可能)

作成したチャンネルのLINE Messageing API設定に移動し、以下のように設定します(一番下にある)

そのあと、LINE Messageing API設定の下にあるチャネルアクセストークンを選択し、発行されたトークンを保存しておきます。(後で使う)

Djangoの実装
Djangoプロジェクト用のディレクトリを作成します。
$ mkdir AI_line_bot
$ cd AI_line_bot
仮想環境にDjangoをインストールする
$ python -m venv env
$ ./env/Scripts/activate
$ pip install Django
###プロジェクト製作
下記コマンドを実行してプロジェクトを作成します。
$ django-admin startproject line_bot
$ cd line_bot/
$ python manage.py startapp line_bot_ai
Djangoの仕組みは元記事をご覧ください。
ファイルの作成など
作ったline_bot_aiのアプリケーションの中に、urls.pyを作成し、以下の内容を記述します。
from django.urls import path
from . import views
urlpatterns = [
path('', views.index, name='callback'),
]
プロジェクト側のline_botフォルダの中にあるurls.pyに反映させるため、ファイルの中身を二箇所変更します。
from django.contrib import admin
from django.urls import include, path # 変更部分
urlpatterns = [
path('line_bot_ai/', include('line_bot_ai.urls')), # 変更部分
path('admin/', admin.site.urls),
]
新しいクラスをアプリ側に作成
views.pyを編集する前に、新しくLineMessageクラスをアプリ側(場所はline_bot/line_bot_ai/LineMessage)に作成し、LINE Messaging APIにHTTPリクエストを送るための、replyメソッドを作成します。
先ほど保存しておいたアクセストークンはここで使います。
from django.http import HttpResponse
from django.views.decorators.csrf import csrf_exempt
import urllib.request
import json
REPLY_ENDPOINT_URL = "https://api.line.me/v2/bot/message/reply"
ACCESSTOKEN = '***先ほど発行したアクセストークンをここに貼り付け***'
HEADER = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + ACCESSTOKEN
}
class LineMessage():
def __init__(self, messages):
self.messages = messages
def reply(self, reply_token):
body = {
'replyToken': reply_token,
'messages': self.messages
}
print(body)
req = urllib.request.Request(REPLY_ENDPOINT_URL, json.dumps(body).encode(), HEADER)
try:
with urllib.request.urlopen(req) as res:
body = res.read()
except urllib.error.HTTPError as err:
print(err)
except urllib.error.URLError as err:
print(err.reason)
メッセージを作るためのプログラムを作成
アプリケーション(line_bot_ai)と同じ階層にutilsというフォルダを作成して、LINEにメッセージを送るためのメッセージ作成用のパイソンファイルを作成します。
今現時点でmessage_creater.pyの中身は、トンボ返しをするようにできています。
def create_single_text_message(message):
test_message = [
{
'type': 'text',
'text': message
}
]
return test_message
アプリサイドのviews.pyを編集
viewsの中身をこれに書き換えます。
from django.shortcuts import render
from django.http import HttpResponse
import json
from django.views.decorators.csrf import csrf_exempt
from utils import message_creater
from line_bot_ai.line_message import LineMessage
@csrf_exempt
def index(request):
if request.method == 'POST':
request = json.loads(request.body.decode('utf-8'))
data = request['events'][0]
message = data['message']
reply_token = data['replyToken']
line_message = LineMessage(message_creater.create_single_text_message(message['text']))
line_message.reply(reply_token)
return HttpResponse("ok")
(いったん)公開用の設定
LLM抜きにとりあえずLINE上で動かせるようにします。
ngrokをインストール、設定
ngrokの公式サイトにログイン後、インストールします。
ngrokを起動し、以下のコマンドを入力します。
$ ngrok http 8000
コマンドを入力すると以下のような画面になるので、青枠で囲んだURLをコピーします。
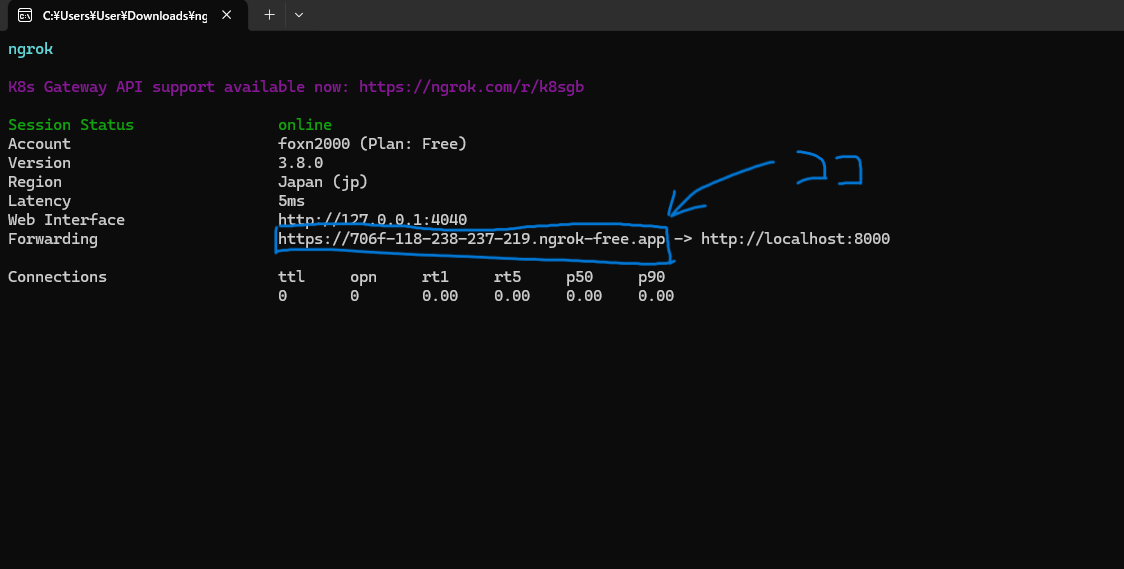
その後、プロジェクト(line_bot)の下にあるsettings.pyの中にあるALLOWED_HOSTSに以下の内容を記述します。
ALLOWED_HOSTS = ["先ほどコピーしたURLのhttps://より下の部分"]
#僕の場合だったら706f-118-238-219.ngrok-free.appを記述
Webhook URLの設定
LINE Developersのページに戻り、Messaging APIのWebhook設定のすぐ下の、Webhook URLの部分に、に先ほどコピーしたURLの最後に”/line_bot_ai/”を合体させたものを入力します。
(例:https;//706f-118-238-219.ngrok-free.app/line_bot_ai/ )

Webhookの利用がオフになっていたら、オンにし、検証を押して、ポップアップで「成功」と出れば、設定は成功です。
サーバーを動かしてみる。
プロジェクトディレクトリ(line_bot(上のほう)で以下のコマンドを実行し、サーバーを起動します。
友達追加をして、動かしてみましょう
$ python manage.py runserver
ローカルLLMが使用できるようにする
ここからはline botにLLMを入れて動かせるようにするセクションです。
まずはLLMをローカルで動かせるようにするためのライブラリをインストールします。
nVidiaのGPUがある人は一番下のtorchをインストールしてください。それがない場合は下から2番目のtorchをインストールしてください。
$ pip install transformers
$ pip install pipline
$ pip install protobuf
$ pip install accelerate
$ pip install sentencepiece
$ pip install torch ← CPU推論で動作させる場合。
$ pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 ← GPU推論で動作させる場合。
message_creater.pyの内容を作り変える
message_creater.pyの内容を以下のものに切り替えます。
今回使用するモデルは著者が開発したDataPilot/ArrowSmart_1.7b_instructionを使用してみます。
import torch
from transformers import AutoModelForSequenceClassification
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline #transformerとtorchがインストールされていることを前提とします。
model_path = "DataPilot/ArrowSmart_1.7b_instruction"#モデルを選択
model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
generator = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0)#推論デバイスを選択
torch.cuda.empty_cache()
def con(in_text):
text = generator(
f"ユーザー: {in_text} システム: ",
max_length = 100,
do_sample = True,
temperature = 0.7,
top_p = 0.9,
top_k = 0,
repetition_penalty = 1.1,
num_beams = 1,
pad_token_id = tokenizer.pad_token_id,
num_return_sequences = 1,
truncation=True
)
json_text = text[0]
result_text = json_text["generated_text"]
output_text = result_text.replace('ユーザー: '+str(in_text)+' システム:', '')#いらないところを消去
return output_text
def create_single_text_message(message):
res = con(str(message)) #推論
message_out = res
test_message = [
{
'type': 'text',
'text': message_out #メッセージに代入
}
]
return test_message
これに変更するとbotが文章を返してくるようになります。
初回ロード時にはモデルを読み込むため、時間がかかりますが正常です。
以下はGPT-4によるプログラムの解説
このプログラムは、テキスト生成のためのボットを作成するためのPythonスクリプトです。以下に、主な機能とその動作を説明します。
必要なライブラリのインポート
torch: PyTorchライブラリで、ディープラーニングの操作に必要です。
transformers: Hugging Face社が提供する、事前学習済みの自然言語処理モデルを簡単に利用できるライブラリです。
モデルの選択とロード
model_pathに指定された"DataPilot/ArrowSmart_1.7b_instruction"というパスから、因果関係に基づいてテキスト生成を行うためのモデル(AutoModelForCausalLM)と、それに対応するトークナイザー(AutoTokenizer)をロードします。
テキスト生成パイプラインの設定
pipelineを使用してテキスト生成のためのパイプラインを構築します。ここで、モデル、トークナイザー、およびデバイス(GPU)を指定しています。
GPUメモリのクリア
torch.cuda.empty_cache()を呼び出して、不要なGPUメモリを解放し、新しい計算のためのスペースを確保します。
テキスト生成関数(con)
この関数は、入力されたテキスト(in_text)に基づいて新しいテキストを生成します。
生成されたテキストは、入力テキストというプレフィックス"ユーザー: {in_text} システム: "を含んでいます。
生成後、不要なプレフィックスを取り除いて、必要な応答のみを返します。
メッセージ生成関数(create_single_text_message)
この関数は、ユーザーからのメッセージを受け取り、con関数を使用してそれに対する応答を生成します。
生成されたメッセージは、辞書のリストとして返され、それをチャットボットや他のシステムが使用できる形式にします。
このプログラムは、テキスト入力に対して自然言語での応答を生成するボットの一例を提供します。transformersライブラリのパワーを利用して、事前に学習された大規模モデルに基づいて新しいテキストを生成し、ユーザーとの対話を可能にすることが主な目的です。
終わり
ラインのボットでも、案外簡単に実装できました!