初めに
この記事を書こうと思ったのは、専門学校で同じような事をパワポで発表したからです。どうせなら、もっと分かり易くした上で、記事にしてしまおうと思い書きました。題名でGPUに詳しそうな感じをかもしだしていますが、別に特段詳しいわけでもなく、ただ単に気になったという理由です。ですので、間違っている可能性も十二分にあるので、参考程度で見て下さい。
この記事では、多少GPUについて知っておいた方が分かり易いと思います。ですが、余り知らない人向けにも、出来る限り分かり易く説明します。なので、若干に違う表現になっている場合もありますのでご了承ください。
さて、本題に入ります。HLSL・GLSL・CUDAなど、GPUに処理を書く上で、よくこの言葉を聞くのではないのでしょうか?結論としては「遅くなるから」です。でも、「なぜ?」とは思った事はありませんか?
HLSL・CUDAなど、GPUでのコードについてよく知らない人は、「GPUでは遅くなるからIFを使うなよ~」ぐらいの解釈でOKです。というより、それだけで十分です。よほど変態みたいなことをしない限り、理由を気にする事態になる事はほぼ確実にありませんから(笑)
説明(LV.1)
GPUとは?
CPUとは異なり、名前の通りグラフィカルな仕事をする部品です。詳しく言うと、出来る限り同時に画像処理・頂点変換・ピクセル計算などなど、これらの物量をこなすために使われる部品です1。
では、物量をこなすにはどうすればいいのでしょうか?・・・そうです。「目には目を物量には物量を」という事です。

ここでいう「職人」を本来は「スレッド」と呼びます。プログラマーならお馴染みですね。
職人(スレッド)の働き
会社にも働くルールがあるように、GPUの職人(スレッド)にも働くためのルールがあります。ここでは分かり易いように、「職人」を「会社員」と置き換えて説明します。
やはり、IF文がどのようにGPUで再現されているのかを知る必要があります。
ルールその1
1つの会社で、社員は全て同じ仕事をするわけではありません。いくつか部署に分かれて違う仕事をします。単純作業でも実際に行う作業は一つではありませんよね?

プログラマー向け
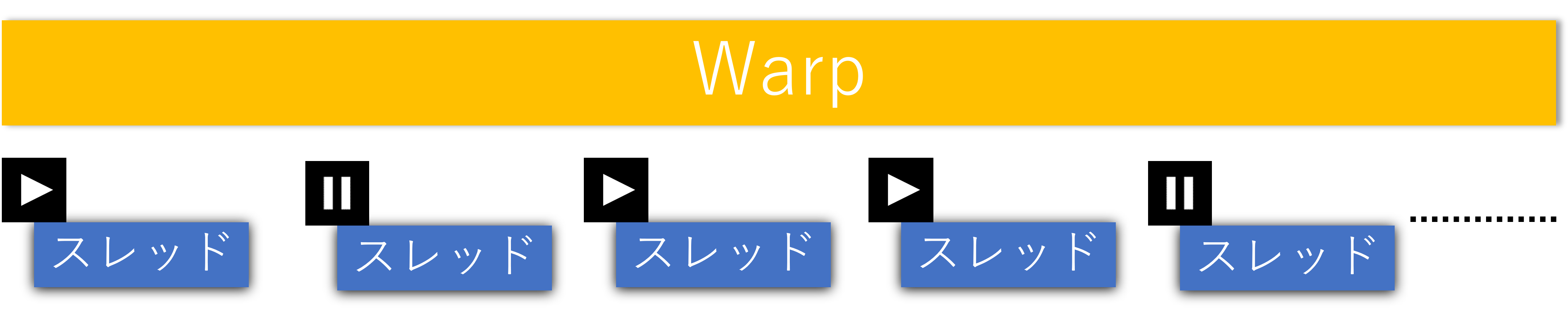
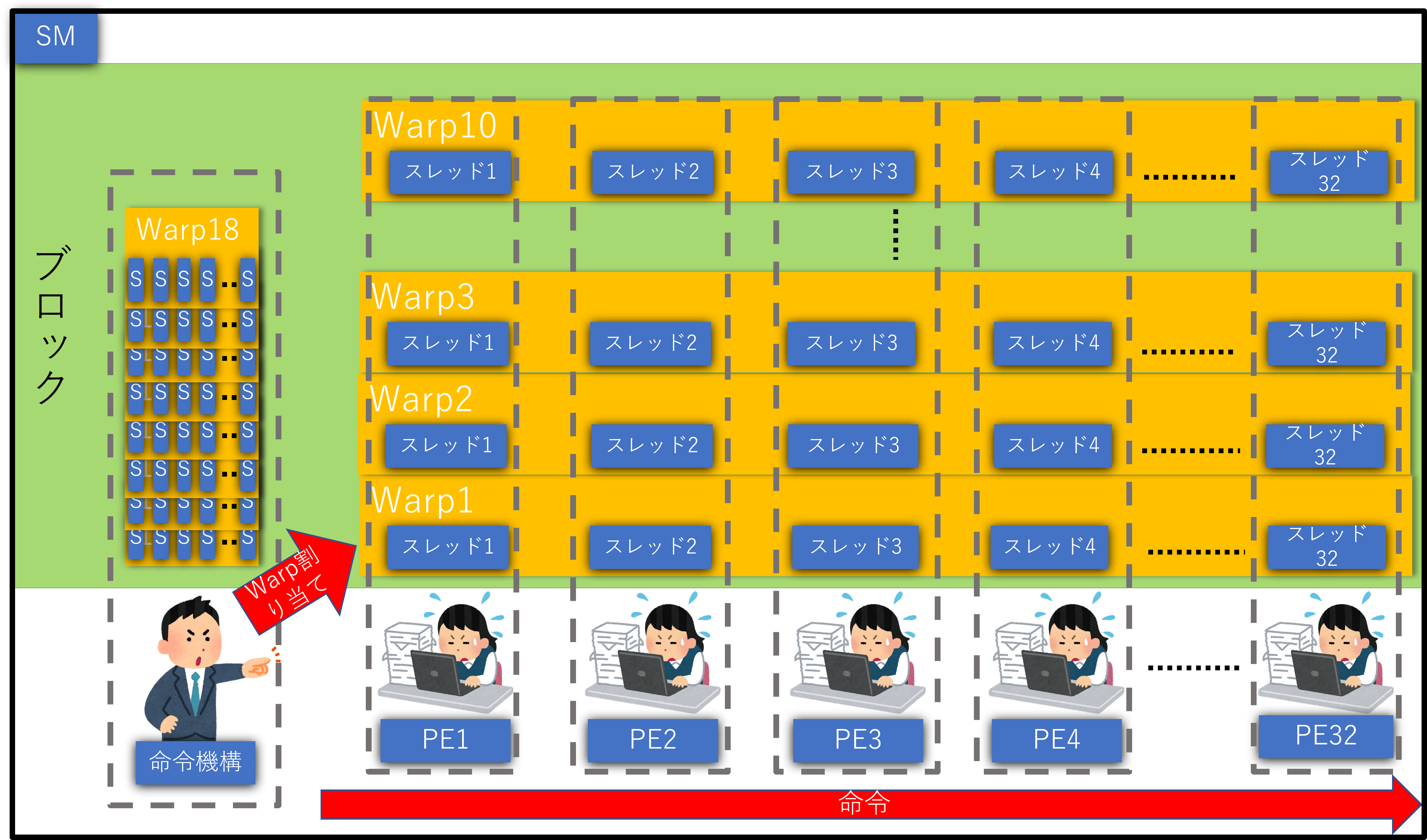
GPUには沢山のスレッドがある訳ですが、一つ一つ管理されている訳ではなく、32スレッドごとにまとめて管理されています。このまとまりを「Warp」と呼びます。(NVIDIA GPUの場合)
ルールその2
この会社では社長が部署ごとに「1つ」の仕事を割り振り「命令」を下します。ワンマン社長ですね。その命令を受けて、各部署全員が出された仕事を同時にこなします。決して、部署内で別々の仕事をする事は無く、全員が同時に仕事を開始します。
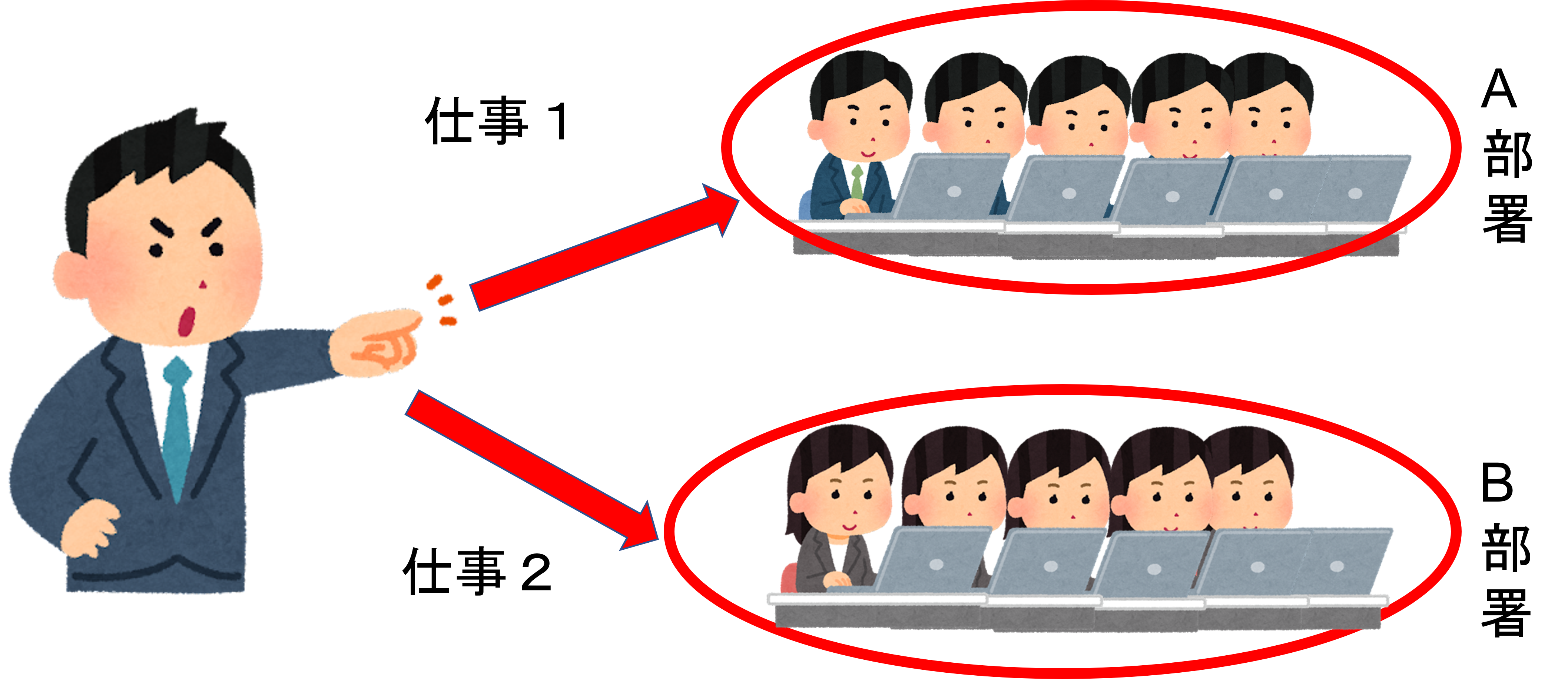
プログラマー向け
GPUは基本「1つの命令」に対し「スレッド」は同じ処理しか出来ません。同じ処理を命令させるので当たり前ですが。
というのも、GPUでは頂点計算・ピクセル計算のように、同じような処理をするにもかかわらず、1Threadずつ命令して実行するのは余りにも非効率なうえに、命令ユニットも演算器の数も全く足りなくなってしまうからです2。

ルールその3
この会社では効率化の為に、社長が判断して不要な仕事は社員にやらせず、別の仕事を割り振ります。社長自ら働く素晴らしい会社ですね。
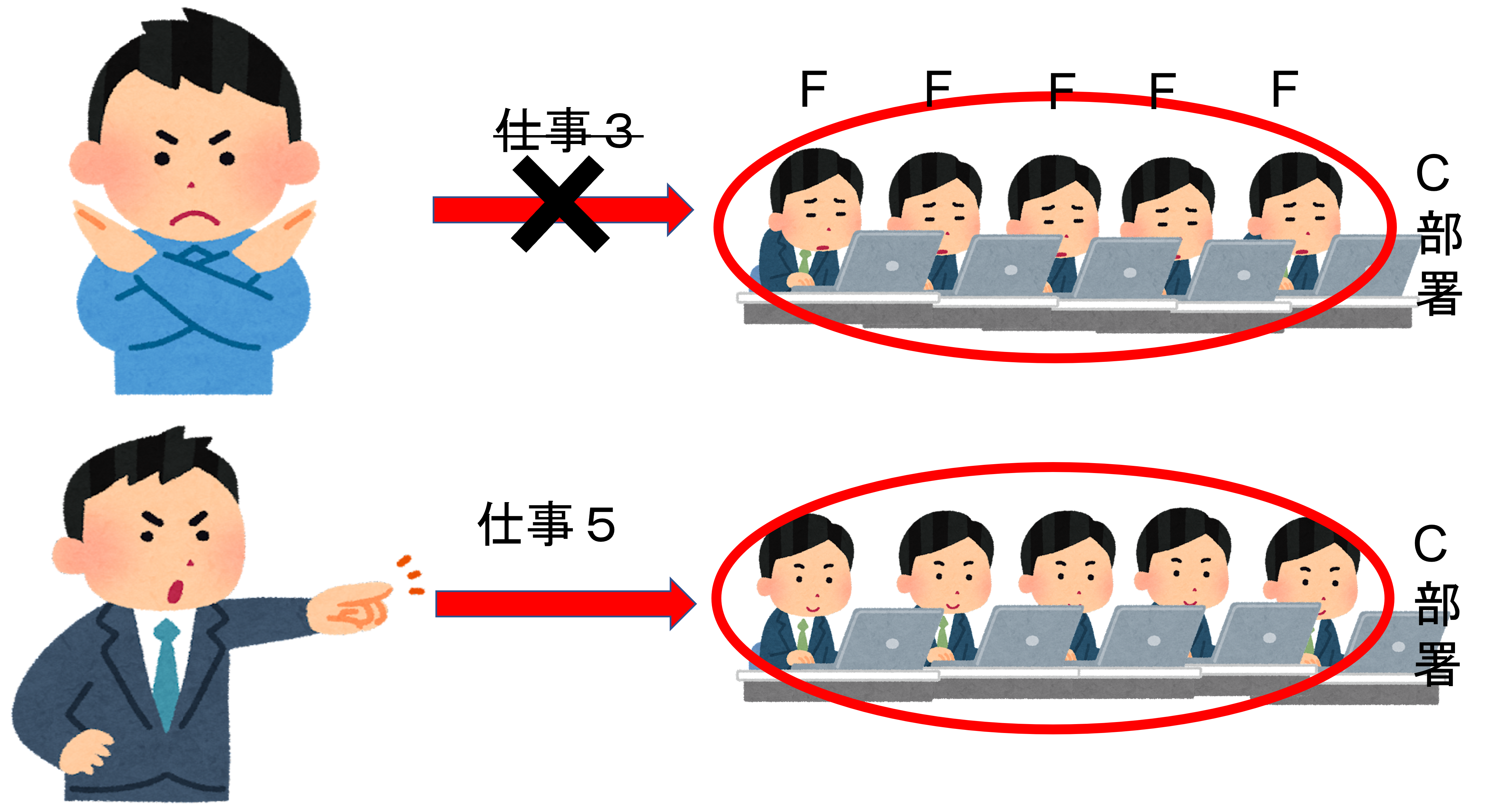
プログラマー向け
これはWarp全体での「IF(条件式)」の判断し処理を省略します。
後述しますが、Warp全てのスレッドでFalseになる条件の場合、各スレッド実行前に命令ユニットが判断する事によって、「各スレッドでFalseの判断を下して「処理をしない」とする判断」こと自体が省けます(演算器側での判断)。その場合、条件終了後の処理(Trueになった場合の処理終了後)の命令を実行します。
ルールその4
何とこの会社では、一部の社員が「この仕事は不可能な状況だ」と判断すると、その社員はサボることが認められます。羨ましい?ですね。
- 社長「え?不可能な仕事を持ってくるな?いやいや、他の社員は出来ているではないか。」
- 社員「そんなぁ~。」
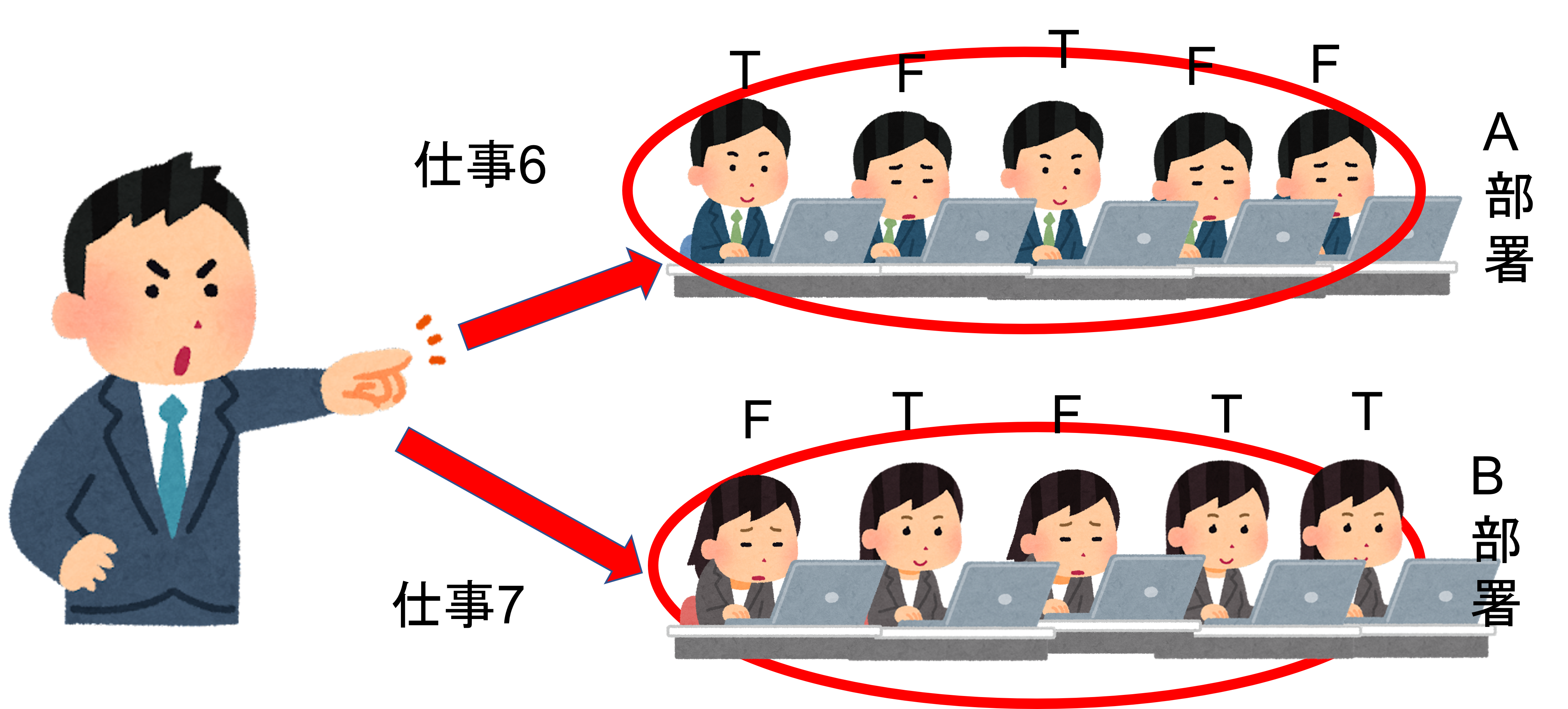
プログラマー向け
ルール3では、Warp内全てのスレッドがFalseの場合は、Trueになった場合の処理が省かれて処理後の命令を下しました。では、全てFalseにならず、一部スレッドだけTrueの条件がある場合はどうなるのでしょうか?
答えは「Trueになったスレッドのみを処理させ、Falseのスレッドは待機させる」です。そして、True側のスレッドの処理が終わり次第、Falseのスレッドの待機を解除し、全てのスレッドを処理します。
まとめ
以上の4ルールを守って、GPUの職人は働いています。勿論、同時に働く職人が多ければ多いほど、効率は良くなります。その為、サボっている職人が多ければ多いほど、効率が悪くなってしまいます。つまり、速度が落ちるという事です。
例えば、単純作業において、全力で働いて仕事を完遂させるのと、半分の力で働いて仕事を完遂させるのでは、どちらが速く終わるでしょうか?そういう事です。
プログラマー向け
GPUのシステム上、「1つの命令で複数のスレッドを動かして」います。その為にルール4での弊害が発生してしまいます。勿論、「1つの命令」=「1つの処理方法」なので、「1Warp」内の全てのスレッドは「別々の処理」をさせる事は基本不可能だからです。
ルール4に補足を付け加えるなら、たった「1スレッド」Trueの条件になってしまった場合であっても、必ずTrueのスレッド以外は待機します。そして、そのスレッドの処理が終了しだい、元のスレッドの待機を解除して全て同時に実行します。1人の為に他の31人は待機するという事です3。理由は分かりますよね?
詳しく知りたい人向け(LV.2)
これ以降は、「GPUの紹介+IF文」といった感じで紹介します。因みに、本記事ではCUDAの処理方法をメインに説明します。というのも、資料が沢山ある上に分かり易いからです。
通常、「スレッドの管理」などはGPU側で行いますが、スレッドの呼び出す数などいくつかの部分は、ユーザー側の管理になっている事が多いです。例えば、CUDAは「グリッド数」と「ブロック数」をユーザー側で指定します。他にも、OpenCLは「スレッド総数」と「スレッド全体を何分割するか」を指定したりします。
GPUは多次元で分割されている
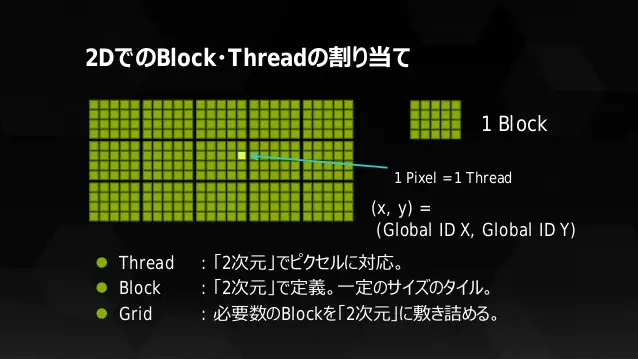
CUDAでは「複数のスレッド」をまとめているモノを「ブロック」と呼びます。更に「複数ブロック」をまとめているモノを「グリッド」と呼びます。CUDAを勉強している方ならご存じですよね?正確に言いますと、スレッドはWarpで固められているので「グリッド > ブロック > Warp > スレッド」という関係性になります。下記の画像はあくまでもイメージです。「図形の数=実際の数」ではありません。
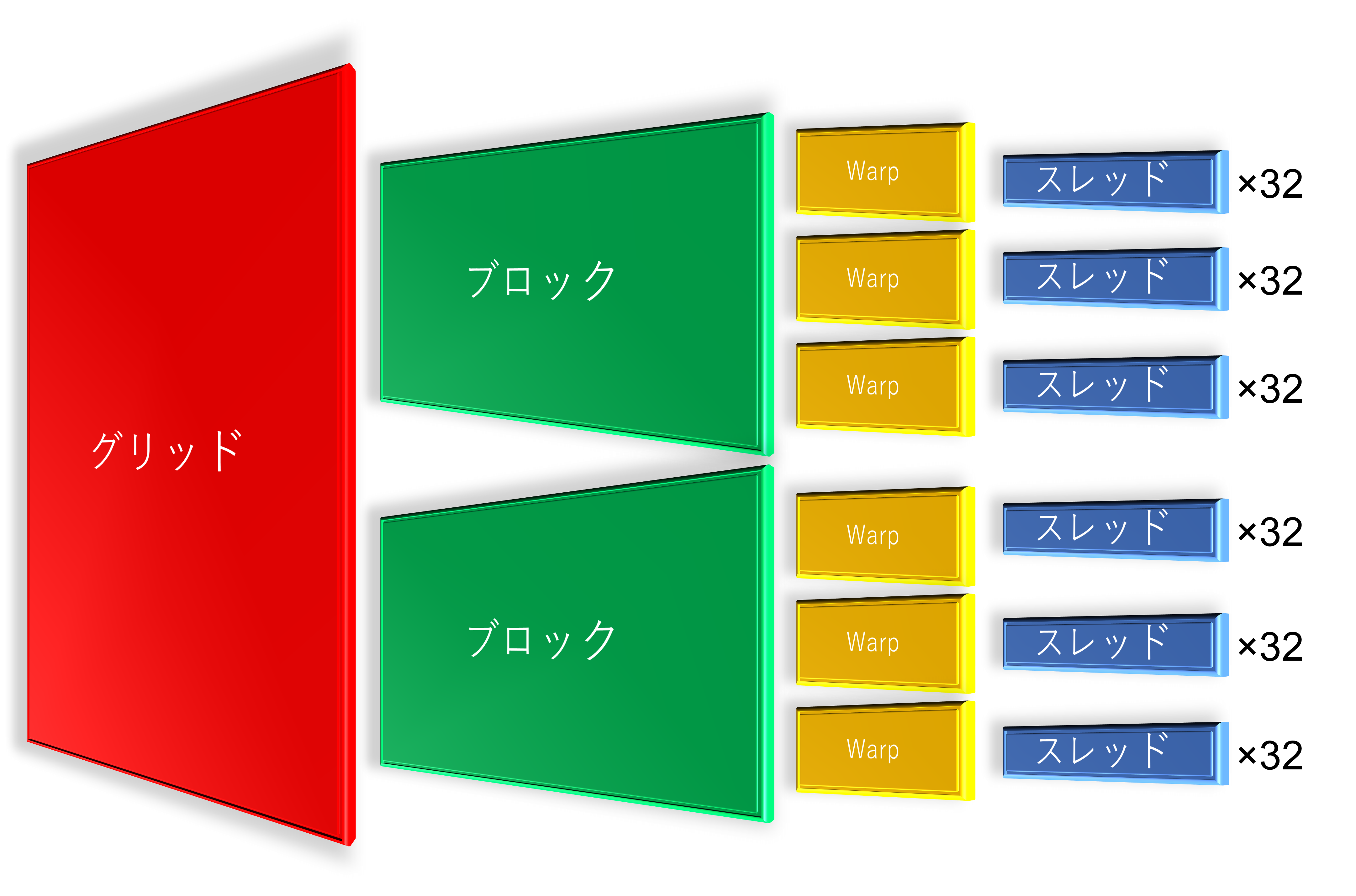
ここで少しややこしいお話なのですが、実はブロック・スレッドは「3次元」として管理されています(ソフトウェア的な概念に近い?)。上記の画像が3Dで描かれているのは伏線でした。
LV.1で説明されていた例を当てはめると...
- 会社(社長)= ブロック
- 部署 = Warp
- 会社員 = スレッド
に当たります。つまり、「会社」の上には「社会」という名の「グリッド」がある訳ですね。
GPUのハードウェア的なあれこれ
これだけ見ると、結構シンプルに見えるのですが、実際にはハードウェア(GPU)が関係してきます。実は先ほど「会社(社長)」としたのですが、正確には別です。
というのも、「複数のブロック」を管理しているのは「グリッド」なのですが、ハードウェア的には「SM(ストリーミング並列プロセッサ(Streaming Multiprocessor))」によって、1つブロックを処理します。勿論、SMも複数個あるので、それらを管理しているのはどこかというと、「Giga Thread Engine」によって「複数のSM」の動作を管理しています。
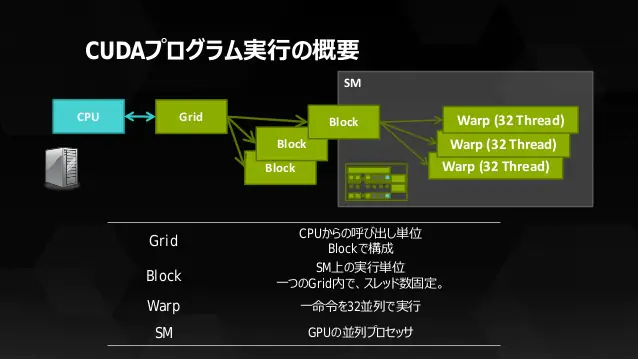
※画像の参照元(P.34)
ソフトウェア・ハードウェアの管理
はい、訳が分からなくなってきましたね。分かります。ここで一旦整理しましょう。
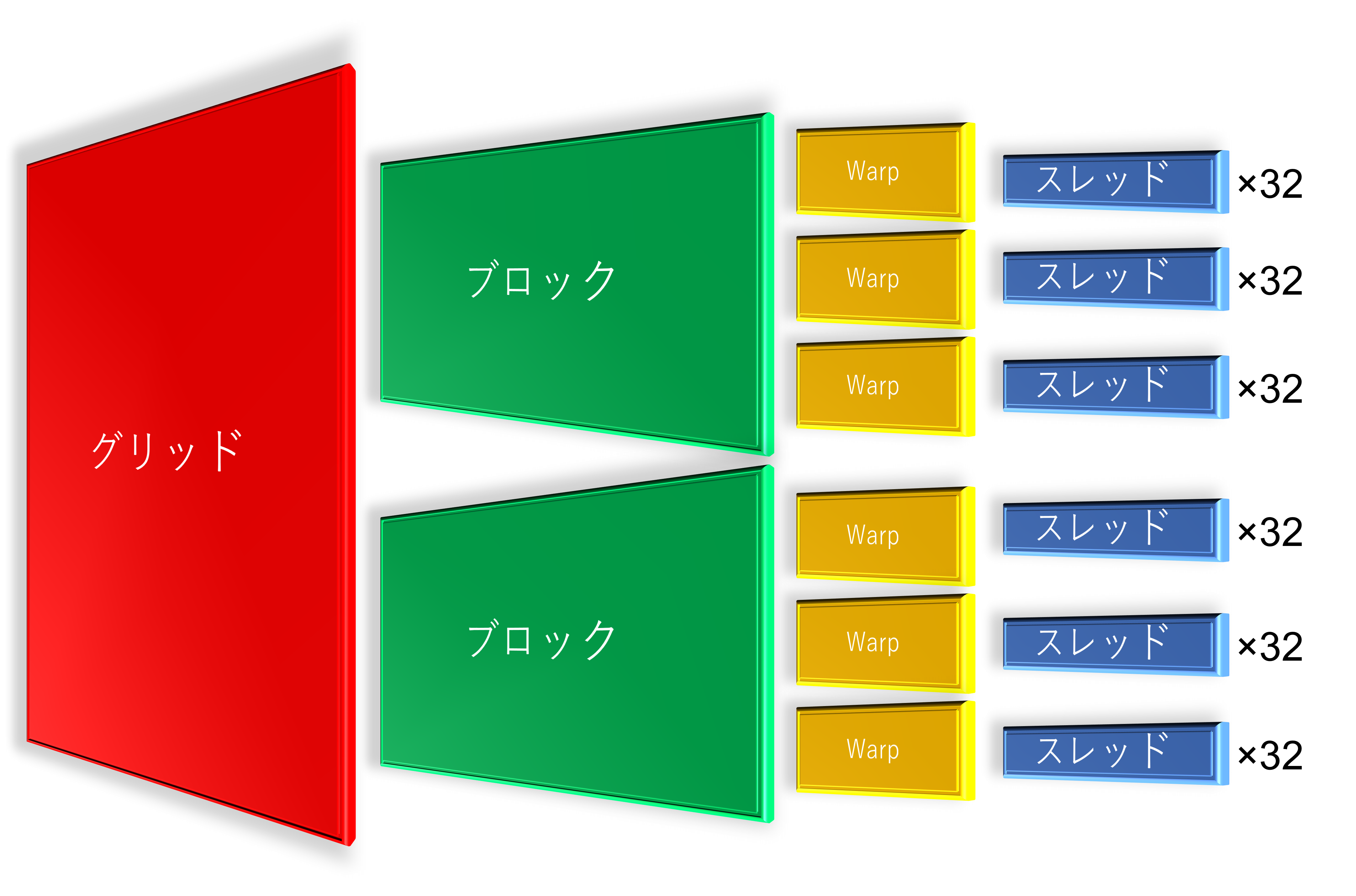
スレッドはWarpによって管理され、Warpはブロックによって管理され、ブロックはグリッドによって管理されています。「グリッド > ブロック > Warp > スレッド」です。簡単ですね。
ですが、これはあくまでソフトウェア的な考え方であって、ハードウェアとなると話が変わってきます。つまり、「仕事」と「人」で管理方法が異なるという事です。LV.1の例で説明しましょう。
仕事
今までは会社員として説明してきましたが、ハードウェア的な概念が混じると説明出来ないので、分解します。会社員はいわゆる「労働(仕事)」をする「人」です。ここでは「労働(仕事)」についてです。
「1つの仕事」は「1つスレッド」として扱われます。ここに「仕事=スレッド」条約が締結されました。
前述している通り、仕事は1種類だけではなく、いくつも種類があります。種類ごとに仕事をまとめる場所として「部署(Warp)」があり管理をします。更に、部署は「会社」で管理されています。これがソフトウェア的な考え方になります。
ですが、これでは会社として機能(活動)出来ません。「会社」と「会議室などの部屋」があるのに「仕事をする人」が存在しないからです。まるで、ペーパーカンパニーです。

人
ここでは「仕事をする人」についてです。「1人」はGPUの場合「演算器」と言えます。CUDAで言うと「CUDAコア」になります。勿論、「一人」だけでは働けないので仕事を与える必要があります。
それが「部署長」つまりSMになります。そして、「部署長」には複数人をまとめて管理出来る能力がありますが、「部署長」は「1つの命令」を「全員へ発行する」という管理を行っています。実は社長と会社員の間に部署長が隠れていたわけですね。
なので、複数で別々の命令を出したい場合、複数のSMが必要になってきます。複数存在する場合やはり、それらを管理する必要があるので、Giga Thread Engineつまり「社長」によって管理します。各SMで勝手に命令を出されては大変な事になってしまうからです。これが、ハードウェア的な考え方になります。
ですが、これも同じくこのままでは会社として機能(活動)出来ません。当たり前ですが、命令を下すための「仕事」が無いからです。
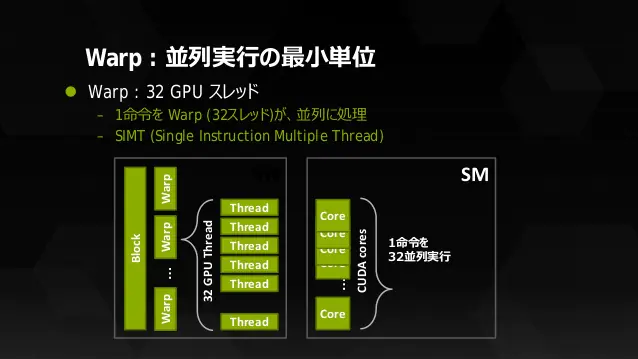
※画像の参照元(P.31)
上記の通り、「人」と「仕事」の両方あってこそ存在出来る「会社(GPU)」です。違いが分かってもらえたでしょうか?
SMはブロックをどう処理するか
少しおまけなのですが、SMとブロック間で必ず守らなければならないルールが存在します。
- 1つの
SMで実行されるブロックは1つ - 1つの
SMに複数のブロックが同時に存在出来る
以上です。これらのルールを守って処理していきます。
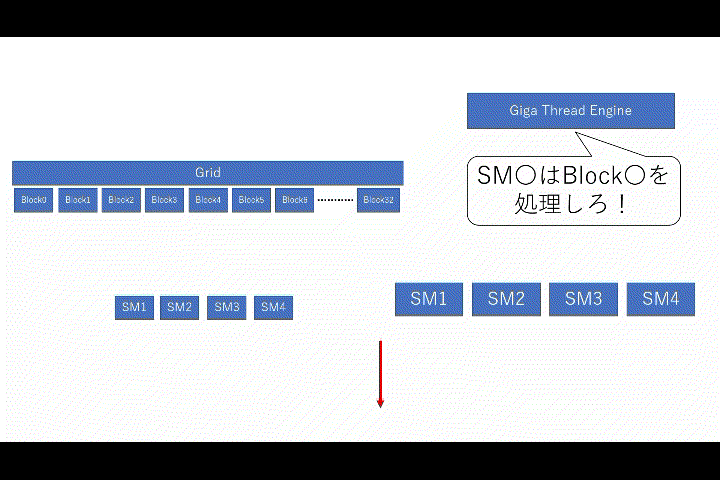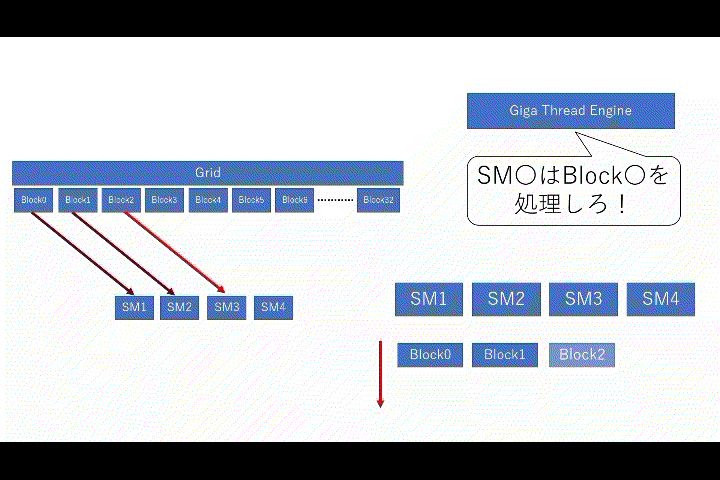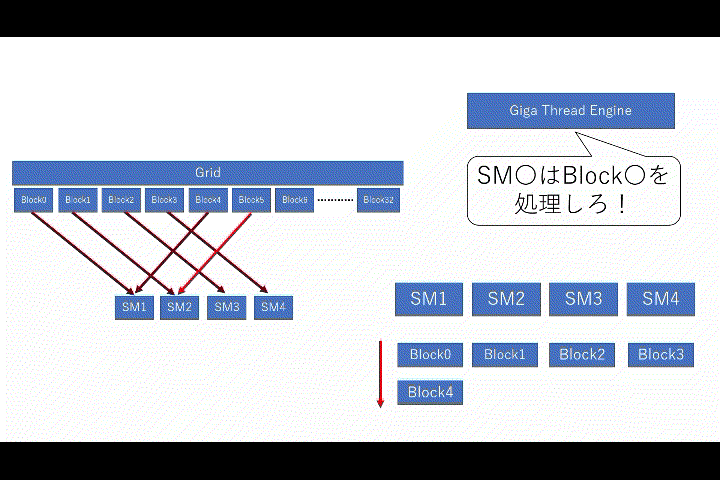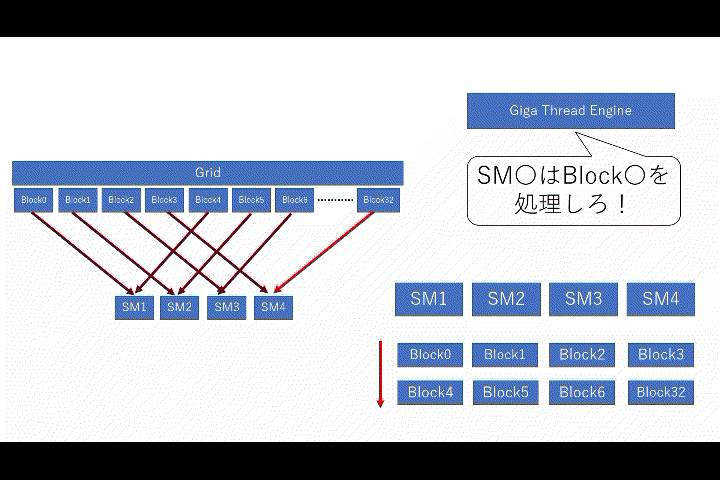
イメージ的には上記のようになります。ただし、ブロックの実行順序は保証されず、特定のSMへのブロック割り当ては出来ません。あくまでイメージ図です。更に、ルールで書かれていた通り、SMで実行されるブロックは必ず「1つ」なので、実行中に新しいブロックが来た場合は待機する事になります。
つまり、社長は部署長が今すぐ仕事出来るかを気にせずに仕事を投げていたわけです。勿論、今すぐ処理が出来ない場合はどんどん処理(タスク)が積み重なっていきます。
GPUの目的
ここで改めて目的について触れますが、GPUで処理するのは頂点計算・ピクセル計算などの「同じ処理ばかりなのでまとめて処理してしまおう」=「1つの命令で複数のスレッドを処理しよう」という考えからきています。この考えを、「Single Instruction Multiple Thread (SIMT)」と言います。
つまり、SIMTの言いたい事は「1頂点=1スレッド、1ピクセル=1スレッドで処理しよう」という事です。しかし、全てのピクセル・頂点で行う処理は出力結果が異なるだけで実行処理は全く同じですよね?なので、「1つの命令で複数のスレッドを使い処理しよう」という事です。
このように、「1つの命令で複数のスレッド」を扱う単位をNVIDIAは「Warp」と決めました。やったー、これで命令処理の手間が圧倒的に省けるぞー(棒)
※画像の参照元(P.58)
あ、UFOのワープとは関係無いですよ。
IF問題
ですが、現実問題として全く同じ実行処理では済まない場合が多いと思います。プログラミングには欠かせない「IF文」です。このままでは1つのWarpの中に、条件が成立するスレッドと不成立のスレッドが混在してしまい、同じ処理が出来ないではありませんか。
そこで考え出されたのが「スレッド自体に処理実行の可否判断をさせればいいじゃないか」という方法です。そうする事で、疑似的に同じ処理をさせる事が可能になるからです。つまり、条件が不成立の時だけ実行処理を無視するという事です。ですが、「無視するだけで速度が速くなる訳ではない」ので注意して下さい。
言い換えると、1ピクセル毎に実行処理の可不可を判断し、実行出来ない場合は「1ターンお休み」をします。(節電の為に読み出し処理や計算を止めるからです)
まとめ
このように、GPUにとってのIFがどれだけ厄介かをご理解いただけたのではないのでしょうか?これだけ書いてあれですが、分からなくても問題ありません。タイトル通り「GPUでIFを使うな」を覚えてもらえれば大丈夫です。プラスαで覚えてもらうならば、「IFを使うとしても、出来る限り短く書け」といった感じです。
もっと詳しく知りたい人向け(LV.3)
これ以上知りたい人はかなり少ないと思いますが、GPUのマルチスレッド方法・実行ユニットにも踏み込んでいきます。
改めて注意
ここで本音を吐くと、私なりに理解して考えまとめた上での記述なので、勘違い・間違いの可能性は普通にあり得ます。何度も言いますがその点をご理解した上でご覧ください。最終的にはご自身で判断いただくようお願いします。参考サイトは一番下に書いてありますので、それも参考にして下さい。
スレッドのフリーズ対策
実は、LV.1の会社員について少し修正する事があります。普通、会社員が仕事をする時は何か道具を使いますよね?会社員の例ではパソコンでしたが、GPUでは実行ユニット(以降は「PE」とします)に当たります。このPEがやっていることは演算処理やレジスタでのロード/ストアなどの処理です。
それだけならいいのですが、ご存じの通り、演算処理にしろロード/ストア処理にしろ絶対に処理時間がかかります。するとどうでしょうか?次の命令実行まで待機する羽目になってしまいます。パソコンで例えるならフリーズ状態です。
こんなことは許されません、作業が止まってしまいます。ですので、それらを回避する為に、PEごとに複数のスレッドを持ち、処理待ちしている間、別のスレッドを実行するという手段をとっています。そして、別のスレッドへ・・・別のスレッドへ・・・を繰り返し、最初のスレッドに戻ってきている時には、既にそのスレッドでの処理を終えているという算段です。
会社員の例で例えると、1台目のパソコンに仕事内容を入力して結果が返ってくるまでフリーズ、直ぐに2台目を使って仕事内容を入力→結果待ち、3台目入力→結果待ち・・・。手持ちのパソコンを全て入力し終えたので、1台目に戻ってくると既に結果が表示されている。といった感じになるでしょうか。
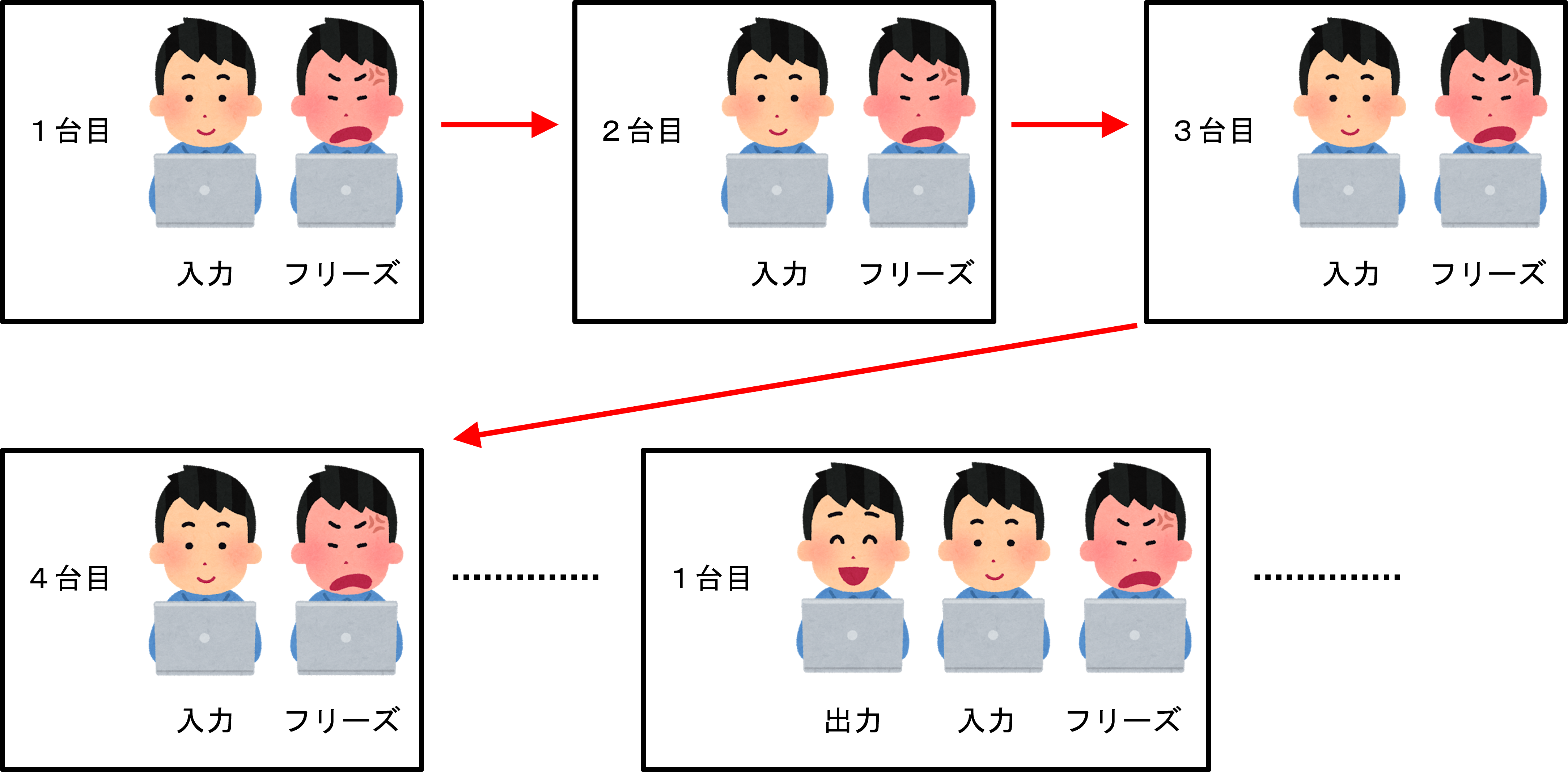
つまり、この会社の会社員全員に約10台のパソコンが配られるようです。現実ならそんなに要りませんが(笑)
LV.1での説明では一人当たり、約1スレッドを持っている表現をしました。ですが実際には一人当たり約10スレッドを持っています。簡略化の為に省略したので、ここで報告します。

実行ユニットの動き
今度は実行ユニット(PE)視点からの「IF」問題を見てみましょう。
さて、PEが大量に集まったものがGPUとも言えるわけですが、何度も言っている通り、GPUには同じ処理を行うことが多いです。なので、「どうせ同じ処理しかしないから、命令機構は1つでいいだろ」と思うかもしれません。ですが、GPU君にとって難敵「IF問題」などがあるので、ある程度自由に出来た方が良いわけです。ここでは、スレッド=PEとして扱います。
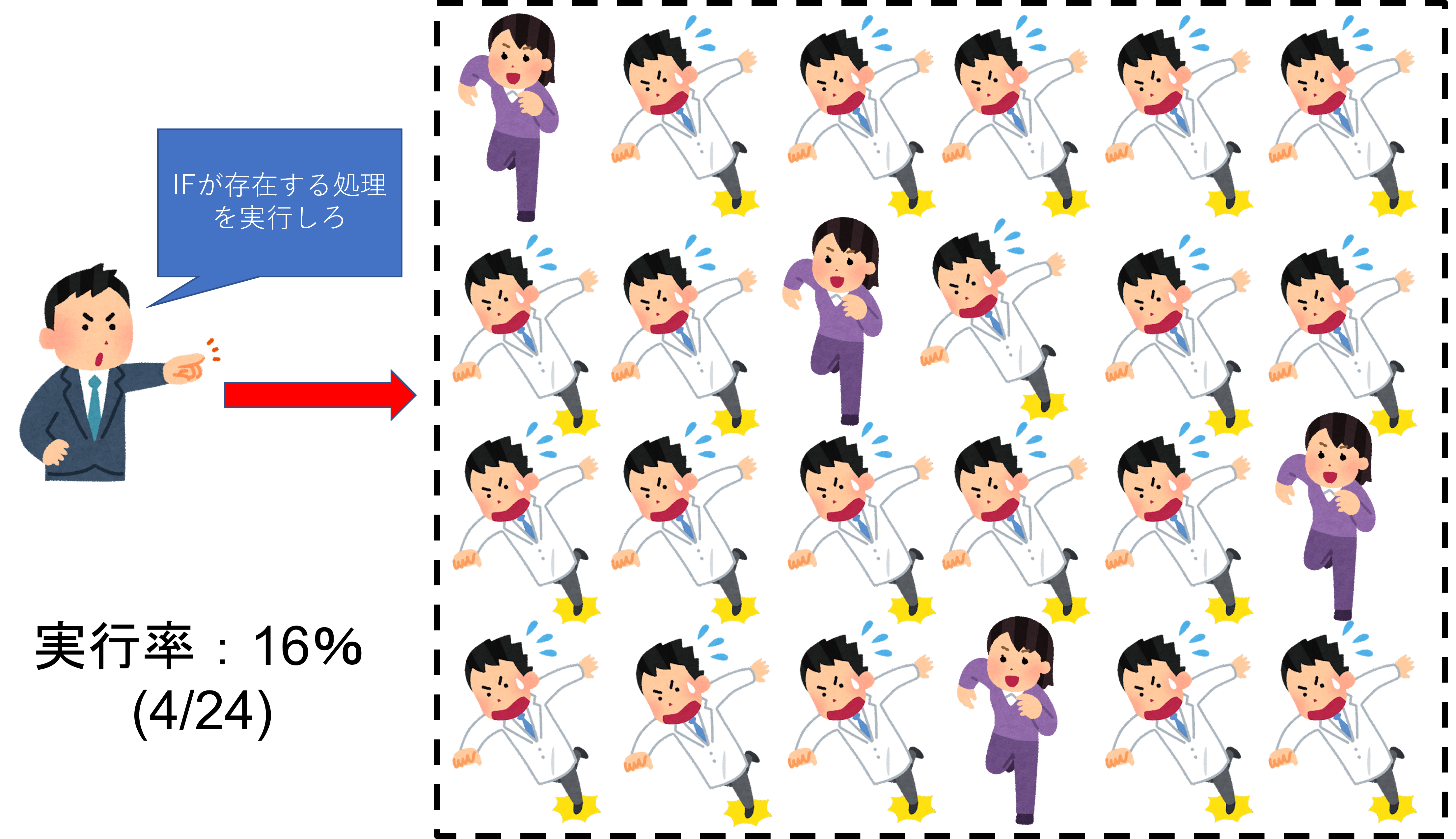
上図で分かると思いますが、何度も言っている通り、IFが存在する場合は「条件が成立するPE」と「不成立のPE」が混在してしまう可能性が非常に高くなってしまいます。そして、「1つの命令」に対しては「同じ処理」しか出来ません。例え1つでも「条件が成立するPE」が存在してしまうと、他の「不成立のPE」の処理が全てストップしてしまいます。
つまり、何万・何十万ものスレッドに対して命令機構が1つだけだと、他の「不成立のPE」が全てストップしてしまいかねません。これでは大量に同時並行で処理出来るGPUの強みが無くなってしまいます。全く笑えません。
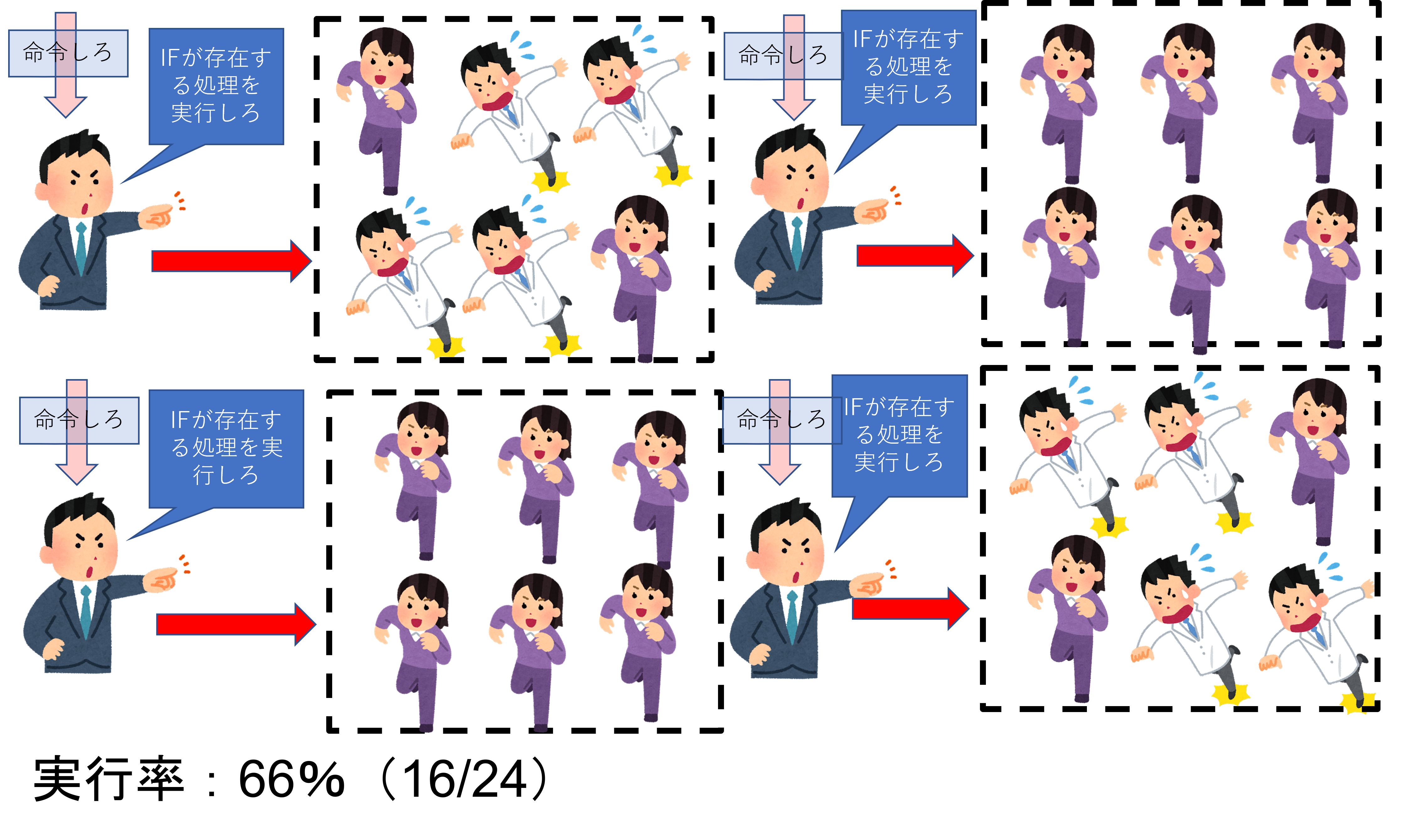
上図のように、命令機構を複数個用意して、「全て」ではなく「一定数」のPEに対し1つ命令機構を付けます。こうする事で、命令を分割する事が可能になり、ストップする影響範囲が「1命令単位」で済みます。すると、全体的に動くPEを増え実行率が増加する訳です。ただし、命令機構へ「命令」を出す「命令機構」が必要になります4。組織である以上は統率する者は必要ですので。
兎にも角にも、比較的まだ「まし」になります。決して「GOOD!」とは言えませんが。
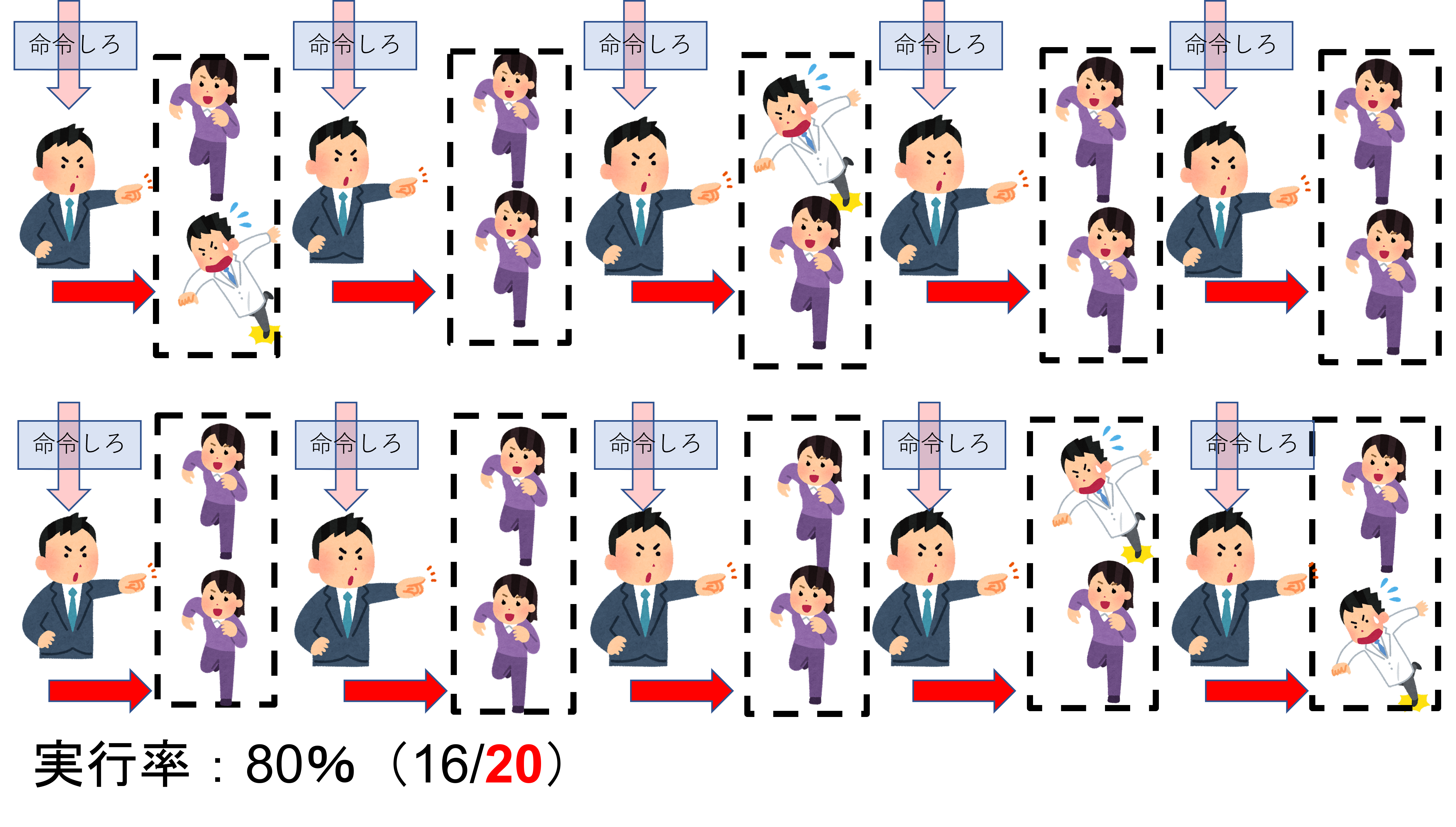
ならば、「命令機構を増やせばいいじゃないか」となるかもしれませんが、上図のように命令機構を増やしすぎると、逆に全ての命令機構に命令する手間・時間が増え、実行率は上がるものの、実行するまでに時間がかかるという事になります。これではあまりにも手間がかかってしまい非効率になってしまいます。更に、命令機構を増やすという事は「物理的」に機構が増えるのでGPU自体が大きくなってしまいます。となると、PEか命令機構もしくは両方を減らさざる負えなくなってしまい、これでは本末転倒です。5
つまり、命令機構とPEのバランスが大事になってきます。実際に、NVIDIAは32PEごとに命令機構を搭載し、AMDは64PEごとに搭載しています。
「Streaming」で「Multi」な「processor」
ここの欄について
私がいくつかの記事から考察して記述しているので、間違えの可能性が十二分にありえます。
先ほどからSMと何度も記述していますが、略さずに言うと「Streaming Multiprocessor」です。でも、よく考えてみて下さい。
- Multi = 複数の
- Processor = 処理装置
- multiprocessing = 複数の並行プロセスを同一システム内で使用すること6
では残りの「Streaming」は何でしょうか?この言葉、近年では「ストリーミング再生」のように、よく聞く言葉ですよね?単語自体は簡単に調べた限り「流れ」が近いでしょうか。プログラムが処理されることを「流れ」と言っているのでしょうか?私は違うと考えています。むしろ、「流れ」より「逐次」の方が意味的には近いと思っています。といっても、英語では「Sequential」になってしまいますが...7。
前述したスレッドのフリーズ対策の時に記述しましたが、1つのSMは複数個のスレッドを管理しています。ですがその時に「チョッ マテヨ」と感じた方はいましたか?
- 32実行ユニットごとに命令機構を搭載している
- 実行ユニットは複数のスレッドを管理している(大体10スレッド)
-
Warpは32スレッドで、それが実行の最小単位になっている -
Warpは「1命令を32並列」で実行されている
あれれぇ~おかしぃ~ぞぉ~?命令を実行しているのは「複数のスレッド(約10スレッド)を持つ複数の実行ユニット(32PE)」なのに、実行の最小単位はWarp(32スレッド)ではありませんか。
つまり、実行の最小単位はWarpであるにもかかわらず、複数の実行ユニットが複数のスレッドを持っている上で実行している事になっています。訳が分からなくなってきました。
こういう時こそ落ち着きましょう。素数を数えましょう。0,0,0,0,0,0,0,0...。失礼しました。
私の考えは、あくまでもWarp(32スレッド)= 複数の実行ユニット(32PE)です。Warpは複数あり、1実行ユニットも約10スレッド持っている。つまり、1度に複数個のWarp(約10Warp)を実行しているのではないかと考えました。
更に、「1SMは1ブロック(複数個のWarpの塊)のみ処理」されますよね。そうです、複数個Warpがあるので、それが実行ユニットの複数のスレッド分だけ複数のWarpが実行されるという考えに落ち着きました。
上図を見て頂ければ大体私の言いたい事が分かると思います。これらの事を「IF」とからめると、命令機構はWarpごとに命令しますが、あくまでも、別のWarpには影響せず、その1Warpのみ影響します。そして、影響する時間は他のWarpの処理が終わり1周回ってくるまでです。これは、ボードゲームの「1ターンお休み」がイメージとしては一番近いと思います。
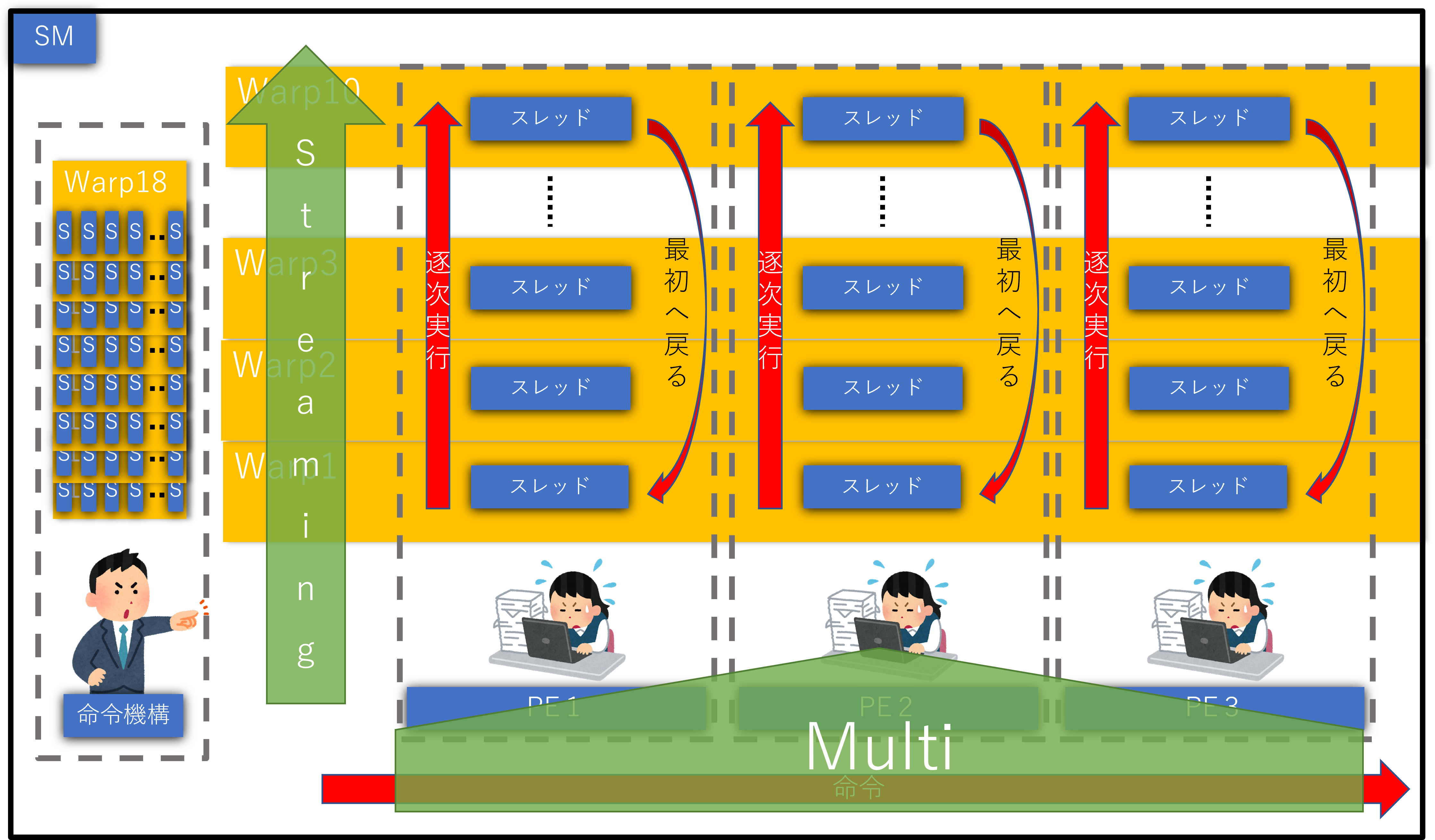
上図のような感じでPEが管理しているスレッドを「逐次」実行していき、SMが管理しているPEを「複数同時」に「処理する装置」だと私は考えました。これぞまさしく「Streaming」で「Multi」な「processor」です。
これらの事は、他の記事では完全に省略して記載していると思います。どう考えてもややこしくなり過ぎますからね...。以上、私の考察でした。
まとめると・・・?
- 1つの実行ユニットは「複数のスレッド(約10スレッド)」を管理
- 命令機構は「32」実行ユニットごと
-
Warpも「32」スレッドごと -
Warpは「1命令を32並列」で実行
何となく分かってきましたよね?更に言葉を付け加えると...
-
Warpを複数個まとめたものが「ブロック」 - ブロックは
Streaming Multiprocessor(SM)で管理。つまり下請けです。 - 複数の
SMは「Giga Thread Engine」で管理。つまり元請けです。
以上の事を踏まえて、画像処理でGPUの働きをまとめると、以下のようになります。
パート1
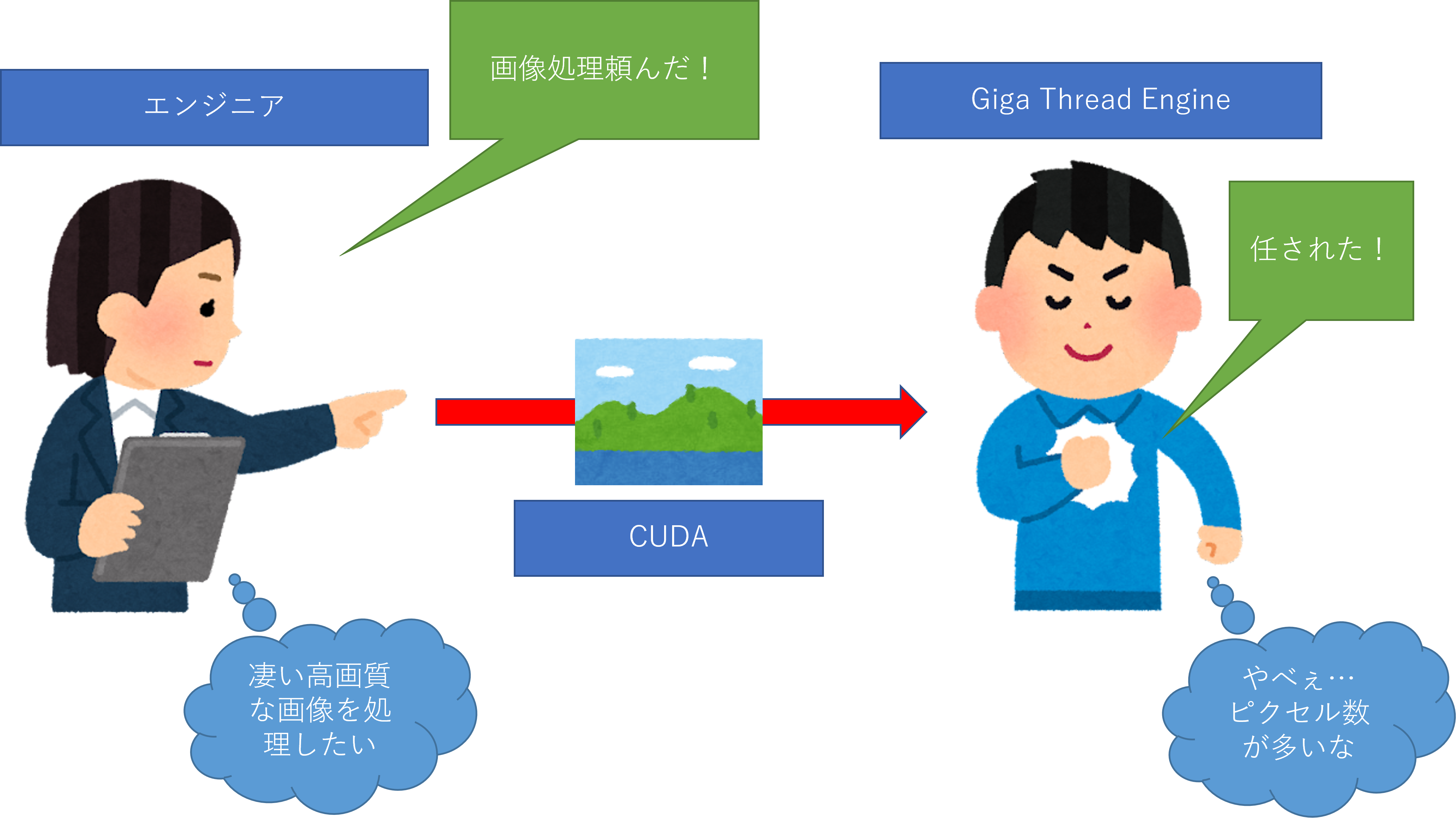
かなり適当ですが、エンジニア(発注主)が画像処理をGPUに投げる場合、CUDAはメンドクサイ処理などを内部でやってくれます。その為のライブラリなんですが(笑)
さて、今回はCUDAを使って処理するとしましょう。プログラム上で「実行関数」が呼び出されると、「Giga Thread Engine」君が「任された!」と処理を開始します。
パート2
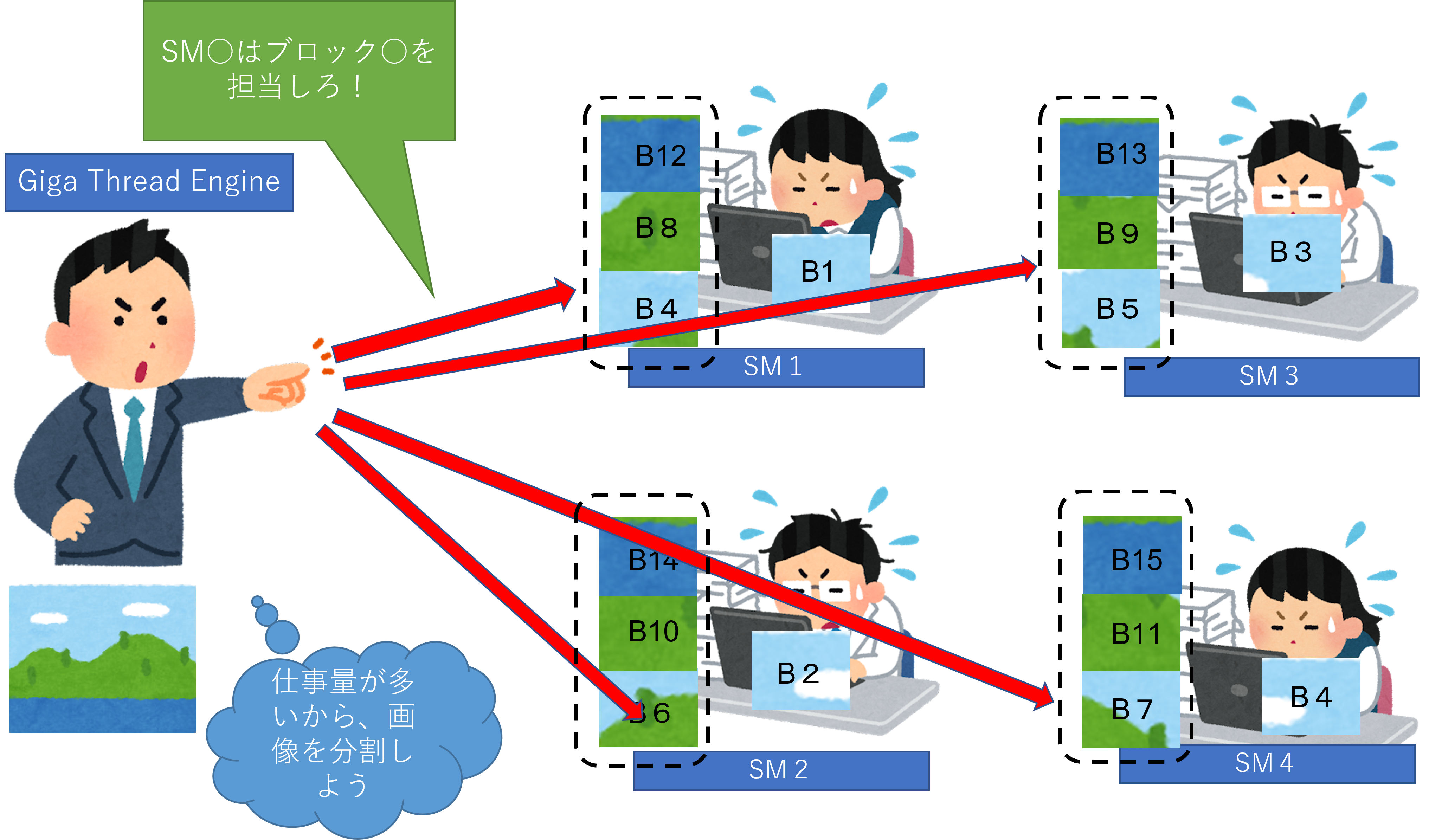
「Giga Thread Engine」は画像を分割して処理しようとします。画像を分割した物を「ブロック」として処理します。その分割したブロックはSM達へ仕事として渡されます。ですが、1つのSMでは「1ブロック」しか処理出来ないので、他のブロックはタスクとして待機します。上図では点線に囲まれた画像の事です。
※ 各ブロックの数字はランダムです。
パート3
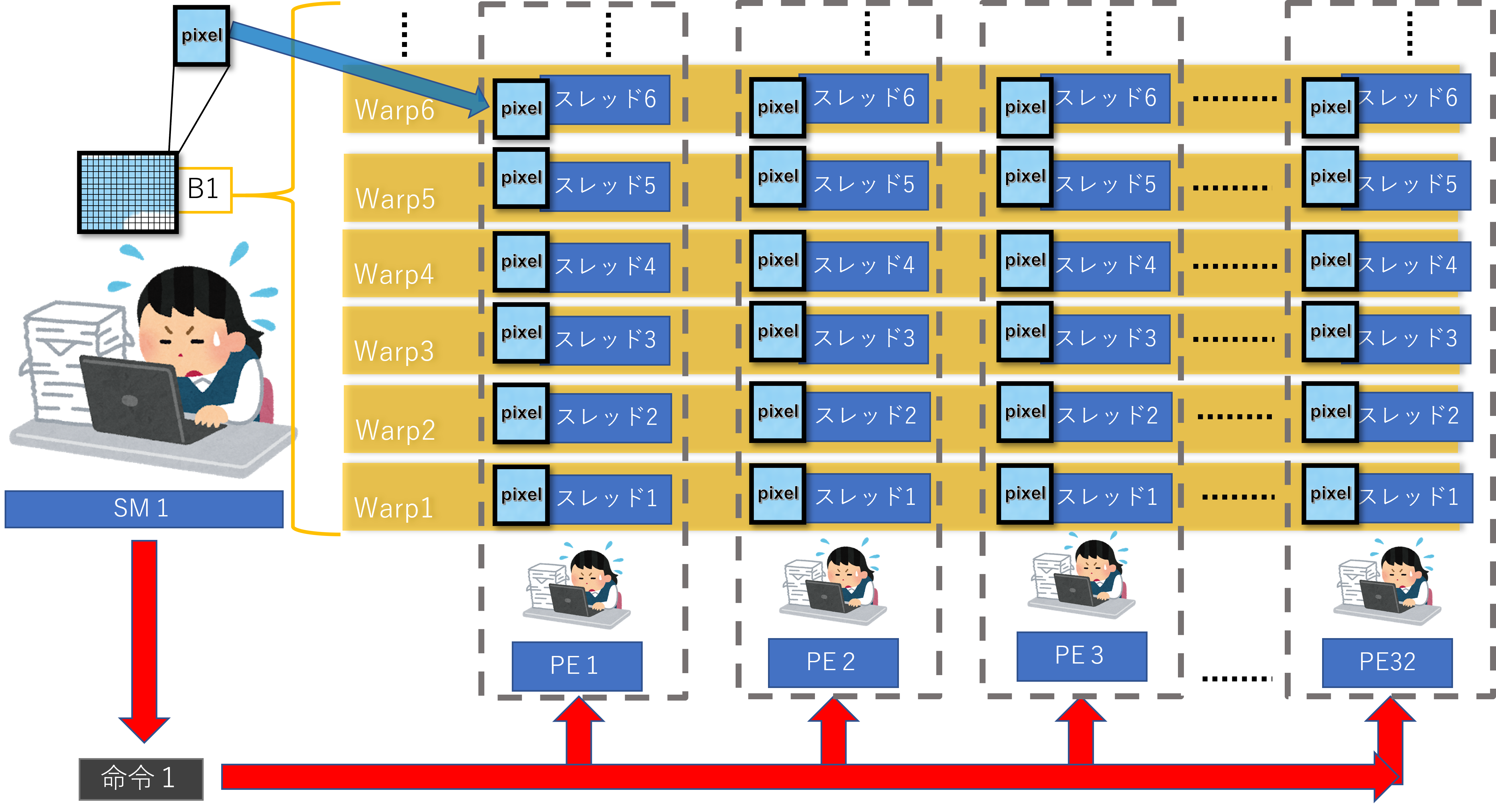
各SMは作業予定のブロック(画像の一部)を細分化し、「1ピクセル=1スレッド」として扱います。ですが、命令の最小単位はあくまでもWarp(32スレッド)なので、32PEのスレッドごとに1Warp仕事を与えます。
そして、命令機構は各PEに「実行処理を開始しろ!」と命令します8。
パート4
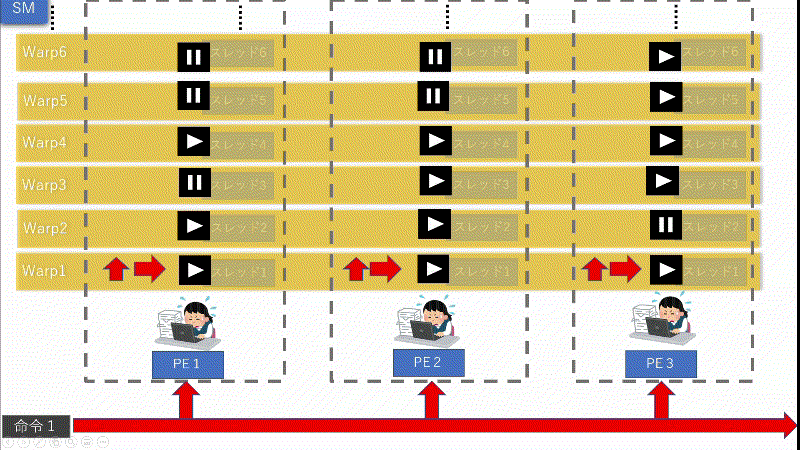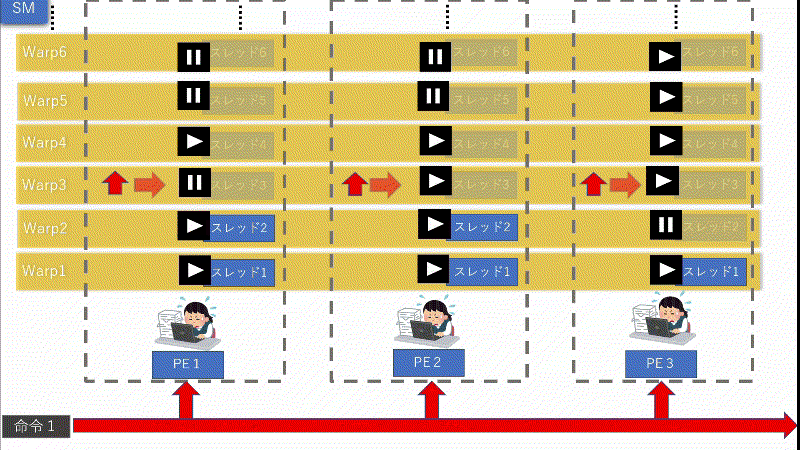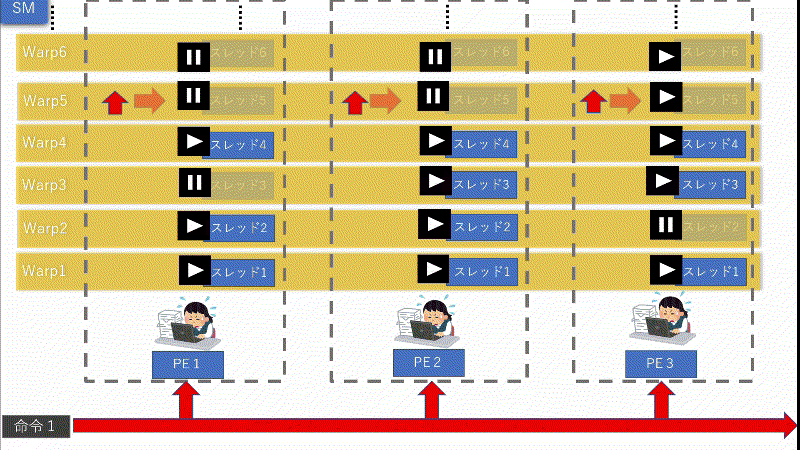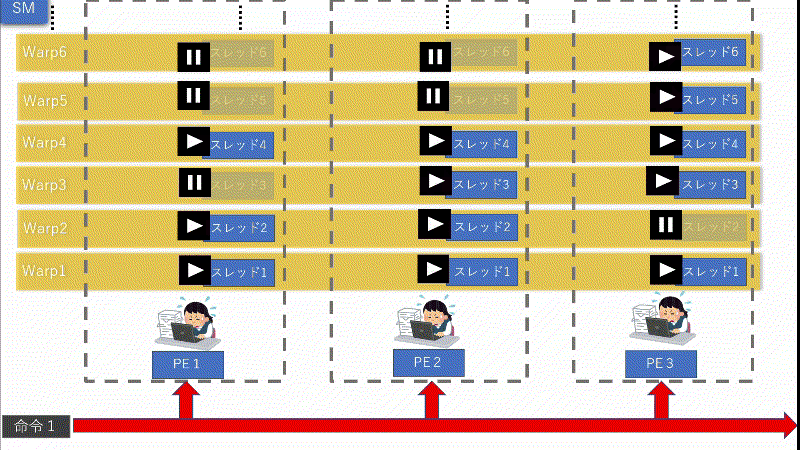
命令機構はWarpごとに命令を出してPEが動きます。上図の場合は「IF」が存在する場合のWarpの大体の動き方になります。(勿論、絶対正しいと言えないのでイメージですが...。参考程度でお願いします。)
最後に
やってしまった、また記事が長くなってしまった...。内容的に分割してしまうと訳が分からないと思うので、分割しなかったのですが、いかんせん量が多くなってしまった...。ここまで、全て読んでくれた方には感謝しかありません。知らなくても問題ない内容に貴重な時間を割いていただき、本当にありがとうございます。書いておきながら申し訳なさが出てきてしまいました。
ここまで読んだ方なら大体の事は分かってもらえたかと思います。これ以上の事は長くなりすぎるので説明は除きますので、気になる方は下記のリンクから覗いてみて下さい。
素材
- イラストやがほとんど9
- CMANはアイコンなど
-
NVIDIA JapanのSlideshareのスライドからいくつか参照しました。
それ以外はパワポを使った自作です。
参考サイト